 基于OpenTelemetry的全鏈路追蹤微服務可觀測性實踐
基于OpenTelemetry的全鏈路追蹤微服務可觀測性實踐

基于OpenTelemetry的全鏈路追蹤微服務可觀測性實踐
一、概述
1.1 背景介紹
微服務拆分到第三年,我們的服務數量從最初的5個膨脹到了47個。一個用戶下單請求要經過API Gateway -> 用戶服務 -> 商品服務 -> 庫存服務 -> 訂單服務 -> 支付服務,中間還有消息隊列和緩存的調用。某天線上出現下單接口P99延遲從200ms飆到了3秒,排查了兩個小時才定位到是庫存服務調用Redis超時導致的。
這就是沒有鏈路追蹤的痛。每個服務自己的日志都正常,但串起來看整個調用鏈,問題藏在哪個環節根本看不出來。
2019年我們先上了Jaeger + OpenTracing SDK,后來OpenTracing和OpenCensus合并成了OpenTelemetry(簡稱OTel),2021年開始逐步遷移到OTel。OTel的定位是可觀測性的統一標準,一套SDK同時產生Trace、Metric、Log三種信號,不再需要為每種信號單獨接入不同的庫。
遷移到OTel后,排障效率提升明顯。同樣的問題,現在從Grafana的Trace面板點進去,直接看到整個調用鏈的瀑布圖,哪個Span耗時異常一目了然,定位時間從小時級降到了分鐘級。
1.2 技術特點
廠商中立的統一標準:OTel是CNCF的畢業項目,不綁定任何后端。今天用Jaeger,明天想換成Tempo或者Zipkin,只需要改Collector的exporter配置,業務代碼一行不用動。我們從Jaeger遷移到Grafana Tempo的過程中,47個服務的代碼零改動。
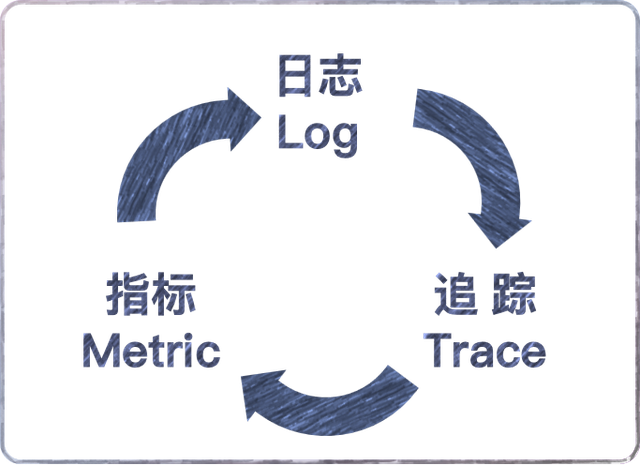
三信號統一(Trace/Metric/Log):一套OTel SDK同時產生分布式追蹤、指標和日志,三種數據通過Trace ID關聯。在Grafana里可以從一個異常Trace跳轉到對應時間段的指標圖表和日志,排障不需要在多個系統之間來回切換。
自動注入能力:Java、Python、Node.js等語言支持自動注入(auto-instrumentation),不需要修改業務代碼就能自動采集HTTP請求、數據庫調用、Redis操作等Span。我們的Java服務用javaagent方式接入,開發團隊完全無感知。
1.3 適用場景
微服務架構的請求鏈路追蹤:服務數量超過10個時,沒有鏈路追蹤基本等于盲人摸象。OTel可以自動記錄每個服務間的調用關系、耗時、狀態碼,快速定位慢請求和錯誤請求的根因。
性能瓶頸分析:通過Trace數據可以看到每個環節的耗時占比,比如一個請求總耗時500ms,其中數據庫查詢占了300ms,就知道該優化SQL了。配合采樣策略,可以只采集慢請求的Trace,減少存儲開銷。
服務依賴關系梳理:OTel Collector可以根據Trace數據自動生成服務拓撲圖,哪個服務調用了哪個服務、調用頻率多少、錯誤率多少,一張圖全看清。新人入職看這張圖就能快速了解系統架構。
1.4 環境要求
| 組件 | 版本要求 | 說明 |
|---|---|---|
| 操作系統 | CentOS 7+ / Ubuntu 20.04+ | 推薦Ubuntu 22.04 LTS |
| OTel Collector | 0.96+ | 本文以0.96.0為例 |
| Jaeger | 1.53+ | 作為Trace后端存儲和查詢 |
| Java | JDK 11+ | Java自動注入需要JDK 11以上 |
| Go | 1.21+ | Go SDK需要1.21以上 |
| Python | 3.8+ | Python自動注入需要3.8以上 |
| 內存 | Collector最低2GB,Jaeger最低4GB | 生產環境各8GB+ |
二、詳細步驟
2.1 準備工作
2.1.1 架構說明
我們采用的架構是:
應用服務(OTel SDK) --> OTel Collector(Agent模式) --> OTel Collector(Gateway模式) --> Jaeger/Tempo
--> Prometheus
--> Loki
兩層Collector的設計:
Agent模式:以DaemonSet或Sidecar部署在每個節點/Pod旁邊,負責接收本地應用的數據,做初步處理(采樣、過濾、添加屬性)
Gateway模式:集中部署,接收所有Agent的數據,做聚合處理后發送到后端存儲
這樣設計的好處是Agent掛了只影響單個節點,Gateway可以水平擴展,后端存儲的變更只需要改Gateway配置。
2.1.2 安裝OTel Collector
# 創建用戶和目錄 sudo useradd --system --no-create-home --shell /usr/sbin/nologin otelcol sudo mkdir -p /etc/otelcol /var/log/otelcol /data/otelcol sudo chown -R otelcol:otelcol /var/log/otelcol /data/otelcol # 下載OTel Collector Contrib版本(包含更多receiver/exporter) OTEL_VERSION="0.96.0" cd/tmp wget https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v${OTEL_VERSION}/otelcol-contrib_${OTEL_VERSION}_linux_amd64.tar.gz tar xzf otelcol-contrib_${OTEL_VERSION}_linux_amd64.tar.gz sudo mv otelcol-contrib /usr/local/bin/otelcol sudo chmod +x /usr/local/bin/otelcol # 驗證安裝 otelcol --version
2.1.3 安裝Jaeger
# 用Docker部署Jaeger All-in-One(測試環境) docker run -d --name jaeger -p 16686:16686 -p 4317:4317 -p 4318:4318 -p 14250:14250 -e COLLECTOR_OTLP_ENABLED=true -e SPAN_STORAGE_TYPE=badger -e BADGER_EPHEMERAL=false -e BADGER_DIRECTORY_VALUE=/badger/data -e BADGER_DIRECTORY_KEY=/badger/key -v /data/jaeger:/badger jaegertracing/all-in-one:1.53 # 生產環境用Elasticsearch后端 docker run -d --name jaeger-collector -p 14250:14250 -p 4317:4317 -p 4318:4318 -e SPAN_STORAGE_TYPE=elasticsearch -e ES_SERVER_URLS=http://elasticsearch:9200 -e ES_INDEX_PREFIX=jaeger -e ES_NUM_SHARDS=3 -e ES_NUM_REPLICAS=1 jaegertracing/jaeger-collector:1.53
2.2 核心配置
2.2.1 OTel Collector Agent模式配置
