 RISC-V+類TPU架構:國產算力實現從"堆砌"到"精耕"的范式躍遷
RISC-V+類TPU架構:國產算力實現從"堆砌"到"精耕"的范式躍遷

電子發燒友網報道(文/吳子鵬)在AI大模型技術迅猛發展的今天,算力已成為決定模型性能與商業價值的關鍵因素。然而,隨著模型參數量與訓練計算量的激增,傳統"算力堆砌"模式已難以為繼。當前,行業正經歷從單純追求規模向注重效率與生態的范式躍遷——長期以來,以GPU為核心的算力體系深陷“高功耗、高成本、生態鎖定”的三重困境,而國產算力更是面臨“跟隨式創新”的瓶頸。
在此背景下,奕行智能推出的Epoch芯片率先采用RISC-V+RVV指令集架構,結合自研的VISA(虛擬指令集)技術和類TPU的雙脈動矩陣計算引擎,不僅在算力效率、數據精度支持、生態兼容上實現突破,更推動國產算力完成從“規模堆砌”到“效率精耕”的關鍵一躍,為AGI時代的算力底層創新提供了中國方案。
 ?
?
在傳統模式下,“算力堆疊”是提升AI性能的主要手段——通過增加GPU數量、擴大集群規模來滿足計算需求。但這種模式的邊際效益正在遞減,不僅帶來高昂的硬件和電力成本,還面臨算力利用率低、延遲高等問題。并且,長期以來,英偉達憑借CUDA生態構筑了近乎封閉的護城河。盡管不少國產芯片嘗試通過“CUDA兼容”切入市場,但正如奕行智能所指出的,CUDA是為英偉達硬件量身定制的鑰匙,在英偉達的GPGPU上才能充分發揮其強大性能,而API層面的兼容普遍存在著水土不服的問題,且難以跟上其快速迭代節奏。
此外,隨著大模型進入推理時代,Token成為核心產品形態。與軟件近乎零成本復制不同,Token的生產以算力和電力為原料,提升算力利用率與能效,直接等同于降低推理成本、提高毛利率。在此背景下,以谷歌TPU為代表的領域專用AI計算架構(DSA)憑借突出的能效比崛起。高盛最近的一份報告指出,谷歌TPU v6到TPU v7,每百萬token 的推理成本降低了約70%。
 ?
?
與兼顧通用性的 GPU 不同,TPU采取了精簡的架構設計,砍掉與AI推理無關的圖形處理單元,將寶貴的晶體管資源集中于大模型最核心的矩陣運算。其獨特的脈動陣列架構,讓數據如流水般在計算單元間連續流動,大幅減少了對寄存器的頻繁讀寫。配合大容量片上 SRAM 緩存與高效的數據搬運引擎 DMA,TPU 顯著降低了“數據搬運”這一主要能耗瓶頸。
谷歌TPU v7構建起規模達9216個TPU的“World Size”,并引入光學電路交換(OCS)技術,根據計算任務動態優化網絡拓撲,實現高效定制化互聯。在軟件層面,谷歌借助XLA編譯器及StableHLO中間表示層,實現對TensorFlow、JAX和PyTorch等主流框架的高效兼容,并通過OpenXLA開源項目構建起跨框架的通用編譯生態,TorchTPU項目實現TPU對PyTorch的原生支持,顯著降低開發者的遷移門檻。
與此同時,英偉達在GPGPU中持續提升DSA的比例,從Volta架構首次引入Tensor Core,到Blackwell架構進一步擴大張量核心規模并加入針對Transformer的優化引擎,體現出向領域定制化演進的趨勢。
不同于傳統指令集的封閉性,奕行智能在業內率先采用RISC-V + RVV(向量擴展)指令集構建AI芯片架構,并且率先支持RVV 1024 bit位寬,拓寬數據通道。
相較于傳統的X86和ARM架構,RISC-V在AI計算領域的優勢尤為突出:
·開放的圖靈完備指令:天然支持復雜控制流,可避免NPU的靈活性短板;
·RVV向量優勢:天然契合AI張量計算,掩碼操作原生支持稀疏矩陣;
·成熟生態借力:GCC/LLVM主流編譯器已完全支持,主流AI框架正在積極適配;
·定制化潛力:允許在標準之上擴展專用指令,完美平衡通用性與專用性。
據介紹,奕行智能Epoch芯片的EVAMIND AI內核集成多組RISC-V高性能核。其中,RISC-V標量計算引擎負責核內計算和控制,支持雙發射核內的VISA指令發射及調度運行;RISC-V向量加速引擎中,圖靈完備的高性能RVV向量加速RV核,超寬的D-length及I-Length利用RVV擴展技術對AI常用的超越函數硬件指令化,大幅提升AI計算性能。
 ?
