 在樹莓派Pico上運用不同的并行化手段
在樹莓派Pico上運用不同的并行化手段

以下文章來源于嵌入式系統專家之聲,作者Martin Ossmann
Martin Ossmann博士(德國)
翻譯:何靈淵
樹莓派Pico由RP2040微控制器驅動,其上搭載兩個CPU核,這讓它非常適合探索并行計算。本文通過真實的數字信號處理樣例來說明從雙核架構中提取最大價值的方法和考量。
本文中的樣例運用了不同的并行化手段。通過雙核處理器來加速一個程序的理論上限值為2,我們簡稱為S = 2。在下面的討論中,我們會給出每一個樣例的加速系數。
同步和“易變”屬性
在多核CPU上編程時,時常需要讓線程同步它們的活動。在下面這個最簡單的例子中,核0可以激活核1,通過變量trigger就可以實現。

圖1
兩個核都會使用變量trigger,為了讓編譯器知道變量的值由于多個線程都可使用,隨時可以改變,添加了“易變”(volatile)屬性。沒有這個屬性,編譯器可能會進行深入的代碼優化,這也許會對兩個線程的共享、并行使用造成不良影響。
共享函數的使用
下面的例子演示了核0和核1可以同時使用一個函數。

圖2
函數delay(nn, cnt)中會打印消息列出正在運行的核和cnt的值,然后會進入等待循環執行nn次(使用本地變量k)。
核0和核1一樣運行無限循環。循環內會調用delay函數,核0和1的nn參數分別為10000000和20000000,因此核1在delay函數中會執行雙倍于核0次數的循環。cnt變量會跟蹤循環執行的次數。兩個核多數時間都會同時在delay函數中。函數的共享是如何做到的呢?函數的代碼只會在內存中儲存一份,兩個核會執行同樣的代碼。代碼中只有讀指令,所以只是訪問代碼并不會造成沖突。
兩個核當然有自己的程序計數器(PC),其中記載代碼指令的地址(代碼進行到了第幾步)。當函數被調用時,PC的值會入棧,參數也會入棧,然后會在棧上預約空間存儲本地變量(這里是k)。這一系列存儲在棧中的變量也被叫做棧幀。PC接下來會載入被調用函數的起始地址。
兩個核有獨立的棧和棧幀,所以即使代碼是共享的,兩個核也各自有一個delay函數的“實例”,代碼相同但是棧幀不同。如果delay函數中使用全局變量或者其他全局資源,分割就不復存在了,并行使用會導致問題。本例說明了并行編程需要考慮的問題。
核0可以影響核1的速度
下一個例子中我們將演示兩個核如何會以不明顯的方式互相影響。

圖3
核1運行簡單的無限循環,核0同樣運行無限循環,但是會將GPIO2設為高電平,等待625個周期,將GPIO2設為低電平,然后再等待625個周期。當核1不運行時,以Pico默認時鐘頻率125MHz運行的核0每秒會運行10萬次循環(125MHz/(2*625周期)),這會在GPIO2上輸出一個100kHz頻率的矩形波。當核1開始執行時,核0的這一輸出信號頻率會降到75kHz。盡管兩個核之間沒有明顯的關聯,它們還是會互相影響。這其中的可能原因是兩個核共用同一個內存接口,這一現象通常可以解釋為什么本文中程序的加速系數S一般都明顯低于2。
本例突出了并行程序中存在的意想不到的效果,調試這樣的并行程序可能會很有挑戰性。
先入先出(FIFO)通信
你可以通過兩個FIFO在兩個核之間安全地傳輸數據,一個從核0向核1發送數據,另一個從核1向核0發送數據。Pico SDK中的FIFO是線程安全的,意味著即使并行使用也能正常運行。
為了測試FIFO的性能,我們可以在核1上實現一個簡單的“服務器”:

圖4
這段代碼等待核0從FIFO發送數據,將得到的數字增加1000后返回給核0。
核0上運行的代碼如下:

圖5
運行時測量的數據表明,這段代碼大概需要0.62微秒。因為每次傳輸的數據為32位,這等同于104Mbit/s。下面這一計數循環用于比較樹莓派Pico的計算速度和數據傳輸率:

圖6
測量數據表明,每次循環需要大約56納秒。如果我們讓服務器運行N = 10次,計算時間大約560納秒,通信時間620納秒,通信的開銷比例大于100%。因此,如果不想要通信開銷影響整體性能,服務器需要大幅提高計算能力。在并行計算環境中編程時,最好不要過于關注程序中最小的細節。除了FIFO,SDK也提供了隊列,幫助傳輸任意數據結構,提供更大的靈活性。另外,SDK提供多種線程同步機制,推薦細致學習SDK提供的功能。
軟件定義無線電(SDR)的并行化
圖7所示的是SDR前端的組成,在將輸入信號和本機振蕩器(LO)信號相乘后,你得到了I頻道(同相)和Q頻道(正交)。兩個頻道幾乎是并行的,非常適合并行計算。核0處理I頻道的數據,核1處理Q頻道的數據。混合后的相加依然由中斷例程處理。第一個并行的部分是巴特沃斯濾波器的實現,使用單精度浮點數。在圖8中,你可以看到低通濾波器的時間特征。
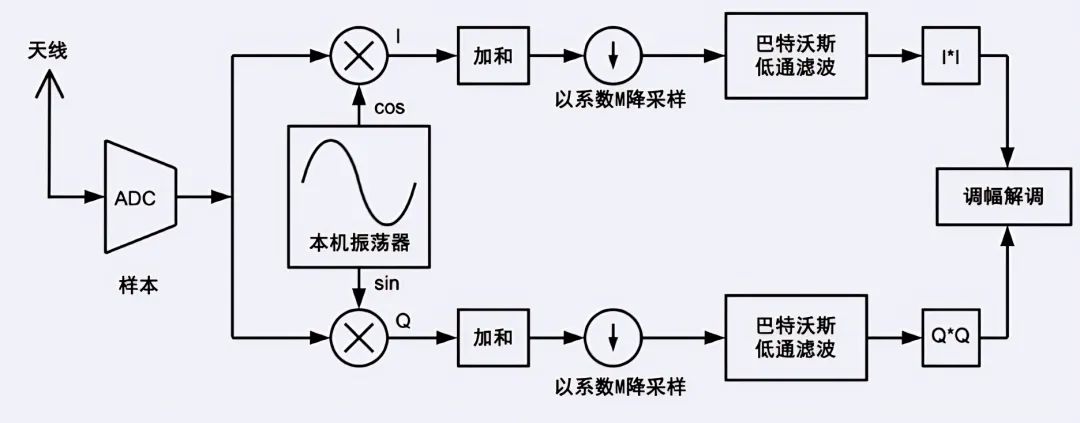
圖7 SDR前端的信號流動
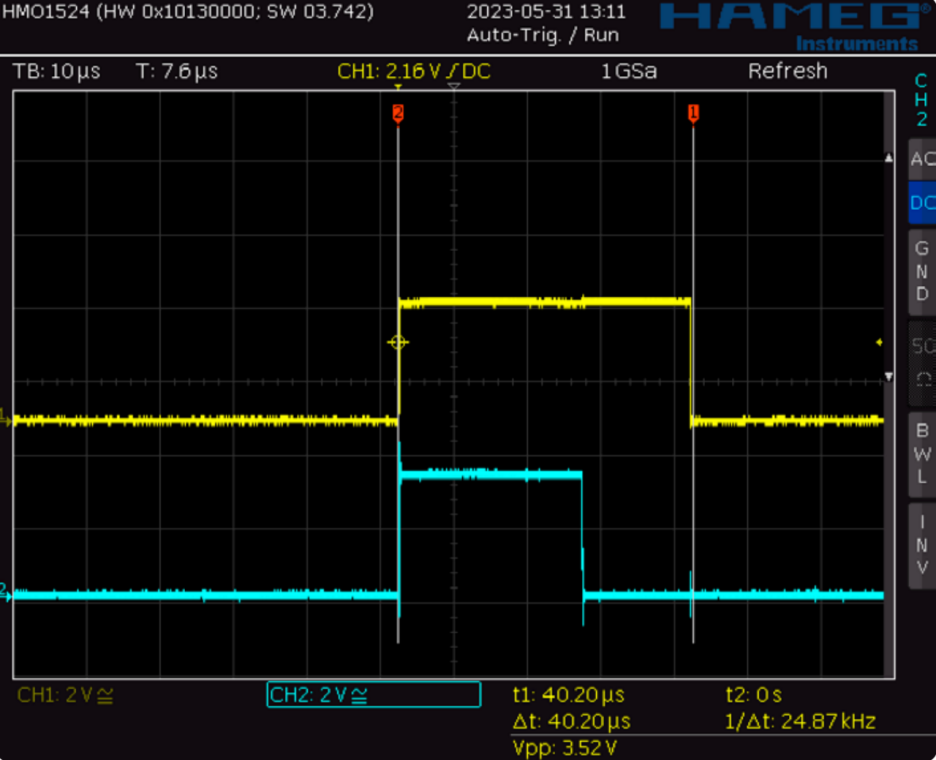
圖8 I和Q低通濾波器例程的執行
核0進行I頻道低通濾波器計算時會輸出黃色的“高電平”,核1進行Q頻道低通濾波器計算時會輸出藍綠色的“高電平”。有趣的是,I頻道的計算需要更長時間,這是因為核0也執行中斷例程進行取樣,所以核0并不是一直可以使用,I頻道的計算于是需要更長時間。
標量積和循環分割
另一個樣例是標量積的計算。并行計算是基于以下的觀察:通常一組計算以循環進行,如果一個循環中的元素可以單獨計算,一個循環可以被分隔為兩個部分,由兩個核并行處理。計算兩個向量x和y的標量積的公式如下圖所示:
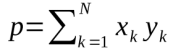
圖9
程序中的skpLoop例程會通過下面的算式計算k1到k2的加和:
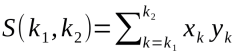
圖10
在非并行的版本中,1到N的值會被直接加和。在并行的版本中,1到N/2和N/2到N的加和是并行進行的,算式如下圖所示:
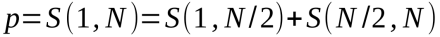
圖11
最終結果通過兩個部分相加得到。核0和核1同時使用skpLoop中的加和循環。因為循環由兩個核分別使用,矩陣xk和yk各自不同,所以沒有沖突。這一程序的加速系數S = 1.8,程序代碼如圖12所示。