# /etc/otelcol/agent-config.yaml receivers: otlp: protocols: grpc: endpoint:0.0.0.0:4317 max_recv_msg_size_mib:16 http: endpoint:0.0.0.0:4318 cors: allowed_origins:["*"] # 采集主機指標(替代node_exporter) hostmetrics: collection_interval:30s scrapers: cpu: metrics: system.cpu.utilization: enabled:true memory: disk: filesystem: load: network: paging: processes: processors: batch: send_batch_size:1024 send_batch_max_size:2048 timeout:5s # 攢夠1024條或等待5秒就發送一批 # 默認的8192太大,延遲高;太小又增加網絡開銷 memory_limiter: check_interval:5s limit_mib:1536 spike_limit_mib:512 # 內存限制1.5GB,超過后開始丟棄數據 # 這個必須配,不配的話Collector OOM是遲早的事 resource: attributes: -key:host.name from_attribute:host.name action:upsert -key:deployment.environment value:production action:upsert -key:service.cluster value:prod-bj-01 action:upsert # 尾部采樣在Agent層不做,放到Gateway層統一處理 # Agent層只做概率采樣作為兜底 probabilistic_sampler: sampling_percentage:100 # Agent層默認采集100%,采樣策略在Gateway層控制 exporters: otlp: endpoint:otel-gateway:4317 tls: insecure:true retry_on_failure: enabled:true initial_interval:5s max_interval:30s max_elapsed_time:300s sending_queue: enabled:true num_consumers:10 queue_size:5000 logging: loglevel:warn # 只在debug時改成info或debug extensions: health_check: endpoint:0.0.0.0:13133 zpages: endpoint:0.0.0.0:55679 service: extensions:[health_check,zpages] pipelines: traces: receivers:[otlp] processors:[memory_limiter,resource,batch] exporters:[otlp] metrics: receivers:[otlp,hostmetrics] processors:[memory_limiter,resource,batch] exporters:[otlp] logs: receivers:[otlp] processors:[memory_limiter,resource,batch] exporters:[otlp] telemetry: logs: level:warn metrics: address:0.0.0.0:8888
2.2.2 OTel Collector Gateway模式配置
# /etc/otelcol/gateway-config.yaml receivers: otlp: protocols: grpc: endpoint:0.0.0.0:4317 max_recv_msg_size_mib:32 http: endpoint:0.0.0.0:4318 processors: batch: send_batch_size:2048 timeout:10s memory_limiter: check_interval:5s limit_mib:6144 spike_limit_mib:1024 # 尾部采樣:根據Trace的完整信息決定是否采樣 tail_sampling: decision_wait:30s # 等待30秒收集完整Trace后再決定是否采樣 num_traces:100000 # 內存中最多保留10萬條Trace expected_new_traces_per_sec:1000 policies: # 策略1:所有錯誤的Trace都保留 -name:errors-policy type:status_code status_code: status_codes:[ERROR] # 策略2:延遲超過1秒的Trace保留 -name:latency-policy type:latency latency: threshold_ms:1000 # 策略3:正常請求按10%概率采樣 -name:probabilistic-policy type:probabilistic probabilistic: sampling_percentage:10 # 策略4:特定服務100%采樣(比如支付服務) -name:payment-always type:string_attribute string_attribute: key:service.name values:[payment-service] # 給Span添加額外屬性 attributes: actions: -key:collector.version value:"0.96.0" action:upsert # Span指標生成:從Trace數據中提取RED指標 spanmetrics: metrics_exporter:prometheusremotewrite dimensions: -name:http.method -name:http.status_code -name:service.name histogram: explicit: buckets:[5ms,10ms,25ms,50ms,100ms,250ms,500ms,1s,2.5s,5s,10s] exporters: otlp/jaeger: endpoint:jaeger-collector:4317 tls: insecure:true prometheusremotewrite: endpoint:http://prometheus:9090/api/v1/write resource_to_telemetry_conversion: enabled:true loki: endpoint:http://loki:3100/loki/api/v1/push default_labels_enabled: exporter:false job:true logging: loglevel:warn extensions: health_check: endpoint:0.0.0.0:13133 zpages: endpoint:0.0.0.0:55679 service: extensions:[health_check,zpages] pipelines: traces: receivers:[otlp] processors:[memory_limiter,tail_sampling,attributes,spanmetrics,batch] exporters:[otlp/jaeger] metrics: receivers:[otlp] processors:[memory_limiter,batch] exporters:[prometheusremotewrite] logs: receivers:[otlp] processors:[memory_limiter,batch] exporters:[loki] telemetry: logs: level:warn metrics: address:0.0.0.0:8888
關鍵配置說明:
tail_sampling的decision_wait設為30秒,意味著一個Trace的所有Span必須在30秒內到達Collector,否則可能被截斷。對于大多數同步調用場景夠用了,但如果有異步消息隊列的場景,可能需要調大到60秒。
spanmetrics處理器會從Trace數據中自動生成請求速率(Rate)、錯誤率(Error)、延遲分布(Duration)三個指標,也就是RED指標。這樣不需要在應用代碼里手動埋點Prometheus指標,Trace數據自動轉換。
memory_limiter必須放在processors列表的第一個,這樣內存超限時最先觸發限流,避免后續處理器繼續消耗內存。
2.2.3 Systemd服務配置
# /etc/systemd/system/otelcol.service [Unit] Description=OpenTelemetry Collector Documentation=https://opentelemetry.io/docs/collector/ After=network-online.target Wants=network-online.target [Service] Type=simple User=otelcol Group=otelcol ExecStart=/usr/local/bin/otelcol --config=/etc/otelcol/agent-config.yaml ExecReload=/bin/kill -HUP $MAINPID Restart=on-failure RestartSec=5 LimitNOFILE=65536 LimitMEMLOCK=infinity StandardOutput=journal StandardError=journal Environment=GOMAXPROCS=4 [Install] WantedBy=multi-user.target
2.3 啟動和驗證
2.3.1 啟動服務
# 驗證配置文件 otelcol validate --config=/etc/otelcol/agent-config.yaml # 啟動Collector sudo systemctl daemon-reload sudo systemctl start otelcol sudo systemctlenableotelcol # 檢查狀態 sudo systemctl status otelcol # 檢查日志 sudo journalctl -u otelcol -f --no-pager
2.3.2 功能驗證
# 檢查健康狀態
curl -s http://localhost:13133/
# 預期輸出:{"status":"Server available"...}
# 檢查Collector自身指標
curl -s http://localhost:8888/metrics | head -30
# 發送測試Trace(用curl模擬OTLP HTTP協議)
curl -X POST http://localhost:4318/v1/traces
-H"Content-Type: application/json"
-d'{
"resourceSpans": [{
"resource": {
"attributes": [{"key": "service.name", "value": {"stringValue": "test-service"}}]
},
"scopeSpans": [{
"scope": {"name": "test"},
"spans": [{
"traceId": "5b8aa5a2d2c872e8321cf37308d69df2",
"spanId": "051581bf3cb55c13",
"name": "test-span",
"kind": 1,
"startTimeUnixNano": "1704067200000000000",
"endTimeUnixNano": "1704067200100000000",
"status": {"code": 1}
}]
}]
}]
}'
# 在Jaeger UI中查看:http://jaeger-host:16686
# 搜索service=test-service應該能看到剛才的Trace
2.3.3 SDK接入示例
Java自動注入(推薦,零代碼改動):
# 下載OTel Java Agent wget https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases/download/v2.1.0/opentelemetry-javaagent.jar -O /opt/otel/opentelemetry-javaagent.jar # 啟動Java應用時加上javaagent參數 java -javaagent:/opt/otel/opentelemetry-javaagent.jar -Dotel.service.name=order-service -Dotel.exporter.otlp.endpoint=http://localhost:4317 -Dotel.exporter.otlp.protocol=grpc -Dotel.traces.sampler=parentbased_always_on -Dotel.metrics.exporter=otlp -Dotel.logs.exporter=otlp -Dotel.resource.attributes=service.namespace=production,service.version=1.2.3 -jar order-service.jar
Go手動接入:
// main.go
packagemain
import(
"context"
"log"
"net/http"
"time"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
"go.opentelemetry.io/otel/propagation"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace"go.opentelemetry.io/otel/sdk/trace"
semconv"go.opentelemetry.io/otel/semconv/v1.24.0"
"go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp"
)
funcinitTracer()(*sdktrace.TracerProvider, error){
ctx := context.Background()
exporter, err := otlptracegrpc.New(ctx,
otlptracegrpc.WithEndpoint("localhost:4317"),
otlptracegrpc.WithInsecure(),
)
iferr !=nil{
returnnil, err
}
res, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceName("inventory-service"),
semconv.ServiceVersion("1.0.0"),
attribute.String("deployment.environment","production"),
),
)
iferr !=nil{
returnnil, err
}