?
在內核設計上,奕行智能的Epoch芯片采用了與谷歌TPU相似的架構思路。
據介紹,該芯片集成了高性能RISC-V核與性能強大的雙脈動流水矩陣運算引擎,其矩陣、向量、標量的精簡架構設計,完全匹配大模型的計算特點,顯著降低了傳統GPGPU 架構中用于調度與資源分配的額外開銷(包含算力、帶寬、編程投入等,通常占總開銷的10%-20%),有效提高能效比與面積效率,打滿算力。
其大尺寸矩陣運算引擎,采用類TPU的雙脈動流水設計,數據復用率提升數倍,且顯著減少了數據前處理的開銷。相比同類方案,編程也更為簡單易用,限制更少——例如幾乎無需為規避bank沖突特意做手動編排,能夠直接支持模型中開發難度大的卷積矩陣乘算子等。
面對AI計算中頻繁出現的4D數據,奕行智能的高性能4D DMA引擎展現出明顯優勢。相比競品往往需要多次數據搬移與處理,該引擎僅通過一次操作即可完成4D數據的整體搬移,并在過程中同步完成數據變換與重排。此外,通過配置大容量片上緩存,將熱點與關鍵數據置于 L1/L2 中,其訪問速度相比存放在 DDR 的方案提升1–2個數量級。其近存計算設計,讓產品在實測中 Flash Attention 關鍵算子利用率相比競品提升4.5倍。
奕行智能指出,該公司推出的國內業界首款RISC-V AI算力芯片Epoch及計算平臺解決方案于2025年啟動量產,目前正在大規模量產出貨中。
除了RISC-V+類TPU,奕行智能的AI芯片還有一大創新,即精準卡位“低位寬高精度”技術浪潮。在深度學習領域,數據精度與計算效率始終存在權衡關系。例如,TPU Tensor Core 在FP8模式下可提供2倍于BF16的算力密度;Ironwood(TPU v7)的FP8峰值算力達到4.6PetaFLOPS,而BF16僅為2.3PFLOPS。2025年6月,NVIDIA正式發布NVFP4,將大模型精度進一步壓縮至4-bit,精度卻接近BF16水準,標志行業進入4-bit時代。
奕行智能AI芯片支持DeepSeek所需的基于分塊量化的FP8計算精度,并在其新一代產品支持NVFP4、MXFP4、MXFP8、MXINT8等前沿的數據格式,可高效釋放算力,大幅降低存儲開銷,助力客戶在大模型時代以更低功耗、更小成本,獲得更卓越的智能體驗。
奕行智能自研的互聯技術方案ELink,支持超大帶寬與超低延遲的Scale Up 擴展,并且配合交換側,已經實現對前沿在網計算技術的支持,意味著可將部分計算卸載至網絡交換節點,而無需在計算卡間搬運大量數據,從而減輕帶寬負擔,降低通信延遲。
為了提升開發人員基于奕行智能AI芯片部署AI大模型的效率,奕行智能以獨創的虛擬指令(VISA)技術在軟件與硬件之間建立中間抽象層,上層的算子及AI編譯器建立在VISA之上,而硬件則負責VISA宏指令的執行。這一設計巧妙地隔離了硬件迭代對上層軟件的沖擊,有效解決了芯片升級帶來的軟件兼容性挑戰。同時,VISA通過軟流水、循環展開等極致優化,解決了AI計算中高級Tensor操作直接編譯到底層指令時性能陡降的行業痼疾。
 ?
