 CVPR 2018 上10篇最酷論文,渴望進步的人都在看
CVPR 2018 上10篇最酷論文,渴望進步的人都在看

▌前言
作為計算機視覺領域的頂級會議,2018年的計算機視覺和模式識別會議(CVPR) 上周在美國鹽湖城舉行。今年的 CVPR共收到3300份來稿并接收了其中的979份。超過6500人參加了今年的會議,這間容納6500人的房間座無虛席,堪稱是一屆史詩般的盛會:
每年的 CVPR都會吸引眾多優秀的人才和他們最新的研究成果,總可以看到學到新的東西。當然還有那些發表了最新并具有突破性成果的論文,為該領域帶來很棒的新知識。這些論文經常在計算機視覺的許多子領域形成最新的技術。
最近,我們看到了一些開箱即用且富有創意的論文!隨著最近深度學習在計算機視覺領域的突破性進展,我們仍然在探索并發現一切未知的可能性。許多論文展示了深度神經網絡在計算機視覺領域中的全新應用。它們可能不是最根本的開創性作品,但就它們從新穎有趣的角度呈現出全新的想法,為相關領域提供了創造性和啟發性的視角。總而言之,這些都是非常酷的作品!
在這里,我將展示我認為在本屆 CVPR上最酷的10篇論文。我們將看到最近使用深度網絡實現的一些新應用,以及如何進一步使用它們。你可以在閱讀過程中根據自己的喜好選擇性地進行閱讀。讓我們開始吧!
▌Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization(用合成數據訓練深度網絡:通過領域隨機化來彌合現實差距)
這篇論文出自Nvidia團隊的研究,使用合成數據來訓練卷積神經網絡(CNN)。 他們為虛幻引擎(Unreal Engine 4) 創建了一個插件用于生成合成的訓練數據。這項研究的關鍵在于他們對訓練數據進行了隨機化,使其能夠包含多種變量,包括:
目標的數量和類型
干擾物的數量,類型,顏色和尺度
感興趣物體的紋理特征及圖片的背景
虛擬攝像機相對于場景的位置
相機相對于場景的角度
光點的數量和位置
他們展示了一些非常有前途的實驗結果,證明了合成數據預訓練的有效性,這是先前研究從未實現過的結果。如果你之前并不了解這個重要知識的話,那么這項研究將會啟發你如何生成并使用合成數據。
▌WESPE: Weakly Supervised Photo Enhancer for Digital?Cameras(WESPE:用于數碼相機的弱監督照片增強器)
這項研究通過訓練生成對抗網絡(GAN) 來從美學上自動化增強圖片。該研究最酷的地方在于以一種弱監督的方式:你不需要輸入-輸出的圖像對。訓練網絡時,你只需要一組“好看”的圖像(用于輸出基礎事實) 和一組想要增強的“不好看”的圖像(用于輸入圖像)。然后,通過訓練GAN產生輸入圖像的增強版本,通常所生成的圖像會極大地增強原圖像的顏色和對比度。
由于不需要精確的圖像對,因而你能夠快捷方便地使用這個圖像增強器。我喜歡這項研究的原因主要是因為它是一種弱監督的方法。雖然我們離無監督學習似乎還很遙遠,但對計算機視覺的許多子領域而言,弱監督學習似乎是一個充滿希望且值得研究的方向。
▌Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++(用Polygon-RNN ++對圖像分割數據集進行高效地交互式標注)
深度神經網絡之所以能夠表現出如此強大性能的主要原因之一是大型且完全帶標注的可用的數據集。然而,對于許多計算機視覺任務而言,這樣的數據既費時又昂貴。特別對于圖像分割任務而言,我們需要對圖像中的每個像素進行類別標注,你可以想象其中的困難性有多大!
Polygon-RNN ++這項研究允許研究者只需在圖像中每個目標周圍設置粗糙的多邊形點,然后該網絡能夠自動生成圖像分割所需的標注信息!本文研究表明這種方法能夠在實際應用中很好地推廣,并可以用來為分段任務創建快速簡便的數據標注!
▌Creating Capsule Wardrobes from Fashion?Images
(從時尚配圖中創造自己的衣柜)
“嗯,我今天應該穿什么?”如果有人能夠每天早上為你解決這個問題,那將再好不過了。
本文研究中,作者設計了一種模型,基于給定的候選服裝和配件清單,模型通過收集一組最小的項目集,提供最全面的服裝混合搭配的方案。研究中模型使用目標函數進行訓練,這些目標函數旨在捕獲視覺兼容性,多功能性及特定用戶的偏好等關鍵要素。有了這種衣柜 (Capsule Wardrobes),你可以輕松從衣櫥中挑選最佳的服裝搭配。
▌Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation (Super SloMo:視頻插值中多個中間幀的高質量估計)
你曾經是否想過以超慢的動作拍攝超級酷炫的東西呢?Nvdia的這項研究 Super SloMo就能幫你實現!研究中他們使用 CNN估計視頻的中間幀,并能將標準的30fps視頻轉換為240fps的慢動作!該模型估計視頻中間幀之間的光流信息,并在這些信息中間插入視頻幀,使慢動作的視頻看起來也能清晰銳利。
▌Who Let The Dogs Out? Modeling Dog Behavior From Visual?Data(用視覺數據構建狗的行為模型)
