 MySQL性能優化實戰
MySQL性能優化實戰

MySQL性能優化實戰:從慢查詢到億級數據優化的進階之路
你是否遇到過這些場景:凌晨3點被告警電話吵醒,數據庫CPU飆到100%?一條簡單的查詢語句要跑30秒?明明加了索引,查詢還是慢如蝸牛?
作為一名運維工程師,我在過去8年里處理過無數MySQL性能問題。今天,我將分享那些讓我"踩坑無數"卻最終練就一身本領的實戰經驗。這篇文章不講虛的理論,只分享真實場景下的優化技巧。
一、性能問題診斷:找到瓶頸比優化更重要
1.1 慢查詢日志:性能問題的第一手證據
很多運維同學知道慢查詢日志,但真正會用的不多。我見過太多人開啟了慢查詢卻從不分析,白白浪費了這個強大的工具。
快速開啟慢查詢日志:
-- 查看當前慢查詢配置 SHOWVARIABLESLIKE'%slow_query%'; SHOWVARIABLESLIKE'long_query_time'; -- 動態開啟慢查詢日志(立即生效,重啟失效) SETGLOBALslow_query_log='ON'; SETGLOBALslow_query_log_file='/var/log/mysql/slow.log'; SETGLOBALlong_query_time=1; -- 超過1秒的查詢記錄下來 SETGLOBALlog_queries_not_using_indexes='ON'; -- 記錄未使用索引的查詢
慢查詢分析神器 - pt-query-digest:
# 安裝percona-toolkit wget https://downloads.percona.com/downloads/percona-toolkit/3.5.0/binary/tarball/percona-toolkit-3.5.0_x86_64.tar.gz tar -xzvf percona-toolkit-3.5.0_x86_64.tar.gz # 分析慢查詢日志,找出TOP 10問題SQL pt-query-digest /var/log/mysql/slow.log > analyze_result.txt # 只看執行時間最長的10條SQL pt-query-digest --limit=10 --order-by=Query_time:sum/var/log/mysql/slow.log
實戰技巧:我通常會設置一個定時任務,每天凌晨自動分析前一天的慢查詢日志,并將結果發送到郵箱。這樣能第一時間發現潛在的性能問題。
1.2 實時監控:抓住性能問題的現行犯
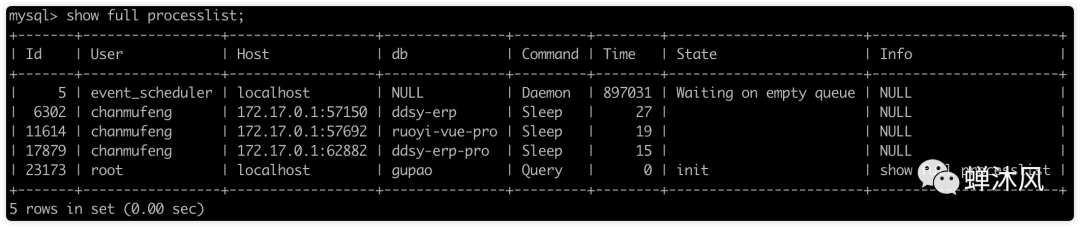
當數據庫突然變慢時,如何快速定位問題?這幾個命令是我的救命稻草:
-- 查看當前正在執行的SQL SHOWPROCESSLIST; -- 或者使用更詳細的 SELECT*FROMinformation_schema.processlist WHEREcommand!='Sleep' ORDERBYtimeDESC; -- 查看InnoDB引擎狀態(包含死鎖信息) SHOWENGINE INNODB STATUSG -- 查看表鎖等待情況 SELECT*FROMinformation_schema.innodb_lock_waits; -- 查看事務執行情況 SELECT*FROMinformation_schema.innodb_trx WHEREtrx_state='RUNNING' ORDERBYtrx_started;
實戰案例:上個月,我們的訂單系統突然響應變慢。通過SHOW PROCESSLIST發現有200多個查詢在等待表鎖。追查后發現是一個開發同學在生產環境執行了ALTER TABLE操作。教訓:任何DDL操作都要在業務低峰期執行,并使用pt-online-schema-change等工具。
1.3 性能指標監控:構建MySQL健康體檢系統
#!/bin/bash
# MySQL性能監控腳本 monitor_mysql.sh
MYSQL_USER="monitor"
MYSQL_PASS="your_password"