tp := sdktrace.NewTracerProvider(
sdktrace.WithBatcher(exporter,
sdktrace.WithBatchTimeout(5*time.Second),
sdktrace.WithMaxExportBatchSize(512),
),
sdktrace.WithResource(res),
sdktrace.WithSampler(sdktrace.ParentBased(sdktrace.AlwaysSample())),
)
otel.SetTracerProvider(tp)
otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(
propagation.TraceContext{},
propagation.Baggage{},
))
returntp,nil
}
funcmain(){
tp, err := initTracer()
iferr !=nil{
log.Fatal(err)
}
defertp.Shutdown(context.Background())
// 使用otelhttp自動注入HTTP處理器
handler := http.HandlerFunc(func(w http.ResponseWriter, r *http.Request){
ctx := r.Context()
tracer := otel.Tracer("inventory-service")
// 手動創建子Span
ctx, span := tracer.Start(ctx,"check-inventory")
deferspan.End()
span.SetAttributes(
attribute.String("product.id", r.URL.Query().Get("product_id")),
attribute.Int("inventory.count",42),
)
w.Write([]byte("OK"))
})
wrappedHandler := otelhttp.NewHandler(handler,"inventory-check")
log.Fatal(http.ListenAndServe(":8080", wrappedHandler))
}
Python自動注入:
# 安裝OTel Python包 pip install opentelemetry-distro opentelemetry-exporter-otlp opentelemetry-bootstrap -a install # 啟動Python應用(自動注入) opentelemetry-instrument --service_name user-service --exporter_otlp_endpoint http://localhost:4317 --exporter_otlp_protocol grpc --traces_exporter otlp --metrics_exporter otlp python app.py
三、示例代碼和配置
3.1 完整配置示例
3.1.1 Collector完整Pipeline配置(生產級)
這是我們線上47個微服務環境跑了10個月的Gateway配置,日均處理Span量約2億條:
# /etc/otelcol/gateway-production.yaml
receivers:
otlp:
protocols:
grpc:
endpoint:0.0.0.0:4317
max_recv_msg_size_mib:32
keepalive:
server_parameters:
max_connection_idle:60s
max_connection_age:300s
time:30s
timeout:10s
http:
endpoint:0.0.0.0:4318
# 接收Prometheus格式的指標
prometheus:
config:
scrape_configs:
-job_name:'otel-collector'
scrape_interval:30s
static_configs:
-targets:['localhost:8888']
processors:
batch/traces:
send_batch_size:2048
send_batch_max_size:4096
timeout:10s
batch/metrics:
send_batch_size:4096
timeout:15s
batch/logs:
send_batch_size:2048
timeout:10s
memory_limiter:
check_interval:5s
limit_mib:6144
spike_limit_mib:1024
tail_sampling:
decision_wait:30s
num_traces:200000
expected_new_traces_per_sec:2000
policies:
-name:error-traces
type:status_code
status_code:
status_codes:[ERROR]
-name:slow-traces
type:latency
latency:
threshold_ms:1000
-name:payment-traces
type:string_attribute
string_attribute:
key:service.name
values:[payment-service,refund-service]
-name:health-check-drop
type:string_attribute
string_attribute:
key:http.target
values:[/health,/ready,/metrics]
invert_match:true
-name:default-sampling
type:probabilistic
probabilistic:
sampling_percentage:5
# 過濾掉健康檢查的Span,減少存儲
filter/traces:
error_mode:ignore
traces:
span:
-'attributes["http.target"] == "/health"'
-'attributes["http.target"] == "/ready"'
-'attributes["http.target"] == "/metrics"'
-'attributes["http.target"] == "/favicon.ico"'
# 敏感信息脫敏
attributes/sanitize:
actions:
-key:http.request.header.authorization
action:delete
-key:db.statement
action:hash
# 對SQL語句做hash,保留可關聯性但不暴露具體內容
spanmetrics:
metrics_exporter:prometheusremotewrite
dimensions:
-name:service.name
-name:http.method
-name:http.status_code
-name:rpc.method
histogram:
explicit:
buckets:[2ms,5ms,10ms,25ms,50ms,100ms,250ms,500ms,1s,2.5s,5s,10s]
dimensions_cache_size:5000
aggregation_temporality:AGGREGATION_TEMPORALITY_CUMULATIVE
exporters:
otlp/jaeger:
endpoint:jaeger-collector.monitoring:4317
