") GPU領(lǐng)跑運(yùn)算性能,實(shí)現(xiàn)高性能計(jì)算新突破
GPU領(lǐng)跑運(yùn)算性能,實(shí)現(xiàn)高性能計(jì)算新突破

2018 全國高性能計(jì)算學(xué)術(shù)年會(huì)(HPC CHINA 2018)于10月20日在青島閉幕。大會(huì)以“HPC+一切皆可計(jì)算”為主題,圍繞高性能計(jì)算技術(shù)的研究發(fā)展與發(fā)展趨勢(shì)、高性能計(jì)算的重大應(yīng)用等主題展開。
年會(huì)上,各領(lǐng)域?qū)<覍W(xué)者圍繞著高性能計(jì)算技術(shù)各抒己見,分享了高性能計(jì)算在其各自領(lǐng)域的最新研究進(jìn)展。NVIDIA公司高性能計(jì)算及新興業(yè)務(wù)中國區(qū)總經(jīng)理劉通在大會(huì)主論壇發(fā)表了“NVIDIA GPU面向未來計(jì)算的持續(xù)創(chuàng)新”主題演講, 為大家介紹了GPU在高性能計(jì)算領(lǐng)域的應(yīng)用以及創(chuàng)新。
近年來,隨著傳統(tǒng)處理器在單線程運(yùn)算方面遭遇到瓶頸,性能加速放緩。GPU為加速計(jì)算指明了新方向,GPU加速器每年正在以穩(wěn)定的速率實(shí)現(xiàn)性能提升,其性能提升態(tài)勢(shì)也將持續(xù)到未來:
如今 ,GPU框架憑借其強(qiáng)大的并行計(jì)算能力,已被眾多超級(jí)計(jì)算機(jī)選做算力核心。目前,包括美國Summit、Sierra;日本ABCI;歐洲的Piz Daint在內(nèi)的諸多全球頂級(jí)超級(jí)計(jì)算機(jī)都采用了NVIDIA GPU作為其算力核心。而且,目前已有70%的通用HPC程序已經(jīng)實(shí)現(xiàn)GPU加速:
然而,與其強(qiáng)大算力相對(duì)應(yīng)的是GPU服務(wù)器突出的性價(jià)比優(yōu)勢(shì)。相較于CPU服務(wù)器,GPU服務(wù)器成本需求更低,原本需要由160臺(tái)Skylake CPU服務(wù)器才能完成的計(jì)算量,只需8臺(tái)V100 GPU 4 卡服務(wù)器即可完成,而總體成本僅是Skylake CPU服務(wù)器的1/5;1臺(tái)DGX-2的計(jì)算量相當(dāng)于300臺(tái)Dual-CPU服務(wù)器,總體成本卻只有其1/8:
此外,GPU能夠?qū)崿F(xiàn)HPC與AI的融合計(jì)算。HPC可為精準(zhǔn)計(jì)算提供支持,AI則可以提高結(jié)果預(yù)測準(zhǔn)確性加快反應(yīng)速度。NVIDIA TENSOR CORE GPU能夠滿足HPC與AI的融合計(jì)算,利用多精度混合計(jì)算,實(shí)現(xiàn)HPC應(yīng)用性能新突破。
應(yīng)用廣泛,GPU加速計(jì)算滲入各個(gè)領(lǐng)域
在實(shí)現(xiàn)加速計(jì)算的同時(shí),GPU加速的超算平臺(tái)還具有廣闊的產(chǎn)業(yè)應(yīng)用范圍,能夠在精準(zhǔn)醫(yī)藥、氣象模擬、新材料、無人駕駛、AI等眾多領(lǐng)域發(fā)揮作用。中國石油東方地球物理公司研究數(shù)據(jù)處理中心賴能和總工程師在NVIDIA新技術(shù)與應(yīng)用主題分論壇中介紹,中石油正在利用NVIDIA GPU加速計(jì)算處理石油海量數(shù)據(jù)。
在服務(wù)產(chǎn)業(yè)應(yīng)用的同時(shí),NVIDIA GPU加速計(jì)算也被廣泛應(yīng)用到科學(xué)研究中。南京大學(xué)周建教授介紹,南京大學(xué)高性能計(jì)算研究中心在使用NVIDIA GPU加速計(jì)算解決VASP雜化泛函數(shù)計(jì)算時(shí)感受了到GPU顯著的加速計(jì)算效果。在進(jìn)行CrGeTe3的雜化泛函自洽計(jì)算測試時(shí),相較于CPU,GPU的加速計(jì)算效果明顯。據(jù)統(tǒng)計(jì),對(duì)于此類較大的系統(tǒng),1個(gè)V100 GPU可以比一個(gè)雙路CPU服務(wù)器快10倍左右:
武漢大學(xué)蔡浩教授也在分論壇中進(jìn)行了介紹,武漢大學(xué)過去在使用滿帶寬振幅分析軟件(FALLS)進(jìn)行分波分析時(shí),存在要處理的事例數(shù)巨大;擬合模型非常復(fù)雜,參數(shù)空間巨大;擬合算法需要的計(jì)算步數(shù)非常多的困難。然而通過程序優(yōu)化,拆掉大的數(shù)據(jù)結(jié)構(gòu),將計(jì)算部分的CUDA代碼,全部分解成小的片段,交由GPU計(jì)算,提高計(jì)算效率;將條件分支全部移到程序外部,交給CPU處理,從而實(shí)現(xiàn)了充分調(diào)動(dòng)計(jì)算單元:
同時(shí),進(jìn)行算法優(yōu)化,將所有的求和計(jì)算都在GPU中進(jìn)行,GPU和CPU之間的數(shù)據(jù)交互降到最低:
目前,F(xiàn)ALLS已經(jīng)實(shí)現(xiàn)了多GPU聯(lián)合計(jì)算,并且實(shí)現(xiàn)了線性加速。如今,F(xiàn)ALLS可以處理更大的數(shù)據(jù)量和更大的參數(shù)空間,相較于算法優(yōu)化之前,計(jì)算時(shí)常實(shí)現(xiàn)了1000倍加速:
中科院高能物理研究所石京燕工程師也表示,中科院高能研究所在進(jìn)行高能物理實(shí)驗(yàn)時(shí),同樣會(huì)面臨海量的數(shù)據(jù)和復(fù)雜的計(jì)算過程,許多應(yīng)用程序都對(duì)采用GPU加速計(jì)算提出了強(qiáng)烈需求。如今,通過在Juno實(shí)驗(yàn)中引入GPU加速計(jì)算;通過GPU加速計(jì)算進(jìn)行交互式數(shù)據(jù)分析;基于深度學(xué)習(xí)進(jìn)行事件重建,中科院高難研究所已經(jīng)受益頗豐。
NVIDIA支持高校高性能計(jì)算教育
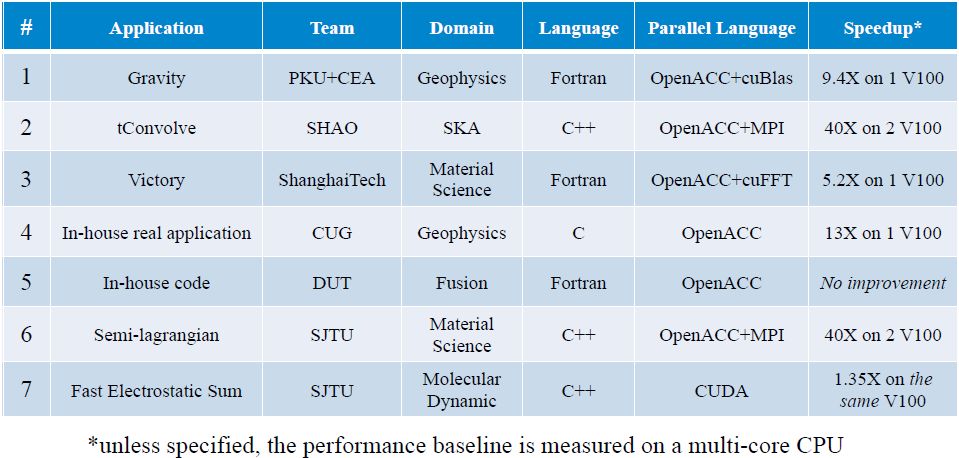
NVIDIA CUDA應(yīng)用市場總監(jiān)侯宇濤在10月19日的演講中表示NVIDIA在關(guān)注GPU技術(shù)創(chuàng)新的同時(shí),也致力于支持高校中的GPU教育。2018年8月20-24日,NVIDIA支持舉辦了國內(nèi)首次OpenACC GPU Hackathon大賽,多支來自國內(nèi)頂尖高校的隊(duì)伍參賽。各團(tuán)隊(duì)基于NVIDIA V100 GPU對(duì)程序應(yīng)用進(jìn)行優(yōu)化,實(shí)現(xiàn)了最大40倍速的計(jì)算速度提升。
此次HPC CHINA,NVIDIA的專家們還把NVIDIA深度學(xué)習(xí)學(xué)院(DLI)帶到了年會(huì)現(xiàn)場,為學(xué)員現(xiàn)場揭秘深度學(xué)習(xí)技術(shù)及其應(yīng)用,帶領(lǐng)學(xué)員動(dòng)手實(shí)驗(yàn),展示如何通過在Caffe框架上的NVIDIA DIGITS和MINIST手寫數(shù)據(jù)集,在深度學(xué)習(xí)工作流程中利用深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)(DNN),尤其是卷積神經(jīng)網(wǎng)絡(luò)(CNN)解決圖像分類問題。
NVIDIA GPU關(guān)注未來計(jì)算,持續(xù)創(chuàng)新
如今,具備更高計(jì)算能力的GPU技術(shù)為HPC應(yīng)用的高速發(fā)展帶來前所未有的強(qiáng)大計(jì)算引擎。隨著HPC與AI的融合在更多領(lǐng)域的應(yīng)用,計(jì)算單元需要同時(shí)具備超強(qiáng)的傳統(tǒng)HPC計(jì)算力和深度學(xué)習(xí)計(jì)算力。最新的NVIDIA GPU系列,完美融合CUDA核心與Tensor核心,同時(shí)滿足傳統(tǒng)計(jì)算與AI計(jì)算的需求,并且配置一系列加速軟件庫,為應(yīng)用開發(fā)提供最簡潔優(yōu)化的編程工具。NVIDIA GPU將不斷向更高性能發(fā)起挑戰(zhàn),無論是硬件還是軟件,都將保持著技術(shù)的高速創(chuàng)新。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5678瀏覽量
110055 -
gpu
+關(guān)注
關(guān)注
28文章
5245瀏覽量
135997
原文標(biāo)題:HPC CHINA 2018 | GPU加速實(shí)現(xiàn)高性能計(jì)算新突破
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
MAX17409:高性能GPU的電源控制利器
成功案例:象帝先計(jì)算技術(shù)與Imagination合作——面向現(xiàn)代圖形與計(jì)算工作負(fù)載的專業(yè)GPU