?
針對AI數據規整性強的特點,奕行智能推出了Tile級動態調度架構。該架構由Tile級虛擬指令集、智能編譯器和硬件調度器組成,原生適配當前興起的Tile(如Triton、TileLang)編程范式。它能夠自動管理指令間依賴、順序流水和內存切分,不僅大幅提高了編程的易用性,更突破了靜態優化的性能天花板。
同時,基于自研的ETK基礎軟件棧,奕行智能全面兼容PyTorch、TensorFlow、JAX等主流框架,提供豐富的深度優化高性能算子。目前,奕行智能正與Triton國際社區展開重量級合作,計劃開源其虛擬指令集,合力打造RISC-V DSA領域的“CUDA”級生態。
在此背景下,奕行智能推出的Epoch芯片率先采用RISC-V+RVV指令集架構,結合自研的VISA(虛擬指令集)技術和類TPU的雙脈動矩陣計算引擎,不僅在算力效率、數據精度支持、生態兼容上實現突破,更推動國產算力完成從“規模堆砌”到“效率精耕”的關鍵一躍,為AGI時代的算力底層創新提供了中國方案。
算力困局:從“堆芯片”到“提效能”的必然轉向
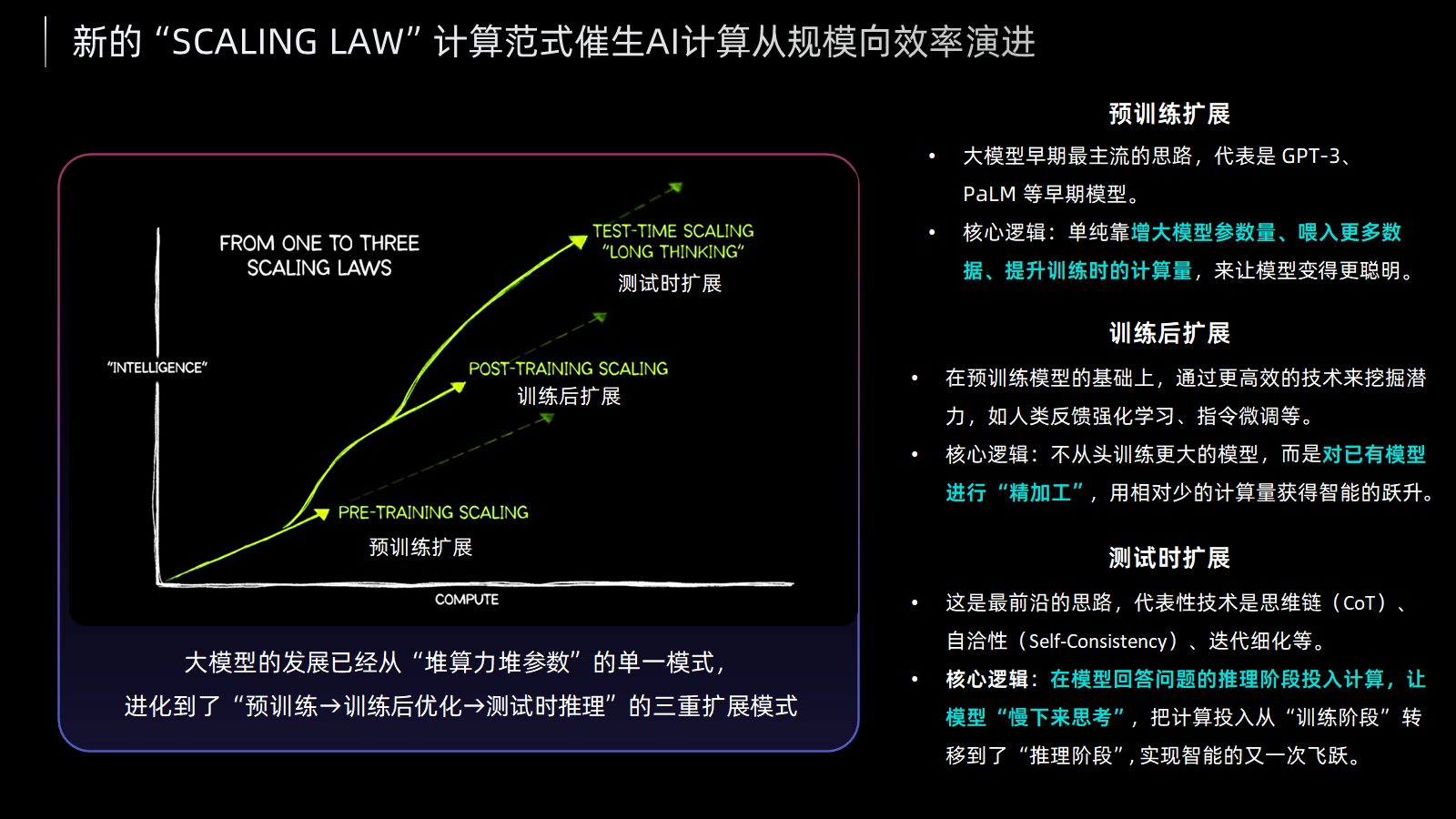
AI大模型的飛速發展,正倒逼算力產業進行一場深刻變革。數據顯示,AI模型參數量和訓練計算量的增長速度,已遠超硬件算力的提升速度,算力供需矛盾日益突出。與此同時,大模型的發展模式也從“預訓練主導”演進為“預訓練→訓練后優化→測試時推理”的三階段擴展模式,推理需求迎來爆發,推動算力競爭的核心從“規模”轉向“效率與規模并重”。?在傳統模式下,“算力堆疊”是提升AI性能的主要手段——通過增加GPU數量、擴大集群規模來滿足計算需求。但這種模式的邊際效益正在遞減,不僅帶來高昂的硬件和電力成本,還面臨算力利用率低、延遲高等問題。并且,長期以來,英偉達憑借CUDA生態構筑了近乎封閉的護城河。盡管不少國產芯片嘗試通過“CUDA兼容”切入市場,但正如奕行智能所指出的,CUDA是為英偉達硬件量身定制的鑰匙,在英偉達的GPGPU上才能充分發揮其強大性能,而API層面的兼容普遍存在著水土不服的問題,且難以跟上其快速迭代節奏。
此外,隨著大模型進入推理時代,Token成為核心產品形態。與軟件近乎零成本復制不同,Token的生產以算力和電力為原料,提升算力利用率與能效,直接等同于降低推理成本、提高毛利率。在此背景下,以谷歌TPU為代表的領域專用AI計算架構(DSA)憑借突出的能效比崛起。高盛最近的一份報告指出,谷歌TPU v6到TPU v7,每百萬token 的推理成本降低了約70%。