tls:
insecure:true
retry_on_failure:
enabled:true
initial_interval:5s
max_interval:60s
sending_queue:
enabled:true
num_consumers:20
queue_size:10000
prometheusremotewrite:
endpoint:http://prometheus.monitoring:9090/api/v1/write
tls:
insecure:true
resource_to_telemetry_conversion:
enabled:true
loki:
endpoint:http://loki-gateway.monitoring:3100/loki/api/v1/push
extensions:
health_check:
endpoint:0.0.0.0:13133
zpages:
endpoint:0.0.0.0:55679
pprof:
endpoint:0.0.0.0:1777
service:
extensions:[health_check,zpages,pprof]
pipelines:
traces:
receivers:[otlp]
processors:[memory_limiter,filter/traces,attributes/sanitize,tail_sampling,spanmetrics,batch/traces]
exporters:[otlp/jaeger]
metrics:
receivers:[otlp,prometheus]
processors:[memory_limiter,batch/metrics]
exporters:[prometheusremotewrite]
logs:
receivers:[otlp]
processors:[memory_limiter,batch/logs]
exporters:[loki]
telemetry:
logs:
level:warn
metrics:
address:0.0.0.0:8888
3.1.2 Java自動注入高級配置
通過配置文件精細控制Java Agent的行為:
# /opt/otel/otel-agent.properties # 啟動時通過 -Dotel.javaagent.configuration-file 指定 otel.service.name=order-service otel.resource.attributes=service.namespace=production,service.version=2.1.0 otel.exporter.otlp.endpoint=http://otel-agent:4317 otel.exporter.otlp.protocol=grpc otel.exporter.otlp.timeout=10000 otel.exporter.otlp.compression=gzip otel.traces.sampler=parentbased_traceidratio otel.traces.sampler.arg=1.0 otel.bsp.schedule.delay=5000 otel.bsp.max.queue.size=2048 otel.bsp.max.export.batch.size=512 # 禁用對性能影響大但價值不高的instrumentation otel.instrumentation.runtime-metrics.enabled=false otel.instrumentation.log4j-appender.enabled=false otel.propagators=tracecontext,baggage otel.span.attribute.value.length.limit=1024 otel.span.attribute.count.limit=64
java -javaagent:/opt/otel/opentelemetry-javaagent.jar -Dotel.javaagent.configuration-file=/opt/otel/otel-agent.properties -jar order-service.jar
3.1.3 Kubernetes DaemonSet部署
# otel-collector-agent-daemonset.yaml
apiVersion:apps/v1
kind:DaemonSet
metadata:
name:otel-collector-agent
namespace:monitoring
spec:
selector:
matchLabels:
app:otel-collector-agent
template:
metadata:
labels:
app:otel-collector-agent
spec:
serviceAccountName:otel-collector
containers:
-name:otel-collector
image:otel/opentelemetry-collector-contrib:0.96.0
args:["--config=/etc/otelcol/config.yaml"]
ports:
-containerPort:4317
hostPort:4317
-containerPort:4318
hostPort:4318
resources:
requests:
cpu:200m
memory:512Mi
limits:
cpu:1000m
memory:2Gi
livenessProbe:
httpGet:
path:/
port:13133
initialDelaySeconds:15
volumeMounts:
-name:config
mountPath:/etc/otelcol
volumes:
-name:config
configMap:
name:otel-agent-config
3.2 實際應用案例
案例一:慢請求根因定位
場景描述:線上下單接口P99延遲從200ms突然飆到3秒,需要快速定位是哪個環節變慢了。
排查流程:
# 第一步:在Jaeger UI中搜索慢Trace
# Service: api-gateway
# Operation: POST /api/v1/orders
# Min Duration: 2s
# 找到一條耗時3.2秒的Trace
# 第二步:查看Trace瀑布圖,發現調用鏈:
# api-gateway (3.2s)
# └── order-service (3.1s)
# ├── user-service (50ms) 正常
# ├── product-service (80ms) 正常
# ├── inventory-service (2.8s) <-- 這里有問題
# ? ? ? ? │ ? ? └── Redis GET (2.7s) <-- 根因
# ? ? ? ? └── payment-service (未執行,被inventory阻塞)
# 第三步:看inventory-service的Redis Span屬性
# db.system: redis
# db.operation: GET
# net.peer.name: redis-cluster-03
# 發現是redis-cluster-03節點響應慢
# 第四步:用spanmetrics生成的指標確認影響范圍
# PromQL: histogram_quantile(0.99,
# ? rate(traces_spanmetrics_latency_bucket{
# ? ? service_name="inventory-service",
# ? ? span_name="Redis GET"
# ? }[5m]))
# 確認P99從5ms飆到了2.7s
從發現問題到定位根因,整個過程不到5分鐘。如果沒有鏈路追蹤,光看各服務自己的日志,至少要1-2小時。