MYSQL_HOST="localhost"
# 監控QPS (每秒查詢數)
QPS=$(mysql -u${MYSQL_USER}-p${MYSQL_PASS}-h${MYSQL_HOST}-e"SHOW GLOBAL STATUS LIKE 'Questions';"-ss | awk'{print $2}')
sleep1
QPS2=$(mysql -u${MYSQL_USER}-p${MYSQL_PASS}-h${MYSQL_HOST}-e"SHOW GLOBAL STATUS LIKE 'Questions';"-ss | awk'{print $2}')
echo"當前QPS:$((QPS2-QPS))"
# 監控連接數
mysql -u${MYSQL_USER}-p${MYSQL_PASS}-h${MYSQL_HOST}-e"
SELECT
count(*) as total_connections,
sum(case when command='Sleep' then 1 else 0 end) as sleeping,
sum(case when command!='Sleep' then 1 else 0 end) as active
FROM information_schema.processlist;"
# 監控緩沖池命中率
mysql -u${MYSQL_USER}-p${MYSQL_PASS}-h${MYSQL_HOST}-e"
SELECT
(1 - (Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests)) * 100 as hit_ratio
FROM (
SELECT
variable_value as Innodb_buffer_pool_reads
FROM information_schema.global_status
WHERE variable_name = 'Innodb_buffer_pool_reads'
) a, (
SELECT
variable_value as Innodb_buffer_pool_read_requests
FROM information_schema.global_status
WHERE variable_name = 'Innodb_buffer_pool_read_requests'
) b;"
二、索引優化:讓查詢飛起來的核心技術
2.1 索引設計原則:不是越多越好
很多人認為索引越多越好,這是個嚴重的誤區。過多的索引會導致:
? 寫入性能下降(每次INSERT/UPDATE都要維護索引)
? 占用更多磁盤空間
? 優化器選擇困難,可能選錯索引
索引設計黃金法則:
-- 案例:電商訂單表 CREATE TABLEorders ( idBIGINTPRIMARY KEYAUTO_INCREMENT, user_idBIGINTNOT NULL, order_noVARCHAR(32)NOT NULL, status TINYINTNOT NULLDEFAULT0, total_amountDECIMAL(10,2)NOT NULL, created_at DATETIMENOT NULL, updated_at DATETIMENOT NULL, -- 索引設計 UNIQUEKEY uk_order_no (order_no), -- 訂單號唯一索引 KEY idx_user_status (user_id, status, created_at), -- 聯合索引 KEY idx_created_at (created_at) -- 時間索引用于范圍查詢 ) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4; -- 為什么這樣設計? -- 1. order_no經常用于精確查詢,設置唯一索引 -- 2. user_id + status 經常一起查詢,建立聯合索引 -- 3. created_at用于訂單時間范圍查詢
2.2 索引失效的坑:明明有索引為什么不走?
