") 基于交錯(cuò)組卷積的高效DNN詳解
基于交錯(cuò)組卷積的高效DNN詳解

卷積神經(jīng)網(wǎng)絡(luò)在近幾年獲得了跨越式的發(fā)展,雖然它們?cè)谥T如圖像識(shí)別任務(wù)上的效果越來越好,但是隨之而來的則是模型復(fù)雜度的不斷提升。越來越深、越來越復(fù)雜的卷積神經(jīng)網(wǎng)絡(luò)需要大量存儲(chǔ)與計(jì)算資源,因此設(shè)計(jì)高效的卷積神經(jīng)網(wǎng)絡(luò)是非常重要和基礎(chǔ)的問題,而消除卷積的冗余性是該問題主要的解決方案之一。
如何消除消除卷積的冗余性?我們邀請(qǐng)到了微軟亞洲研究院視覺計(jì)算組資深研究員王井東博士,為大家講解發(fā)表在 ICCV 2017 和 CVPR 2018 上基于交錯(cuò)組卷積的方法。
以下是公開課內(nèi)容,AI科技大本營整理,略有刪減:
▌深度學(xué)習(xí)大獲成功的原因
2006年《Science》上的一篇文章——Reducing the Dimensionality of Data with Neural Networks,是近十多年來促進(jìn)深度學(xué)習(xí)發(fā)展非常重要的一篇文章。當(dāng)時(shí)這篇文章出來的時(shí)候,很多機(jī)器學(xué)習(xí)領(lǐng)域的人都在關(guān)注這個(gè)工作,但是它在計(jì)算機(jī)視覺領(lǐng)域里并沒有取得非常好的效果,所以并沒有引起計(jì)算機(jī)視覺領(lǐng)域的人的關(guān)注。
深度學(xué)習(xí)的方法在計(jì)算機(jī)視覺領(lǐng)域真正得到關(guān)注是因?yàn)?2012 年的一篇文章——ImageNet Classification with Deep Convolutional Neural Networks。這個(gè)文章用深度卷積神經(jīng)網(wǎng)絡(luò)的方法贏得了計(jì)算機(jī)視覺領(lǐng)域里一個(gè)非常重要的 ImageNet 比賽的冠軍。在 2012 年之前的冠軍都是基于 SVM(支持向量機(jī))或者隨機(jī)森林的方法。
2012年 Hinton 和他的團(tuán)隊(duì)通過深度網(wǎng)絡(luò)取得了非常大的成功,這個(gè)成功大到什么程度?比前一年的結(jié)果提高了十幾個(gè)百分點(diǎn),這是非常可觀、非常了不起的提高。因?yàn)樵?ImageNet 比賽上的成功,計(jì)算機(jī)視覺領(lǐng)域開始接受深度學(xué)習(xí)的方法。
比較這兩篇文章,雖然我們都稱之為深度學(xué)習(xí),但實(shí)際上相差還挺大的。特別是 2012 年這篇文章叫“深度卷積神經(jīng)網(wǎng)絡(luò)”,簡(jiǎn)寫成 “CNN”。CNN 不是 2012 年這篇文章新提出來的,在九十年代,Yann LeCun 已經(jīng)把 CNN 用在數(shù)字識(shí)別里,而且取得非常大的成功,但是在很長的時(shí)間里,大家都沒有拿 CNN 做 ImageNet 比賽,直到這篇文章。今天大家發(fā)現(xiàn)深度學(xué)習(xí)已經(jīng)統(tǒng)治了計(jì)算機(jī)視覺領(lǐng)域。
為什么 2012 年深度學(xué)習(xí)能夠成功?其實(shí)除了深度學(xué)習(xí)或者 CNN 的方法以外,還有兩個(gè)東西,一個(gè)是 GPU,還有一個(gè)就是 ImageNet。
這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)是 2012 年 Hinton 跟他學(xué)生提出的,其實(shí)這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)也就8層,好像沒有那么深,但當(dāng)時(shí)訓(xùn)練這個(gè)網(wǎng)絡(luò)非常困難,需要一個(gè)星期才訓(xùn)練出來,而且當(dāng)時(shí)別人想復(fù)現(xiàn)它的結(jié)果也沒有那么容易。
這篇文章以后,大家都相信神經(jīng)網(wǎng)絡(luò)越深,性能就會(huì)變得越好。這里面有幾個(gè)代表性的工作,簡(jiǎn)單回顧一下。
深度網(wǎng)絡(luò)結(jié)構(gòu)的兩個(gè)發(fā)展方向
▌越來越深
2014 年的 VGG,這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)非常簡(jiǎn)單,就是一層一層堆積起來的,而且層與層之間非常相似。
同一年,Google 有一個(gè)網(wǎng)絡(luò)結(jié)構(gòu),稱之為“GoogLeNet”,這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)看起來比 VGG 的結(jié)構(gòu)復(fù)雜一點(diǎn)。這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)剛出來的時(shí)候看起來比較復(fù)雜,今天看起來就是多分支的一個(gè)結(jié)構(gòu)。剛開始,大家普遍的觀點(diǎn)是這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)是人工調(diào)出來的,沒有很強(qiáng)的推廣性。盡管 GoogLeNet 是一個(gè)人工設(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu),其實(shí)這里面有非常值得借鑒的東西,包括有長有短多分支結(jié)構(gòu)。
2015 年時(shí)出了一個(gè)網(wǎng)絡(luò)結(jié)構(gòu)叫 Highway。Highway 這篇文章主要是說,我們可以把 100 層的網(wǎng)絡(luò)甚至 100 多層的網(wǎng)絡(luò)訓(xùn)練得非常好。它為什么能夠訓(xùn)練得非常好?這里面有一個(gè)概念是信息流,它通過 SkipConnection 可以把信息很快的從最前面?zhèn)鬟f到后面層去,在反向傳播的時(shí)候也可以把后面的梯度很快傳到前面去。這里面有一個(gè)問題,就是這個(gè) Skip Connection 使用了 gate function,使得深度網(wǎng)絡(luò)訓(xùn)練困難仍然沒有真正解決。
同一年,微軟的同事發(fā)明了一個(gè)網(wǎng)絡(luò),叫“ResNet”,這個(gè)網(wǎng)絡(luò)跟 Highway 在某種意義上很相像,相像在什么地方?它同樣用了 Skip Connection,從某一層的 output 直接跳到后面層的 output 去。這個(gè)跟 Highway 相比,它把 gate function 扔掉了,原因在于在訓(xùn)練非常深的網(wǎng)絡(luò)里 gate 不是一個(gè)特別好的東西。通過這個(gè)設(shè)計(jì),它可以把 100 多層的網(wǎng)絡(luò)訓(xùn)練得非常好。后來發(fā)現(xiàn),通過這招 1000 層的網(wǎng)絡(luò)也可以訓(xùn)練得非常好,非常了不起。
2016年,GoogLeNet、Highway、ResNet出現(xiàn)以后,我們發(fā)現(xiàn)這里面的有長有短的多分支結(jié)構(gòu)非常重要,比如我們的工作 deeply-fused nets,在多個(gè) Branch 里面,每個(gè)分支深度是不一樣的這樣的好處在于,如果我們把從這個(gè)結(jié)構(gòu)看成一個(gè)圖的話,發(fā)現(xiàn)從這個(gè)輸入點(diǎn)到那個(gè)輸出點(diǎn)有多條路徑,有的路徑長,有的路徑短,從這個(gè)意義上來講,我們認(rèn)為有長有短的路徑可以把深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練好。
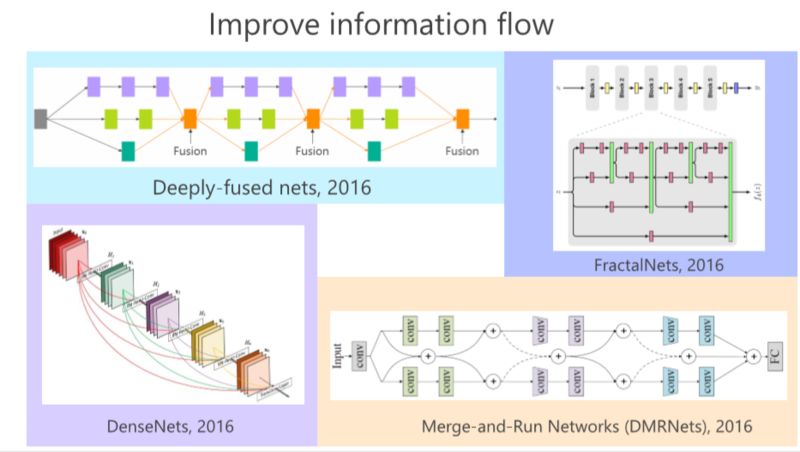
同年,我們發(fā)現(xiàn)有個(gè)類似的工作,叫 FractalNets,它跟我們的 deeply-fused nets 非常相像。
這條路都是通過變深,希望把網(wǎng)絡(luò)結(jié)構(gòu)訓(xùn)練得非常好,使它的性能非常好,加上 Skip Connection 等等形式來使得信息流非常好。盡管我們通過 Skip Connection 把深度網(wǎng)絡(luò)訓(xùn)練得很不錯(cuò),但深度還是帶來一些問題,就是并沒有把性能發(fā)揮得很好,所以有另外一個(gè)維度,大家希望變得更寬一點(diǎn)。
除此之外,大的網(wǎng)絡(luò)用在實(shí)際中會(huì)遇到一些問題。比如部署到手機(jī)上時(shí)希望計(jì)算量不要太大,模型也不要太大,性能仍然要很好,所以識(shí)別率做的非常高的但是很龐大的網(wǎng)絡(luò)結(jié)構(gòu)在實(shí)際應(yīng)用里面臨一些困難。
▌簡(jiǎn)化結(jié)構(gòu)的幾種方法

