") 算力積木+3D堆疊!GPNPU架構(gòu)創(chuàng)新,應對AI推理需求
算力積木+3D堆疊!GPNPU架構(gòu)創(chuàng)新,應對AI推理需求

電子發(fā)燒友網(wǎng)報道(文/李彎彎)2025年,人工智能正式邁入應用推理時代。大模型從實驗室走向千行百業(yè),推理需求呈指數(shù)級爆發(fā)。然而,高昂的推理成本與有限的算力供給之間的矛盾日益凸顯,成為制約AI規(guī)模化落地的關(guān)鍵瓶頸。在此背景下,云天勵飛推出其第五代芯片架構(gòu)——GPNPU(General-Purpose Neural Processing Unit,通用神經(jīng)網(wǎng)絡(luò)處理單元),以一場底層架構(gòu)的革命,試圖重塑AI算力格局,推動大模型推理走向極致性價比時代。
GPNPU的核心定位是:做推理時代的優(yōu)等生。它摒棄了傳統(tǒng)芯片追求大而全的通用計算思路,轉(zhuǎn)而聚焦大模型推理的核心場景,如Prefill準備階段和Decode生成階段,進行深度定制與優(yōu)化。其目標極具挑戰(zhàn)性:將當前約1美元/百萬Token的推理成本,壓縮至僅需1美分/百萬Token,實現(xiàn)百倍效率提升。
GPNPU的黑科技源于三大底層創(chuàng)新。首先是算力積木設(shè)計思想。傳統(tǒng)芯片往往一刀切,難以兼顧云、邊、端多樣化的部署需求。GPNPU采用模塊化架構(gòu),如同樂高積木般可靈活堆疊,實現(xiàn)一次流片、多規(guī)格輸出。其算力覆蓋從8T到256T,既能支撐云端大模型推理,也能賦能邊緣設(shè)備與終端智能體,如機器人、手機、AR眼鏡,真正實現(xiàn)全場景覆蓋。
其次,GPNPU采用3D堆疊存儲技術(shù),直面內(nèi)存墻難題。大模型推理對帶寬極為敏感,數(shù)據(jù)搬運速度常成為性能瓶頸。通過3D堆疊,GPNPU大幅提升存儲密度與帶寬利用率,讓計算單元得以持續(xù)滿血運行,顯著提升能效比。
第三,GPNPU實現(xiàn)異構(gòu)化與靈活調(diào)度。它深刻洞察到推理任務(wù)的動態(tài)特性:Prefill階段重算力,Decode階段重帶寬。因此,通過軟硬協(xié)同優(yōu)化,GPNPU可動態(tài)調(diào)整算力、帶寬與存儲的配比,不再依賴單一芯片硬扛,而是以靈活架構(gòu)適配任務(wù)變化,實現(xiàn)資源最優(yōu)利用。
與傳統(tǒng)架構(gòu)相比,GPNPU展現(xiàn)出顯著差異化優(yōu)勢。傳統(tǒng)GPU雖生態(tài)成熟、通用性強,但推理成本高昂;傳統(tǒng)NPU能效較高,但多聚焦終端推理,通用性受限。而GPNPU則兼具GPU的通用性與NPU的高能效,專為大模型推理優(yōu)化,覆蓋端、邊、云全場景,并以算力積木實現(xiàn)前所未有的架構(gòu)靈活性,真正實現(xiàn)極致性價比。
目前,基于GPNPU架構(gòu)的芯片正加速落地。正在研發(fā)的Nova 500系列,作為第五代GPNPU芯片,重點提升帶寬與能效,是實現(xiàn)“1元內(nèi)搞定百萬Token”目標的關(guān)鍵一步。展望未來,Nova 600系列將探索光電一體化互聯(lián),構(gòu)建高性價比的算力網(wǎng)絡(luò),進一步將推理成本推向分級成本新低。
依托GPNPU,云天勵飛已構(gòu)建“深穹”(云端)、“深界”(邊緣)、“深擎”(具身智能)三大芯片產(chǎn)品矩陣,全面服務(wù)于互聯(lián)網(wǎng)大廠、智能終端廠商與機器人企業(yè),推動AI應用的廣泛落地。
在國產(chǎn)工藝受限、高端GPU供應不確定的現(xiàn)實下,云天勵飛沒有選擇在制程工藝上硬拼,而是以架構(gòu)創(chuàng)新另辟蹊徑。GPNPU不僅是技術(shù)的突破,更是一種戰(zhàn)略智慧的體現(xiàn)——通過“算力積木+3D堆疊”的創(chuàng)新路徑,走出一條高能效、低成本、全場景的差異化發(fā)展之路。它預示著,AI算力將不再昂貴稀缺,而是如水電般普惠,真正賦能千行百業(yè)的智能化變革。