-- 創建測試表 CREATE TABLEusers ( idINTPRIMARY KEY, nameVARCHAR(50), ageINT, emailVARCHAR(100), KEY idx_name (name), KEY idx_age (age) ); -- 索引失效場景1:類型不匹配 -- 錯誤示例(age是INT類型,用字符串查詢) EXPLAINSELECT*FROMusersWHEREage='25'; -- 可能不走索引 -- 正確示例 EXPLAINSELECT*FROMusersWHEREage=25; -- 索引失效場景2:使用函數 -- 錯誤示例 EXPLAINSELECT*FROMusersWHEREYEAR(created_at)=2024; -- 不走索引 -- 正確示例 EXPLAINSELECT*FROMusersWHEREcreated_at>='2024-01-01'ANDcreated_at
2.3 索引優化實戰:一個真實的優化案例
上個季度,我優化了一個查詢從30秒降到0.1秒,這里分享優化過程:
-- 原始慢查詢(執行時間:30秒) SELECT o.order_no, o.total_amount, u.name, p.product_name FROMorders o JOINusers uONo.user_id=u.id JOINorder_items oiONo.id=oi.order_id JOINproducts pONoi.product_id=p.id WHEREo.created_at>DATE_SUB(NOW(),INTERVAL30DAY) ANDo.status=1 ANDu.city='北京'; -- 使用EXPLAIN分析 EXPLAINSELECT...; -- 發現問題:orders表全表掃描,沒有合適的索引 -- 優化方案1:添加合適的索引 ALTER TABLEordersADDINDEX idx_status_created (status, created_at); ALTER TABLEusersADDINDEX idx_city (city); -- 優化方案2:改寫SQL,先縮小結果集 SELECT o.order_no, o.total_amount, u.name, p.product_name FROM( SELECT*FROMorders WHEREstatus=1 ANDcreated_at>DATE_SUB(NOW(),INTERVAL30DAY) LIMIT1000 ) o JOINusers uONo.user_id=u.idANDu.city='北京' JOINorder_items oiONo.id=oi.order_id JOINproducts pONoi.product_id=p.id; -- 執行時間:0.1秒
三、查詢優化:寫出高性能SQL的藝術
3.1 JOIN優化:小表驅動大表
-- 假設 users 表有100萬條記錄,orders 表有1000萬條記錄 -- 需要查詢北京用戶的訂單 -- 低效寫法(大表驅動小表) SELECTo.*, u.name FROMorders o LEFTJOINusers uONo.user_id=u.id WHEREu.city='北京'; -- 高效寫法(小表驅動大表) SELECTo.*, u.name FROMusers u INNERJOINorders oONu.id=o.user_id WHEREu.city='北京'; -- 更好的寫法(使用子查詢先過濾) SELECTo.*, u.name FROMorders o INNERJOIN( SELECTid, nameFROMusersWHEREcity='北京' ) uONo.user_id=u.id;
3.2 分頁優化:大偏移量的解決方案
-- 問題:深度分頁性能差 -- 當offset很大時,MySQL需要掃描大量不需要的行 SELECT*FROMordersORDERBYid LIMIT1000000,20; -- 需要掃描1000020行 -- 優化方案1:使用覆蓋索引 SELECT*FROMorders o INNERJOIN( SELECTidFROMordersORDERBYid LIMIT1000000,20 ) tONo.id=t.id; -- 優化方案2:使用游標方式(推薦) -- 記住上一頁最后一條記錄的id SELECT*FROMordersWHEREid>1000000ORDERBYid LIMIT20; -- 優化方案3:使用延遲關聯 SELECT*FROMorders o INNERJOIN( SELECTidFROMorders WHEREcreated_at>'2024-01-01' ORDERBYid LIMIT1000000,20 ) tUSING(id);
3.3 子查詢優化:EXISTS vs IN vs JOIN
