 NVIDIA Omniverse USD插件開發中的UI卡頓問題復現及分析
NVIDIA Omniverse USD插件開發中的UI卡頓問題復現及分析

UI 卡頓問題復現及分析
在進行 NVIDIA Omniverse USD 插件開發的時候遇到了一個性能卡頓的問題,這個功能的初衷是通過路徑追蹤和原始的綠幕視頻,借助 Omniverse Farm 來實現高質量的后期自動化流程,實現思路是記錄相機定位 FreeD 的運動軌跡,并記錄保存到一個 USD 的 sublayer 當中,根據時間碼(Timecode)進行后期自動化合成的流程,流程圖如下:
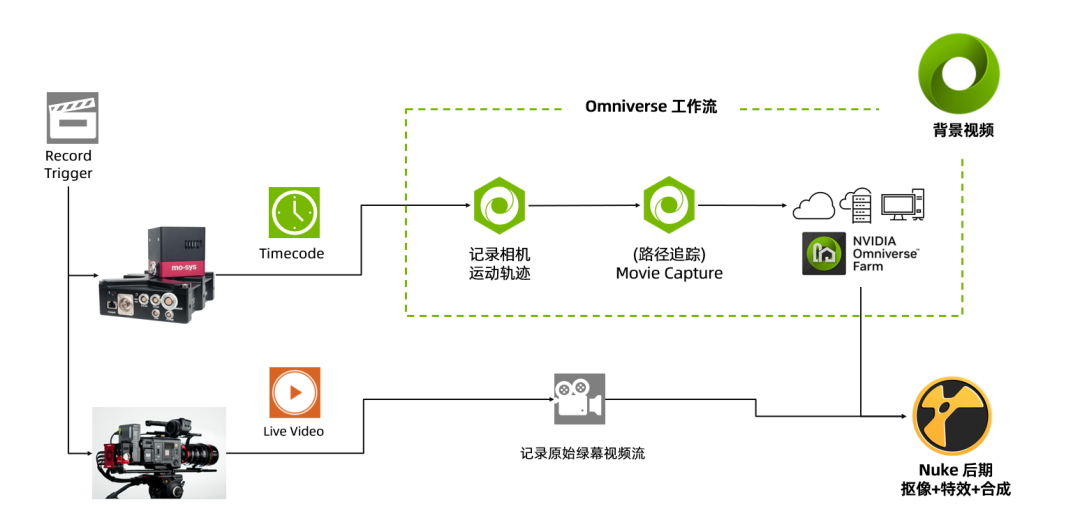
在外部攝影機記錄原始的綠幕影片素材的時候,點擊開始 / 結束分別會觸發一個時間碼 (Timecode)的信號,信號可以在 BMD 采集卡當中通過 SDK 獲得,這樣我們把從開始到結束的相機定位軌跡記錄存至 buffer 中,然后更新到 USD 的 stage sublayer 中。
首先通過 Python API 創建一個 Sublayer,把記錄的 sequence 通過 USD time sampler 記錄到相機 prim 的 attribute 下面,僅對一萬個 time sampler 進行記錄并統一寫入該 sublayer,后觀察到該寫入過程耗時達數十秒,且造成 Omniverse 主線程 UI 出現卡頓。經測試,無論采用同步、異步 AsyncIO 或線程方式執行操作,均未使情況得到改善,UI 卡死現象始終存在。(可以查看代碼文件中注釋的 1、2、3)
Tracy.py 的源代碼如下:
importomni.kit.app importtime importasyncio frompxrimportSdf, Usd, UsdGeom, Gf fromomni.kit.usd.layersimportLayerUtils, get_layers, LayerEditMode importomni.kit.commands fromcollectionsimportdeque importos fromtypingimportList,Tuple fromomni.kit.widget.layers.path_utilsimportPathUtils importcarb fromtypingimportList,Tuple fromenumimportEnum importasyncio frompxrimportSdf, Usd, UsdGeom frompxrimportUsd, UsdGeom, Gf fromomni.kit.async_engineimportrun_coroutine fromconcurrent.futuresimportALL_COMPLETED, ThreadPoolExecutor, wait defcreate_prim(stage, prim_path="/World/Camera"): prim = stage.GetPrimAtPath(prim_path) ifprimandprim.GetTypeName() =="Camera": carb.log_info(f"Camera already exists at:{prim_path}") returnprim else: camera_prim = UsdGeom.Camera.Define(stage, prim_path) camera_prim.AddTranslateOp().Set(Gf.Vec3d(10,20,30)) camera_prim.AddRotateXYZOp().Set(Gf.Vec3f(0,45,0)) carb.log_info(f"Created new Camera at:{prim_path}") returncamera_prim.GetPrim() classTestClass: def__init__(self): self._rotate_queue = deque() self._translate_queue = deque() self._pts_queue = deque() self._pts =0 self._Layer_num =0 defcreate_sublayer(self, _root_layer, strLayerName, orderIndex, bSetAuthoring): #layname = self._Layer_num +=1 identifier1 = LayerUtils.create_sublayer(_root_layer, orderIndex, strLayerName).identifier # ifbSetAuthoring: omni.kit.commands.execute("SetEditTargetCommand", layer_identifier=identifier1) defprepare_data(self): begin = time.time() rotation_1 = Gf.Vec3f(0.0,0.0,0.0) _translate = Gf.Vec3d(0.0,0.0,0.0) for_inrange(10000): self._rotate_queue.append(rotation_1) self._translate_queue.append(_translate) end = time.time() carb.log_info(f"prepare_data elaspe:{end - begin}") asyncdefawait_flush_save(self): carb.log_info("before await_flush_save {time.time()}") awaitomni.kit.app.get_app().next_update_async() self.flush_save() carb.log_info("end await_flush_save {time.time()}") defflush_save(self): timecode =0 whileself._rotate_queueorself._translate_queue: ifself._rotate_queue: f_val = self._rotate_queue.popleft() self._rotation_ops.Set(time = timecode, value = f_val) ifself._translate_queue: d_val = self._translate_queue.popleft() self._translate_ops.Set(time = timecode, value = d_val) timecode +=10 self._render_update_sub =None asyncdefawaitflush(self): awaitomni.kit.app.get_app().next_update_async() self.flush_save(self) asyncdefflush_save_async(self): time0 = time.perf_counter() carb.log_info("flush_save_async begin") loop = asyncio.get_running_loop() # 直接調用同步函數(主線程),但用await asyncio.sleep(0)切分事件循環 awaitloop.run_in_executor(None, self.flush_save) time1 = time.perf_counter() carb.log_info(f"flush_save_async end elaspe:{time1 - time0}") definit_stage_camera(self, stage, camera_prim_path): self._stage = stage self._camera_path = camera_prim_path self._camera_prim = UsdGeom.Camera.Get(stage, camera_prim_path).GetPrim() xform_ops = UsdGeom.Xformable(self._camera_prim).GetOrderedXformOps() foropinxform_ops: ifop.GetOpType()in[UsdGeom.XformOp.TypeRotateXYZ, UsdGeom.XformOp.TypeRotateXZY, UsdGeom.XformOp.TypeRotateYXZ, UsdGeom.XformOp.TypeRotateYZX, UsdGeom.XformOp.TypeRotateZXY, UsdGeom.XformOp.TypeRotateZYX]: #rotation = op.Get() self._rotation_type = op.GetOpType() self._rotation_ops = op #print(f"rotation is {rotation}") elifop.GetOpType() == UsdGeom.XformOp.TypeScale: self._scale_ops = op elifop.GetOpType() == UsdGeom.XformOp.TypeTranslate: self._translate_ops = op if__name__ =="__main__": _stage = omni.usd.get_context().get_stage() root_layer = _stage.GetRootLayer() prim_path ="/World/Camera" new_layer_path ="d:/camera_sublayer.usd" runclass = TestClass() create_prim(_stage, prim_path) runclass.init_stage_camera(_stage, prim_path) runclass.create_sublayer(root_layer, new_layer_path,0,True) runclass.prepare_data() begin = time.time() carb.log_info(f"before run coroutine") #(1)Async block UI for about 50 seconds run_coroutine(runclass.await_flush_save()) #(2)Also block UI about 50 seconds # with ThreadPoolExecutor() as executor: # executor.submit(runclass.flush_save()) #(3)Sync, same block #self.flush_save() end = time.time() carb.log_info(f"elaspe time is{end-begin}, 10000 ends")
* 附代碼鏈接:https://github.com/slayersong/OVPerf_Tracy/blob/main/tracy_profiler.py(復制鏈接至瀏覽器打開)
復現問題:打開菜單中的Developer --Script Editor,打開 tray_profiler.py 文件,然后點擊 Run,可以看到創建了一個 camera_sublayer,并且主 UI 卡住了幾十秒無響應。
需要注意的是,在 Omniverse USD 的 layer 層級繼承覆蓋當中,在上層的 Layer 的行為會覆蓋下層的 layer,關于 USD layer 層級的關系,請查看本文結尾提供的 DLI 課程鏈接。
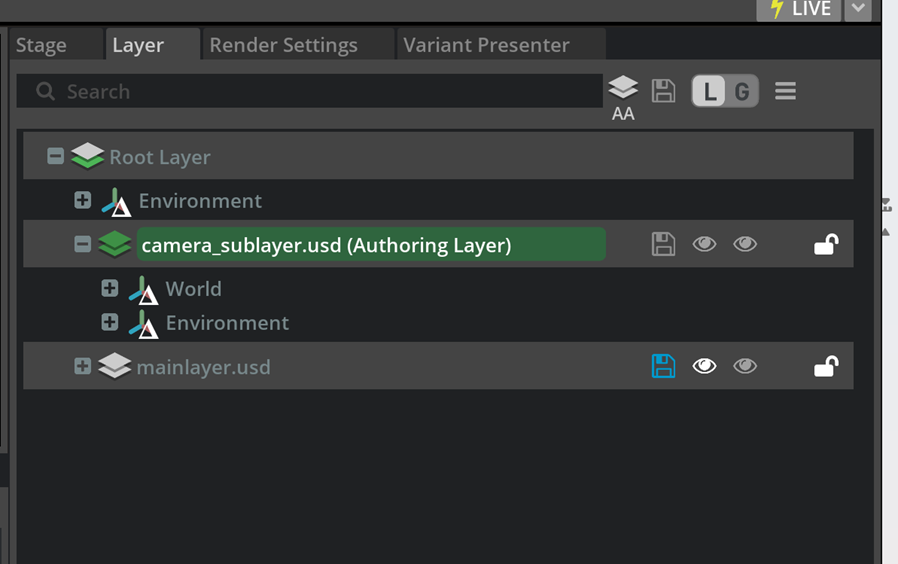
然后在 Content Browser 中單擊鼠標右鍵,選擇 Edit,可以看到數據成功寫入了 USD 文件,只是中間卡頓的時間過長。
分析:在遇到 Profiler 的時候不要盲猜,可能是 memory、IO Bound、Compute Bound 或者一些不太能想到的情況,這時候則需要利用專業化的工具進行分析定位,找到問題所在并解決,比如可以利用著名工具Tracy(https://github.com/wolfpld/tracy),該工具可以分析 CPU / GPU 性能瓶頸,并支持主流 Graphics API:DX、Vulkan、OpenGL、CUDA 等,且 Omniverse 已經把該工具與 Omniverse Kit 進行了集成。因此可以利用 Tracy 去看底層的 CallStack 里什么影響了這個操作,在 Omniverse 當中,Tracy 已經配置好了 Symbol 符號表, 可以看到底層的代碼函數調用堆棧,后而尋找具體是什么情況卡住了不正常的幾十秒時間。
Tracy 的使用
2.1 操作介紹
Omniverse 已經集成了 Tracy 的開發集成插件:https://docs.omniverse.nvidia.com/extensions/latest/ext_profiler_tracy.html
Tracy 本身是一個著名的分析工具,具體的菜單操作可以參考知乎這個帖子:https://zhuanlan.zhihu.com/p/1915041165033607442
UI 操作的詳細講解可參考如下視頻:
Tracy 講解文檔
視頻參考:
https://www.bilibili.com/video/BV1or421J7Du/?spm_id_from=333.337.search-card.all.click