另外一條路是簡(jiǎn)化網(wǎng)絡(luò)結(jié)構(gòu),消除里面的冗余性。因?yàn)榇蠹叶颊J(rèn)為現(xiàn)在深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)里有很強(qiáng)的冗余性,消除冗余性是我近幾年發(fā)現(xiàn)非常值得做的一個(gè)領(lǐng)域,因?yàn)樗膶?shí)際用處很大。
卷積操作
CNN 里面的卷積操作實(shí)際上對(duì)應(yīng)的就是矩陣向量相乘,大家做的基本就是消除卷積里的冗余性。
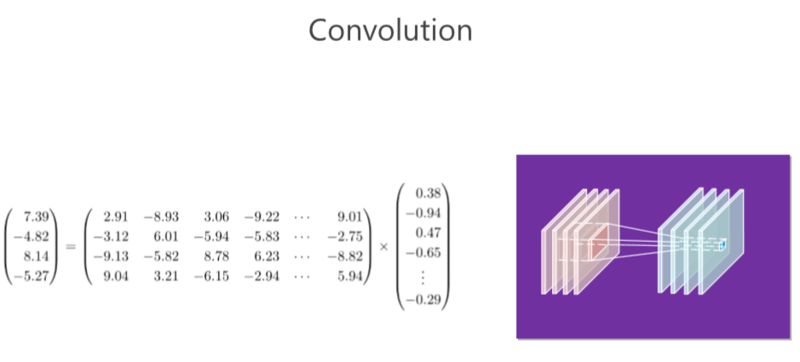
我們回顧一下卷積。右邊的圖:在 CNN 里面有若干個(gè)通道,每個(gè)通道實(shí)際上是一個(gè)二維的數(shù)組,每個(gè)位置都有一個(gè)數(shù)值,在這里面我們稱為“響應(yīng)值”。這里面有四個(gè)通道,實(shí)際上就相當(dāng)于三維的數(shù)組一樣。以這里(每個(gè)位置)為中心,取一個(gè) 3×3 的小塊出來,3×34 個(gè)通道,那就有 3×3×4 這么多個(gè)數(shù)值,然后我們把這么多個(gè)數(shù)值拉成一個(gè) 3×3×4=36 維向量。卷積有個(gè)卷積核,卷積核對(duì)應(yīng)一個(gè)橫向量,這個(gè)橫向量和列向量一相乘,就會(huì)得到響應(yīng)的值,這是第一個(gè)卷積核。通過第二個(gè)卷積核又會(huì)得到第二個(gè)值,類似地可以得到第三個(gè)第四個(gè)值。
總結(jié)起來,卷積操作就是是矩陣和向量相乘,矩陣對(duì)應(yīng)的是若干個(gè)卷積核,向量對(duì)應(yīng)的是周圍方塊的響應(yīng)值(ResponseValue)。
大家都知道矩陣跟向量相乘占了很大的計(jì)算量。我在這里舉的例子并沒有那么大,但大家想一想,如果輸入輸出 100個(gè) 通道,,假如這個(gè)卷積核是3×3×100,那就是 100×900 的計(jì)算量,這個(gè)計(jì)算量非常大,所以有大部分工作集中在解決這里面(卷積操作)冗余性的問題。
Low-precision kernels(低精度卷積核)
有什么辦法解決冗余性的問題呢?