-- 場景:查找有訂單的用戶 -- 表數據量:users 10萬,orders 100萬 -- 方法1:使用IN(當子查詢結果集小時效率高) SELECT*FROMusers WHEREidIN(SELECTDISTINCTuser_idFROMorders); -- 方法2:使用EXISTS(當外表小,內表大時效率高) SELECT*FROMusers u WHEREEXISTS(SELECT1FROMorders oWHEREo.user_id=u.id); -- 方法3:使用JOIN(通常性能最好) SELECTDISTINCTu.*FROMusers u INNERJOINorders oONu.id=o.user_id; -- 性能對比腳本 SET@start=NOW(6); -- 執行查詢 SELECTCOUNT(*)FROMusersWHEREidIN(SELECTuser_idFROMorders); SELECTTIMESTAMPDIFF(MICROSECOND,@start, NOW(6))/1000000asexecution_time;
四、參數調優:榨干硬件的每一分性能
4.1 內存參數優化
-- 查看當前buffer pool大小 SHOWVARIABLESLIKE'innodb_buffer_pool_size'; -- 查看buffer pool命中率(應該大于95%) SELECT (1-(Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests))*100 asbuffer_pool_hit_ratio FROM( SELECTvariable_value Innodb_buffer_pool_reads FROMinformation_schema.global_status WHEREvariable_name='Innodb_buffer_pool_reads' ) a, ( SELECTvariable_value Innodb_buffer_pool_read_requests FROMinformation_schema.global_status WHEREvariable_name='Innodb_buffer_pool_read_requests' ) b;
my.cnf 優化配置示例:
[mysqld] # 內存優化(假設服務器有64GB內存) innodb_buffer_pool_size=48G # 物理內存的75% innodb_buffer_pool_instances=8# CPU核數 innodb_log_file_size=2G # 大事務場景可以設置更大 innodb_flush_log_at_trx_commit=2# 性能和安全的平衡 innodb_flush_method= O_DIRECT # 避免雙重緩存 # 連接優化 max_connections=2000 max_connect_errors=100000 connect_timeout=10 # 查詢緩存(MySQL 8.0已移除) query_cache_type=0# 建議關閉,用Redis代替 # 臨時表優化 tmp_table_size=256M max_heap_table_size=256M # 慢查詢 slow_query_log=1 long_query_time=1 log_queries_not_using_indexes=1
4.2 硬件層面的優化建議
基于我的經驗,硬件優化的性價比排序:
1.SSD > 內存 > CPU:SSD對數據庫性能提升最明顯
2.RAID配置:RAID10 是最佳選擇(性能和安全的平衡)
3.網絡:萬兆網卡,減少網絡延遲
五、架構優化:從單機到分布式的進化
5.1 讀寫分離:最簡單有效的擴展方案
# Python實現讀寫分離示例 importrandom importpymysql classDBRouter: def__init__(self): # 主庫(寫) self.master = pymysql.connect( host='master.db.com', user='root', password='password', database='mydb' ) # 從庫池(讀) self.slaves = [ pymysql.connect(host='slave1.db.com', ...), pymysql.connect(host='slave2.db.com', ...), ] defexecute_write(self, sql, params=None): """寫操作走主庫""" withself.master.cursor()ascursor: cursor.execute(sql, params) self.master.commit() returncursor.lastrowid defexecute_read(self, sql, params=None): """讀操作隨機選擇從庫""" slave = random.choice(self.slaves) withslave.cursor()ascursor: cursor.execute(sql, params) returncursor.fetchall() defexecute_read_master(self, sql, params=None): """強制讀主庫(解決延遲問題)""" withself.master.cursor()ascursor: cursor.execute(sql, params) returncursor.fetchall() # 使用示例 db = DBRouter() # 寫入訂單 order_id = db.execute_write( "INSERT INTO orders (user_id, amount) VALUES (%s, %s)", (123,99.99) ) # 立即查詢需要讀主庫(避免主從延遲) order = db.execute_read_master( "SELECT * FROM orders WHERE id = %s", (order_id,) )
5.2 分庫分表:應對億級數據的終極方案
