 Arm正式取消Cortex命名!CPU向著高算力進發,Lumex CSS平臺加持!
Arm正式取消Cortex命名!CPU向著高算力進發,Lumex CSS平臺加持!

電子發燒友網報道(文/黃晶晶)日前,在ArmUnlocked上海站峰會上,Arm重磅推出智能終端專屬 Lumex CSS平臺。Lumex CSS是一套專為旗艦級智能手機及下一代個人電腦加速其人工智能 (AI) 體驗的先進計算平臺。
CSS是Arm推出的計算子系統,針對不同的應用領域,提供包括Arm Neoverse 計算子系統、面向汽車行業的 Zena、面向移動市場的 Lumex、面向PC市場的Niva,以及面向物聯網和邊緣 AI的Orbis。
Lumex CSS 平臺集成了搭載第二代可伸縮矩陣擴展 (SME2) 技術的最高性能 ArmCPU、GPU及系統 IP,不僅能助力生態伙伴更快將AI設備推向市場,還可支持桌面級移動游戲、實時翻譯、智能助手及個性化應用等多樣的豐富體驗。

取消Cortex命名,Lumex平臺CPU采用新的命名規則
Arm高級副總裁兼終端事業部總經理Chris Bergey表示,在終端業務方面,從Lumex 平臺開始,Arm引入新的命名規則。在這個新命名體系下,Lumex平臺里面的CPU系列會以C1-Ultra、C1-Premium、C1-Pro以及C1-Nano等名稱出現。這一命名體系清晰直觀,能讓整個行業和合作伙伴一目了然。同樣的命名體系也應用于GPU產品線。例如,過去的 “Immortalis” 品牌,現統一采用 Lumex 體系下的Mali命名。關于面向汽車市場的 Zena CSS 平臺,Arm之前介紹過一些信息,但關于面向個人電腦的 Niva CSS 平臺,Arm尚未發布相關信息。
具體來看,搭載SME2的Armv9.3架構在CPU、GPU方面都有較大提升。Arm C1-Ultra CPU是Arm至今推出的性能最強的CPU,其單線程峰值性能較上一代 Arm Cortex-X925 CPU提升高達 25%,非常適合處理嚴苛的 AI 與計算工作負載。針對功耗敏感型的用例,Arm C1-Pro CPU 較 Cortex-A725能效提升幅度達12%。

借助SME2實現AI就緒端側AI性能可提升達五倍,能效可提升三倍。顯著的性能提升還包括語音識別延遲改善超4.7倍,經典大語言模型任務性能提升4.7 倍,生成式 AI 處理速度快2.8倍。
GPU方面,Mali G1-Ultra 集性能與能效于一身,性能提升20% 的同時,每幀能耗也降低9%。該 GPU 在 AI 與機器學習網絡上的推理速度比 Immortalis-G925 快上 20%,光線追蹤性能提升兩倍。
在CSS模式的交付方面,合作伙伴無論是希望選用RTL交付形式的技術授權方式,還是采用接近生產就緒的實現方案,Arm均能提供充分的靈活性與定制化能力,助力合作伙伴借助Lumex CSS快速推進項目,大規模交付具備旗艦級加速性能的豐富AI體驗。
SME2較前代性能的提升
此次,Arm在所有新推出的CPU平臺上全面啟用第二代可伸縮矩陣擴展(SME2) 技術,為開發者帶來更強的AI性能、更低的內存占用,并讓端側AI運行更加流暢,尤其對于音頻生成、攝像頭推理、計算機視覺或聊天交互等對實時性要求嚴苛的應用而言。SME2的推出,標志著端側AI 開發邁入對開發者更為友好的新時代。
Arm終端事業部產品管理副總裁James McNiven解析,SME2是SME的新一代版本。它新增了更多指令集,可進一步提升性能和能效。它支持更小的數據類型——具體而言是2 bit和4 bit,隨著每年高度量化模型的不斷增多,這類小數據類型在移動生態系統中的重要性正日益凸顯。這也是Arm將SME2 整合到Lumex 平臺中的原因所在。
Arm預計到2030年SME和SME2將為超30億臺設備新增超100億TOPS的計算能力。這將使端側AI能力實現指數級飛躍,它將降低成本、減少延遲、增強隱私,整體提升用戶體驗。對開發者而言,這意味著他們能更迅速地將創新成果推向市場。
借助Lumex,Arm助力下一代旗艦級智能手機的快速發展,讓AI真正實現個性化。它具備實時適配能力,從核心到上層進行了全面優化,能將平臺級的智能體驗置于用戶的掌心。
提供額外2到6 TOPS算力,CPU算力對端側AI更友好
James McNiven表示,隨著AI應用的日趨成熟,許多AI工作負載會從云端轉向端側。但云端與端側的混合模式將會長期共存——云端AI不會被取代,只是出于隱私考量,許多AI功能的運行需要同時滿足三個條件:隨時可用、低延遲交付,且必須在端側運行。從功能提供者的視角來看,讓用戶設備承載盡可能多的AI 工作負載以降低云端成本,亦是合理之舉。
因此,若某項工作負載需在端側運行,開發者接下來要做的決策是該讓它在設備的哪個模塊上運行。如今的移動端系統級芯片 (SoC) 非常復雜,它們均配備 CPU(大部分計算工作負載在此運行)與高性能 GPU(專門處理圖形工作負載)。旗艦或高端智能手機還會搭載 NPU,作為 AI 工作負載的專用加速器。

