 卷積神經網絡 (CNN) 已成為圖像分類的首選解決方案
卷積神經網絡 (CNN) 已成為圖像分類的首選解決方案

隨著攝像頭和其他設備產生的數據在快速增長,促使人們運用機器學習從汽車、安防和其他應用產生的影像中提取更多有用的信息。專用器件有望在嵌入式視覺應用中實現高性能機器學習 (ML) 推理。但是此類器件大都處于早期開發階段,因為設計人員正在努力尋找最有效的算法,甚至人工智能 (AI) 研究人員也在迅速推演新方法。
目前,開發人員一般使用針對 ML 的可用 FPGA 平臺來構建嵌入式視覺系統,以期滿足更高的性能要求。與此同時,他們可以保持所需的靈活性,以跟上機器學習發展的步伐。
本文將介紹 ML 處理的要求,以及為何 FPGA 能解決許多性能問題。然后,將介紹一個合適的基于 FPGA 的 ML 平臺及其使用方法。
機器學習算法和推理引擎
在 ML 算法中,卷積神經網絡 (CNN) 已成為圖像分類的首選解決方案。其圖像識別的準確率非常高,因而得以廣泛應用于多種應用,跨越不同的平臺,例如智能手機、安防系統和汽車駕駛員輔助系統。作為一種深度神經網絡 (DNN),CNN 使用的神經網絡架構由專用層構成。在對標注圖像進行訓練期間,它會從圖像中提取特征,并使用這些特征給圖像分類(參見“利用現成的軟硬件啟動機器學習”)。
CNN 開發人員通常在高性能系統或云平臺上進行訓練,使用圖形處理單元 (GPU) 加速在標注圖像數據集(通常數以百萬計)上訓練模型所需的巨量矩陣計算。訓練完成之后,訓練好的模型用在推理應用中,對視頻流中的新圖像或幀進行分類。推理部署完成后,訓練好的模型仍然需要執行同樣的矩陣計算,但由于輸入量要少很多,開發人員可以將 CNN 用于在通用硬件上運行的普通機器學習應用(參見“利用 Raspberry Pi 構建機器學習應用”)。
然而,對于許多應用而言,通用平臺缺乏在 CNN 推理中同時實現高準確率和高性能所需的性能。優化技術和替代 CNN 架構(如 MobileNet 或 SqueezeNet)有助于降低平臺要求,但通常會犧牲準確率并增加推理延時,而這可能與應用要求相沖突。
與此同時,快速發展的算法使得機器學習 IC 的設計工作變得復雜,因為需要機器學習 IC 既要足夠專門化以加速推理,又要足夠通用化以支持新算法。FPGA 多年來一直扮演著這一特定角色,提供加速關鍵算法所需的性能和靈活性,解決了通用處理器性能不足或沒有專用器件可用的問題。
FPGA 作為機器學習平臺
對于機器學習而言,GPU 仍然是標桿——這是早期的 FPGA 根本無法企及的。最近出現的一些器件,如IntelArria 10 GXFPGA 和Lattice SemiconductorECP5FPGA,大大縮小了先進 FPGA 和 GPU 之間的差距。對于某些使用緊湊的整數數據類型的 DNN 架構來說,此類 FPGA 的性能/功耗比甚至高于主流 GPU。
高級 FPGA 組合了嵌入式存儲器和數字信號處理 (DSP) 資源,對于一般矩陣乘法 (GEMM) 運算能夠實現很高的性能。其嵌入式存儲器靠近計算引擎,從而緩解了 CPU 存儲器瓶頸,而這種瓶頸通常會限制通用處理器上機器學習算法的性能。反之,相比于典型 DSP 器件(圖 1),FPGA 上的嵌入式 DSP 計算引擎提供了更多的并行乘法器資源。FPGA 廠商在交付專門用于機器學習的 FPGA 開發平臺時充分利用了這些特性。
圖 1:Lattice Semiconductor ECP5 之類的高級 FPGA 提供了實現高性能推理所需的并行處理資源和嵌入式存儲器。(圖片來源:Lattice Semiconductor)
例如,Intel 最近推出的支持 FPGA 的 OPENVINO? 擴展了該平臺將推理模型部署到不同類型設備(包括 GPU、CPU 和 FPGA)的能力。在該平臺上,開發人員可使用 Intel 的深度學習推理引擎工作流程,其中整合了 Intel 深度學習部署工具包和在 Intel OPENVINO 工具包中提供的 Intel 計算機視覺軟件開發套件 (SDK)。開發人員使用 SDK 的應用編程接口 (API) 構建模型,并且可利用 Intel 的運行模型優化器針對不同硬件平臺進行優化。
