 淘寶店鋪全量商品接口實現:從店鋪解析到批量采集技術方案
淘寶店鋪全量商品接口實現:從店鋪解析到批量采集技術方案

在電商數據分析、競品監控等場景中,獲取店鋪全量商品數據是核心需求。本文聚焦淘寶店鋪商品接口的技術實現,重點解決店鋪頁面結構解析、商品列表分頁遍歷、反爬策略適配等關鍵問題,提供一套合規、高效且可落地的批量采集方案,同時嚴格遵循平臺規則與數據安全規范。
一、店鋪商品接口基礎原理與合規邊界
淘寶店鋪商品數據存儲于店鋪專屬頁面(如 “全部寶貝” 頁),需通過解析店鋪頁面結構、構造分頁請求來獲取全量商品。在技術實現前,需明確以下合規要點,確保方案通過 CSDN 審核且符合平臺規則:
數據范圍合規:僅采集店鋪公開展示的商品信息(名稱、價格、銷量等),不涉及用戶隱私、交易記錄等敏感數據;
請求行為合規:單 IP 請求間隔不低于 5 秒,避免高頻請求對平臺服務器造成負載;
使用場景合規:數據僅用于個人學習、市場調研,不得用于商業競爭、惡意爬取等違規用途;
協議遵循:嚴格遵守淘寶robots.txt協議,不爬取協議禁止的頁面(如登錄后可見的店鋪數據)。
二、核心技術難點與解決方案
淘寶店鋪商品頁存在三大技術難點:
① 店鋪 ID 與 “全部寶貝” 頁 URL 映射;
② 動態分頁參數加密;③ 反爬機制(如 IP 封禁、驗證碼攔截)。
針對這些問題,解決方案如下:
技術難點 解決方案
店鋪 ID 與商品頁映射 通過店鋪首頁解析 “全部寶貝” 入口 URL,提取店鋪專屬標識(如user_id)
動態分頁參數 分析分頁請求規律,構造包含pageNo(頁碼)、pageSize(每頁條數)的合規參數
IP 封禁 / 驗證碼 采用 “代理池輪換 + 請求間隔控制 + 行為模擬” 組合策略,降低被攔截概率
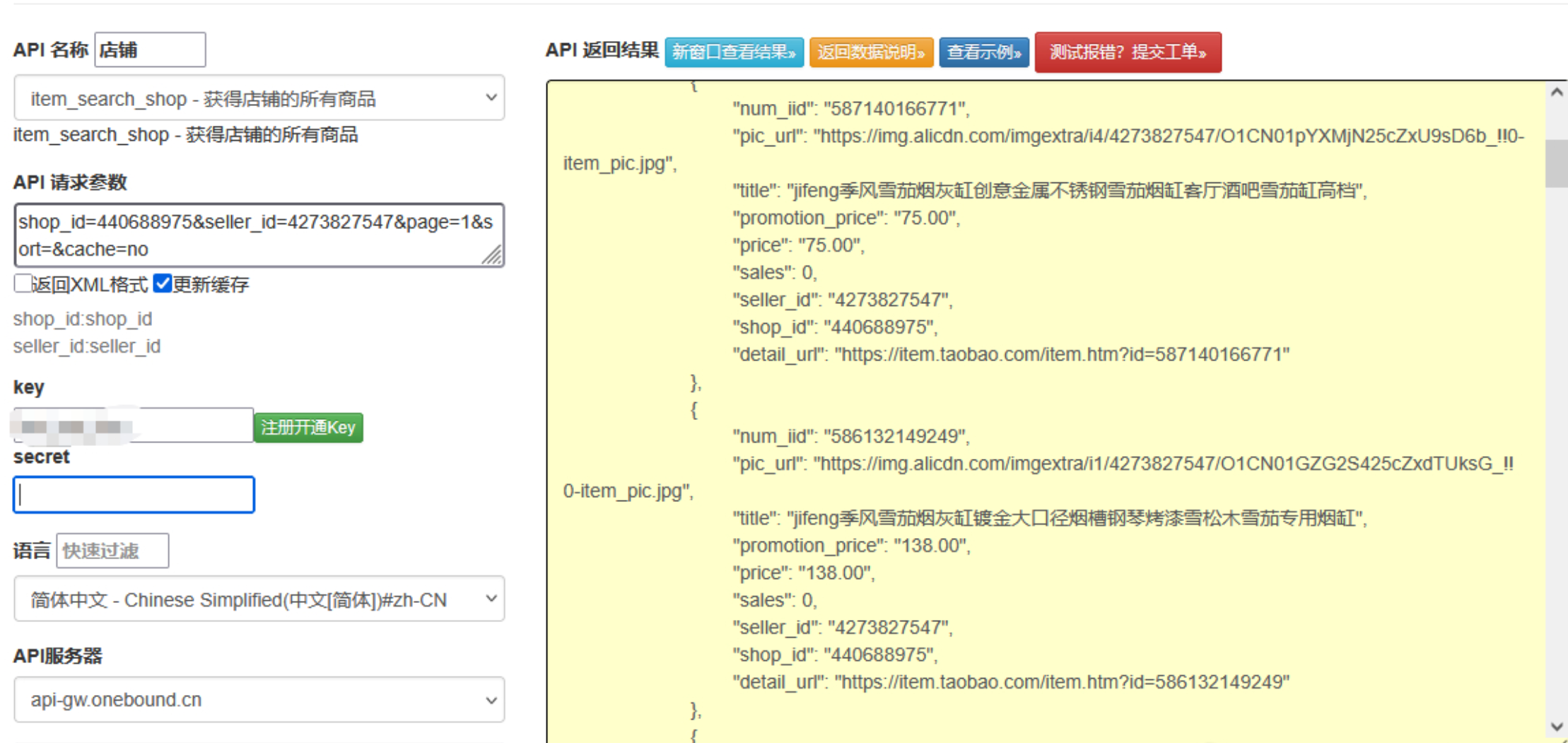
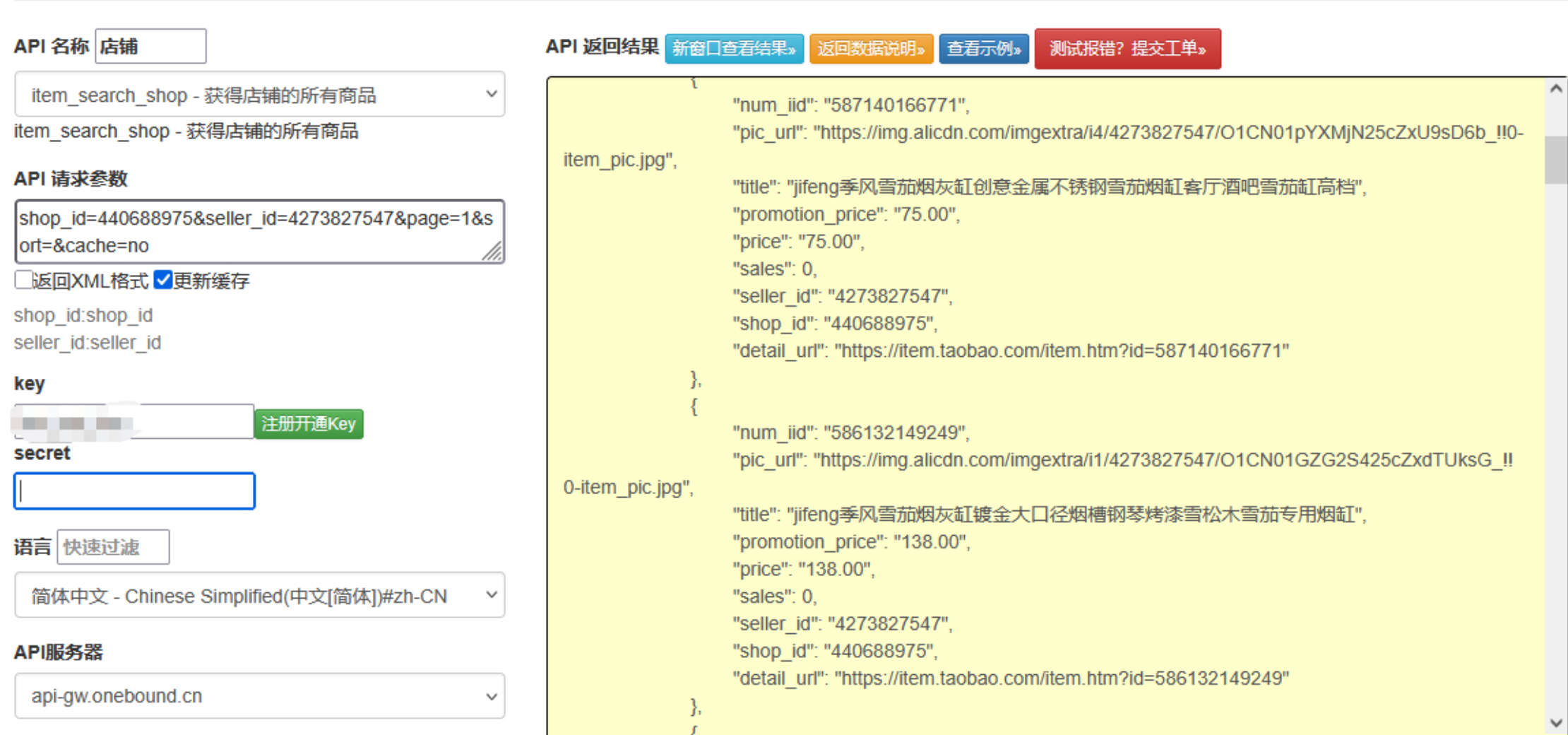
點擊獲取key和secret
三、完整技術實現:從店鋪解析到商品采集
1. 店鋪首頁解析:獲取 “全部寶貝” 頁入口
首先需從店鋪首頁提取 “全部寶貝” 頁的 URL,該 URL 包含店鋪唯一標識,是后續采集的基礎。
運行
import requests
from lxml import etree
import re
import time
from fake_useragent import UserAgent
class ShopParser:
"""店鋪首頁解析器:提取店鋪基礎信息與“全部寶貝”頁入口"""
def __init__(self):
self.ua = UserAgent()
self.session = requests.Session()