案例二:跨服務上下文傳播驗證
場景描述:新接入OTel的服務和老的Zipkin服務之間Trace斷裂,需要排查上下文傳播問題。
排查步驟:
# OTel默認使用W3C TraceContext格式: # traceparent: 00-- - # 老服務用的是B3格式: # X-B3-TraceId / X-B3-SpanId / X-B3-Sampled # 解決方案:Java Agent配置多傳播器 # otel.propagators=tracecontext,baggage,b3multi # 驗證方法:用curl手動發請求檢查響應頭 curl -v -H"traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01" http://new-service:8080/api/test2>&1 | grep -i"traceparent|b3"
遷移期間兩種格式并存,等所有服務都遷移到OTel后再去掉B3支持。
四、最佳實踐和注意事項
4.1 最佳實踐
4.1.1 采樣策略選擇
采樣策略直接決定了存儲成本和排障能力之間的平衡。我們踩過的坑:一開始全量采集,47個服務每天產生20億條Span,Jaeger后端的Elasticsearch撐了兩周就扛不住了。
頭部采樣(Head-based Sampling):在Trace的第一個Span就決定是否采樣。優點是實現簡單、資源消耗低;缺點是決策時不知道這個Trace后續會不會出錯,可能漏掉錯誤Trace。
# Java Agent頭部采樣配置 # 按比例采樣:只采集10%的Trace otel.traces.sampler=parentbased_traceidratio otel.traces.sampler.arg=0.1
尾部采樣(Tail-based Sampling):等Trace的所有Span都到達Collector后再決定是否采樣。優點是可以根據完整信息決策(比如只保留錯誤的和慢的Trace);缺點是Collector需要在內存中緩存所有Trace,資源消耗大。
# Collector尾部采樣配置(推薦放在Gateway層) tail_sampling: decision_wait:30s num_traces:200000 policies: -name:errors-always type:status_code status_code: status_codes:[ERROR] -name:slow-always type:latency latency: threshold_ms:1000 -name:normal-sample-5pct type:probabilistic probabilistic: sampling_percentage:5
我們的做法:Gateway層用尾部采樣,錯誤Trace和慢Trace(>1s)100%保留,正常Trace只保留5%。這樣存儲量從20億條/天降到了約3億條/天,但所有有問題的Trace都不會丟。
4.1.2 Span屬性規范
Span屬性(Attributes)是排障時的關鍵信息,但不是越多越好。屬性太多會增加網絡傳輸和存儲開銷,太少又查不到有用信息。
我們團隊制定的Span屬性規范:
# 必須包含的屬性(所有服務統一) service.name:order-service # 服務名 service.version:1.2.3 # 服務版本 deployment.environment:production # 環境 service.namespace:ecommerce # 業務域 # HTTP請求Span必須包含 http.method:GET http.url:/api/v1/orders/12345 http.status_code:200 http.request_content_length:1024 http.response_content_length:2048 # 數據庫調用Span必須包含 db.system:mysql db.name:order_db db.operation:SELECT db.statement:"SELECT * FROM orders WHERE id = ?" # 注意:db.statement只記錄參數化的SQL,不記錄實際參數值,防止泄露敏感數據 # RPC調用Span必須包含 rpc.system:grpc rpc.service:inventory.InventoryService rpc.method:CheckStock # 禁止包含的屬性(敏感信息) # - 用戶密碼、Token # - 信用卡號、身份證號 # - 請求體中的完整JSON(太大)
4.1.3 與Prometheus/Loki關聯
OTel的三信號關聯是排障效率提升的關鍵。在Grafana中配置數據源關聯:
# Grafana數據源配置 - Jaeger # Settings -> Trace to logs: # Data source: Loki # Tags: service.name -> job # Span start time shift: -5m # Span end time shift: 5m # Filter by trace ID: true # Settings -> Trace to metrics: # Data source: Prometheus # Tags: service.name -> service_name # Span start time shift: -5m # Span end time shift: 5m
這樣配置后,在Jaeger的Trace詳情頁可以一鍵跳轉到:
對應時間段的Loki日志(按Trace ID過濾)
對應服務的Prometheus指標圖表
4.1.4 安全加固
敏感信息脫敏:在Collector的attributes處理器中刪除Authorization頭、對SQL語句做hash處理。別把用戶Token寫到Span里,Jaeger的存儲是明文的。
傳輸加密:生產環境Collector之間的通信用mTLS加密,特別是跨網絡的Agent到Gateway鏈路。
訪問控制:Jaeger UI加Nginx反向代理做IP白名單或SSO認證,不要裸露在公網。
數據保留策略:Trace數據保留7-14天就夠了,超過這個時間的Trace基本不會再查。Jaeger的Elasticsearch后端配置ILM策略自動清理。
4.2 注意事項
4.2.1 配置注意事項
memory_limiter必須放在processors列表的第一個位置。如果放在batch后面,batch已經消耗了大量內存,memory_limiter來不及限流,Collector直接OOM。我們線上出過一次這個問題,Collector反復重啟。
tail_sampling的decision_wait不能設太短。設10秒的話,如果某個服務的Span因為網絡延遲晚到了,這個Trace就不完整,采樣決策可能不準確。我們設30秒,覆蓋了99%的場景。
Java Agent的otel.bsp.max.queue.size默認2048,在高并發場景下可能不夠。隊列滿了新的Span會被丟棄,日志里會出現"Dropping span"警告。我們調到了4096。
別在生產環境開Collector的logging exporter的info級別,每條Span都會打一行日志,IO會被打滿。只在debug時臨時開啟。
4.2.2 常見錯誤
| 錯誤現象 | 原因分析 | 解決方案 |
|---|---|---|