?與兼顧通用性的 GPU 不同,TPU采取了精簡的架構設計,砍掉與AI推理無關的圖形處理單元,將寶貴的晶體管資源集中于大模型最核心的矩陣運算。其獨特的脈動陣列架構,讓數據如流水般在計算單元間連續流動,大幅減少了對寄存器的頻繁讀寫。配合大容量片上 SRAM 緩存與高效的數據搬運引擎 DMA,TPU 顯著降低了“數據搬運”這一主要能耗瓶頸。
谷歌TPU v7構建起規模達9216個TPU的“World Size”,并引入光學電路交換(OCS)技術,根據計算任務動態優化網絡拓撲,實現高效定制化互聯。在軟件層面,谷歌借助XLA編譯器及StableHLO中間表示層,實現對TensorFlow、JAX和PyTorch等主流框架的高效兼容,并通過OpenXLA開源項目構建起跨框架的通用編譯生態,TorchTPU項目實現TPU對PyTorch的原生支持,顯著降低開發者的遷移門檻。
與此同時,英偉達在GPGPU中持續提升DSA的比例,從Volta架構首次引入Tensor Core,到Blackwell架構進一步擴大張量核心規模并加入針對Transformer的優化引擎,體現出向領域定制化演進的趨勢。
架構創新:RISC-V + 類TPU的雙重優勢
在這場全球AI基礎設施的范式重構中,國內AI芯片企業奕行智能敏銳地捕捉到了行業趨勢變革,創新性地將RISC-V的開放靈活性與類TPU架構的高效性相結合,打造出全新的AI計算底座。不同于傳統指令集的封閉性,奕行智能在業內率先采用RISC-V + RVV(向量擴展)指令集構建AI芯片架構,并且率先支持RVV 1024 bit位寬,拓寬數據通道。
相較于傳統的X86和ARM架構,RISC-V在AI計算領域的優勢尤為突出:
·開放的圖靈完備指令:天然支持復雜控制流,可避免NPU的靈活性短板;
·RVV向量優勢:天然契合AI張量計算,掩碼操作原生支持稀疏矩陣;
·成熟生態借力:GCC/LLVM主流編譯器已完全支持,主流AI框架正在積極適配;
·定制化潛力:允許在標準之上擴展專用指令,完美平衡通用性與專用性。
據介紹,奕行智能Epoch芯片的EVAMIND AI內核集成多組RISC-V高性能核。其中,RISC-V標量計算引擎負責核內計算和控制,支持雙發射核內的VISA指令發射及調度運行;RISC-V向量加速引擎中,圖靈完備的高性能RVV向量加速RV核,超寬的D-length及I-Length利用RVV擴展技術對AI常用的超越函數硬件指令化,大幅提升AI計算性能。
?在內核設計上,奕行智能的Epoch芯片采用了與谷歌TPU相似的架構思路。
