") 基于Vulkan的端側(cè)AI運(yùn)算
基于Vulkan的端側(cè)AI運(yùn)算

【拆·應(yīng)用】是為開源鴻蒙應(yīng)用開發(fā)者打造的技術(shù)分享平臺,是匯聚開發(fā)者的技術(shù)洞見與實(shí)踐經(jīng)驗(yàn)、提供開發(fā)心得與創(chuàng)新成果的展示窗口。誠邀您踴躍發(fā)聲,期待您的真知灼見與技術(shù)火花!
引言
本期內(nèi)容由AI Model SIG提供,介紹了在開源鴻蒙中,利用圖形接口Vulkan的計(jì)算著色器能力,在端側(cè)部署大模型的的整體思路和實(shí)踐分享。
開源鴻蒙是由開放原子開源基金會孵化及運(yùn)營的開源項(xiàng)目,目標(biāo)是面向全場景、全連接、全智能時(shí)代,搭建一個(gè)智能終端設(shè)備操作系統(tǒng)的框架和平臺,促進(jìn)萬物互聯(lián)產(chǎn)業(yè)的繁榮發(fā)展。在人工智能時(shí)代下,與其它成熟的操作系統(tǒng)相比,開源鴻蒙部署AI LLM模型的能力欠缺。為了補(bǔ)齊開源鴻蒙在端側(cè)部署大模型的能力,筆者將分享如何在端側(cè)打通大模型部署的整體思路和實(shí)踐。
軟硬件選型
在硬件上選取國產(chǎn)CPU飛騰D2000,顯卡選用AMD GPU。目前能夠在OpenHarmony5.0.0 Release上點(diǎn)亮AMD GPU,包括RX 550、RX 580和RX 7900 XTX。
其次是推理框架的選擇,筆者選取了llama.cpp這個(gè)開源的推理框架,倉庫地址為:github.com/ggml-org/llama.cpp。目前很火的ollama,其也是選用了llama.cpp作為推理后端。llama.cpp是一個(gè)專注于在邊緣設(shè)備、個(gè)人PC上進(jìn)行l(wèi)lm部署的高性能推理框架。其相比于vllm等主流llm推理框架來說,有以下明顯的優(yōu)點(diǎn):
純 C++/C 實(shí)現(xiàn),在Windows、mac、Linux等多種系統(tǒng)下編譯都非常簡單。
豐富的后端支持:如圖所示,支持x86、arm、Nidia_GPU、AMD_GPU、Vulkan甚至華為昇騰NPU_CANN。
支持CPU AVX指令集進(jìn)行矢量計(jì)算加速、CPU多核并行計(jì)算、CPU+GPU混合計(jì)算
支持低精度量化:1.5bit、2 bit、3 bit、4 bit、5 bit、6 bit和 8 bit整數(shù)量化,可加快推理速度并減少內(nèi)存使用。
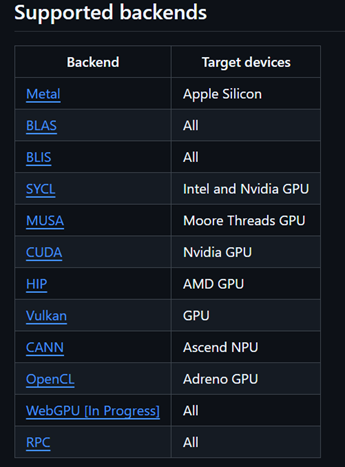
llama.cpp支持的后端及其硬件
在上圖中,llama.cpp支持Vulkan后端。筆者通過查閱相關(guān)資料和閱讀llama.cpp關(guān)于Vulkan的相關(guān)代碼,發(fā)現(xiàn)其是利用圖形接口Vulkan的計(jì)算著色器(Compute Shader)的能力來運(yùn)行大模型的。計(jì)算著色器(Compute Shader) 是GPU上用于通用計(jì)算(GPGPU) 的特殊程序,與傳統(tǒng)圖形渲染管線解耦,可直接操作GPU并行處理非圖形任務(wù)(如AI推理、物理模擬、數(shù)據(jù)處理)等。下表是計(jì)算著色器的特點(diǎn):
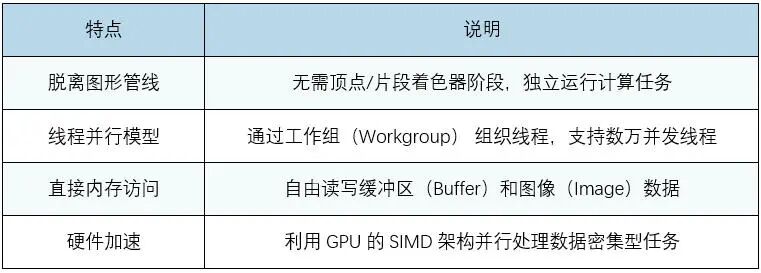
綜合多因素的考量,在軟硬件上最終選用飛騰D2000 + AMD GPU + OpenHarmony 5.0.0 Release的組合,利用圖形接口Vulkan的計(jì)算著色器能力,在終端設(shè)備上高效運(yùn)行大模型。
在開源鴻蒙部署大模型的難點(diǎn)
在第一部分提到將利用圖形接口Vulkan的計(jì)算著色器的能力,在端側(cè)高效運(yùn)行大模型。在開源鴻蒙社區(qū)有個(gè)Vulkan的demo樣例,倉庫地址為:https://gitee.com/openharmony/applications_app_samples/tree/master/code/BasicFeature/Native/NdkVulkan,通過筆者的實(shí)踐,目前在HarmonyOS能跑通該樣例,但是在開源鴻蒙上尚不能跑通該樣例。通過閱讀該例子的文檔說明,如下圖,發(fā)現(xiàn)核心原因是缺少AMD GPU的Vulkan用戶態(tài)驅(qū)動庫libvulkan_radeon.so以及Vulkan的sdk。因此核心難點(diǎn)是要能將Vulkan的計(jì)算著色器在開源鴻蒙上正常跑起來。
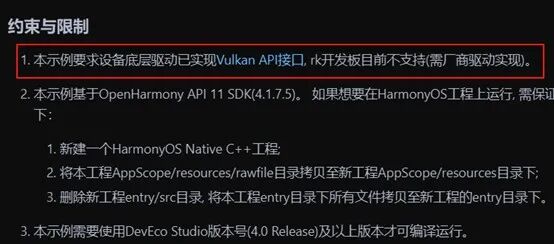
NdkVulkan例子
整體思路
為了能夠利用圖形接口Vulkan的計(jì)算著色器的能力跑大模型。筆者總結(jié)了以下四個(gè)的關(guān)鍵步驟:
在開源鴻蒙上正常點(diǎn)亮AMD GPU。
交叉編譯出AMD的Vulkan用戶態(tài)驅(qū)動。
交叉編譯出Vulkan sdk。
移植llama.cpp到OpenHarmony上。
實(shí)踐要點(diǎn)
點(diǎn)亮AMDGPU
1.確保AMD GPU 內(nèi)核態(tài)是正常的選用的內(nèi)核版本為linux 6.6.22,需要將內(nèi)核的以下選項(xiàng)打開。