深度學習部署工具包旨在與 IntelDK-DEV-10AX115S-AArria 10 GX FPGA 開發套件配合使用,讓開發人員能從領先的 ML 框架(包括 Caffe 和 TensorFlow)導入訓練好的模型(圖 2)。在諸如 Arria 10 GX FPGA 開發套件之類目標平臺或使用 Arria 10 GX FPGA 器件的定制設計上,工具包中的模型優化器和推理引擎分別處理模型轉換和部署。
圖 2:支持 FPGA 的 Intel OPENVINO 工具包提供了一套必需的完整工具鏈,可將在 Caffe、TensorFlow 和其他框架上訓練的模型部署到 Arria 10 GX FPGA 開發套件或圍繞 Arria 10 GX FPGA 構建的定制設計上。(圖片來源:Intel)
為了遷移預訓練模型,開發人員使用基于 Python 的模型優化器生成了一個中間表示 (IR),該表示包含在一個提供網絡拓撲的 xml 文件和一個以二進制值提供模型參數的 bin 文件中。除了生成 IR 之外,模型優化器還會執行一項關鍵功能——移除模型中用于訓練但對推理毫無作用的層。此外,該工具會在可能的情況下將每個提供獨立數學運算的層合并到一個組合層中。
通過這種網絡修剪和合并,模型變得更緊湊,進而加快推理時間并減少對目標平臺的存儲器需求。
Intel 推理引擎是一個 C++ 庫,其中包含一組 C++ 類。這些類對于受支持的目標硬件平臺來說是通用的,因此可以在各個平臺上實現推理。對于推理應用而言,開發人員使用像CNNNetReader這樣的類來讀取 xml 文件 (ReadNetwork) 中包含的 CNN 拓撲以及 bin 文件 (ReadWeights) 中包含的模型參數。模型加載完成后,調用類方法Infer()執行阻塞推理,同時調用類方法StartAsync()執行異步推理,當推理完成時使用等待或完成例程處理結果。
Intel 在 OPENVINO 環境提供的多個示例應用程序中演示了完整的工作流程和詳細的推理引擎 API 調用。例如,安全屏障攝像機示例應用程序展示了使用推理模型流水線,以首先確定車輛邊界框(圖 3)。流水線中的下一個模型檢查了邊界框中的內容,識別車輛類別、顏色和車牌位置等車輛屬性。
圖 3:Intel 安全屏障攝像機示例應用程序演示了使用推理流水線,先識別車輛(綠色邊界框),再識別顏色、類型和車牌位置(紅色框)等車輛屬性,最后識別車牌字符(紅色文本)。(圖片來源:Intel Corp.)
流水線中的最后一個模型使用這些車輛屬性從車牌中提取字符。為了使用該模型進行推理,示例代碼顯示了利用推理模型 C++ 庫創建對象 (LPR),而該對象則是名為LPRDetection的結構的一個實例。此結構使用推理引擎 API 類對象來讀取 (CNNNetReader) 并驗證模型輸入和輸出(列表 1)。
副本
CNNNetwork read() override {
std::cout << "[ INFO ] Loading network files for Licence Plate Recognition (LPR)" << std::endl;
??????? CNNNetReader netReader;
??????? /** Read network model **/
??????? netReader.ReadNetwork(FLAGS_m_lpr);
??????? std::cout << "[ INFO ] Batch size is forced to? 1 for LPR Network" << std::endl;
??????? netReader.getNetwork().setBatchSize(1);
??????? /** Extract model name and load it's weights **/
??????? std::string binFileName = fileNameNoExt(FLAGS_m_lpr) + ".bin";
??????? netReader.ReadWeights(binFileName);
?