這可能是有史以來最酷的研究論文!這項研究的想法是試圖模擬狗的思想和行為。研究人員將許多傳感器連接到狗的四肢以收集其運動和行為數據;。此外,他們還在狗的頭部安裝一個攝像頭,以便從狗的視角獲取相應的運動信息。然后,將一組CNN特征提取器用于從視頻幀獲取圖像特征,并將其與傳感器數據一起傳遞給一組LSTM模型,以便學習并預測狗的動作和行為。這是一項非常新穎而富有創造性的應用研究,其整體的任務框架及獨特的執行方式都是本文的亮點!希望這項研究能夠為我們未來收集數據和應用深度學習技術的方式帶來更多的創造力。
▌Learning to Segment Every?Thing(學習分割一切)
在過去的幾年里,何凱明團隊 (以前在微軟研究院,現就職于 Facebook AI Research) 提出了許多重大的計算機視覺研究成果。他們的研究最棒之處在于將創造力和簡單性相結合,諸如將 ResNets和Mask R-CNN相結合的研究,這些都不是最瘋狂或最復雜的研究思路,但是它們簡單易行,并在實踐中非常有效。
該團隊最新的研究 Learning to Segment Every Thing是 Mask R-CNN研究的擴展,它使模型準確地分割訓練期間未出現的類別目標!這對于獲取快速且廉價的分割數據標注是非常有用的。事實上,該研究能夠獲得一些未知目標的基準分割效果(baseline segment),這對于在自然條件中部署這樣的分割模型來說是至關重要的,因為在這樣的環境下可能存在許多未知的目標。總的來說,這絕對是我們思考如何充分利用深層神經網絡模型的正確方向。
▌Soccer on Your?Tabletop(桌上足球)
本文的研究是在FIFA世界杯開幕時正式發表的,理應獲得最佳時機獎!這的確是CVPR上在計算機視覺領域的“更酷”應用之一。簡而言之,作者訓練了一個模型,在給定足球比賽視頻的情況下,該模型能夠輸出相應視頻的動態3D重建,這意味著你可以利用增強現實技術在任何地方查看它!
本文最大的亮點是結合使用許多不同類型的信息。使用視頻比賽數據訓練網絡,從而相當容易地提取3D網格信息。在測試時,提取運動員的邊界框,姿勢及跨越多個幀的運動軌跡以便分割運動員。接著你可以輕松地將這些3D片段投射到任何平面上。在這種情況下,你可以通過制作虛擬的足球場,以便在 AR條件下觀看的足球比賽!在我看來,這是一種使用合成數據進行訓練的方法。無論如何它都是一個有趣的應用程序!
▌LayoutNet: Reconstructing the 3D Room Layout from a Single RGBImage(LayoutNet:從單個RGB圖像重建3D房間布局)
這是一個計算機視覺的應用程序,我們可能曾經想過:使用相機拍攝某些東西,然后用數字3D技術重建它。這也正是本文研究的目的,特別是重建 3D房間布局。研究人員使用全景圖像作為網絡的輸入,以獲得房間的完整視圖。網絡的輸出是3D重建后的房間布局,具有相當高的準確性!該模型足夠強大,可以推廣到不同形狀、包含許多不同家具的房間。這是一個有趣而好玩、又不需要投入太多研究人員就能實現的應用程序。
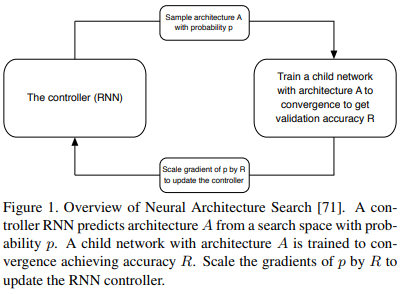
▌Learning Transferable Architectures for Scalable Image Recognition (學習可遷移的結構用于可擴展的圖像識別任務)
最后要介紹的是一項許多人都認為是深度學習未來的研究:神經架構搜索(NAS)。NAS背后的基本思想是我們可以使用另一個網絡來“搜索”最佳的模型結構,而不需要手動地設計網絡結構。結構搜索過程是基于獎勵函數進行的,通過獎勵模型以使其在驗證數據集上有良好的表現。此外,作者在論文中表明,這種模型結構比起手動設計的模型能夠獲得更高的精度。這將是未來巨大的研究方向,特別是對于設計特定的應用程序而言。因為我們真正關注的是設計好的NAS算法,而不是為我們特定的應用設計特定的網絡。精心設計的NAS算法將足夠靈活,并能夠為任何任務找到良好的網絡結構。
▌結束語
希望你能從中學到一些新的、有用的東西,甚至能夠為你自己的研究與工作找到一些新的想法!
-
3D
+關注
關注
9文章
3012瀏覽量
115099 -
深度學習
+關注
關注
73文章
5599瀏覽量
124417 -
cnn
+關注
關注
3文章
355瀏覽量
23431
原文標題:CVPR 2018 上10篇最酷論文,圈兒里最Cool的人都在看
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Nullmax研發團隊靜態元素檢測和拓撲推理新成果入選CVPR 2026
從CVPR 2019看事件相機步態識別:技術突破與產品應用

后摩智能4篇論文入選人工智能頂會ICLR 2026
MediaTek多篇論文入選全球前沿國際學術會議
地平線五篇論文入選NeurIPS 2025與AAAI 2026

后摩智能六篇論文入選四大國際頂會

理想汽車12篇論文入選全球五大AI頂會
思必馳與上海交大聯合實驗室五篇論文入選NeurIPS 2025
易控智駕榮獲計算機視覺頂會CVPR 2025認可
理想汽車八篇論文入選ICCV 2025
傳音多媒體團隊攬獲CVPR NTIRE 2025兩項挑戰賽冠亞軍

NVIDIA榮獲CVPR 2025輔助駕駛國際挑戰賽冠軍
后摩智能四篇論文入選三大國際頂會
云知聲四篇論文入選自然語言處理頂會ACL 2025




 工商網監
工商網監
評論