因?yàn)榫矸e核通常是浮點(diǎn)型的數(shù),浮點(diǎn)型的數(shù)計(jì)算復(fù)雜度要大一點(diǎn),同時(shí)它占得空間也會(huì)大一點(diǎn)。最簡(jiǎn)單的一招是什么?假設(shè)把卷積核變成二值的,比如 1、-1,我們看看 1、-1轉(zhuǎn)成以后有什么好處?這個(gè)向量 1、-1(使得)本來相乘的操作變成加減了,這樣一來計(jì)算量就減少了很多。除此以外,模型和存儲(chǔ)量也減少很多。

也有類似相關(guān)的工作,就是把浮點(diǎn)型的變成整型的,比如以前 32 位浮點(diǎn)數(shù)的變成 16 位的整型數(shù),同樣存儲(chǔ)量會(huì)小,或者模型會(huì)小。除了卷積核進(jìn)行二值化化以外或者進(jìn)行整數(shù)化以外,也可以把 Response 變成二值數(shù)或者整數(shù)。

還有一類研究得比較多的是量化。比如把這個(gè)矩陣聚類,比如 2.91、3.06、3.21,聚成一類,我用 3 來代替它量化有什么好處?首先,你的存儲(chǔ)量減少了,不需要存儲(chǔ)原來的數(shù)值,只需要存量化以后的每個(gè)中心的索引值就可以了。除此之外,計(jì)算量也變小了,你可以想辦法讓它減少乘的次數(shù),這樣就模型大小就會(huì)減少了。
Low-rank kernels(低秩卷積核)


另外一條路,矩陣大怎么辦?把矩陣變小一點(diǎn),所以很多人做了這件事情, 100 個(gè)(輸出)通道,我把它變成 50 個(gè),這是一招。另外一招, input(輸入)很多, 100 個(gè)通道,變成了 50 個(gè)。
低秩卷積核的組合

