 分塊延遲渲染架構能否在桌面領域立足?
分塊延遲渲染架構能否在桌面領域立足?

Imagination的PowerVR GPU架構始終是高效能的代名詞。我們的IP技術在移動設備、消費電子及其他嵌入式領域奠定了聲譽,這些領域的SoC設計方案往往需要優先考慮電池續航與芯片面積。
然而在桌面市場,顯卡所需的GPU IP要求則大不相同:
高性能:主流顯卡需達到20 TFLOPS算力與300GPixel/s渲染能力方能立足;高端游戲顯卡的性能標準更為嚴苛
先進特性:超分辨率等AI增強功能漸成標配,GPU更成為生成式AI革命的關鍵推動力
軟件兼容:必須通過硬件級DirectX支持流暢運行Windows平臺游戲
能效控制:即便在桌面領域,能效同樣至關重要,用戶期待低散熱、靜音運行的設備。
近年來,Imagination通過增加主GPU核心內處理單元數量,結合領先的多核擴展技術,已助力桌面領域客戶實現主流級性能目標。
我們常被問及:在長期被即時渲染架構(IMR)主導的桌面領域,分塊延遲渲染架構(TBDR)是否真的能勝任?
答案是肯定的。事實上這兩種架構風格的差異并不如想象中巨大。接下來我們將深入解析其實現原理。
回歸基礎:傳統3D渲染的簡化數據流
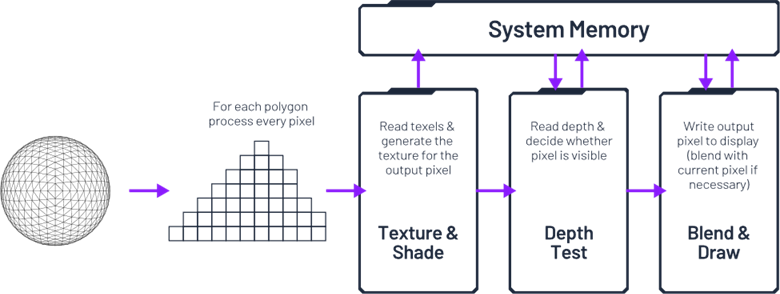
在3D圖形處理中,每個提交給渲染器的對象都會在下一個對象被處理之前立即完成變換、光柵化和著色。這正是“即時模式渲染(immediate mode rendering)”這一名稱的由來。
當然,在3D場景中,遠離攝像機的物體可能(完全或部分)被前景物體遮擋。如果在"紋理與著色"步驟之后才執行深度測試,那些已經處理過的像素片段很可能被更靠近攝像機的三角形/像素片段所"覆蓋重繪"。這會導致著色器執行不必要的計算工作,同時引發大量冗余(且高功耗)的數據傳輸。所有顏色和深度數據都存儲在系統內存中,處理顏色混合和深度緩沖區更新時頻繁的讀取/修改/寫入操作,將產生巨大的內存帶寬開銷,或者需要配備超大容量的L2/L3緩存。
在芯片面積和功耗限制較少的設備上,這種程度的資源浪費尚可接受,但對智能手機等資源受限的環境卻并不適用。這正是Imagination分塊延遲渲染技術展現價值的領域。
第一節:桌面系統中的分塊渲染
認識Imagination的分塊渲染技術
基于分塊延遲渲染(TBDR)架構中的分塊處理發生在渲染管線早期,具體位于幾何處理階段。該階段通過處理頂點數據,將整個場景劃分為若干稱為"圖塊"的獨立區域。這種分塊機制使得芯片內緩存可以替代高成本的系統內存往返數據傳輸。分塊技術還能優化工作負載分配——由于每個圖塊相互獨立,可在不同核心或著色單元間并行處理。與傳統即時渲染(IMR)架構按三角形處理的方式不同,這種方式可實現性能的線性擴展。另一關鍵優勢在于:每個圖塊的數據量極小,使得整個處理流程可完全在芯片內完成,每個圖塊僅需執行單次寫回操作。
Imagination GPU專屬分塊優化技術
Imagination擁有三項降低內存帶寬、實現極致功耗控制的核心分塊技術:
Imagination GPU將三角形精確歸類至對應圖塊,確保計算資源僅用于必要區域。多數廠商采用邊界框(bounding boxes)方案,因數據過量提取可能導致工作量翻倍——而采用分層圖塊劃分的GPU情況甚至更糟。
2.精準剔除(Perfect Culling)
我們擁有多項早期剔除技術專利,涵蓋微對象剔除、深度剔除等創新領域,以及傳統離屏剔除和背向三角形剔除等成熟方案。