文檔參考:
https://github.com/CppCon/CppCon2023/blob/main/Presentations/Tracy_Profiler_2024.pdf
2.2 安裝
首先打開菜單 Developer -- Extension 搜索,找到 Profiler Tracy 并且安裝。
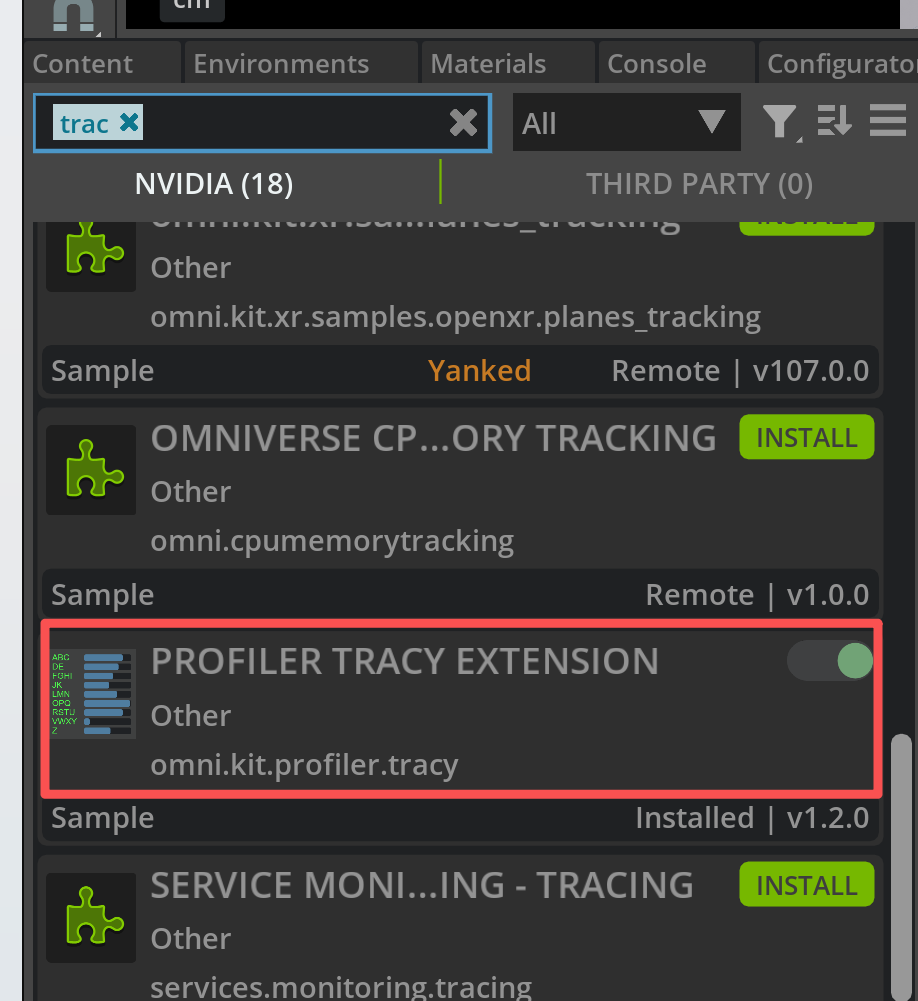
然后會出現一個新的 Profiler 菜單,點擊 Profiler --Tracy --Launch and Connect。
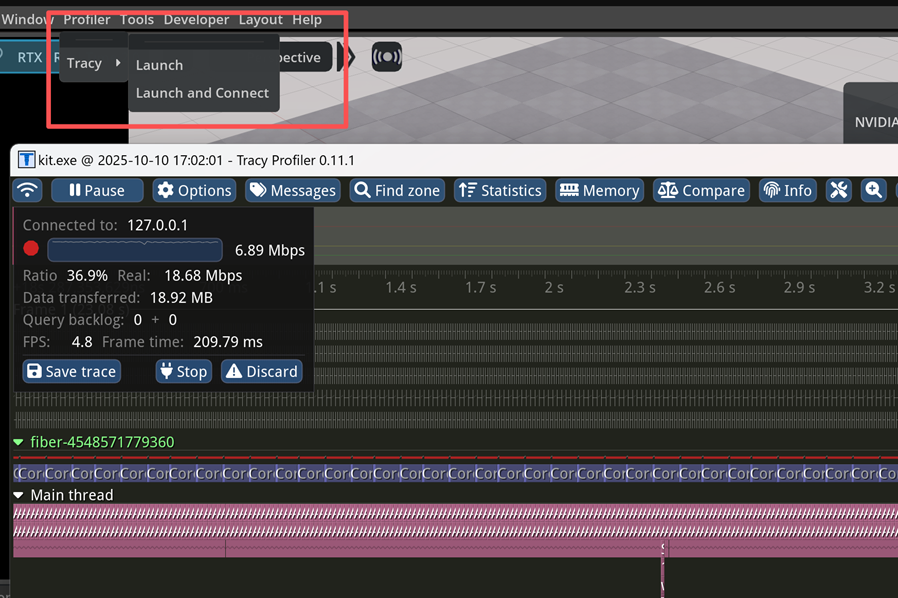
Tracy 基本使用操作:
1. Pause:在實時監測到發生性能瓶頸的事件以后要暫停,否則時間軸會一直向右走
2. 按住鼠標右鍵可以拖動到你想要的位置
3. 鼠標滾輪:Zoom in / out
2.3 分析問題
運行上述代碼,點擊 Tracy 中的 Pause 暫停(不暫停 Tracy 會一直記錄的一直滾動)。之后按住 Ctrl 和鼠標中間的滾輪,Zoom 縮小操作,可以很容易找到一個最大的耗時,從 11 秒開始到 31 秒,這一個 Frame Render 用了二十幾秒(注意:函數的調用堆棧已經正確顯示),可以發現卡在了 RenderThread 中的usd_mutex_wait函數上面:
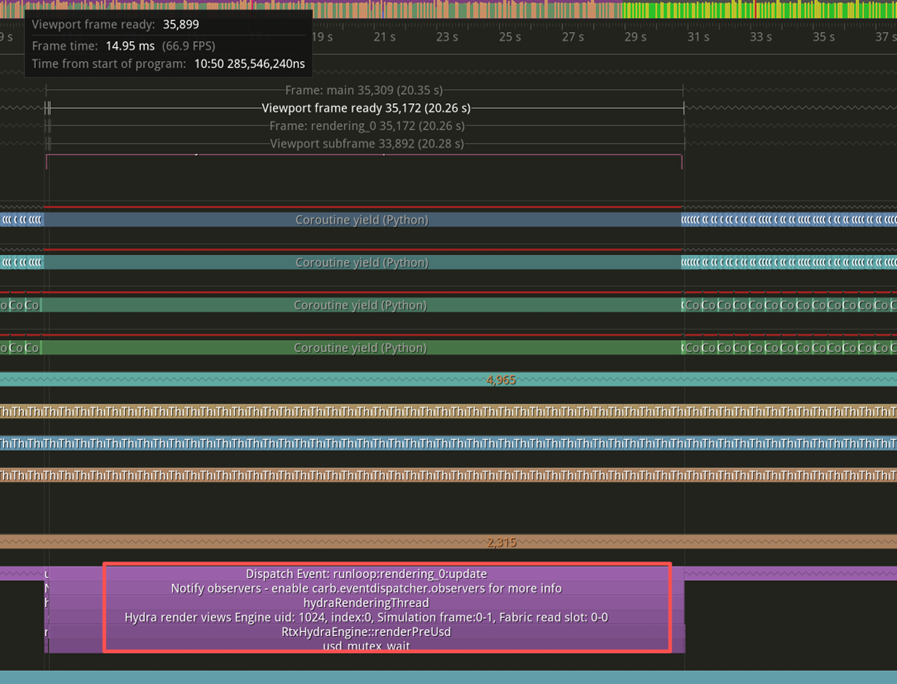
這樣通過 Tracy 的使用就明白了問題卡住的大致原因,簡而言之,渲染線程會等待 USD 寫入的結束,一直卡在usd_mutex_wait。
2.4 解決問題
分析:該問題的本質其實是 USD 的寫入與修改會非常的慢,這是 USD 的基礎架構造成的。
單單針對這個問題解決的方法不復雜,可以思考一下,寫入的 Sublayer 其實并不需要實時參與 USD Composite, 因為我們并不需要實時觀察到合成結果,可以創建離線的 Sublayer ,等待寫入結束以后再自動或者手動把 Sublayer 加入進來,代碼如下,看到并沒有卡頓這一個過程,那么問題就解決了。
針對此次問題的 Solution 如下:
importomni.kit.app
importtime
importasyncio
frompxrimportSdf, Usd, UsdGeom, Gf
fromomni.kit.usd.layersimportLayerUtils, get_layers, LayerEditMode
importomni.kit.commands
fromcollectionsimportdeque
importos
fromtypingimportList,Tuple
fromomni.kit.widget.layers.path_utilsimportPathUtils
importcarb
fromtypingimportList,Tuple
fromenumimportEnum
importasyncio
frompxrimportSdf, Usd, UsdGeom
frompxrimportUsd, UsdGeom, Gf
fromomni.kit.async_engineimportrun_coroutine
fromconcurrent.futuresimportALL_COMPLETED, ThreadPoolExecutor, wait
defcreate_prim(stage, prim_path="/World/Camera"):
prim = stage.GetPrimAtPath(prim_path)
ifprimandprim.GetTypeName() =="Camera":
carb.log_info(f"Camera already exists at:{prim_path}")
returnprim
else:
camera_prim = UsdGeom.Camera.Define(stage, prim_path)
camera_prim.AddTranslateOp().Set(Gf.Vec3d(10,20,30))
camera_prim.AddRotateXYZOp().Set(Gf.Vec3f(0,45,0))
carb.log_info(f"Created new Camera at:{prim_path}")
returncamera_prim.GetPrim()
classTestClass:
def__init__(self):
self._rotate_queue = deque()
self._translate_queue = deque()