把通道變少會(huì)不會(huì)降低性能?所以有人做了這件事情:把這個(gè)矩陣變成兩個(gè)小矩陣相乘,假如這個(gè)矩陣是 100×100 的,我把它變成 100×10 和10×100 兩個(gè)矩陣相乘,(相乘得到的矩陣)也變成 100×100 的矩陣,近似原來 100×100 那個(gè)矩陣。這樣想想,100×100 變成 100×10 跟 10×100,顯然模型變小了,變成五分之一。此外計(jì)算量也降到五分之一。
稀疏卷積核
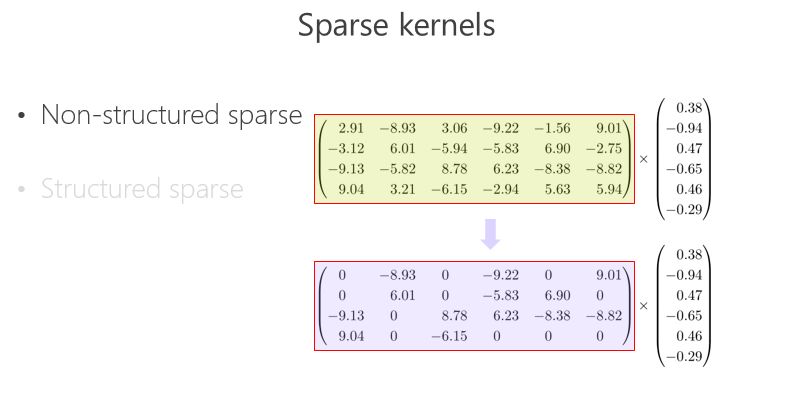
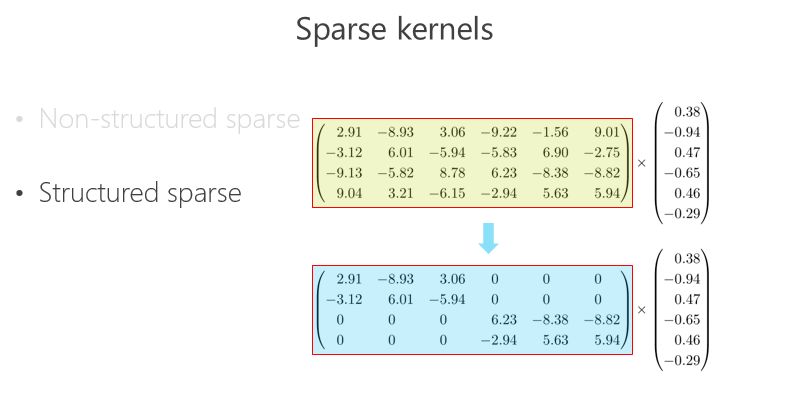
另外一條路,怎么把矩陣跟向量相乘變得快一點(diǎn)、模型的參數(shù)少一點(diǎn)?可以把里面的有些數(shù)變成 0,比如 2.91 變成 0,3.06 變成 0,變成 0 以后就成了稀疏的矩陣,這個(gè)稀疏矩陣存儲(chǔ)量會(huì)變小,如果你足夠稀疏的話,計(jì)算量會(huì)小,因?yàn)橹苯邮?0 就不用乘了。還有一種 Structured sparse(結(jié)構(gòu)化稀疏),比如這種對(duì)角形式,矩陣跟向量相乘,可以優(yōu)化得很好。這里 Structured sparse 對(duì)應(yīng)我后面將要講的組卷積(Groupconvolution)。
稀疏卷積核的組合
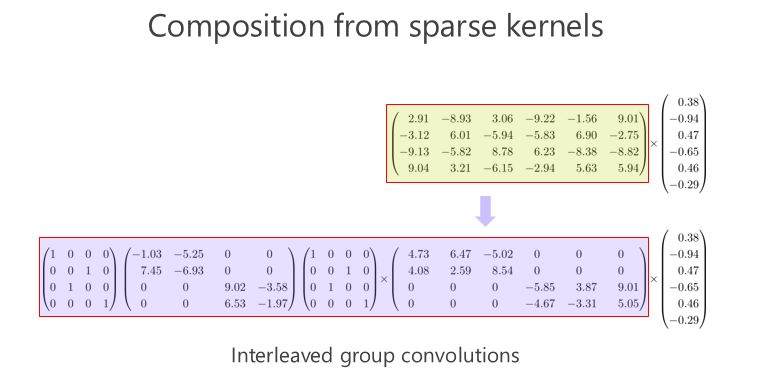
我們來看看這個(gè)矩陣能不能通過多個(gè)稀疏矩陣相乘來近似,這是我今天要講的重點(diǎn),我們的工作也是圍繞這一點(diǎn)在往前走。在我們做這個(gè)方向之前,大家并沒有意識(shí)到一個(gè)矩陣可以變成兩個(gè)稀疏矩陣相乘甚至多個(gè)稀疏矩陣相乘,來達(dá)到模型小跟計(jì)算量小的目標(biāo)。
從IGCV1到IGCV3
▌IGCV1
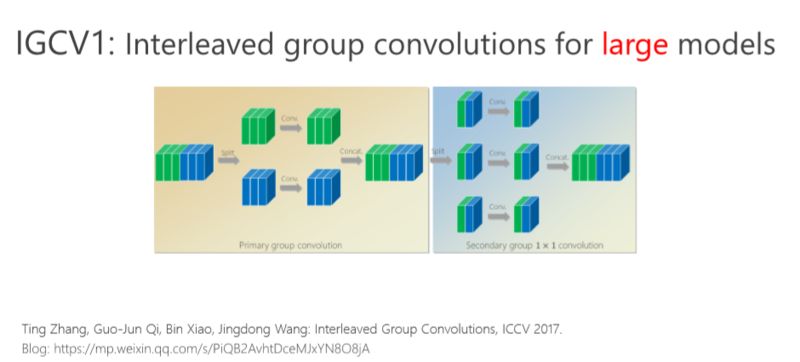
首先我給大家介紹一下我們?nèi)ツ暝?ICCV 2017 年會(huì)議上的文章,交錯(cuò)組卷積的方法。
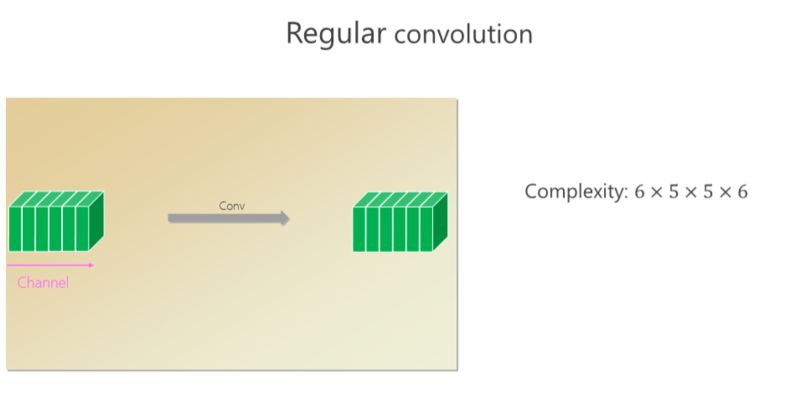
這個(gè)卷積里面有六個(gè)通道,通過卷積出來的也是六個(gè)小方塊(通道),假如 spatial kernel 的尺寸是5×5,對(duì)每個(gè)位置來講,它的計(jì)算量是6×5×5×6。
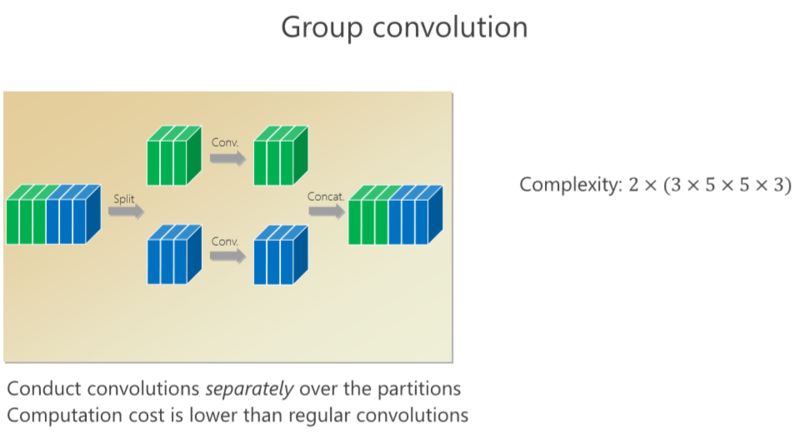
我剛才講了(一種結(jié)構(gòu)化)稀疏的形式,對(duì)應(yīng)的就是組卷積的形式,組卷積是什么意思?我把這 6 個(gè)通道分成上面 3 個(gè)通道和下面 3 個(gè)通道,分別做卷積,做完以后把它們拼在一起,最后得到的是6個(gè)通道。看看計(jì)算量,上面是 3×5×5×3,下面也是一樣的,整個(gè)計(jì)算復(fù)雜度跟前面的 6×5×5×6 相比就小了一半,但問題是參數(shù)利用率可能不夠。
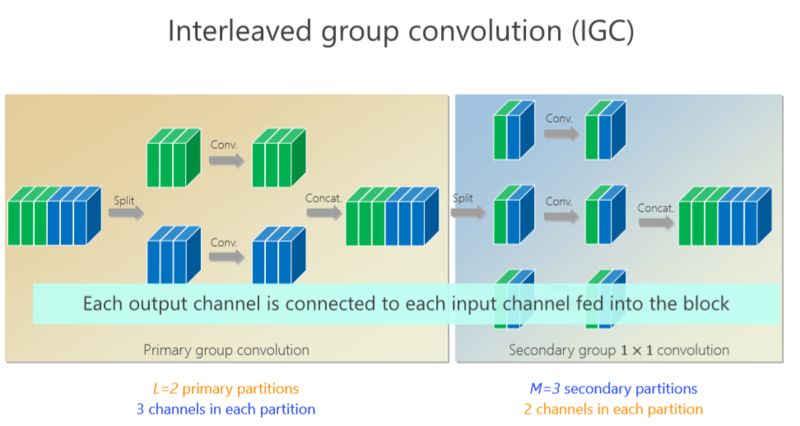
我們的工作是基于組卷積的,剛才提到了上面的三個(gè)通道和這三個(gè)通道不相關(guān),那有沒有辦法讓它們相關(guān)?所以我們又引進(jìn)了第二個(gè)組卷積,我們把這6個(gè)通道重新排了序,1、4 放到這(第一個(gè)分支),2、5 放到這(第二個(gè)分支),3、6 放到那(第三個(gè)分支),這樣每一分支再做一次 1×1 的convolution,得出新的兩個(gè)通道、兩個(gè)通道、兩個(gè)通道,拼在一起。通過交錯(cuò)的方式,我們希望達(dá)到每個(gè) output(輸出)的通道(綠色的通道或者藍(lán)色的通道)跟前面6個(gè)通道都相連。
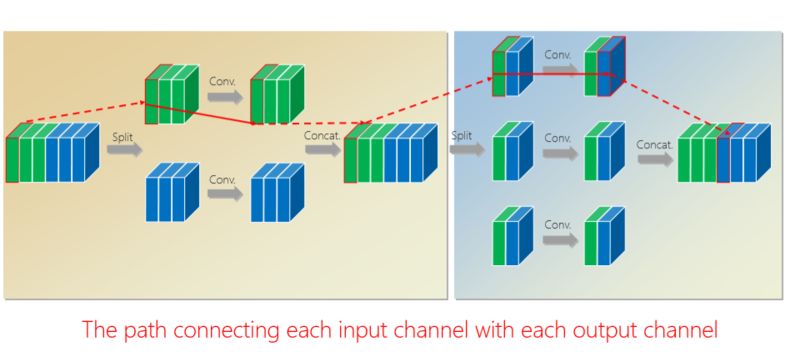
有什么好處?通過第二組的組卷積可以達(dá)到互補(bǔ)的條件,或者使得任何一個(gè) output(輸出通道)和任何一個(gè) input(輸入通道)連起來。