| Trace斷裂,父子Span不關聯 | 上下文傳播失敗,propagator配置不匹配 | 檢查所有服務的propagator配置是否一致 |
| Collector報"dropping spans" | 發送隊列滿或后端寫入慢 | 增大sending_queue.queue_size,檢查后端性能 |
| Java Agent啟動后應用變慢 | 自動注入的instrumentation太多 | 禁用不需要的instrumentation |
| Span中缺少預期的屬性 | SDK版本不匹配或屬性名不符合語義約定 | 檢查SDK版本,參考OTel Semantic Conventions |
| 尾部采樣不生效 | decision_wait太短或Span分散在多個Collector | 增大decision_wait,確保同一Trace的Span路由到同一Collector |
| Collector OOM | memory_limiter未配置或位置不對 | 確保memory_limiter在processors列表第一位 |
4.2.3 兼容性問題
OTel SDK版本:Java Agent、Go SDK、Python SDK的版本盡量保持一致,至少大版本一致。混用不同大版本可能出現協議不兼容。
Collector版本:Contrib版本的Collector包含社區貢獻的組件,更新頻率快,偶爾會有breaking change。升級前先看Release Notes。
Jaeger兼容:Jaeger 1.35+原生支持OTLP協議,不需要再用jaeger exporter,直接用otlp exporter發送到Jaeger的4317端口。
Prometheus兼容:OTel的Metric和Prometheus的Metric在命名規范上有差異(OTel用點號分隔,Prometheus用下劃線),Collector的prometheusremotewrite exporter會自動轉換。
五、故障排查和監控
5.1 故障排查
5.1.1 日志查看
# Collector日志 sudo journalctl -u otelcol -f --no-pager # 只看錯誤 sudo journalctl -u otelcol -p err --since"1 hour ago" # Collector自身指標(通過/metrics端點) curl -s http://localhost:8888/metrics | grep otelcol # zpages調試頁面(需要開啟zpages擴展) # 瀏覽器訪問 http://collector-host:55679/debug/tracez # 可以看到Collector內部處理的Trace樣本
5.1.2 常見問題排查
問題一:Trace數據丟失,Jaeger中查不到預期的Trace
# 第一步:檢查Collector是否收到了數據 curl -s http://localhost:8888/metrics | grep otelcol_receiver_accepted_spans # 如果這個值在增長,說明Collector收到了Span # 第二步:檢查Collector是否成功發送 curl -s http://localhost:8888/metrics | grep otelcol_exporter_sent_spans # 對比accepted和sent的差值,差值大說明有丟棄 # 第三步:檢查發送失敗數 curl -s http://localhost:8888/metrics | grep otelcol_exporter_send_failed_spans # 不為0說明發送到后端失敗了 # 第四步:檢查采樣策略是否過濾掉了 curl -s http://localhost:8888/metrics | grep otelcol_processor_tail_sampling
解決方案:
發送失敗:檢查后端(Jaeger/Tempo)是否正常運行,網絡是否通
被采樣過濾:檢查tail_sampling策略,確認目標Trace符合保留條件
隊列溢出:增大sending_queue.queue_size
問題二:Collector OOM反復重啟
# 檢查內存使用 curl -s http://localhost:8888/metrics | grep go_memstats_heap_inuse_bytes # 檢查是否配置了memory_limiter grep -A5"memory_limiter"/etc/otelcol/config.yaml # 檢查tail_sampling的num_traces是否設太大 # 每個Trace在內存中大約占用2-5KB # num_traces=200000 大約需要400MB-1GB內存
解決方案:
確保memory_limiter在processors列表第一位
減小tail_sampling的num_traces
增大Collector的內存限制
如果是Agent模式,不要在Agent層做tail_sampling
問題三:SDK初始化失敗,應用啟動報錯
# Java Agent常見錯誤 # "Failed to export spans. The request could not be executed." # 原因:Collector地址不可達 # 解決:檢查otel.exporter.otlp.endpoint配置 # "java.lang.NoClassDefFoundError: io/opentelemetry/..." # 原因:Agent版本和應用依賴的OTel庫版本沖突 # 解決:用Agent自帶的instrumentation,移除應用pom.xml中的OTel依賴 # Go SDK常見錯誤 # "context deadline exceeded" # 原因:Collector連接超時 # 解決:檢查endpoint配置,確認Collector在運行
問題四:跨服務上下文傳播斷裂
# 排查步驟: # 1. 確認所有服務使用相同的propagator # 2. 檢查中間件(Nginx/Kong/Envoy)是否透傳了traceparent頭 # 3. 檢查消息隊列消費者是否正確提取了上下文 # Nginx需要配置透傳trace頭 # proxy_set_header traceparent $http_traceparent; # proxy_set_header tracestate $http_tracestate; # 驗證Nginx是否透傳 curl -v -H"traceparent: 00-aaaabbbbccccddddeeeeffffgggghhhh-1111222233334444-01" http://nginx-proxy/api/test2>&1 | grep traceparent
5.1.3 調試模式
# 臨時開啟Collector debug日志 # 修改配置文件中的telemetry.logs.level為debug # 或者用環境變量 OTEL_LOG_LEVEL=debug otelcol --config=/etc/otelcol/config.yaml # 使用logging exporter查看處理的數據 # 在配置中臨時添加logging exporter # exporters: # logging: # verbosity: detailed # sampling_initial: 5 # sampling_thereafter: 200 # Java Agent debug模式 java -javaagent:opentelemetry-javaagent.jar -Dotel.javaagent.debug=true -jar app.jar # 會輸出所有instrumentation的加載信息和Span詳情
5.2 性能監控