據介紹,該芯片集成了高性能RISC-V核與性能強大的雙脈動流水矩陣運算引擎,其矩陣、向量、標量的精簡架構設計,完全匹配大模型的計算特點,顯著降低了傳統GPGPU 架構中用于調度與資源分配的額外開銷(包含算力、帶寬、編程投入等,通常占總開銷的10%-20%),有效提高能效比與面積效率,打滿算力。
其大尺寸矩陣運算引擎,采用類TPU的雙脈動流水設計,數據復用率提升數倍,且顯著減少了數據前處理的開銷。相比同類方案,編程也更為簡單易用,限制更少——例如幾乎無需為規避bank沖突特意做手動編排,能夠直接支持模型中開發難度大的卷積矩陣乘算子等。
面對AI計算中頻繁出現的4D數據,奕行智能的高性能4D DMA引擎展現出明顯優勢。相比競品往往需要多次數據搬移與處理,該引擎僅通過一次操作即可完成4D數據的整體搬移,并在過程中同步完成數據變換與重排。此外,通過配置大容量片上緩存,將熱點與關鍵數據置于 L1/L2 中,其訪問速度相比存放在 DDR 的方案提升1–2個數量級。其近存計算設計,讓產品在實測中 Flash Attention 關鍵算子利用率相比競品提升4.5倍。
奕行智能指出,該公司推出的國內業界首款RISC-V AI算力芯片Epoch及計算平臺解決方案于2025年啟動量產,目前正在大規模量產出貨中。
除了RISC-V+類TPU,奕行智能的AI芯片還有一大創新,即精準卡位“低位寬高精度”技術浪潮。在深度學習領域,數據精度與計算效率始終存在權衡關系。例如,TPU Tensor Core 在FP8模式下可提供2倍于BF16的算力密度;Ironwood(TPU v7)的FP8峰值算力達到4.6PetaFLOPS,而BF16僅為2.3PFLOPS。2025年6月,NVIDIA正式發布NVFP4,將大模型精度進一步壓縮至4-bit,精度卻接近BF16水準,標志行業進入4-bit時代。
奕行智能AI芯片支持DeepSeek所需的基于分塊量化的FP8計算精度,并在其新一代產品支持NVFP4、MXFP4、MXFP8、MXINT8等前沿的數據格式,可高效釋放算力,大幅降低存儲開銷,助力客戶在大模型時代以更低功耗、更小成本,獲得更卓越的智能體驗。
奕行智能自研的互聯技術方案ELink,支持超大帶寬與超低延遲的Scale Up 擴展,并且配合交換側,已經實現對前沿在網計算技術的支持,意味著可將部分計算卸載至網絡交換節點,而無需在計算卡間搬運大量數據,從而減輕帶寬負擔,降低通信延遲。
為了提升開發人員基于奕行智能AI芯片部署AI大模型的效率,奕行智能以獨創的虛擬指令(VISA)技術在軟件與硬件之間建立中間抽象層,上層的算子及AI編譯器建立在VISA之上,而硬件則負責VISA宏指令的執行。這一設計巧妙地隔離了硬件迭代對上層軟件的沖擊,有效解決了芯片升級帶來的軟件兼容性挑戰。同時,VISA通過軟流水、循環展開等極致優化,解決了AI計算中高級Tensor操作直接編譯到底層指令時性能陡降的行業痼疾。