圖12串行和并行標量積計算
有限脈沖響應(FIR)濾波器
FIR濾波器在數字信號處理應用中有著廣泛應用。在N階的FIR濾波器中,當前輸出值的計算需要將最后N個信號的值進行加和,期間會將樣本和脈波響應系數ak相乘,公式如下圖所示:
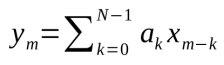
圖13
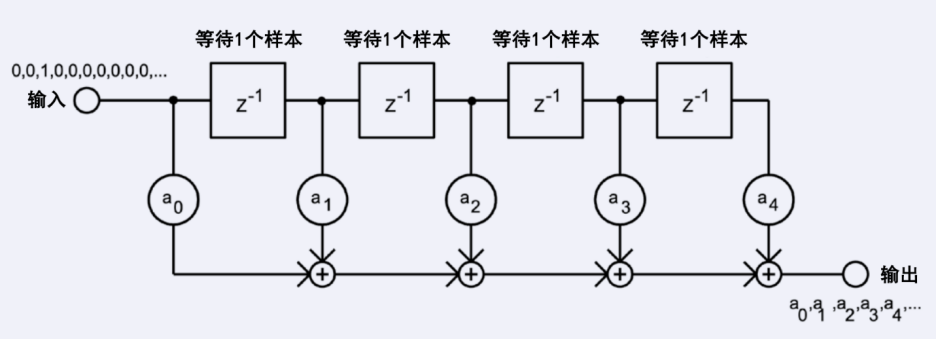
圖14 FIR濾波器的信號流動
計算中需要將最后N個輸入值xk存儲起來,這可以通過一個環形緩沖區很容易地進行。計算的并行化和其他標量計算類似,可以通過循環分割來進行。你只需要正確地管理環形緩沖區和使用腳標。循環的邏輯如下圖所示:

圖15
readPtr參數指向環形緩沖區xBuf的起始位置。并行的FIR計算如下圖所示:

圖16
本程序的加速系數S = 1.7。
程序開發
調試并行程序經常既復雜又有挑戰性。一般可以首先在一個更為靈活的環境中編寫一個版本的程序作為參考版本,像是一個開源、免費的處理環境,然后在那里進行調試。在這一過程中,你可以生成用于并行的測試數據。這一版本的軟件成型后可以移植到目標系統上,并用同樣的測試數據進行測試。調試時你可以比較兩個版本的軟件行為。
帶流水線的無限脈沖響應(IIR)濾波器
在數字信號處理中,IIR濾波器十分常用。IIR濾波器是一由系列雙二階單元(圖17)組成的。非并行的形式中,一個單元的輸入和上個單元的輸出一致,也就是計算單元2前必需完成單元1的計算。
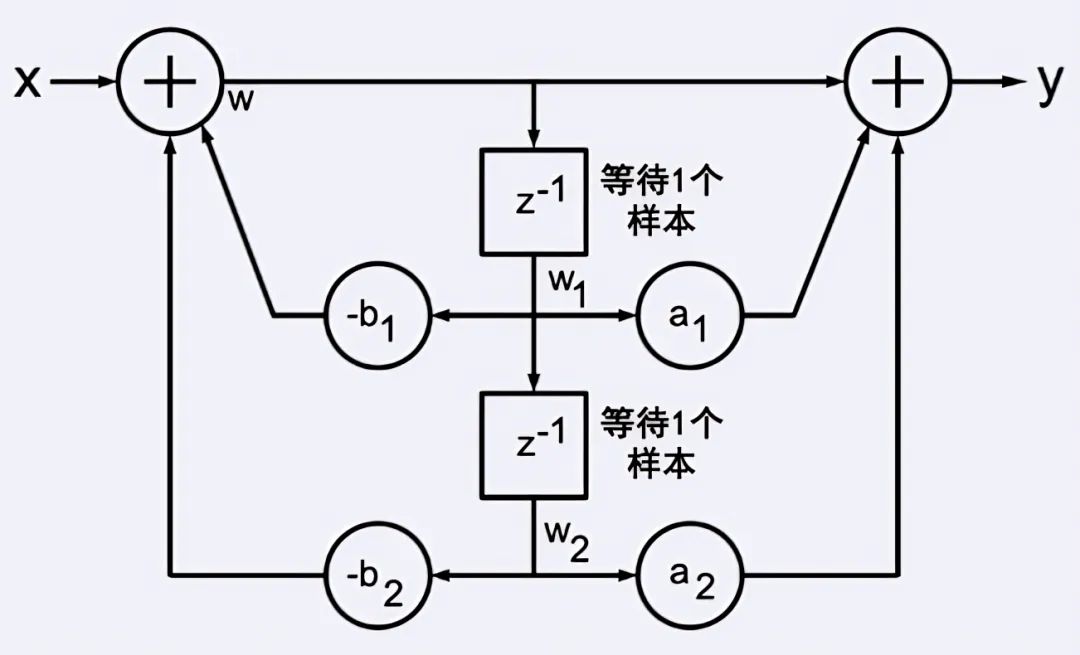
圖17一個雙二階單元
每個單元取決于上一個單元的結果,用代碼表示如下圖所示:

圖18
這使得雙二階單元計算的并行化變得困難,不過我們可以應用一種流水線技巧。流水線的概念是從實現快速的處理器開始的,將指令的執行分割為取指令、解碼和執行三個步驟,不同命令的不同步驟可以同時執行。
當讀取指令Ik時,上一個指令I(k-1)已經被解碼,再上一個指令I(k-2)正在執行中(圖19)。這樣的并行處理能提高輸出,單個指令并沒有提速。
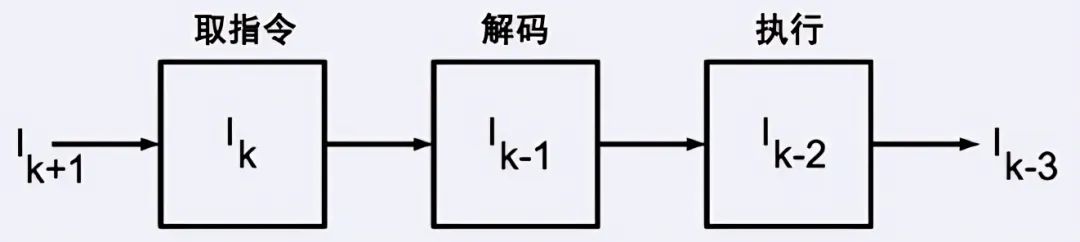
圖19 CPU中的流水線
這一概念可以應用到IIR濾波器上,代碼如下圖所示:

圖20
這里增加的中間值inp1到inp4讓單元的計算互為獨立,雙二階計算可以并行,這正是雙核CPU上運行IIR濾波器的方法。這里的方法加速系數S大約為1.8。
就地執行(XIP)功能
如果你多次運行IIR濾波器并測量時間,你會有令人驚訝的發現(表1)。首次運行需要大約64微秒,這是后面運行的2.5倍左右。這一加速可以從RP2040訪問代碼存儲的角度解釋。代碼在串行QPSI閃存中存儲,CPU可以像直接訪問CPU中數據一樣訪問(所以是就地執行,eXecute In Place——XIP)。由于閃存的訪問使用串行接口,速度相對較慢。為了加速,XIP接口上有一個基于快速RAM的緩存,其中存儲最近剛讀取的內存字,所以同樣位置的內存不需要經過QPSI接口,而是直接從緩存讀取。
表1 IIR濾波器執行時間
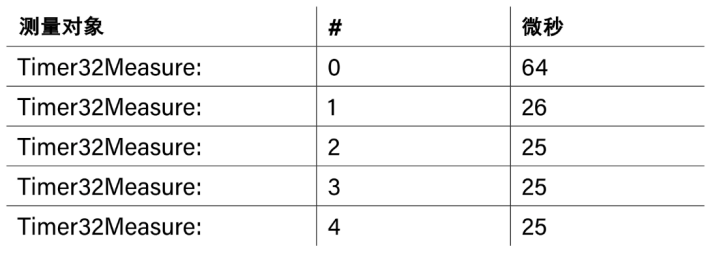
這一過程可以解釋運行時間的數據。首次運行時,代碼不能使用緩存,QSPI訪問既慢又是串行性的。代碼載入到緩存之后,再運行的速度就會變快。這從一方面說明現代CPU運行時行為的復雜性。你需要了解這樣的機制,才能得到正確和可靠的結果。
快速傅里葉變換(FFT)
在數字信號處理中,快速傅里葉變換(FFT)時常用于分析信號。FFT計算由所謂的“蝴蝶操作”組成,蝴蝶操作中的數據流動如圖21所示。
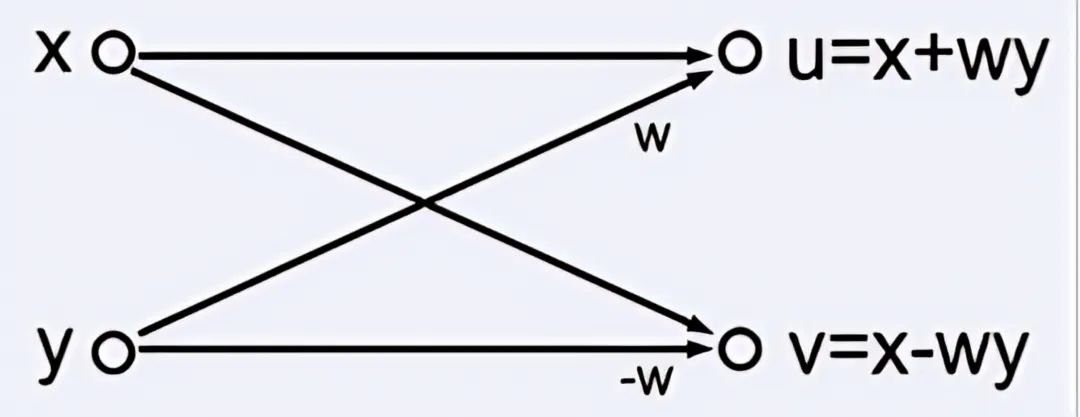
圖21蝴蝶操作中的信號流動
圖中系數w為與蝴蝶操作相關的相位的余弦。
圖22表示N = 16時的數據流動,共進行log2N = 4次迭代,每次進行N/2個蝴蝶操作。在一次迭代中,蝴蝶操作互相獨立,所以可以并行執行。一半的蝴蝶操作由核0執行,另一半由核1執行,每個核會執行N/4個蝴蝶操作。加速系數S = 1.85。
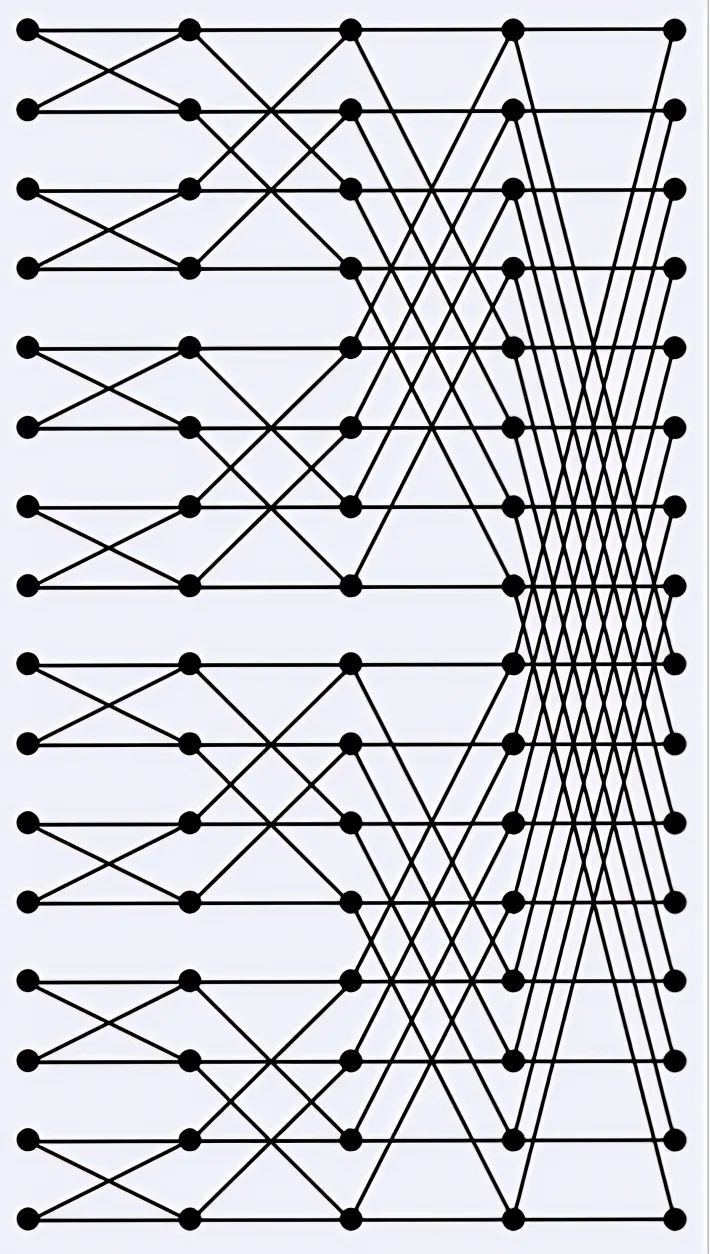
圖22 16-點FFT的信號流動
霍納法則
現在讓我們把話題轉向如何處理x階的多項式。在下面的例子中,多項式為5階,算式為:
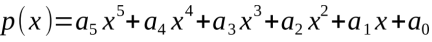
圖23
求值需要N-1次乘法計算x的次方,N-1次與系數ak相乘,以及N次加法運算。霍納法則給出了更加高效的計算方法。例如,可以通過下圖中第一行的算式迭代計算5階p(x)的值(譯者注:p0為最終結果,第二和第三行通過展開多項式來證明p0和原多項式相等):
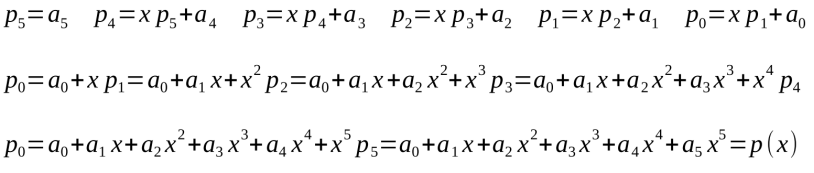
圖24
最后,你會得到p(x)的值,而且只進行了N次乘法和N次加法,也就是說,總共節省了N-1次乘法。霍納法則不能并行化,這是因為pk的值互相依賴,但是多項式本身可以被分割為兩部分,如下圖的算式所示:
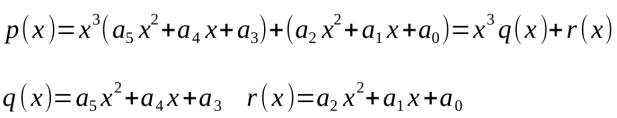
圖25
現在我們可以同時求多項式q(x)和r(x)的值。要得到p(x)的值,只需要用x3(既x(N+1)/2)乘以q(x)加上r(x)。x(N+1)/2的快速計算非常重要,這可以通過利用連續乘方的結果1,x,x2,x4,x8,x16…來計算,例如x9= x8*x,計算需要log2N次。log2N相比N很小(特別是N很大時),計算會很快,不會特別影響性能。
N = 100時,在樹莓派Pico上運行非并行版本需要133微秒,霍納法則加上多項式分割的版本,兩個核各自需要71微秒,將兩者快速加和需要7微秒,也就是說并行算法需要78微秒,加速系數S = 133/78 = 1.7。x(N+1)/2的計算確實會影響效率,但是總體的提速效果依然很明顯。
線性代數
除了點積,矩陣向量積也可以并行化,加速系數S = 1.6。線性方程組也可以并行化,S = 1.8。兩個解決方案都使用了簡單的循環分割方法。
真正的高效率
通過探索本文中的一系列實例,可以看到在雙核的樹莓派Pico上能夠有效地將任務的執行過程并行化。實踐中一些例子能達到S = 1.8,非常接近理論上限S = 2。最佳的并行策略需要合適的算法,尋找這樣的算法的過程尤為重要。只有能夠將任務分割,并獨立、分別執行的方法,才能從并行處理中獲得最大的效率提升。
關于作者
Martin Ossmann
Martin Ossmann在12歲時就開始閱讀Elektor雜志和動手實驗了。在學習電子工程,并作為工程師工作數年之后,他成為了德國亞琛應用科學大學電子工程和信息技術系的一名教授。他不僅是若干科學著作的作者,30年來他時常在Elektor雜志上發表新的電路或是軟件項目,展示他豐富的專業知識。
-
微控制器
+關注
關注
48文章
8425瀏覽量
164856 -
cpu
+關注
關注
68文章
11294瀏覽量
225344 -
Pico
+關注
關注
0文章
188瀏覽量
18549 -
樹莓派
+關注
關注
122文章
2080瀏覽量
110539
原文標題:樹莓派Pico雙核編程——邁入并行計算的世界
文章出處:【微信號:麥克泰技術,微信公眾號:麥克泰技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
在樹莓派Pico RP2040上怎樣使用MicroPython呢?

樹莓派Pico的相關資料分享
樹莓派Pico的相關資料推薦
樹莓派也出MCU了?樹莓派Pico來了!

樹莓派Pico:僅4美元的MCU
基于樹莓派pico的可編程游戲手柄設計
樹莓派PICO pio使用

樹莓派 Pico 2040 的“速度狂飆”:時鐘速度幾乎翻倍!




 工商網監
工商網監
評論