5.2.1 關鍵指標監控
# Collector接收的Span數量 curl -s http://localhost:8888/metrics | grep otelcol_receiver_accepted_spans # Collector發送成功的Span數量 curl -s http://localhost:8888/metrics | grep otelcol_exporter_sent_spans # Collector發送失敗的Span數量 curl -s http://localhost:8888/metrics | grep otelcol_exporter_send_failed_spans # Collector發送隊列大小 curl -s http://localhost:8888/metrics | grep otelcol_exporter_queue_size # Collector內存使用 curl -s http://localhost:8888/metrics | grep go_memstats_heap_inuse_bytes # 處理器丟棄的Span數量 curl -s http://localhost:8888/metrics | grep otelcol_processor_dropped_spans
5.2.2 監控指標說明
| 指標名稱 | 正常范圍 | 告警閾值 | 說明 |
|---|---|---|---|
| otelcol_receiver_accepted_spans rate | 根據業務量 | 突降50%以上 | 接收速率突降說明有服務停止上報 |
| otelcol_exporter_send_failed_spans rate | 0 | > 0持續5分鐘 | 任何發送失敗都需要關注 |
| otelcol_exporter_queue_size | < queue_size的70% | > queue_size的85% | 隊列接近滿說明后端寫入跟不上 |
| go_memstats_heap_inuse_bytes | < limit_mib的80% | > limit_mib的85% | 內存接近限制需要擴容 |
| otelcol_processor_dropped_spans rate | 0 | > 0 | 有Span被丟棄 |
| traces_spanmetrics_latency P99 | 根據SLA | 超過SLA閾值 | 從Trace生成的延遲指標 |
5.2.3 Prometheus監控規則
# prometheus-rules/otel-collector-alerts.yaml
groups:
-name:otel-collector-alerts
rules:
-alert:OtelCollectorDown
expr:up{job="otel-collector"}==0
for:2m
labels:
severity:critical
annotations:
summary:"OTel Collector實例{{ $labels.instance }}不可用"
-alert:OtelCollectorSpanExportFailure
expr:rate(otelcol_exporter_send_failed_spans_total[5m])>0
for:5m
labels:
severity:warning
annotations:
summary:"OTel Collector Span發送失敗"
description:"失敗速率:{{ $value }}/s,檢查后端存儲是否正常"
-alert:OtelCollectorQueueNearFull
expr:otelcol_exporter_queue_size/otelcol_exporter_queue_capacity>0.85
for:5m
labels:
severity:warning
annotations:
summary:"OTel Collector發送隊列接近滿"
-alert:OtelCollectorMemoryHigh
expr:go_memstats_heap_inuse_bytes{job="otel-collector"}/1024/1024/1024>5
for:5m
labels:
severity:warning
annotations:
summary:"OTel Collector堆內存超過5GB"
-alert:OtelCollectorSpanDropped
expr:rate(otelcol_processor_dropped_spans_total[5m])>0
for:3m
labels:
severity:warning
annotations:
summary:"OTel Collector有Span被丟棄"
5.3 備份與恢復
5.3.1 備份策略
OTel Collector本身是無狀態的,不需要備份數據,只需要備份配置文件。Trace數據的備份由后端存儲(Jaeger/Tempo)負責。
#!/bin/bash
# otel-backup.sh
set-euo pipefail
BACKUP_DIR="/backup/otel/$(date +%Y%m%d)"
mkdir -p"$BACKUP_DIR"
# 備份Collector配置
tar czf"$BACKUP_DIR/otel-config.tar.gz"/etc/otelcol/
# 備份Java Agent配置
tar czf"$BACKUP_DIR/otel-agent-config.tar.gz"/opt/otel/ 2>/dev/null ||true
# 備份Jaeger配置(如果有)
tar czf"$BACKUP_DIR/jaeger-config.tar.gz"/etc/jaeger/ 2>/dev/null ||true
# 清理7天前的備份
find /backup/otel -maxdepth 1 -typed -mtime +7 -execrm -rf {} ;
echo"[$(date)] OTel配置備份完成:$BACKUP_DIR"
5.3.2 恢復流程
停止Collector:sudo systemctl stop otelcol
恢復配置:tar xzf /backup/otel/20250101/otel-config.tar.gz -C /
驗證配置:otelcol validate --config=/etc/otelcol/agent-config.yaml
重啟服務:sudo systemctl start otelcol && curl -s http://localhost:13133/
-
python
+關注
關注
57文章
4876瀏覽量
90022 -
微服務
+關注
關注
0文章
150瀏覽量
8102
原文標題:告別“日志大海撈針”:OpenTelemetry 全鏈路追蹤落地實戰
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
微服務與容器技術實踐
微服務架構與實踐摘要
基于拓撲分割的網絡可觀測性分析方法
六大頂級、開源的數據可觀測性工具
華為云服務治理?| 微服務常見故障模式
基調聽云攜手道客打造云原生智能可觀測性平臺聯合解決方案
使用APM無法實現真正可觀測性的原因
什么是多云? 為什么我們需要多云可觀測性 (Observability)?
華為云發布全棧可觀測平臺 AOM,以 AI 賦能應用運維可觀測

【質量視角】可觀測性背景下的質量保障思路
DeepSeek賦能Vixtel飛思達CloudFox可觀測性平臺,打破可觀測性工程的實施壁壘
IBM被 2025年 Gartner? 可觀測性平臺魔力象限? 評為領導者




 工商網監
工商網監
評論