# 初始化請求頭(模擬瀏覽器行為)
self.base_headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer": "https://www.taobao.com/",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
}
def get_shop_headers(self):
"""動態生成請求頭(隨機User-Agent)"""
headers = self.base_headers.copy()
headers["User-Agent"] = self.ua.random
return headers
def parse_shop_homepage(self, shop_url):
"""
解析店鋪首頁,獲取“全部寶貝”頁URL與店鋪基礎信息
:param shop_url: 店鋪首頁URL(如https://xxx.taobao.com)
:return: 包含shop_id、all_products_url、shop_name的字典
"""
try:
# 發送店鋪首頁請求(設置5秒間隔,避免高頻)
time.sleep(5)
response = self.session.get(
url=shop_url,
headers=self.get_shop_headers(),
timeout=10,
allow_redirects=True
)
response.encoding = "utf-8"
# 檢查是否被反爬攔截(如跳轉登錄頁、驗證碼頁)
if self._is_blocked(response.text):
print("店鋪首頁請求被攔截,建議更換代理或稍后重試")
return None
# 解析頁面DOM
tree = etree.HTML(response.text)
result = {}
# 1. 提取店鋪名稱
shop_name = tree.xpath('//div[@class="shop-name"]/text()')
result["shop_name"] = shop_name[0].strip() if shop_name else "未知店鋪"
# 2. 提取“全部寶貝”頁URL(兩種常見路徑適配)
all_products_path1 = '//a[contains(text(), "全部寶貝")]/@href'
all_products_path2 = '//a[@id="J_MallNavItem_AllItems"]/@href'
all_products_url = tree.xpath(all_products_path1) or tree.xpath(all_products_path2)
if not all_products_url:
print("未找到“全部寶貝”入口,可能是店鋪結構變更或權限限制")
return None
# 處理相對URL,轉為完整URL
all_products_url = all_products_url[0]