??????? /** LPR network should have 2 inputs (and second is just a stub) and one output **/
??????? // ---------------------------Check inputs
??????? std::cout << "[ INFO ] Checking LPR Network inputs" << std::endl;
??????? InputsDataMap inputInfo(netReader.getNetwork().getInputsInfo());
??????? if (inputInfo.size() != 2) {
??????????? throw std::logic_error("LPR should have 2 inputs");
???? ???}
??????? InputInfo::Ptr& inputInfoFirst = inputInfo.begin()->second;
inputInfoFirst->setInputPrecision(Precision::U8);
inputInfoFirst->getInputData()->setLayout(Layout::NCHW);
inputImageName = inputInfo.begin()->first;
auto sequenceInput = (++inputInfo.begin());
inputSeqName = sequenceInput->first;
if (sequenceInput->second->getTensorDesc().getDims()[0] != maxSequenceSizePerPlate) {
throw std::logic_error("LPR post-processing assumes certain maximum sequences");
}
// ---------------------------Check outputs
std::cout << "[ INFO ] Checking LPR Network outputs" << std::endl;
??????? OutputsDataMap outputInfo(netReader.getNetwork().getOutputsInfo());
??????? if (outputInfo.size() != 1) {
??????????? throw std::logic_error("LPR should have 1 output");
??????? }
??????? outputName = outputInfo.begin()->first;
std::cout << "[ INFO ] Loading LPR model to the "<< FLAGS_d_lpr << " plugin" << std::endl;
?
??????? _enabled = true;
??????? return netReader.getNetwork();
??? }
列表 1:此代碼片段來自 IntelOPENVINO工具包中的安全屏障攝像機示例應用程序,演示了使用 Intel 推理引擎 C++ 庫 API 將模型及其參數讀入推理引擎的設計模式。(代碼來源:Intel)
為了執行推理,該代碼加載數據并調用submitRequest方法,該方法啟動推理周期并等待結果,然后顯示識別的車牌字符(列表 2)。
副本
if (LPR.enabled()) { // licence plate
// expanding a bounding box a bit, better for the license plate recognition
result.location.x -= 5;
result.location.y -= 5;
result.location.width += 10;
result.location.height += 10;
auto clippedRect = result.location & cv::Rect(0, 0, width, height);