系統(tǒng)正常啟動后,采用modetest工具進(jìn)行測試,在測試前需要關(guān)閉render_service、composer_host和allocator_host這三個(gè)進(jìn)程,具體的命令如下:

在hdc shell中運(yùn)行以下命令:
如果能夠在顯示屏上看到彩色的條紋,如下圖,說明AMD GPU的內(nèi)核態(tài)是正常的。
modetest測試結(jié)果
2.確保AMD GPU的用戶態(tài)是正常的
首先通過mesa3d交叉編譯出AMD GPU的用戶態(tài)驅(qū)動,主要為libEGL.so.1.0.0、libgallium_dri.so、libgbm.so.1.0.0、libglapi.so.0.0.0、libGLESv1_CM.so.1.1.0和libGLESv2.so.2.0.0這個(gè)5個(gè)動態(tài)庫。
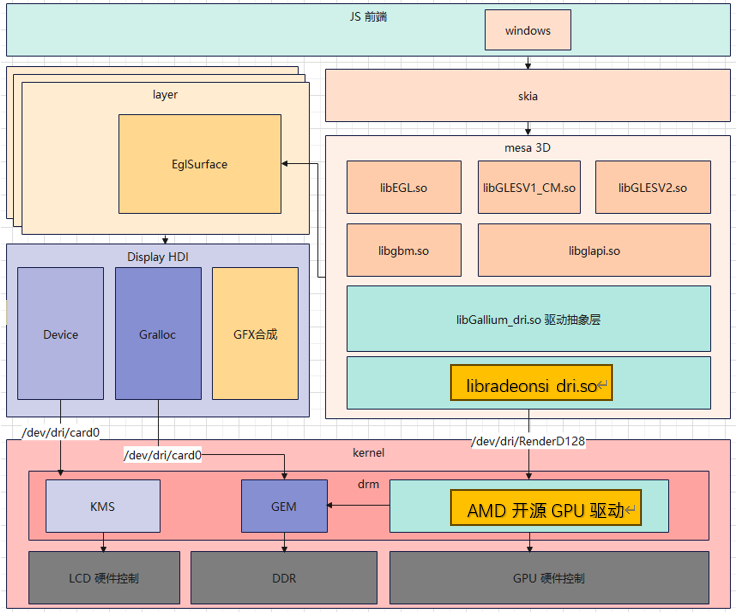
大家可以參考laval社區(qū)的《開源鴻蒙開源GPU庫Mesa3D適配說明》這篇文章,了解GPU的適配過程,鏈接地址為:https://laval.csdn.net/64804567ade290484cb2ed06.html
這篇文章主要講的是mali gpu的mesa3d點(diǎn)亮過程。由于跑Vulkan的計(jì)算著色器可以不用到顯示的功能,因此在這里具體的適配過程就不展開,感興趣的讀者可在AI Model SIG的ohos_vulkan倉庫獲取相關(guān)的AMD GPU 的mesa用戶態(tài)驅(qū)動的庫,倉庫地址為:https://gitcode.com/ai_model_sig/ohos_vulkan 成功適配后,可以在顯示屏正常看到開源鴻蒙的桌面。
Vulkan用戶態(tài)驅(qū)動
這一步的核心是能夠獲得libvulkan_radeon.so這個(gè)動態(tài)庫。在mesa3d中有Vulkan用戶態(tài)驅(qū)動的實(shí)現(xiàn),因此通過編譯mesa3d這個(gè)開源項(xiàng)目編譯出libvulkan_radeon.so這個(gè)Vulkan用戶態(tài)驅(qū)動庫。
在build_ohos.py文件中需要指定 -Dgallium-drivers=amd 和 -Dvulkan-drivers=amd這兩個(gè)參數(shù),如下圖:
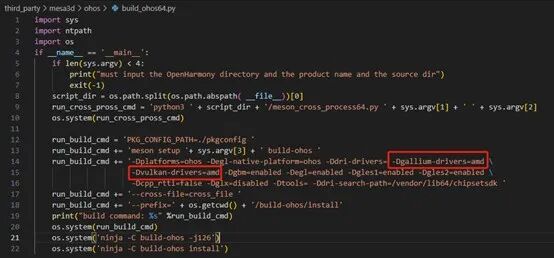
通過以下指令:
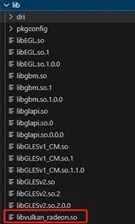
便可以編譯出libvulkan_radeon.so這個(gè)動態(tài)庫,如下圖所示
Vulkan sdk
Vulkan sdk的構(gòu)成主要包含以下11個(gè)項(xiàng)目:
https://github.com/KhronosGroup/glslang.git
https://github.com/KhronosGroup/SPIRV-Headers.git
https://github.com/KhronosGroup/SPIRV-Tools.git
https://github.com/zeux/volk.git
https://github.com/KhronosGroup/Vulkan-ExtensionLayer.git
https://github.com/KhronosGroup/Vulkan-Headers.git
https://github.com/KhronosGroup/Vulkan-Loader.git
https://github.com/KhronosGroup/Vulkan-Tools.git
https://github.com/KhronosGroup/Vulkan-Utility-Libraries.git
https://github.com/KhronosGroup/Vulkan-ValidationLayers.git
在這里需要通過交叉編譯的方式獲得aarch64版本的產(chǎn)物,如下圖所示。
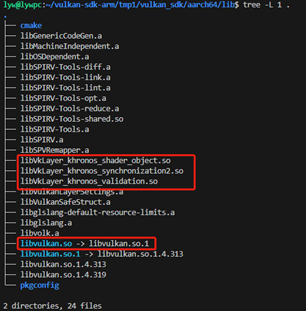
Vulkan sdk的編譯比較復(fù)雜,這里不進(jìn)行展開,讀者可以通過這個(gè)鏈接下載:
https://gitcode.com/ai_model_sig/ohos_vulkan/pull/1
下面介紹一下如何將Vulkan sdk部署在開源鴻蒙上:
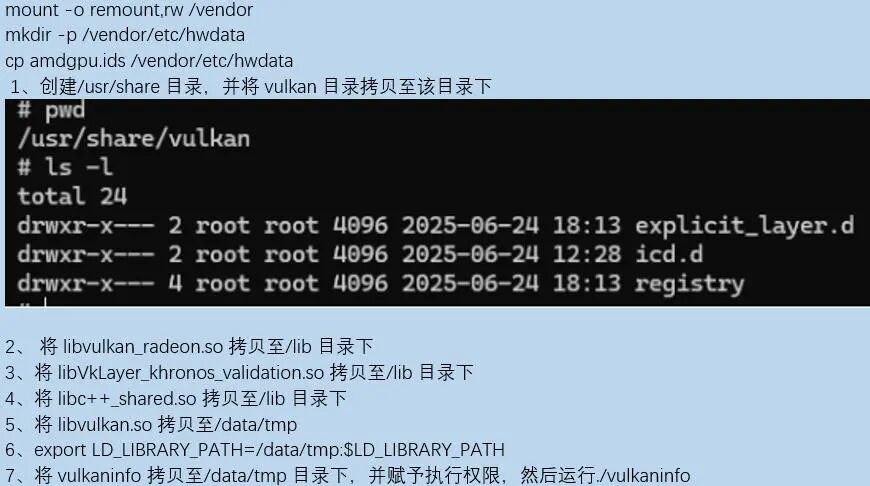
通過運(yùn)行vulkaninfo可以獲取vulkan的相關(guān)信息,也能獲取我們所用GPU的型號。