LT1208高速運(yùn)算放大器:高性能與多應(yīng)用的完美結(jié)合
高性能運(yùn)算放大器AD845:特性、應(yīng)用與設(shè)計(jì)要點(diǎn)
高性能145MHz FastFET運(yùn)算放大器AD8066的深度剖析
Samtec NITROWAVE?高性能微波電纜組件:突破傳統(tǒng)的卓越之選
炎核開源開放平臺(tái)上架推出OpenSparseBlas高性能稀疏計(jì)算庫
瀚海量子與沐曦股份達(dá)成戰(zhàn)略合作 量子計(jì)算軟件領(lǐng)軍者+高性能GPU芯片領(lǐng)軍者
知合計(jì)算:RISC-V架構(gòu)創(chuàng)新,阿基米德系列劍指高性能計(jì)算

中科曙光構(gòu)建全國產(chǎn)化基因組學(xué)高性能計(jì)算平臺(tái)
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】+NVlink技術(shù)從應(yīng)用到原理
使用樹莓派構(gòu)建 Slurm 高性能計(jì)算集群:分步指南!

高性能計(jì)算面臨的芯片挑戰(zhàn)

開售RK3576 高性能人工智能主板
Synaptics發(fā)布高性能AI MCU,推動(dòng)邊緣計(jì)算新突破




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論