這里面我們引進(jìn)了一個(gè)嚴(yán)格的互補(bǔ)條件,直觀來講就是,如果有兩個(gè)通道在第一組卷積里面,落在同一個(gè) Branch(分支),我希望在第二組里面落在不同的 Branch(分支)。第二組里面比如一個(gè) Branch(分支)里面的若干個(gè)通道,要來自于第一個(gè)組卷積里面的所有 Branches(分支),這個(gè)稱為互補(bǔ)條件。這個(gè)互補(bǔ)條件帶來什么?它會(huì)帶來(任何一對(duì)輸入輸出通道之間存在) path,也就是說相乘矩陣是密集矩陣。為什么稱之為“嚴(yán)格的”?就是任何一個(gè) input 和 output 之間有一條 path,而且有且只有一條path。

嚴(yán)格的準(zhǔn)則引進(jìn)來以后,參數(shù)量變小了、模型變小了,帶來什么好處?這里我給一個(gè)結(jié)論,L 是(第)一個(gè)組卷積里面的 partitions(分支)的數(shù)目或者卷積的數(shù)目,M是第二組組卷積卷積的數(shù)目,S 是卷積核的大小,通常都是大于 1 的。這樣的不等式幾乎是恒成立的,這個(gè)不等式意味著什么?結(jié)論是:如果跟普通標(biāo)準(zhǔn)的卷積去比,通過我們的設(shè)計(jì)方式可以讓網(wǎng)絡(luò)變寬。跟網(wǎng)絡(luò)變深相比起來,網(wǎng)絡(luò)變寬是另外一個(gè)維度,變寬有什么好處?會(huì)不會(huì)讓結(jié)果變好?我們做了一些實(shí)驗(yàn)。
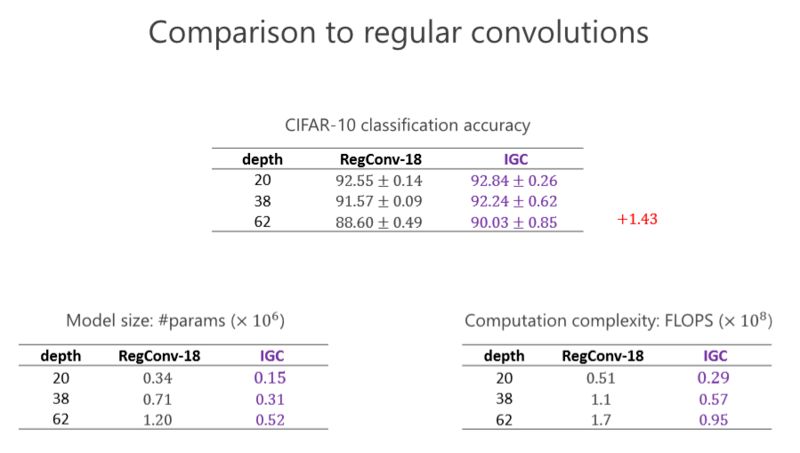
這個(gè)實(shí)驗(yàn)是跟標(biāo)準(zhǔn)的卷積去比,大家看看左下角的表格,這個(gè)表格是參數(shù)量,我們?cè)O(shè)計(jì)的網(wǎng)絡(luò)幾乎是標(biāo)準(zhǔn)(卷積)參數(shù)量的一半。然后看看右下角這個(gè)網(wǎng)絡(luò),我們的的計(jì)算量幾乎也是一半。在 CIFAR-10 標(biāo)準(zhǔn)的圖像分類數(shù)據(jù)集里(上面的表格),我們的結(jié)果比前面的一種好。我們甚至?xí)l(fā)現(xiàn)越深越好,在 20 層有些提升并沒有那么明顯,但深的時(shí)候可以達(dá)到 1.43 的提高量。
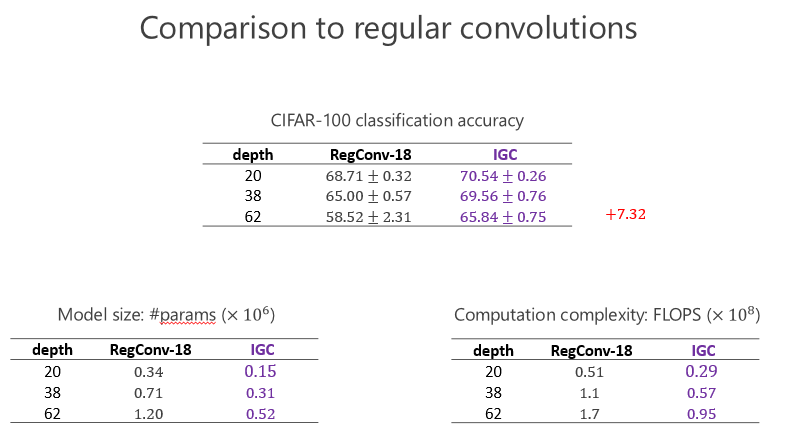
后來 CIFRA-100 我們也做了同樣的實(shí)驗(yàn),發(fā)現(xiàn)我們提升仍然是一致的,甚至跟前面的比起來提高得更大,因?yàn)榉?100 類比分 10 類困難一點(diǎn),說明越困難的任務(wù),我們的優(yōu)勢(shì)越明顯。這個(gè)變寬了以后(性能)的確變好了,通過 IGC 實(shí)現(xiàn),網(wǎng)絡(luò)結(jié)構(gòu)變寬的確會(huì)帶來好處。