3.幾何壓縮(Geometry Compression)
我們的GPU是唯一采用硬件級幾何壓縮技術的產品。該技術能在頂點數據(包括位置坐標、法線向量、紋理坐標等)存儲或傳輸前進行壓縮,通過減小頂點緩沖區尺寸來降低內存帶寬需求。GPU在頂點處理過程中實時執行數據壓縮,從而實現內部緩存的高效利用,減少外部內存訪問頻次。
這些技術共同保障了即使在桌面級設備上,GPU也能在提供游戲及生產力應用所需性能的同時,保持卓越能效與低噪音運行。
那么分塊渲染雖高效,其與桌面軟件的兼容性如何?主流桌面API(OpenGL與DirectX)及游戲引擎均已支持分塊渲染。基于分塊延遲渲染的管線前端(在分塊處理階段之前)與經典即時渲染架構并無差異。值得注意的是,現代即時渲染架構也已發展出自身的分塊方案:例如英偉達GPU配備分塊緩存(tiled caching)技術,AMD GPU則提供"繪制流分檔光柵化器"(Draw Stream Binning Rasterizer)。
Imagination GPU與AMD/英偉達方案的核心區別在于:即時渲染架構通過片上緩存(而非系統內存)實現其"分塊"處理。但這并非桌面客戶的障礙——我們的GPU可配置為將分塊數據與幾何數據存儲于片上內存(SRAM),從而降低延遲并減少外部DDR帶寬占用。未默認采用此設計是因它會增加芯片面積,這對嵌入式細分市場的成本敏感型合作伙伴難以接受。
本質上,分塊渲染器與即時渲染器已呈現技術融合:即時渲染器通過引入分塊機制提升能效與處理效率。因此,關于分塊渲染器軟件兼容性的挑戰已不復存在,相關歷史論斷實屬過時且具有誤導性。
Imagination 桌面級 GPU優化方案
面向嵌入式市場的經典Imagination GPU專注于面積效率,因為在嵌入式市場,GPU的芯片面積預算通常有限,也無法負擔支持幾何圖塊劃分所需的更大片上緩存。這與桌面市場不同,桌面市場普遍擁有巨大的緩存,例如AMD的Infinity Cache最高可達128MB。
在桌面市場使用Imagination GPU IP的客戶可以進行以下調整,以適應桌面環境:
允許將參數/圖塊緩沖區映射到任意內存區域(而不僅限于系統內存)。
將緩沖區限制為特定的、較小的尺寸。
啟用"智能參數管理"(SPM)功能,允許硬件刷新部分圖塊渲染數據以釋放片上參數存儲空間,代價是會降低隱藏面消除效率(例如已刷新的工作負載后續可能被其他物體遮擋)。
如有需要,可將數據溢出到系統內存。
第2節:桌面端的延遲渲染
了解Imagination的延遲渲染
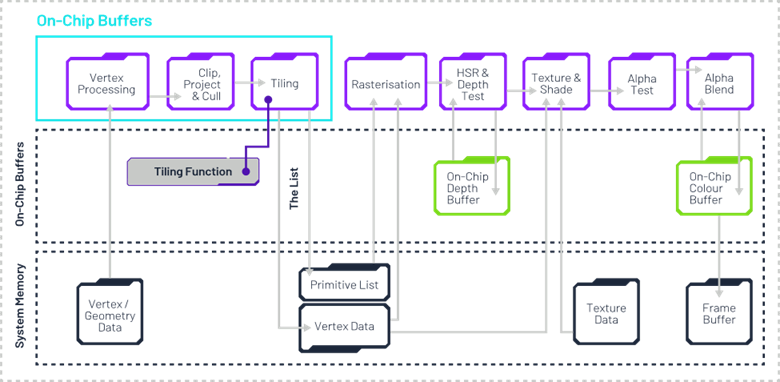
如前所述,即時渲染模式在處理場景對象時,會立即進行變換、光柵化和著色,而不會預先判斷哪些對象在屏幕上是可見的。
除了分塊技術,Imagination GPU還采用延遲渲染方案。該技術在片段處理階段初期引入深度測試,主動檢測并剔除被遮擋的三角形。完成此步驟后,渲染管線才會執行紋理貼圖與著色計算。這種"按需渲染"的技術路徑有效降低了計算負載、內存帶寬及功耗消耗。
其運作流程如下:
提取每個圖塊,僅根據位置數據對變換后的幾何體進行光柵化
隱藏面消除(HSR)階段通過片上緩沖區判定可見片段
片段處理階段負責獲取屬性與紋理數據
像素處理階段運行像素著色器代碼,實施逐像素光照等著色技術,所有混合操作均在片上圖塊內存完成,避免片外讀寫
通過將片上緩沖區數據寫入內存,逐塊完成最終3D幀渲染
延遲渲染與桌面軟件的兼容性如何?