-- 分表方案示例:按用戶ID取模分表 -- 創建16個訂單表 CREATE TABLEorders_0LIKEorders_template; CREATE TABLEorders_1LIKEorders_template; -- ... 一直到 orders_15 -- 路由算法(應用層實現) -- table_index = user_id % 16 -- 如 user_id = 12345, 則數據存在 orders_9 表中# Python分表路由實現 classShardingRouter: def__init__(self, shard_count=16): self.shard_count = shard_count defget_table_name(self, base_name, sharding_key): """根據分片鍵計算表名""" shard_index = sharding_key %self.shard_count returnf"{base_name}_{shard_index}" definsert_order(self, user_id, order_data): table_name =self.get_table_name('orders', user_id) sql =f"INSERT INTO{table_name}(user_id, ...) VALUES (%s, ...)" # 執行SQL defquery_user_orders(self, user_id): """查詢用戶訂單(定位到具體分表)""" table_name =self.get_table_name('orders', user_id) sql =f"SELECT * FROM{table_name}WHERE user_id = %s" # 執行查詢 defquery_order_by_id(self, order_id): """根據訂單ID查詢(需要掃描所有分表)""" results = [] foriinrange(self.shard_count): table_name =f"orders_{i}" sql =f"SELECT * FROM{table_name}WHERE order_id = %s" # 并發查詢所有分表 results.extend(execute_query(sql, order_id)) returnresults
六、故障處理:那些年踩過的坑
6.1 死鎖問題處理
-- 查看最近的死鎖信息 SHOWENGINE INNODB STATUSG -- 查找當前的鎖等待 SELECT r.trx_id waiting_trx_id, r.trx_mysql_thread_id waiting_thread, r.trx_query waiting_query, b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread, b.trx_query blocking_query FROMinformation_schema.innodb_lock_waits w INNERJOINinformation_schema.innodb_trx bONb.trx_id=w.blocking_trx_id INNERJOINinformation_schema.innodb_trx rONr.trx_id=w.requesting_trx_id; -- 殺掉阻塞的事務 KILL12345; -- thread_id
預防死鎖的最佳實踐:
1. 保持事務簡短
2. 按相同順序訪問表和行
3. 使用較低的隔離級別(如RC)
4. 為表添加合適的索引避免鎖表
6.2 主從延遲問題
#!/bin/bash # 監控主從延遲腳本 check_slave_lag() { lag=$(mysql -h$1-e"SHOW SLAVE STATUSG"| grep"Seconds_Behind_Master"| awk'{print $2}') if["$lag"="NULL"];then echo"Slave is not running on$1" # 發送告警 elif["$lag"-gt 10 ];then echo"Warning: Slave lag on$1is${lag}seconds" # 發送告警 else echo"Slave$1is healthy, lag:${lag}s" fi } # 檢查所有從庫 forslaveinslave1.db.com slave2.db.com;do check_slave_lag$slave done