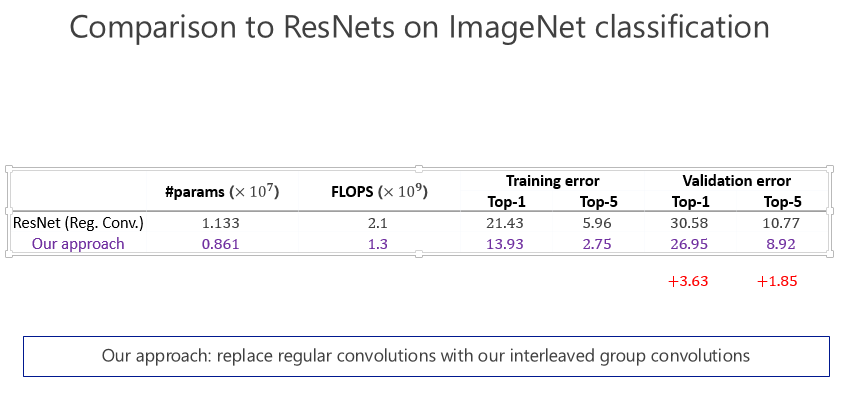
這是兩個(gè)小的數(shù)據(jù)集,其實(shí)在計(jì)算機(jī)視覺領(lǐng)域里小數(shù)據(jù)集上的結(jié)果是不能(完全)說明問題的,一定要做非常大的數(shù)據(jù)集。所以我們當(dāng)時(shí)也做了 ImageNet 數(shù)據(jù)集,跟 ResNet 比較了一下,參數(shù)量少了近五分之二,計(jì)算量小了將近一半了,錯(cuò)誤率也降低了,這證明通過 IGC 的實(shí)現(xiàn),讓模型變寬,在大的網(wǎng)絡(luò)模型上取得非常不錯(cuò)的效果。
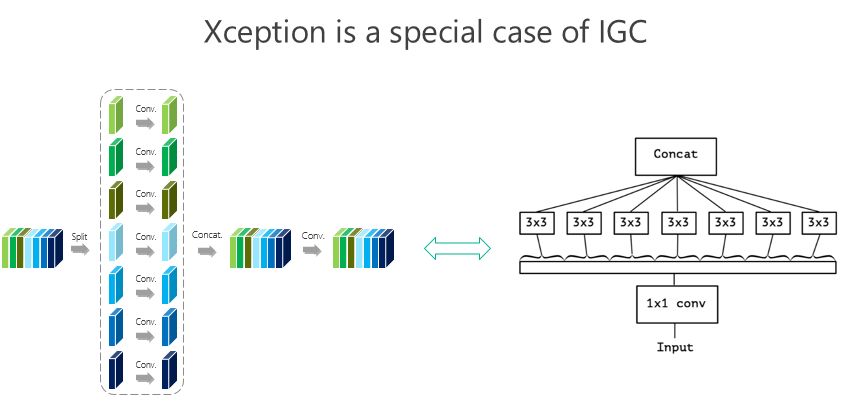
我們大概是前年 8、9 月份開始做這個(gè)事情,10 月份發(fā)現(xiàn) Google 有一個(gè)工作是 Xception,這個(gè)是它的結(jié)構(gòu)圖,這個(gè)形式非常接近(我們的結(jié)構(gòu)),跟我們前面所謂的 IGC 結(jié)構(gòu)非常像,實(shí)際上就是我們的一個(gè)特例。當(dāng)時(shí)我們覺得這個(gè)特例有沒有可能結(jié)果最好,所以我們做了些驗(yàn)證,整體上我們結(jié)構(gòu)好一點(diǎn)。
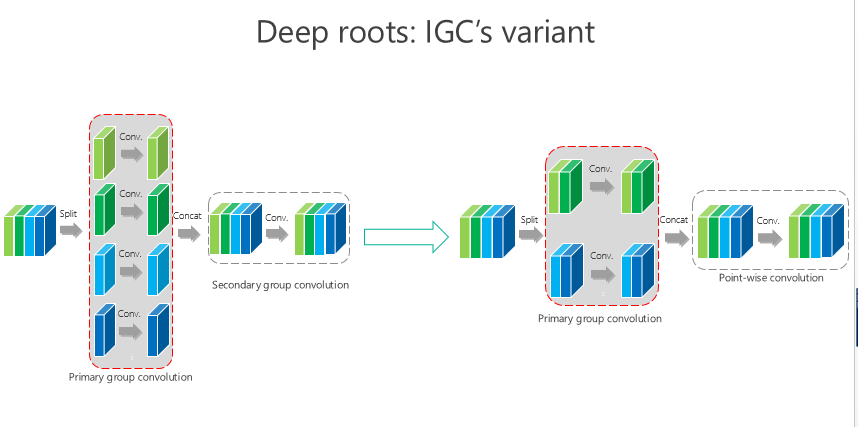
IGC 可能還有變體,比如我要是把這個(gè) channel-wise 也變成組卷積,第二個(gè)是 1×1 的,這樣的結(jié)果會(huì)怎樣?我們做了類似同樣的實(shí)驗(yàn),仍然發(fā)現(xiàn)我們的方法是最好的。
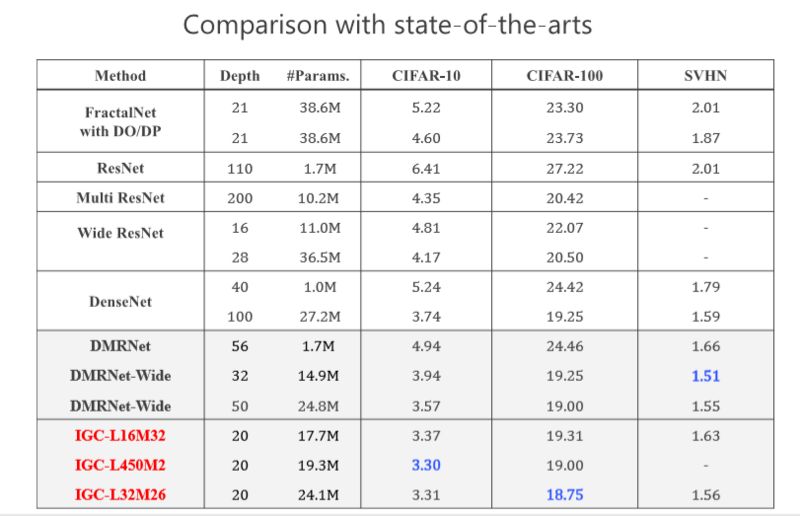
當(dāng)時(shí)我們做的時(shí)候,希望在網(wǎng)絡(luò)結(jié)構(gòu)上跟 state-of-the-arts 的方法去比較,我們?nèi)〉昧朔浅2诲e(cuò)的結(jié)果,當(dāng)時(shí)我們的工作是希望通過消除冗余性提高模型性能或者準(zhǔn)確率。
▌IGCV2
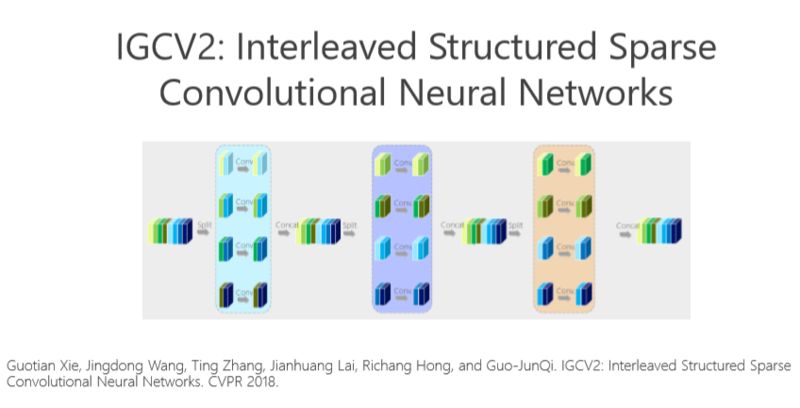
后來我們嘗試?yán)孟哂嘈詭淼暮锰帲堰@個(gè)模型部署到手機(jī)上去。我們?nèi)ツ暧盅刂@個(gè)方向繼續(xù)往前走,把這個(gè)問題理解得更深,希望進(jìn)一步消除冗余性。
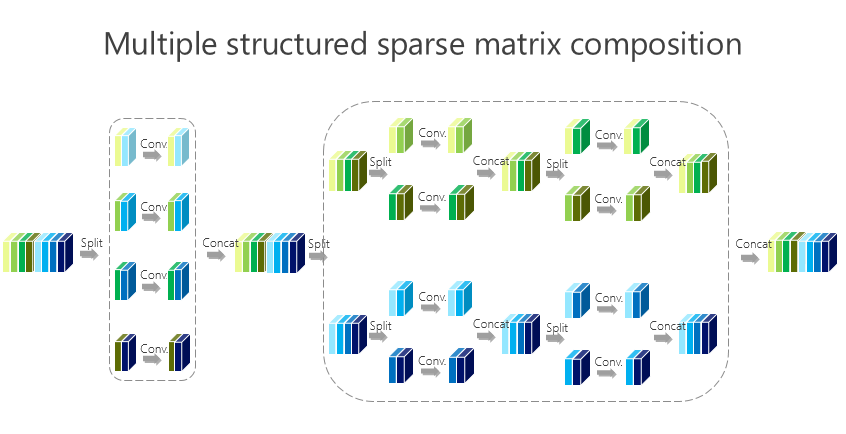
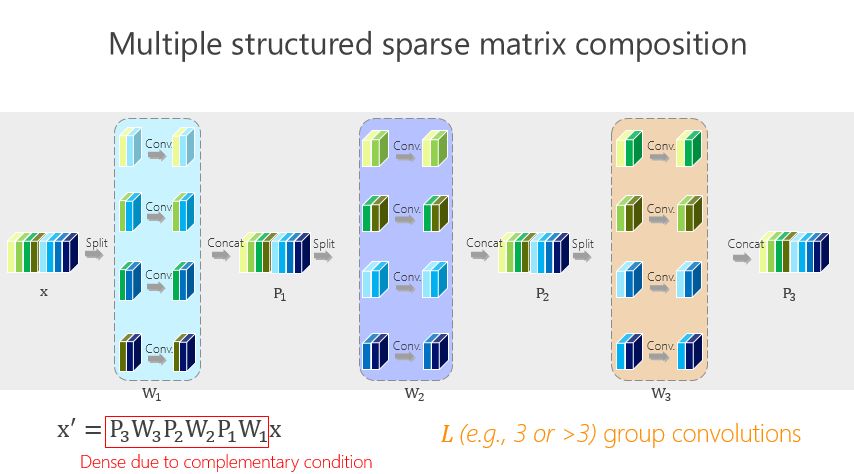
這個(gè)講起來比較直接或簡(jiǎn)單一點(diǎn),前面的網(wǎng)絡(luò)結(jié)構(gòu)是兩個(gè)組卷積或者兩個(gè)矩陣相乘得到的,我們有沒有辦法變得多一點(diǎn)?實(shí)際上很簡(jiǎn)單,如上圖所示。