self._pts_queue = deque()
self._pts =0
defregis(self):
self._app = omni.kit.app.get_app()
self._render_update_sub = self._app.get_update_event_stream().create_subscription_to_pop(
self.pre_frame_render, order=-10, name="gm_render_event")
defpre_frame_render(self,e):
self._pts +=1
self.get_push_pos_rotate(self._pts)
ifself._pts ==1000:
begin = time.time()
carb.log_info(f"before run coroutine")
run_coroutine(self.await_flush_save())
#self.flush_save()
carb.log_info(f"end run coroutine")
end = time.time()
carb.log_info(f"elaspe time is{end-begin}")
self._render_update_sub =None
defget_push_pos_rotate(self, pts):
rotae = self._rotation_ops.Get()
translate = self._translate_ops.Get()
self._rotate_queue.append(rotae)
self._translate_queue.append(translate)
self._pts_queue.append(pts)
defprepare_data(self):
begin = time.time()
rotation_1 = Gf.Vec3f(0.0,0.0,0.0)
_translate = Gf.Vec3d(0.0,0.0,0.0)
foriinrange(500):
# rotation_1 = Gf.Vec3f(0.0, 0.0, 0.0)
# _translate = Gf.Vec3d(0.0, 0.0, 0.0)
rotation_1 = Gf.Vec3f(-253.0, i * (360.0/499),93) # 99是為了最后一次達到360
# _translate的xyz從0遞增到100
_translate = Gf.Vec3d(2124.0, 2124.0, 104)
self._rotate_queue.append(rotation_1)
self._translate_queue.append(_translate)
end = time.time()
carb.log_info(f"prepare_data elaspe:{end - begin}")
asyncdefawait_flush_save(self):
carb.log_info("before await_flush_save {time.time()}")
awaitomni.kit.app.get_app().next_update_async()
self.flush_save()
carb.log_info("end await_flush_save {time.time()}")
defflush_save(self):
timecode =0
whileself._rotate_queueorself._translate_queue:
ifself._rotate_queue:
f_val = self._rotate_queue.popleft()
#self._rotation_ops.Set(time = timecode, value = f_val)
self.seq_write_rotate_op.Set(time = timecode, value = f_val)
ifself._translate_queue:
d_val = self._translate_queue.popleft()
self.seq_write_translate_op.Set(time = timecode, value = d_val)
#self._translate_ops.Set(time = timecode, value = d_val)
timecode +=10
self._sub_stage.GetRootLayer().Save()
self._render_update_sub =None