?針對AI數據規整性強的特點,奕行智能推出了Tile級動態調度架構。該架構由Tile級虛擬指令集、智能編譯器和硬件調度器組成,原生適配當前興起的Tile(如Triton、TileLang)編程范式。它能夠自動管理指令間依賴、順序流水和內存切分,不僅大幅提高了編程的易用性,更突破了靜態優化的性能天花板。
同時,基于自研的ETK基礎軟件棧,奕行智能全面兼容PyTorch、TensorFlow、JAX等主流框架,提供豐富的深度優化高性能算子。目前,奕行智能正與Triton國際社區展開重量級合作,計劃開源其虛擬指令集,合力打造RISC-V DSA領域的“CUDA”級生態。
結語
從“算力堆疊”到“精耕細作”,國產AI芯片正在探索一條屬于自己的進階之路。奕行智能通過RISC-V+類TPU的架構創新,確立硬件的高效與靈活;通過低位寬高精度的技術突破,高效軟硬件協同以及動態調度架構,實現商業成本的極致優化;通過VISA虛擬指令集架構、兼容主流框架的軟件棧等,打破生態壁壘。這款正在大規模量產出貨的Epoch芯片,不僅是奕行智能技術實力的集中展現,更是國產算力在AGI時代實現彎道超車、邁向高質量發展的一個重要縮影。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
TPU
+關注
關注
0文章
171瀏覽量
21691 -
RISC-V
+關注
關注
49文章
2926瀏覽量
53331
發布評論請先 登錄
相關推薦
熱點推薦
從"替代人力"到"智能協同":履帶式巡檢機器人的產業躍遷
2026年的工業智能化轉型浪潮中,一個顯著的趨勢正在形成——工業巡檢機器人正從單純的"人力替代工具"升級為具備感知、決策與協同能力的"智能體"。
選EtherCAT模塊,別只看價格,先看"體檢報告"
±8kV靜電、±2kV浪涌、-42℃極寒、1500V高壓—這不是極限運動,而是DPort-ECT模塊的出廠"必修課"。本文詳解工業級EtherCAT從站如何通過嚴苛測試關

機械臂越復雜越&amp;quot;卡頓&amp;quot;?別讓控制器拖了后腿
工業機器人動作越復雜,傳統控制器越"卡頓"?ZMC900E用4核A55跑Linux算軌跡,3核R5F硬件級專管EtherCAT通信,實現±1.5μs微秒級抖動,破解
ZM82:一顆國產模組,如何讓傳統路燈變&amp;quot;聰明&amp;quot;?