這種方法帶來的好處很直接,就是希望參數(shù)量盡量小,那怎么才能(使)參數(shù)量盡量小?我們引進(jìn)了所謂的平衡條件。雖然這里面我們有 L-1 個(gè) 1×1 的組卷積,但 L-1 個(gè) 1×1 的組卷積之間有區(qū)別嗎?誰重要一點(diǎn)、誰不重要一點(diǎn)?其實(shí)我們也不知道。不知道怎么辦?就讓它一樣。一樣了以后,我們通過簡(jiǎn)單的數(shù)學(xué)推導(dǎo)就會(huì)得出上面的數(shù)學(xué)結(jié)果。
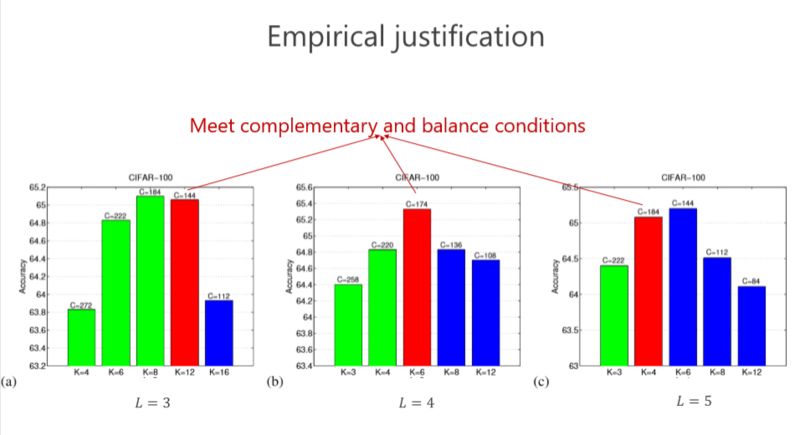
現(xiàn)在再驗(yàn)證一下,前面講了互補(bǔ)條件、平衡條件,那這個(gè)結(jié)果是不是最好的?或者是不是有足夠的優(yōu)勢(shì)?我們做了些實(shí)驗(yàn),這個(gè)紅色的是對(duì)應(yīng)滿足我們條件的,發(fā)現(xiàn)這個(gè)情況下(L=4)結(jié)果是最好的。其實(shí)是不是總是最好?不見得,因?yàn)閷?shí)際問題跟理論分析還是有點(diǎn)距離。但我們總體發(fā)現(xiàn)基本上紅色的不是最好也排在第二,說明這種設(shè)計(jì)至少給了我們很好的準(zhǔn)則來幫助設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)。這個(gè)雖然不總是最好的,但和最好的是差不多的。