asyncdefawaitflush(self):
awaitomni.kit.app.get_app().next_update_async()
self.flush_save(self)
asyncdefflush_save_async(self):
time0 = time.perf_counter()
carb.log_info("flush_save_async begin")
loop = asyncio.get_running_loop()
# 直接調用同步函數(主線程),但用await asyncio.sleep(0)切分事件循環
awaitloop.run_in_executor(None, self.flush_save)
time1 = time.perf_counter()
carb.log_info(f"flush_save_async end elaspe:{time1 - time0}")
defcreate_offline_layer(self, layer_base_path, prim_path, bOverride):
# split name and ext
name, ext = os.path.splitext(layer_base_path)
index =1
new_layer_path = layer_base_path
#If exist create a new path such as basepath_1.usd
whileos.path.exists(new_layer_path):
new_layer_path =f"{name}_{index}{ext}"
index +=1
new_layer = Sdf.Layer.CreateNew(new_layer_path)
# 2. 打開該layer對應的Stage(編輯該layer)
self._sub_stage = Usd.Stage.Open(new_layer)
# 3. 以over方式定義相機Prim(覆蓋已有的/world/Camera)
ifbOverride:
self._seq_camera_prim = self._sub_stage.OverridePrim(prim_path)
self._seq_camera_prim.SetSpecifier(Sdf.SpecifierOver)
else:
self._seq_camera_prim = self._sub_stage.DefinePrim(prim_path)
# 4. 獲取或創建Xformable接口,用于添加變換操作
xformable = UsdGeom.Xformable(self._seq_camera_prim)
# 5. 添加translate和rotateXYZ操作
self.seq_write_translate_op = xformable.AddTranslateOp()
self.seq_write_rotate_op = xformable.AddRotateXYZOp()
definit_stage_camera(self, stage, camera_prim_path):
self._stage = stage
self._camera_path = camera_prim_path
self._camera_prim = UsdGeom.Camera.Get(stage, camera_prim_path).GetPrim()
xform_ops = UsdGeom.Xformable(self._camera_prim).GetOrderedXformOps()
foropinxform_ops:
ifop.GetOpType()in[UsdGeom.XformOp.TypeRotateXYZ,
UsdGeom.XformOp.TypeRotateXZY,
UsdGeom.XformOp.TypeRotateYXZ,
UsdGeom.XformOp.TypeRotateYZX,
UsdGeom.XformOp.TypeRotateZXY,
UsdGeom.XformOp.TypeRotateZYX]:
#rotation = op.Get()
self._rotation_type = op.GetOpType()
self._rotation_ops = op
#print(f"rotation is {rotation}")
elifop.GetOpType() == UsdGeom.XformOp.TypeScale:
self._scale_ops = op