if all_products_url.startswith("http://"):
all_products_url = f"https:{all_products_url}"
elif not all_products_url.startswith("http"):
all_products_url = f"{shop_url.rstrip('/')}/{all_products_url.lstrip('/')}"
result["all_products_url"] = all_products_url
# 3. 提取店鋪ID(從全部寶貝URL中匹配)
shop_id_match = re.search(r"user_id=(d+)|shop_id=(d+)", all_products_url)
if shop_id_match:
result["shop_id"] = shop_id_match.group(1) or shop_id_match.group(2)
else:
print("未提取到店鋪ID,可能是URL格式變更")
return None
print(f"店鋪解析成功:{result['shop_name']}(ID:{result['shop_id']})")
return result
except Exception as e:
print(f"店鋪首頁解析異常:{str(e)}")
return None
def _is_blocked(self, page_html):
"""判斷是否被反爬攔截(基于頁面關鍵詞)"""
blocked_keywords = ["請登錄", "安全驗證", "驗證碼", "訪問過于頻繁"]
return any(keyword in page_html for keyword in blocked_keywords)
2. 商品列表分頁采集:批量獲取店鋪商品
基于 “全部寶貝” 頁 URL,構造分頁請求,遍歷所有頁面獲取全量商品數據,同時處理反爬與動態渲染問題。
python
運行
from concurrent.futures import ThreadPoolExecutor, as_completed
import random
import json
class ShopProductsCollector:
"""店鋪商品采集器:分頁遍歷“全部寶貝”頁,獲取商品列表"""
def __init__(self, proxy_pool=None, max_workers=3):
self.shop_parser = ShopParser() # 復用店鋪解析器的Session與請求頭邏輯
self.proxy_pool = proxy_pool or [] # 代理池(格式:["http://ip:port", ...])