GPNPU的核心定位是:做推理時代的優(yōu)等生。它摒棄了傳統(tǒng)芯片追求大而全的通用計算思路,轉(zhuǎn)而聚焦大模型推理的核心場景,如Prefill準備階段和Decode生成階段,進行深度定制與優(yōu)化。其目標極具挑戰(zhàn)性:將當前約1美元/百萬Token的推理成本,壓縮至僅需1美分/百萬Token,實現(xiàn)百倍效率提升。
GPNPU的黑科技源于三大底層創(chuàng)新。首先是算力積木設(shè)計思想。傳統(tǒng)芯片往往一刀切,難以兼顧云、邊、端多樣化的部署需求。GPNPU采用模塊化架構(gòu),如同樂高積木般可靈活堆疊,實現(xiàn)一次流片、多規(guī)格輸出。其算力覆蓋從8T到256T,既能支撐云端大模型推理,也能賦能邊緣設(shè)備與終端智能體,如機器人、手機、AR眼鏡,真正實現(xiàn)全場景覆蓋。
其次,GPNPU采用3D堆疊存儲技術(shù),直面內(nèi)存墻難題。大模型推理對帶寬極為敏感,數(shù)據(jù)搬運速度常成為性能瓶頸。通過3D堆疊,GPNPU大幅提升存儲密度與帶寬利用率,讓計算單元得以持續(xù)滿血運行,顯著提升能效比。
第三,GPNPU實現(xiàn)異構(gòu)化與靈活調(diào)度。它深刻洞察到推理任務(wù)的動態(tài)特性:Prefill階段重算力,Decode階段重帶寬。因此,通過軟硬協(xié)同優(yōu)化,GPNPU可動態(tài)調(diào)整算力、帶寬與存儲的配比,不再依賴單一芯片硬扛,而是以靈活架構(gòu)適配任務(wù)變化,實現(xiàn)資源最優(yōu)利用。
與傳統(tǒng)架構(gòu)相比,GPNPU展現(xiàn)出顯著差異化優(yōu)勢。傳統(tǒng)GPU雖生態(tài)成熟、通用性強,但推理成本高昂;傳統(tǒng)NPU能效較高,但多聚焦終端推理,通用性受限。而GPNPU則兼具GPU的通用性與NPU的高能效,專為大模型推理優(yōu)化,覆蓋端、邊、云全場景,并以算力積木實現(xiàn)前所未有的架構(gòu)靈活性,真正實現(xiàn)極致性價比。
目前,基于GPNPU架構(gòu)的芯片正加速落地。正在研發(fā)的Nova 500系列,作為第五代GPNPU芯片,重點提升帶寬與能效,是實現(xiàn)“1元內(nèi)搞定百萬Token”目標的關(guān)鍵一步。展望未來,Nova 600系列將探索光電一體化互聯(lián),構(gòu)建高性價比的算力網(wǎng)絡(luò),進一步將推理成本推向分級成本新低。
依托GPNPU,云天勵飛已構(gòu)建“深穹”(云端)、“深界”(邊緣)、“深擎”(具身智能)三大芯片產(chǎn)品矩陣,全面服務(wù)于互聯(lián)網(wǎng)大廠、智能終端廠商與機器人企業(yè),推動AI應用的廣泛落地。
在國產(chǎn)工藝受限、高端GPU供應不確定的現(xiàn)實下,云天勵飛沒有選擇在制程工藝上硬拼,而是以架構(gòu)創(chuàng)新另辟蹊徑。GPNPU不僅是技術(shù)的突破,更是一種戰(zhàn)略智慧的體現(xiàn)——通過“算力積木+3D堆疊”的創(chuàng)新路徑,走出一條高能效、低成本、全場景的差異化發(fā)展之路。它預示著,AI算力將不再昂貴稀缺,而是如水電般普惠,真正賦能千行百業(yè)的智能化變革。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
AI
+關(guān)注
關(guān)注
91文章
40696瀏覽量
302335
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
端側(cè)AI“堆疊DRAM”技術(shù),這些國內(nèi)廠商發(fā)力!
正3D DRAM等定制化存儲方案正是基于利基存儲和先進封裝,以近存計算的方式滿足AI推理的存儲需求。SoC廠商、下游終端廠商都在積極適配這一類新型存儲。 ? 華邦電子CUBE ? 華邦