目前我們能將Vulkan在開源鴻蒙上正式跑起來了,接下來需要寫一個(gè)簡單的例子來驗(yàn)證Vulkan的計(jì)算著色器是否正常。筆者提供了一個(gè)簡單的利用計(jì)算著色器來進(jìn)行矩陣并行計(jì)算,大家可以通過laval社區(qū)的這篇文章詳細(xì)了解一下,文章鏈接:
https://laval.csdn.net/685bdb3d965a29319f2773cb.html
該例子的核心就是矩陣A和矩陣B相乘的到矩陣C,矩陣C的每個(gè)元素需要做256次乘法和255次加法。
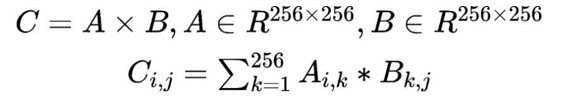
下面是例子的具體內(nèi)容:
整體流程:初始化Vulkan → 創(chuàng)建矩陣緩沖區(qū) → 構(gòu)建計(jì)算管線 → 提交計(jì)算任務(wù) → 同步獲取結(jié)果 → 驗(yàn)證輸出 → 資源釋放;
編寫計(jì)算著色器,如下圖;
并行策略:每個(gè)線程計(jì)算輸出矩陣的一個(gè)元素;
工作組配置:每個(gè)工作組包含16x16=256個(gè)并行線程;
執(zhí)行粒度:與主程序中的vkCmdDispatch(MATRIX_SIZE/16, MATRIX_SIZE/16, 1)配合,共調(diào)度 (256/16)^2 = 256個(gè)工作組覆蓋整個(gè)矩陣;
線程總數(shù):256 * 256 = 65536 個(gè)并行線程。