第二個(gè)問題,我們究竟要設(shè)計(jì)多少個(gè)組卷積(L 設(shè)成多少)?同樣我們的準(zhǔn)則也是通過參數(shù)量最小來進(jìn)行分析,以前是兩個(gè)組卷積,我們可以通過 3 個(gè)、4 個(gè)達(dá)到參數(shù)量更小,但其實(shí)最終的結(jié)論發(fā)現(xiàn),并不是參數(shù)量最優(yōu)的情況下性能是最好的。
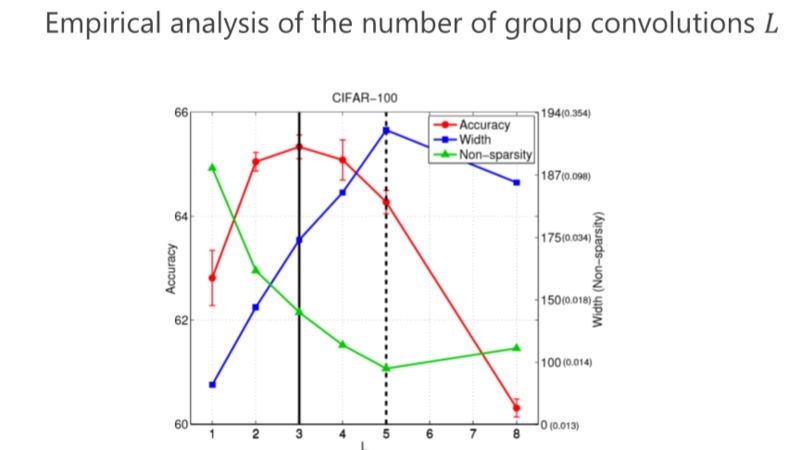
▌IGCV3

后來我們發(fā)現(xiàn),如果遵循嚴(yán)格互補(bǔ)條件,模型的結(jié)構(gòu)變得非常稀疏、非常寬,結(jié)果不見得是最好的。所以我們變成了 Loose。Loose 是什么意思?以前 output(輸出通道)和 input (輸入通道)之間是有且只有一個(gè) path,我們改得非常簡(jiǎn)單,能不能多個(gè)path?多個(gè) path 就沒那么稀疏了,它好處在于每個(gè) output (輸出通道)可以多條路徑從 input (輸入通道)那里拿到信息,所以我們?cè)O(shè)計(jì)了 Loose condition。

實(shí)際上非常簡(jiǎn)單,我們就定義兩個(gè)超級(jí)通道(super-channels)只能在一個(gè) Branch 里面同時(shí)出現(xiàn),不能在兩個(gè) Branch 里同時(shí)出現(xiàn),來達(dá)到 Loose condition。
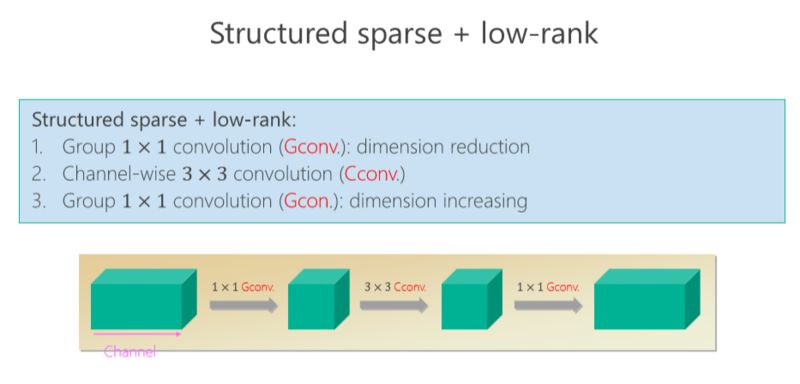
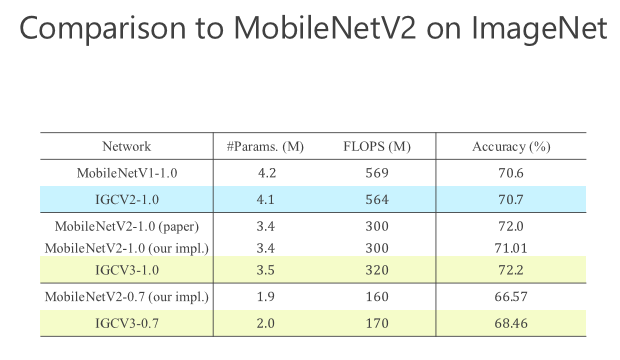
后來我們進(jìn)一步往前走,把 structured sparse 和 low-rank 兩個(gè)組起來。我們?cè)?ImageNet 上比較,同時(shí)跟 MobileV2 去比,在小的模型我們優(yōu)勢(shì)是越來越明顯的。比較結(jié)果,見下圖。
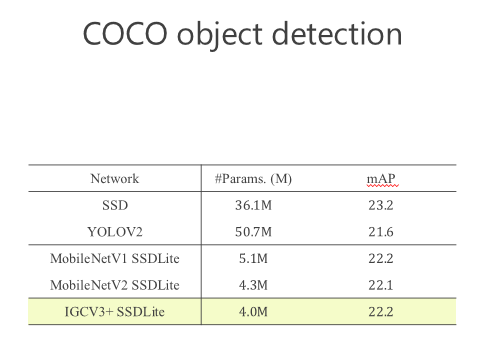

這就是今天的主要內(nèi)容,這個(gè)工作是我跟很多學(xué)生和同事一起做的,前面這5個(gè)是我的學(xué)生,Ting Zhang現(xiàn)在在微軟研究院工作,Bin Xiao 是我的同事,Guojun Qi 是美國的教授,我們一起合作了這篇文章。
-
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
372瀏覽量
12875 -
dnn
+關(guān)注
關(guān)注
0文章
61瀏覽量
9499
發(fā)布評(píng)論請(qǐng)先 登錄
什么是卷積碼? 什么是卷積碼的約束長度?
【我是電子發(fā)燒友】如何加速DNN運(yùn)算?
CNN之卷積層
詳解時(shí)間交錯(cuò)技術(shù)
可分離卷積神經(jīng)網(wǎng)絡(luò)在 Cortex-M 處理器上實(shí)現(xiàn)關(guān)鍵詞識(shí)別
卷積碼,卷積碼是什么意思
卷積碼,什么是卷積碼
什么是DNN_如何使用硬件加速DNN運(yùn)算
淺談卷積編碼在通信中的應(yīng)用 詳解卷積編碼設(shè)計(jì)應(yīng)用
詳解卷積神經(jīng)網(wǎng)絡(luò)卷積過程
卷積神經(jīng)網(wǎng)絡(luò)詳解 卷積神經(jīng)網(wǎng)絡(luò)包括哪幾層及各層功能
AI芯片設(shè)計(jì)DNN加速器buffer管理策略
基于FPGA進(jìn)行DNN設(shè)計(jì)的經(jīng)驗(yàn)總結(jié)




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論