邊緣AI算力臨界點:深度解析176TOPS香橙派AI Station的產(chǎn)業(yè)價值
310P芯片的底層架構(gòu),深度剖析這款產(chǎn)品的技術(shù)細節(jié)、算力門檻及其在實際產(chǎn)業(yè)落地中的真實價值。
一、176TOPS的產(chǎn)業(yè)門檻:為何這是邊緣算力
發(fā)表于 03-10 14:19
百億Token一分錢!云天勵飛喊出“推理成本萬倍降”,公布三年三芯路線圖
勵飛再次闡述了GPNPU架構(gòu)的技術(shù)內(nèi)涵,并公開了未來三年大算力芯片路線圖,致力于成為“最懂AI的推理

力爭百萬 Tokens 推理成本降低百倍:云天勵飛發(fā)布未來三年大算力芯片戰(zhàn)略,首曝 DeepVerse 路線圖
集中于攻克大模型落地的“成本壁壘”,致力于通過底層架構(gòu)創(chuàng)新,力爭實現(xiàn)百萬 Tokens 推理成本降低 100 倍以上的目標,推動 AI 從技術(shù)嘗鮮走向普惠生產(chǎn)

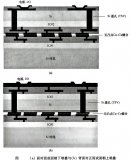
簡單認識3D SOI集成電路技術(shù)
在半導體技術(shù)邁向“后摩爾時代”的進程中,3D集成電路(3D IC)憑借垂直堆疊架構(gòu)突破平面縮放限制,成為提升性能與功能密度的核心路徑。
應對端側(cè)AI算力、內(nèi)存、功耗“三堵墻”困境,安謀科技Arm China “周易”X3給出技術(shù)錦囊
NPU IP,通過架構(gòu)創(chuàng)新、軟硬件協(xié)同優(yōu)化與開放生態(tài)等,為應對端側(cè)AI“算力墻”、“內(nèi)存墻”、

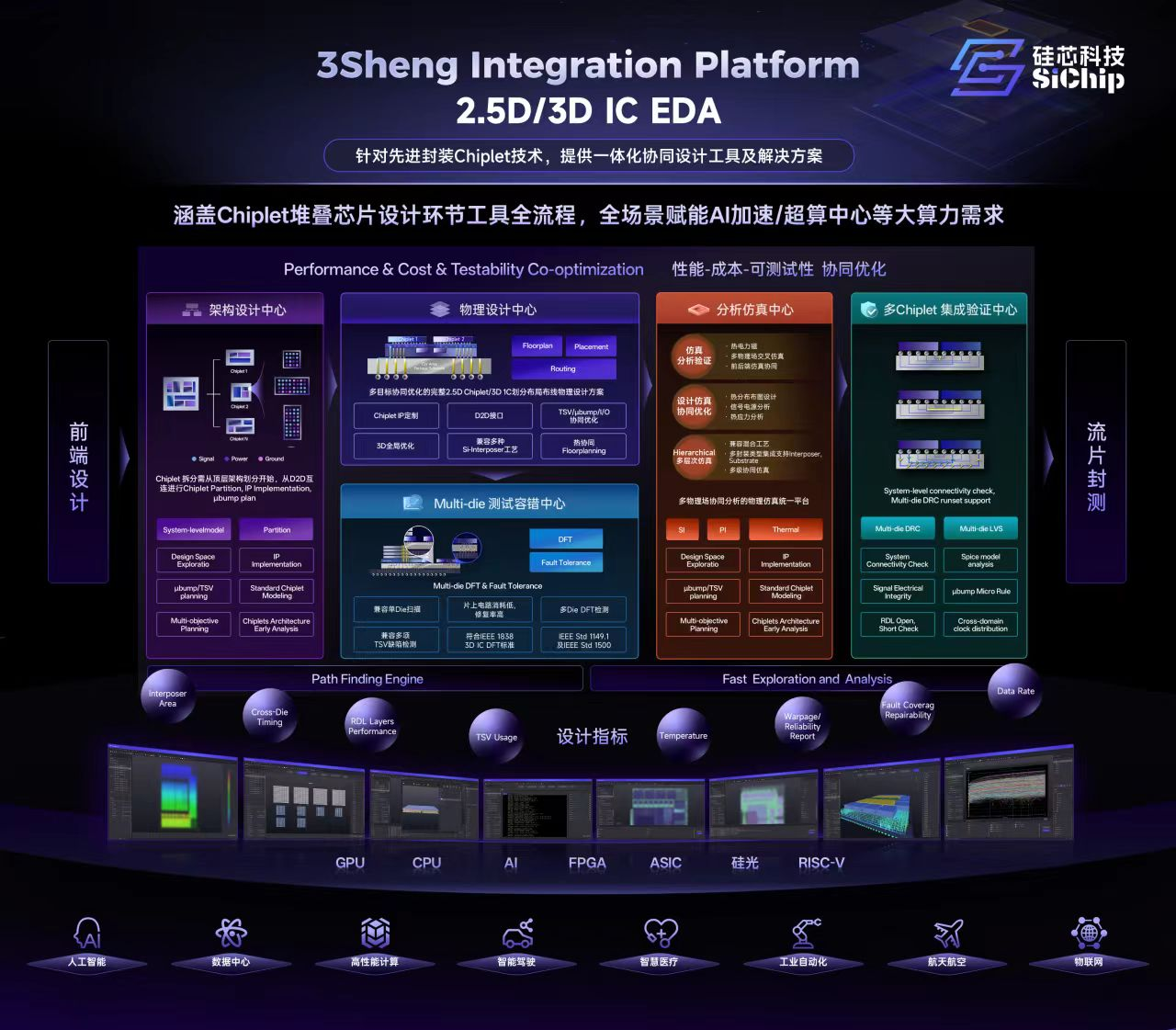
硅芯科技:AI算力突破,新型堆疊EDA工具持續(xù)進化
電子發(fā)燒友網(wǎng)報道(文/黃晶晶)先進封裝是突破算力危機的核心路徑。2.5D/3D Chiplet異構(gòu)集成可破解內(nèi)存墻、功耗墻與面積墻,但面臨多物理場分析、測試容錯等EDA設(shè)計挑戰(zhàn)。現(xiàn)有E
國產(chǎn)AI芯片真能扛住“算力內(nèi)卷”?海思昇騰的這波操作藏了多少細節(jié)?
反而壓到了310W。更有意思的是它的異構(gòu)架構(gòu):NPU+CPU+DVPP的組合,居然能同時扛住訓練和推理場景,之前做自動駕駛算法時,用它跑模型時延直接降了20%。
但疑惑也有:這種算力密
發(fā)表于 10-27 13:12
什么是AI算力模組?
未來,騰視科技將繼續(xù)深耕AI算力模組領(lǐng)域,全力推動AI邊緣計算行業(yè)的深度發(fā)展。隨著AI技術(shù)的不斷演進和物聯(lián)網(wǎng)應用的持續(xù)拓展,騰視科技的