6.3 連接池爆滿問題
-- 診斷連接問題 -- 查看當前連接數 SHOWSTATUSLIKE'Threads_connected'; -- 查看最大連接數設置 SHOWVARIABLESLIKE'max_connections'; -- 查看連接來源分布 SELECT user, host,count(*)asconnections, GROUP_CONCAT(DISTINCTdb)asdatabases FROMinformation_schema.processlist GROUPBYuser, host ORDERBYconnectionsDESC; -- 找出長時間Sleep的連接 SELECT*FROMinformation_schema.processlist WHEREcommand='Sleep' ANDtime>300 ORDERBYtimeDESC;
七、性能優化工具箱
7.1 必備工具清單
1.percona-toolkit:MySQL DBA的瑞士軍刀
2.MySQLTuner:一鍵診斷配置問題
3.sysbench:壓力測試工具
4.mysql-sniffer:實時抓取SQL語句
5.Prometheus + Grafana:監控可視化
7.2 自動化優化腳本
#!/bin/bash # auto_optimize.sh - MySQL自動優化腳本 echo"=== MySQL Performance Auto-Optimization ===" # 1. 分析慢查詢 echo"Analyzing slow queries..." pt-query-digest /var/log/mysql/slow.log --limit=10 > /tmp/slow_analysis.txt # 2. 檢查表碎片 echo"Checking table fragmentation..." mysql -e" SELECT table_schema, table_name, ROUND(data_free/1024/1024, 2) as data_free_mb FROM information_schema.tables WHERE data_free > 100*1024*1024 ORDER BY data_free DESC;" # 3. 分析索引使用情況 echo"Analyzing index usage..." mysql -e" SELECT object_schema, object_name, index_name, count_star as usage_count FROM performance_schema.table_io_waits_summary_by_index_usage WHERE object_schema NOT IN ('mysql', 'performance_schema') AND index_name IS NOT NULL ORDER BY count_star DESC LIMIT 20;" # 4. 生成優化建議 echo"Generating optimization recommendations..." mysqltuner --outputfile /tmp/mysqltuner_report.txt echo"Optimization report generated at /tmp/"
實戰總結:優化是個系統工程
經過這些年的實戰,我總結出MySQL優化的核心原則:
1.監控先行:沒有監控就沒有優化。建立完善的監控體系是第一步。
2.對癥下藥:不要盲目優化。先找到瓶頸,再針對性解決。
3.小步快跑:每次只改一個參數,觀察效果后再繼續。避免"優化過度"。
4.備份為王:任何優化操作前,先備份。我見過太多"優化變故障"的案例。
5.持續學習:MySQL在不斷進化,8.0的很多特性都值得研究。
寫在最后
MySQL優化不是一蹴而就的,它需要持續的觀察、分析和調整。希望這篇文章能給你一些啟發。如果你在實際工作中遇到了有趣的優化案例,歡迎在評論區分享。
記住:最好的優化是不需要優化。在設計之初就考慮性能問題,比事后優化要輕松得多。
如果這篇文章對你有幫助,別忘了點贊收藏。我會持續分享更多運維實戰經驗,下期我們聊聊"Kubernetes故障排查的18般武藝"。
-
cpu
+關注
關注
68文章
11277瀏覽量
224935 -
數據庫
+關注
關注
7文章
4019瀏覽量
68331 -
MySQL
+關注
關注
1文章
905瀏覽量
29516
原文標題:MySQL性能優化實戰:從慢查詢到億級數據優化的進階之路
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
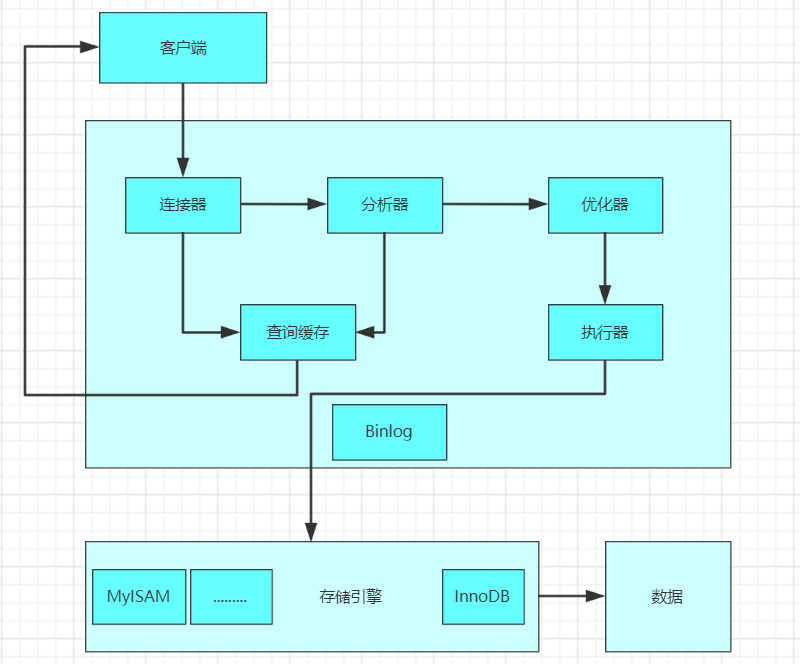

詳解MySQL的查詢優化 MySQL邏輯架構分析
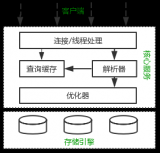
MySQL數據庫:理解MySQL的性能優化、優化查詢




 工商網監
工商網監
評論