從開發者的角度出發,他們大多需要較強的 CPU,從而進一步為工作負載提供更多靈活性。所以對于Arm來說,重點就是不斷的增強這些平臺的計算體驗。CPU 能夠帶來最大的靈活性,以實現整個生態系統普遍的性能。
那么,在引入SME2之后,CPU的AI性能得到了怎樣的提升呢?
進一步來說,根據具體的實現方案和運行頻率,第二代可伸縮矩陣擴展 (SME2) 在技術上可提供額外2到6 TOPS的算力。James McNiven解析,你可能會想“才 6 TOPS?而一些 NPU 已經超過100 TOPS了。”相比之下這聽起來似乎并不突出。但實際情況是,對于低延遲、模型較小的AI任務,例如圖像預處理、語音識別或實時語境助手,這種級別的算力不僅足夠,往往還綽綽有余。
更重要的是,當今許多 AI 工作負載受限于內存帶寬,而非算力本身。因此,即使 NPU 擁有 100 TOPS 的算力,如果無法足夠快速地提供數據,這種峰值性能也難以被充分利用。通過啟用 SME2 直接在 CPU 核心上運行,能夠以低延遲訪問緩存和系統內存,因此在處理這些規模小、頻繁觸發且對延遲敏感的任務時極為高效。因此,盡管 2 到 6 TOPS 的數值看似不高,但在實際應用中的效率和響應速度上,卻是一次巨大的躍升。此外,SME2 還帶來了可編程性優勢。與功能固定的 NPU 不同,它能適應不斷演進的各類 AI 模型和用例。
當然,NPU不會消失,GPU上的推理也不會被取代。Arm 深信不同的計算單元有不同的長處,各自針對不同類型的 AI 工作負載進行優化。NPU擅長高吞吐量、大模型的推理任務,例如大語言模型 (LLM)、視覺 Transformer;GPU更適合并行性強、與圖形相關的 AI 任務,例如渲染加上 AI 圖形優化升級;而搭載 SME2 的 CPU,則在需要與系統邏輯緊密集成的低延遲、持續在線的小模型任務中有卓越表現。
這些計算單元并非相互競爭,而是相輔相成。SME2 帶來了全新的靈活性,尤其對那些希望AI特性能夠在盡可能多的設備上運行的第三方開發者而言,這個靈活性意義重大,包括那些沒有專用NPU的設備。因為每一臺基于 Arm 架構的智能手機都具備 CPU,且在不久的將來,許多智能手機都將支持啟用 SME2 的CPU 核心。這意味著開發者可以依賴一個一致且廣泛可用的 AI 加速層,無需擔心硬件碎片化的問題。
在AI計算時代,Arm 的產品體系從 IP 到計算子系統 (CSS),再到“AI 優先”的計算平臺。這項著眼“平臺優先”的產品戰略,整合了高性能 CPU/GPU 硬件、KleidiAI 軟件工具及集成庫,構建起“芯片-軟件-工具”的端到端平臺。憑借卓越的性能、能效和可擴展性,該計算平臺能助力合作伙伴實現快速集成,降低研發復雜度與規模化風險,滿足 AI 時代的多樣化需求。
發布評論請先 登錄
Hailo-8算力卡 + RK3588實測!26TOPS加持,助力AI視覺升級!

Genio 720處理器規格參數_MTK8391高算力核心板方案
Arm Lumex平臺賦能新一代旗艦智能手機體驗升級

MWC Doha 2025|美格智能全新發布60 Tops AI算力、支持Linux系統的SNM982高算力AI模組

從CPU、GPU到NPU,美格智能持續優化異構算力計算效能
全新Arm Lumex CSS平臺加速開發周期

全新Arm Lumex CSS平臺實現兩位數性能提升

Arm Zena CSS加速軟件和芯片開發進程
Arm產品命名體系的演變


Arm 公司面向移動端市場的 ?Arm Lumex? 深度解讀
Arm 公司面向汽車市場的 ?Arm Zena? 深度解讀
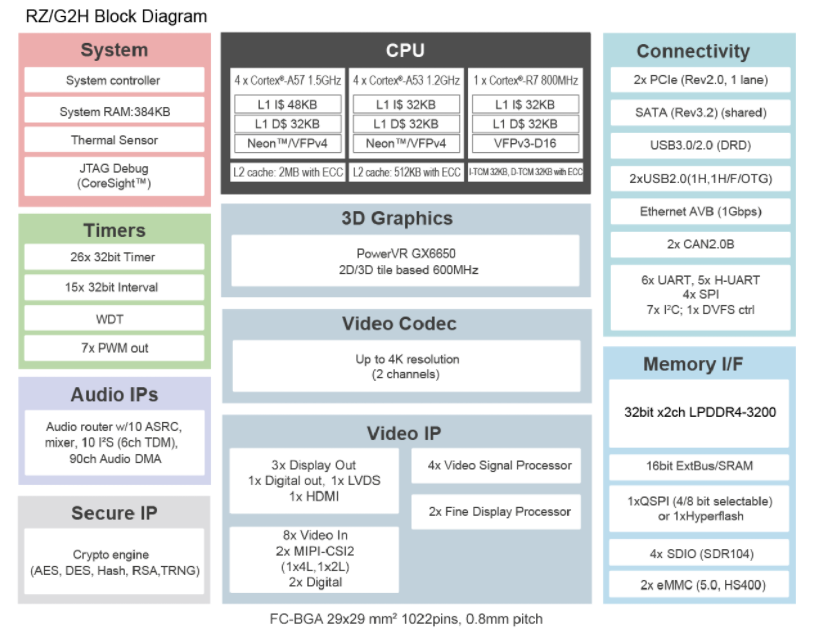
帶四核Arm Cortex-A57和四核Arm Cortex-A53 CPU的RZ/G2H超高性能微處理器數據手冊



 工商網監
工商網監
評論