elifop.GetOpType() == UsdGeom.XformOp.TypeTranslate:
self._translate_ops = op
if__name__ =="__main__":
_stage = omni.usd.get_context().get_stage()
prim_path ="/World/Camera"
new_layer_path ="d:\tes303.usda"
runclass = TestClass()
create_prim(_stage, prim_path)
runclass.init_stage_camera(_stage, prim_path)
runclass.create_offline_layer(new_layer_path, prim_path,True)
carb.log_info("create_offline_layer after")
#runclass.regis()
runclass.prepare_data()
begin = time.time()
carb.log_info(f"before run coroutine")
run_coroutine(runclass.flush_save_async())
#run_coroutine(runclass.await_flush_save())
#runclass.flush_save()
carb.log_info(f"end run coroutine")
#runclass.flush_save()
# with ThreadPoolExecutor() as executor:
# executor.submit(runclass.flush_save())
end = time.time()
carb.log_info(f"elaspe time is{end-begin}, 1000 ends")
# class YourClass:
# def __init__(self):
# # 初始化隊列等
# pass
# def flush_save(self):
# # 這是同步函數,不能改動
# # 里面調用了Omniverse API,必須在主線程執行
# print("Begin flush save")
# time.sleep(1)
# print("end flush save")
# async def flush_save_async(self):
# time0 = time.perf_counter()
# print("run task begin")
# loop = asyncio.get_running_loop()
# # 直接調用同步函數(主線程),但用await asyncio.sleep(0)切分事件循環
# await loop.run_in_executor(None, self.flush_save)
# time1 = time.perf_counter()
# print(f"run task end elaspe:{time1 - time0}")
# async def testawait():
# pass
# # obj = YourClass()
# # run_coroutine(obj.flush_save_async())
# # print(f"run pass the async")
# # count = 0
# # def pre_frame_render(e):
# # #print(f"Frame Begin: {app.get_update_number()} {e.payload}, event-type {e.type}, {time.time() * 1000 % 1000000} ")
# # asyncio.ensure_future(obj.flush_save_async())
# # async def run_task():
# # time0 = time.perf_counter()
# # print("run task begin")
# # await obj.flush_save_async()
# # print("run task end")
# # time1 = time.perf_counter()
# # elapse_time = time1 - time0
# # print(f"run taks elapse is {elapse_time}")
# # def frame_render(e):
# # print(f"Frame Render: {app.get_update_number()} {e.payload}, event-type {e.type}, {time.time() * 1000 % 1000000}")
# # def post_frame_render(e):
# # print(f"Frame End: {app.get_update_number()} {e.payload}, event-type {e.type}, {time.time() * 1000 % 1000000}")
# first_last_event = 1000000
# # pre_update_sub = app.get_pre_update_event_stream().create_subscription_to_pop(
# # pre_frame_render, order=-first_last_event, name="gm_frame_begin")
# #asyncio.ensure_future(obj.flush_save_async())
* 附代碼鏈接:https://github.com/slayersong/OVPerf_Tracy/blob/main/solution_%20tracy_profiler.py
但是在一些項目當中一定要實時觀察到結果。比如,有很多的數字孿生的工業場景中會存在小車傳送帶,各種物品都是實時進入到場景管線當中,這其中必定要參與 USD 合成。
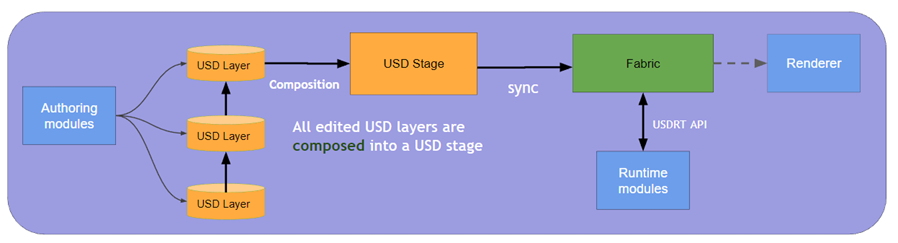
所以這里介紹一個 Omniverse 對 USD 進行重構的基本概念 Fabric,USDRT(USDRT 是 Fabric 的 API),NVIDIA 在 Omniverse 當中開發了 Fabric 組件專門處理 USD 實時更改緩慢的問題:
https://docs.omniverse.nvidia.com/kit/docs/usdrt/latest/docs/usd_fabric_usdrt.html
通過這個官方文檔的圖也驗證了剛才的結論:Render 線程會等待 USD 的合成結果 Composed 后進行渲染。
結束:如果單解決這個問題其實并不復雜,但是其中需要用到很多的基礎知識,包括 USD 的合成機制、多線程開發、遇到問題如何去利用工具定位分析等。后面我們將會對 USDRT 與 Fabric 進行更細致的講解,包括代碼的開發使用和 Omniverse 中其他性能工具的使用教程。也希望更多的朋友可以分享在 USD 開發過程當中的心得體會。
附錄:
關于前面提到的 USD 的基本開發教程,包括 USD 合成機制,USD 基本動畫 TimeSampler 等:
文案提供和技術支持:
宋毅明
NVIDIA Omniverse & OpenUSD 開發者關系經理
*與 NVIDIA 產品相關的圖片或視頻(完整或部分)的版權均歸 NVIDIA Corporation 所有。
-
NVIDIA
+關注
關注
14文章
5667瀏覽量
109985 -
攝影機
+關注
關注
0文章
75瀏覽量
10951 -
插件
+關注
關注
0文章
345瀏覽量
23612
原文標題:Omniverse 性能優化系列(一):Tracy Profiler
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Labview卡頓、UI無法刷新
NVIDIA透露即將發布的Blender 3.0中將包括USD支持
NVIDIA將NVIDIA Omniverse帶給全球超過250萬的開發者
利用NVIDIA Omniverse加速游戲開發管線
NVIDIA SIGGRAPH的最新發布與重要更新
Omniverse 中文課程系列 1: 開發 Extensions 來自定義 Omniverse 功能與 UI

奧比中光將接入 NVIDIA Omniverse開發平臺
Omniverse 中文課程系列 2:USD 入門、基礎與進階 — 賦能協同 3D 工作流

Omniverse 中文課程系列 3:實戰練習如何成為自定義 UI 界面大師

NVIDIA 知乎精彩問答甄選 | 查看 NVIDIA Omniverse 相關精彩問答

SIGGRAPH 2023 | NVIDIA Omniverse 開啟通往 OpenUSD 廣闊天地的大門
NVIDIA Omniverse中的物理模擬功能

NVIDIA Omniverse USD Composer能用來做什么?如何獲取呢?
Omniverse教程(12):NVIDIA Omniverse USD Presenter的基礎應用



 工商網監
工商網監
評論