cv::Mat Plate = frame(clippedRect);
// ----------------------------Run License Plate Recognition
LPR.enqueue(Plate);
t0 = std::chrono::high_resolution_clock::now();
LPR.submitRequest();
LPR.wait();
t1 = std::chrono::high_resolution_clock::now();
LPRNetworktime += std::chrono::duration_cast(t1 - t0);
LPRInferred++;
// ----------------------------Process outputs
cv::putText(frame,
LPR.GetLicencePlateText(),
cv::Point2f(result.location.x, result.location.y + result.location.height + 15),
cv::FONT_HERSHEY_COMPLEX_SMALL,
0.8,
cv::Scalar(0, 0, 255));
if (FLAGS_r) {
std::cout << "License Plate Recognition results:" << LPR.GetLicencePlateText() << std::endl;
???????? }
???? }
???? cv::rectangle(frame, result.location, cv::Scalar(0, 0, 255), 2);
?}
列表 2:此代碼片段來自 Intel OPENVINO 工具包中的安全屏障攝像機示例應用程序,展示了加載模型、執行推理和生成結果的設計模式。(代碼來源:Intel)
集成式嵌入式視覺平臺
Intel 的 OPENVINO 方法強調平臺重定向,而 Lattice 的 SensAI 平臺完全聚焦于 FPGA 推理。SensAI 平臺的特性之一是為 DNN 架構(包括 CNN 和一個稱為二值化神經網絡 (BNN) 的緊湊架構)提供 FPGA IP。針對嵌入式視覺,SensAI CNN IP 為完整的推理引擎提供框架,將控制子系統、存儲器、輸入和輸出的接口與實現不同類型模型層(包括卷積、BatchNorm 歸一化、ReLu 激活、池化和其他)的資源結合在一起(圖 4)。
圖 4:Lattice Semiconductor CNN IP 實現了一個完整的推理系統框架,將專用引擎和用于控制、存儲器、輸入、輸出的接口結合在一起。(圖片來源:Lattice Semiconductor)
為了實現 CNN 模型,開發人員首先要在針對 ECP5 FPGA 的 Lattice Diamond 設計環境中或針對其他 Lattice FPGA 系列的 Radiant 設計環境中,利用 Lattice Clarity 配置工具配置 CNN。這里,開發人員可以指定模型類型(CNN 或 BNN)、卷積引擎數(最多 8 個)及每層的內部存儲大小(最多 16 Kb)或二進制大對象 (blob)。配置 CNN 之后,開發人員使用設計環境生成核心,作為 FPGA 比特流。
開發人員單獨將通過 Caffe 或 TensorFlow 開發并訓練好的模型導入 SensAI 平臺。這里,Lattice 神經網絡編譯器將訓練好的 Caffe 或 TensorFlow 模型轉換為一組包含神經網絡模型參數和執行命令序列的文件。SensAI 平臺將來自設計環境和編譯器的單獨輸出一起并入 FPGA,以提供最終的推理模型(圖 5)。
圖 5:Lattice Semiconductor SensAI 平臺將其 CNN 和 BNN IP 與其神經網絡編譯器結合在一起,使開發人員能夠轉換 Caffe 或 TensorFlow 模型,以在 Lattice FPGA 上作為推理引擎來運行。(圖片來源:Lattice Semiconductor)
