 SimData:基于aiSim的高保真虛擬數據集生成方案
SimData:基于aiSim的高保真虛擬數據集生成方案

在自動駕駛感知系統的研發過程中,模型的性能高度依賴于大規模、高質量的感知數據集。目前業界常用的數據集包括 KITTI、nuScenes、Waymo Open Dataset 等,它們為自動駕駛算法的發展奠定了重要基礎。
然而,構建真實世界的感知數據集并非易事——不僅需要投入大量人力、物力與時間成本,還需要面對數據采集受限、隱私合規、標注耗時以及極端場景難以獲取等諸多挑戰。
在此背景下,高保真虛擬數據集正成為自動駕駛感知算法研究的新方向。通過仿真平臺生成的虛擬數據,不僅能夠快速擴充數據規模,還可靈活構造復雜路況、惡劣天氣及罕見事件,為模型提供更全面的訓練樣本。
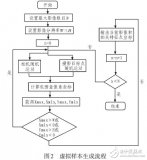
基于此,康謀推出了全新的高保真虛擬數據集——SimData。SimData依托aiSim的高精度物理建模與逼真視覺渲染能力,能夠生成多傳感器同步數據(包括相機、激光雷達、雷達、IMU 等),實現與真實世界數據一致的多模態特性。
SimData數據結構嚴格遵循nuScenes數據集格式規范,可直接使用官方nuscenes-devkit工具解析和可視化,大幅降低開發者上手成本。
本文將介紹SimData的核心特性與構建流程,并展示其在典型感知任務中的表現。SimData 正式版及相關對比測試報告將于近期發布,敬請持續關注康謀的最新動態。
02 SimData構建過程
傳感器布局
在 aiSim 仿真平臺中,我們嚴格復現了nuScenes 數據集的傳感器布局,以確保數據結構和多模態同步特性的一致性。
仿真車輛共配置了 6 路環視相機、5 個雷達(Radar)、1 個激光雷達(LiDAR)、1 個慣性測量單元(IMU)以及 1 個定位系統(GPS)。
其中,相機與雷達的采樣頻率均為 40 Hz,激光雷達的采樣頻率為 80 Hz,能夠滿足高時序精度的多傳感器同步采集需求。
各傳感器的空間布設與朝向如下圖所示:


整體視圖(左)、前視圖(右)


左視圖(左)、頂視圖(右)
與 nuScenes 不同的是,SimData中所有傳感器均采用FLU(Forward–Left–Up) 坐標系,而在 nuScenes 數據集中,相機傳感器使用的是RDF(Right–Down–Forward)坐標系。
在數據構建過程中,我們對所有標注文件進行了嚴格的坐標系轉換與對齊處理,確保坐標定義在邏輯上與 nuScenes 完全一致。
因此,用戶在使用 SimData 時,無需額外關注坐標差異,其數據解析與開發體驗與 nuScenes保持一致。下圖展示了nuScenes中各傳感器的典型布局及其坐標系定義。

數據結構
SimData 數據集在結構設計上與 nuScenes 完全保持一致。對于已經熟悉 nuScenes 的開發者而言,無需額外的適配或學習成本,即可快速上手SimData 的使用與解析。
下圖展示了 SimData 數據集的整體目錄結構,nuScenes 同樣遵循這一組織形式,以實現無縫兼容與工具級互通。

具體說明如下:

maps文件夾
存放數據集中使用到的所有高精地圖圖像文件,用于提供地理位置信息和場景背景參考。
samples文件夾
存放各類傳感器的關鍵幀數據,包括:
- 6 路攝像頭圖像(.jpg文件)
- 5 路雷達點云(.pcd文件)
- 1 路激光雷達點云(.bin文件)
其中,每隔0.5 秒抽取一幀數據作為關鍵幀進行保存。
sweeps文件夾
保存除關鍵幀以外的連續傳感器數據,用于構建時序信息和多幀融合任務。
v1.0-*文件夾
存放傳感器的標注與元數據信息,所有文件均以.json格式保存,涵蓋時間戳、姿態參數、標注標簽、場景描述等內容。
各個json標注文件的關系網絡也與nuScenes數據集保持一致,這里以nuScenes官方文件結構圖進行說明:

在 SimData 數據集中,每個文件中的信息塊均通過一個全局唯一的 UUID(Universally Unique Identifier) 作為token進行標識。
這些 token 構成了數據集中不同信息之間的關聯橋梁,用戶可通過sample.json、sample_data.json 和 sample_annotation.json三個核心文件獲取絕大多數標注與結構化信息。
sample.json
sample.json文件記錄了關鍵幀(Keyframe)的基礎信息。
- 每個關鍵幀都對應一個sample_token,用于唯一標識該幀數據。
- 通過scene_token可在scene.json文件中查找到該樣本所屬的場景。
- 文件中還提供了 前一幀 (prev) 與 后一幀 (next) 的token,可用于構建連續幀關系。
sample_data.json
利用sample_token可在sample_data.json 中獲取對應幀的多傳感器數據詳情,包括:
- ego_pose_token:車輛自車位姿的引用,可在 ego_pose.json 中獲得該時刻的位姿信息(位置與朝向)。
- calibrated_sensor_token:對應傳感器的標定參數,可在 calibrated_sensor.json 中查詢到該傳感器的內參與外參信息。
- filename:傳感器原始數據的文件路徑。若為相機數據,還包含圖像的高度(height)與寬度(width)。
- timestamp:時間戳(單位:微秒),用于多傳感器時間同步。
- is_key_frame:布爾值,指示該幀是否為關鍵幀。
- next / prev:分別指向下一幀和前一幀的 token,實現時序關聯。
sample_annotation.json
sample_annotation.json文件記錄了每個關鍵幀中檢測到的目標物體信息,可通過 sample_token 進行關聯。包含的主要字段如下:
(1)instance_token:目標實例的唯一標識。
可在 instance.json 中查詢到該實例對應的 category_token(類別信息)、首次與最后出現的關鍵幀 token。
通過 category_token 可進一步在 category.json 中獲取該實例的具體類別名稱。
(2)visibility_token:
可見度等級標識(共四級,數值越大表示可見度越高),其定義可在 visibility.json 中查閱。
(3)目標幾何與姿態信息,這些位姿均定義在傳感器坐標系下。
中心點位置 (translation)
尺寸大小 (size)
旋轉角度 (rotation),以 四元數(Quaternion) 形式存儲
(4)點云統計信息
檢測框中包含的激光雷達點數 (num_lidar_pts) 與 雷達點數 (num_radar_pts)。
(5)前后幀關聯
分別記錄該實例在前一幀與后一幀中的對應 token。
03 SimData與感知模型使用示例
使用方法與真值可視化
SimData可以直接使用nuScenes-devkit進行解析,使用方法與nuScenes數據集一致。示例:
1. from nuscenes.nuscenes import NuScenes
2. nusc = NuScenes(version='v1.0-custom', dataroot=data_path, verbose=True)
得到示例化對象后便可以使用nuScenes官方提供的工具對SimData進行分析和模型訓練。配合cv2或matplotlib可以對數據集進行可視化:
具有gt框的六路攝像頭輸出:
同步lidar點云,可以同時繪制出bev視角下的標注信息


bevformer檢測效果展示
以下是使用在nuScenes數據集下訓練的權重,采用bevformer-tiny模型直接進行檢測的效果(即沒有在SimData上進行訓練)。
1. bevformer官方代碼庫:https://github.com/fundamentalvision/BEVFormer/tree/master
2. bevformer論文:https://arxiv.org/pdf/2203.17270
04 總結
本文闡述了虛擬數據集在自動駕駛感知研究中的重要性,并介紹了基于aiSim仿真平臺生成的高保真虛擬感知數據集——SimData。
文章詳細說明了 SimData 的數據組成結構與使用方法,并利用開源感知模型對其進行了檢測驗證,從而驗證了數據集的可用性與有效性。
后續,康謀團隊將發布更為詳盡的測試與對比報告,以進一步驗證SimData與真實數據集之間的高一致性。通過這一系列工作,我們不僅證明了aiSim仿真環境的高保真特性,也為研究者與開發者提供了一個高質量、易用且可擴展的虛擬感知數據資源,以持續助力自動駕駛感知算法的研究與訓練。
-
數據采集
+關注
關注
40文章
7699瀏覽量
119650 -
激光雷達
+關注
關注
977文章
4365瀏覽量
195138 -
自動駕駛
+關注
關注
791文章
14641瀏覽量
175790
發布評論請先 登錄
高保真揚聲器系統設計的探索
主動降噪、高保真藍牙耳機解決方案

什么是高保真耳機
![[圖文]<b class='flag-5'>高保真</b>調頻調諧器](https://file1.elecfans.com//web2/M00/A4/33/wKgZomUMMx-ACzWzAAGeyClUIeA060.jpg)
高保真音響實用全書

基于Python-casacore的射電測量集文件生成方法






 工商網監
工商網監
評論