延遲渲染對軟件完全透明,且完全符合現代API規范。采用延遲渲染方案不會造成任何功能限制,其影響僅體現在GPU內部操作層面。
究其本質,延遲渲染實質上是亂序深度計算的一種實現形式。英偉達與AMD采用的Early-Z技術正是同類方案,其他廠商類似的解決方案還包括前向像素消除(Forward Pixel Kill)、片段預渲染(Fragment Pre-Pass)等。因此亂序深度測試具有廣泛兼容性,完全不會與桌面API產生沖突。
結語:效率與性能的完美結合
正如本文所見,即時渲染模式與基于分塊的延遲渲染GPU的主要區別在于可見性測試的時機、顏色/深度數據的存儲位置以及對L2緩存的要求。在設計初衷上,基于分塊的延遲渲染GPU更側重于提升系統效率,減少芯片內部的數據移動。
但兩種渲染架構的差異并不如許多人設想的那般懸殊。現代即時渲染器已吸納分塊渲染與早期深度測試等技術來優化工作負載分配與處理效率。與此同時,Imagination的GPU IP具備充分靈活性,桌面市場客戶可根據實際需求進行針對性調整。
這些架構層面的相通之處,使得高性能分塊延遲渲染GPU成為現代桌面系統的理想選擇。無論是游戲娛樂、內容創作還是AI增強應用,Imagination GPU都為傳統即時渲染架構提供了面向未來的替代方案。
了解更多關于適用于桌面領域的Imagination GPU系列產品信息,請訪問Imagination官方網站。
英文鏈接:https://blog.imaginationtech.com/does-tile-based-deferred-rendering-have-a-place-in-desktop
聲明:本文為原創文章,轉載需注明作者、出處及原文鏈接。
-
gpu
+關注
關注
28文章
5222瀏覽量
135767 -
渲染
+關注
關注
0文章
79瀏覽量
11397 -
imagination
+關注
關注
1文章
622瀏覽量
63413
發布評論請先 登錄
昆侖天工Skywork與Google Cloud深度合作發布桌面級Agent
進迭時空 Bianbu LXQt | 全新流暢輕桌面!

探索RISC-V在機器人領域的潛力
詳解ROMA中復雜圖表的渲染實現
延遲脈沖信號發生器在激光觸發領域的應用?
從 CPU 到 GPU,渲染技術如何重塑游戲、影視與設計?

知乎開源“智能預渲染框架” 幾行代碼實現鴻蒙應用頁面“秒開”
在TR組件優化與存算一體架構中構建技術話語權
通道渲染:釋放渲染的全部潛能!通道渲染的作用、類型、技巧
無限穿墻技術西安品茶工作室南郊北郊教學簡約網絡延遲
GPU架構深度解析
明遠智睿SSD2351核心板在語音對講與HMI領域的創新應用
CPU渲染、GPU渲染、XPU渲染詳細對比:哪個渲染最快,哪個效果最好?
2D圖形渲染緩慢怎么加快?
HarmonyOS應用高負載場景分幀渲染



 工商網監
工商網監
評論