針對嵌入式視覺應用,LatticeLF-EVDK1-EVN嵌入式視覺開發套件 (EVDK) 為運行 CNN 模型推理提供了理想的目標平臺。EVDK 提供了一個完整的 80 x 80 mm 三板堆疊式視頻平臺,包括 Lattice CrossLink 視頻輸入板、帶 ECP5 FPGA 的處理器板和 HDMI 輸出板。開發人員可以將 EVDK 用作 Lattice 提供的多個示例 CNN 應用的目標平臺。例如,Lattice 速度標志檢測參考設計運用 EVDK 來展示 SensAI CNN IP 在典型汽車應用中的應用(圖 6)。

圖 6:Lattice Semiconductor 速度標志檢測參考設計利用 SensAI 平臺和 Lattice LF_EVDK1-EVN 嵌入式視覺開發套件提供一個完整的推理應用,開發人員可以對其立即操作或詳細探索。(圖片來源:Lattice Semiconductor)
此示例應用程序的項目文件包括全套文件,從 Caffe caffemodel 和 TensorFlow pb 格式的模型開始。因此,開發人員可以探索這些模型的細節。例如,使用 TensorFlowimport_pb_to_tensorboard.py實用程序,開發人員可以導入 Lattice 提供的 pb 模型,以查看此示例應用程序中使用的 CNN 的細節(圖 7)。本例中,所提供的模型是由四個“Fire”模塊組成的序列,每個模塊包括:
- Conv2D 層,執行 3 x 3 卷積以從輸入流中提取特征
- 激活層,執行 BatchNorm 歸一化,然后執行修正線性單元 (ReLU) 激活
- MaxPool 池化層,用于對前一層的輸出進行采樣
圖 7:Lattice 速度標志檢測示例應用程序包括 TensorFlow pb 模型,開發人員可以將其導入 TensorBoard 進行詳細檢查。注意:數據向上流過此圖中的各層。(圖片來源:Digi-Key Electronics)
開發人員可以使用 SensAI 平臺生成模型文件,完成前面描述的模型流程。或者,開發人員可以使用所提供的文件直接跳轉到部署階段。任一情況下,文件都是通過接有適配器的 microSD 卡加載到 EVDK 中。
在操作中,EVDK 上的攝像機向 ECP5 FPGA 提供視頻流,其中配置的 CNN 加速器 IP 執行命令序列以執行推理。同任何推理引擎一樣,每個輸出通道都會產生一個結果,指出與該輸出通道相關聯的標簽即為輸入圖像的校正標簽的概率。本例中,模型是用每小時 25、30、35、40、45、50、55、60 和 65 英里的限速標志的標注圖像進行訓練的。因此,當模型在其輸入字段中的任何位置檢測到限速標志時,它會顯示檢測到的標志對應于每小時 25、30、35、40、45、50、55、60 或 65 英里限速的概率(圖 8)。
圖 8:Lattice 速度標志檢測演示運行在 Lattice EVDK 上,對視頻輸入流執行推理,生成輸出值,指示捕獲到的圖像對應于與該特定輸出相關聯的標簽的可能性。本例中,它顯示限速標志最有可能是 25 mph。(圖片來源:Lattice Semiconductor)
總結
為在嵌入式視覺應用中運用機器學習,開發人員使用可用硬件平臺實現所需性能水平的能力受到了限制。然而,高性能 FPGA 的出現使得開發人員可以構建性能接近 GPU 的推理引擎。采用專為嵌入式視覺設計的機器學習 FPGA 平臺,開發人員可以專注于特定需求,使用標準機器學習框架訓練模型,并依靠 FPGA 平臺實現高性能推理。
-
FPGA
+關注
關注
1660文章
22412瀏覽量
636316 -
IC
+關注
關注
36文章
6411瀏覽量
185632 -
cnn
+關注
關注
3文章
355瀏覽量
23422
發布評論請先 登錄
神經網絡的初步認識


一些神經網絡加速器的設計優化方案
CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSISI庫的使用
NMSIS神經網絡庫使用介紹
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作

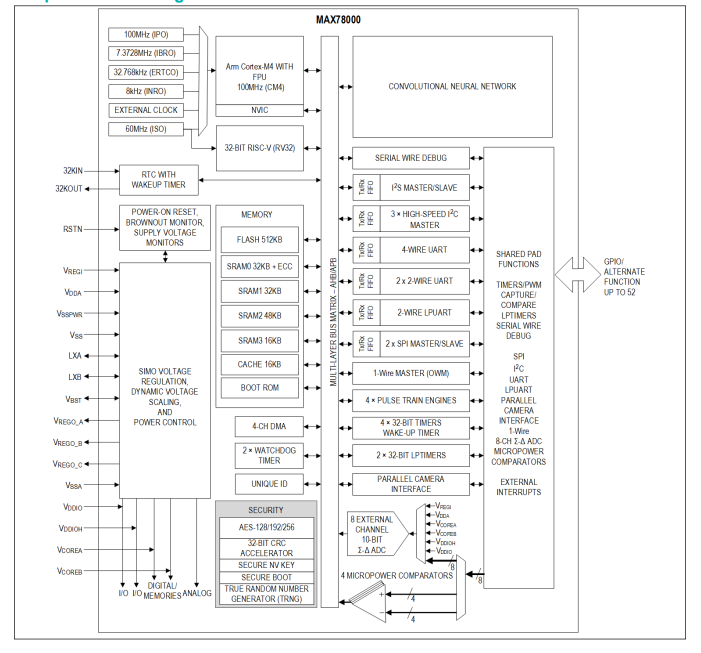
MAX78000采用超低功耗卷積神經網絡加速度計的人工智能微控制器技術手冊
在友晶LabCloud平臺上使用PipeCNN實現ImageNet圖像分類

自動駕駛感知系統中卷積神經網絡原理的疑點分析



 工商網監
工商網監
評論