什么是AI算力模組?
未來,騰視科技將繼續(xù)深耕AI算力模組領(lǐng)域,全力推動AI邊緣計算行業(yè)的深度發(fā)展。隨著AI技術(shù)的不斷演進和物聯(lián)網(wǎng)應用的持續(xù)拓展,騰視科技的

【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
能力
2)內(nèi)存帶寬
3)邊緣設(shè)備的AI算力
2、架構(gòu)與形態(tài)
1)AGI芯片的基本架構(gòu)
設(shè)計AGI
發(fā)表于 09-18 15:31
睿海光電領(lǐng)航AI光模塊:超快交付與全場景兼容賦能智算時代——以創(chuàng)新實力助力全球客戶構(gòu)建高效算力底座
光模塊功耗和光纖部署復雜度,同時結(jié)合優(yōu)化的前向糾錯(FCE)技術(shù),確保誤碼率低于10?12,靈敏度穩(wěn)定在-5dBm以內(nèi),充分滿足AI算力集群對長距離、低時延的嚴苛需求。
二、交付周期領(lǐng)
發(fā)表于 08-13 19:03
積算科技上線赤兔推理引擎服務(wù),創(chuàng)新解鎖FP8大模型算力
北京2025年7月30日 /美通社/ -- 近日,北京積算科技有限公司(以下簡稱"積算科技")宣布其算力服務(wù)平臺上線赤兔推理引擎。積
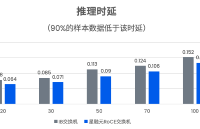
算力革命:RoCE實測推理時延比InfiniBand低30%的底層邏輯
AI 訓練與推理中的網(wǎng)絡(luò)效率瓶頸,助力數(shù)據(jù)中心在高帶寬、低延遲、高可靠性的需求下實現(xiàn)算力資源的最優(yōu)配置。
AI原生架構(gòu)升級:RAKsmart服務(wù)器在超大規(guī)模模型訓練中的算力突破
近年來,隨著千億級參數(shù)模型的崛起,AI訓練對算力的需求呈現(xiàn)指數(shù)級增長。傳統(tǒng)服務(wù)器架構(gòu)在應對分布式



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論