計(jì)算著色器
假設(shè)矩陣A的元素全為1,矩陣B的元素全為2,那么矩陣C的計(jì)算結(jié)果應(yīng)該全為512。如下圖可見矩陣C的計(jì)算結(jié)果正確,總耗時(shí)大概在5毫秒左右。通過對比矩陣C的結(jié)果和耗時(shí),初步可以確認(rèn)Vulkan的計(jì)算著色器能在開源鴻蒙上正常運(yùn)行。
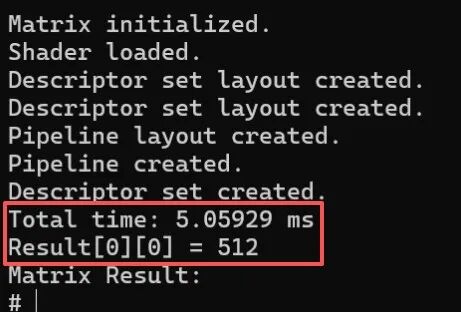
矩陣C的計(jì)算結(jié)果
推理框架 llama.cpp
利用前一步得到的Vulkan sdk,接下來需要交叉編譯出llama.cpp。下面是交叉編譯的命令。

最終我們將編譯的產(chǎn)物拷貝至開源鴻蒙設(shè)備上,然后運(yùn)行。可以看到llama.cpp能夠正確識別我們的AMD GPU并將模型的權(quán)重加載至顯卡上。

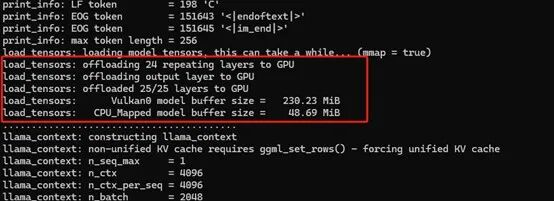
總結(jié)
本文主要分享了如何在端側(cè)打通大模型部署的整體思路和實(shí)踐,從而補(bǔ)齊開源鴻蒙在端側(cè)部署大模型的能力。目前能夠利用圖形接口Vulkan的計(jì)算著色器的能力,能夠在端側(cè)的AMD的消費(fèi)級顯卡AMD 7900XTX上部署類似DeepSeek 32B這類的大模型,從而打造了AI能力的算力底座,為AI應(yīng)用提供支撐。
-
cpu
+關(guān)注
關(guān)注
68文章
11310瀏覽量
225586 -
AI
+關(guān)注
關(guān)注
91文章
40578瀏覽量
302171 -
開源
+關(guān)注
關(guān)注
3文章
4280瀏覽量
46347 -
大模型
+關(guān)注
關(guān)注
2文章
3715瀏覽量
5239
原文標(biāo)題:拆·應(yīng)用丨第6期:基于Vulkan的端側(cè)AI運(yùn)算
文章出處:【微信號:gh_e4f28cfa3159,微信公眾號:OpenAtom OpenHarmony】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

端側(cè)AI浪潮已來!炬芯科技發(fā)布新一代端側(cè)AI音頻芯片,能效比和AI算力大幅度提升

首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
億智電子攜手合作伙伴推動端側(cè)AI產(chǎn)業(yè)的快速發(fā)展
榮耀引領(lǐng)端側(cè)AI新時(shí)代
廣和通端側(cè)AI解決方案驅(qū)動性能密集型場景商用型場景商用

把握關(guān)鍵節(jié)點(diǎn),美格智能持續(xù)推動端側(cè)AI規(guī)模化拓展

把握關(guān)鍵節(jié)點(diǎn),美格智能持續(xù)推動端側(cè)AI規(guī)模化拓展

廣和通開啟端側(cè)AI新時(shí)代
中信建投建議關(guān)注端側(cè)AI模組機(jī)會
廣和通Fibocom AI Stack:加速端側(cè)AI部署新紀(jì)元
AI大模型端側(cè)部署正當(dāng)時(shí):移遠(yuǎn)端側(cè)AI大模型解決方案,激活場景智能新范式

AI大模型端側(cè)部署正當(dāng)時(shí):移遠(yuǎn)端側(cè)AI大模型解決方案,激活場景智能新范式

炬芯科技探索端側(cè)AI技術(shù)與應(yīng)用
借助谷歌LiteRT構(gòu)建下一代高性能端側(cè)AI




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論