ZM82系列國產ZigBee模組以星型組網替代傳統有線通信,實現路燈遠程監控、智能調光與故障自愈,助力城市照明系統降本增效、綠色升級。行業痛點:傳統城市照明的管理困境傳統城市照明系統受制于早期技術
L3試點落地,和芯星通如何成為車企突圍的&amp;quot;隱形守護者&amp;quot;?
;生死線"。從"能測"到"能跑",高精度定位技

Vishay Vitramon Touch &quot;N&quot; Tune? MLCC套件技術分析
在元件焊盤上,無需焊接即可查看電路特性。這樣可以實現快速電路性能評估,并方便更換組件,直至達到所需的調諧效果。該高頻MLCC Touch "N" Tune套件非常適合寬帶無線通信、 RF儀器、濾波網絡、 定時
&quot;Access violation&quot; 錯誤,復位位置,重新打印
"Access violation" 錯誤
光耦合器:電子世界的 &quot;光橋梁&quot;
在現代電子設備的復雜電路中,信號的傳輸與隔離至關重要。就像城市交通中需要橋梁來跨越障礙、連接不同區域一樣,電子電路里也需要一座 "橋梁" 來實現信號的安全、高效傳輸,同時避免
精密設備的&amp;quot;電力保鏢&amp;quot;:優比施UPS如何守護數據與硬件安全?
一、用戶痛點:精密設備的"斷電恐懼癥"在數據中心、醫療實驗室、工業控制等場景中,精密電子設備對電源的依賴已達到"零容忍"級別:數據安全危機:服務

地熱發電環網柜局放監測設備:清潔能源電網的&amp;quot;安全衛士&amp;quot;
文章由山東華科信息技術有限公司提供在"雙碳"目標驅動下,地熱發電作為穩定基荷電源,其電網接入設備的可靠性至關重要。環網柜作為地熱電站與主網連接的關鍵節點,其內部絕緣缺陷可能引發

為什么GNSS/INS組合被譽為導航界的&amp;quot;黃金搭檔&amp;quot;?
在導航技術領域,GNSS(全球導航衛星系統)和INS(慣性導航系統)的結合,一直被業界譽為"黃金搭檔"。它們優勢互補,克服了單一系統的局限性,為高精度、高可靠性的導航提供了完美

人形機器人為什么要定制? ——揭秘工業場景的&quot;千面需求&quot;
核心洞察:標準化機器人難以破解工業場景的"需求碎片化"困局。富唯智能通過?"五大模塊柔性架構+零代碼中樞"
倉儲界的&quot;速效救心丸&quot;,Ethercat轉PROFINET網關實戰案例
實戰案例,Ethercat轉PROFINET網關,倉儲界的"速效救心丸"

電纜局部放電在線監測:守護電網安全的&amp;quot;黑科技&amp;quot;
文章由山東華科信息技術有限公司提供在萬家燈火的背后,有一張覆蓋全國的"能源神經網絡"晝夜不息地運轉。電纜作為電力輸送的"主動脈",其健康狀況直接

隧道管廊變壓器局放在線監測:為地下&amp;quot;電力心臟&amp;quot;裝上智能聽診器
文章由山東華科信息技術有限公司提供在城市的地下脈絡中,隧道管廊承載著電網的"主動脈",而變壓器堪稱其中的"動力心臟"。這個封閉而潮濕的環境中,變




 工商網監
工商網監
評論