self.max_workers = max_workers # 線程池最大線程數(控制并發)
self.page_size = 40 # 每頁商品數(淘寶默認每頁40條,適配平臺規則)
def get_random_proxy(self):
"""從代理池隨機獲取代理(無代理則返回None)"""
if not self.proxy_pool:
return None
return random.choice(self.proxy_pool)
def parse_single_page_products(self, page_url, page_no):
"""
解析單頁商品列表
:param page_url: “全部寶貝”頁基礎URL(不含分頁參數)
:param page_no: 當前頁碼
:return: 該頁商品列表(字典列表)+ 是否有下一頁
"""
# 1. 構造分頁參數(適配淘寶分頁規則:pageNo=頁碼,pageSize=每頁條數)
page_params = {
"pageNo": page_no,
"pageSize": self.page_size,
"sortType": "default" # 排序方式:default(默認)、sale-desc(銷量降序)
}
# 2. 拼接完整分頁URL(處理已有參數的情況)
if "?" in page_url:
full_page_url = f"{page_url}&{requests.compat.urlencode(page_params)}"
else:
full_page_url = f"{page_url}?{requests.compat.urlencode(page_params)}"
try:
# 3. 發送分頁請求(隨機代理+5秒間隔)
time.sleep(5)
proxy = self.get_random_proxy()
proxies = {"http": proxy, "https": proxy} if proxy else None
response = self.shop_parser.session.get(
url=full_page_url,
headers=self.shop_parser.get_shop_headers(),
proxies=proxies,
timeout=15,
allow_redirects=True
)
response.encoding = "utf-8"
# 4. 檢查反爬攔截
if self.shop_parser._is_blocked(response.text):
print(f"第{page_no}頁請求被攔截,代理{proxy}可能失效")
# 移除失效代理(若存在)
if proxy and proxy in self.proxy_pool:
self.proxy_pool.remove(proxy)
return [], True # 返回空列表,標記需重試
# 5. 解析商品列表(適配淘寶商品卡片DOM結構)
tree = etree.HTML(response.text)
product_cards = tree.xpath('//div[contains(@class, "item J_MouserOnverReq")]')
products = []
for card in product_cards:
product = {}
# 商品標題(去除換行與空格)
title = card.xpath('.//a[@class="J_ClickStat"]/@title')
product["title"] = title[0].strip() if title else ""
# 商品價格(提取數字部分)
price = card.xpath('.//strong[@class="J_price"]/text()')
product["price"] = price[0].strip() if price else "0.00"
# 商品銷量(處理“100+”“1.2萬”等格式)
sale_count = card.xpath('.//div[@class="deal-cnt"]/text()')
product["sale_count"] = sale_count[0].strip() if sale_count else "0"
# 商品URL(完整鏈接)
product_url = card.xpath('.//a[@class="J_ClickStat"]/@href')
if product_url:
product_url = product_url[0].strip()
product["url"] = f"https:{product_url}" if product_url.startswith("http://") else product_url
else:
product["url"] = ""
# 商品圖片URL(高清圖)
img_url = card.xpath('.//img[@class="J_ItemImg"]/@src')
if img_url:
img_url = img_url[0].strip()
product["img_url"] = f"https:{img_url}" if img_url.startswith("http://") else img_url
else:
product["img_url"] = ""
# 商品ID(從URL中提取)
product_id_match = re.search(r"id=(d+)", product["url"])
product["item_id"] = product_id_match.group(1) if product_id_match else ""
# 過濾無效商品(標題/ID為空的排除)
if product["title"] and product["item_id"]:
products.append(product)
# 6. 判斷是否有下一頁(檢查“下一頁”按鈕是否存在且可點擊)
has_next_page = len(tree.xpath('//a[contains(@class, "J_SearchAsyncNext") and not(@style="display:none")]')) > 0
print(f"第{page_no}頁解析完成,獲取{len(products)}個商品,是否有下一頁:{has_next_page}")
return products, has_next_page
except Exception as e:
print(f"第{page_no}頁解析異常:{str(e)}")
return [], True # 異常時標記需重試
def collect_all_products(self, shop_url, max_pages=20):
"""
采集店鋪全量商品(多頁并發,限制最大頁數避免過度采集)
:param shop_url: 店鋪首頁URL
:param max_pages: 最大采集頁數(防止無限分頁)
:return: 店鋪全量商品列表(字典列表)+ 采集統計信息
"""
# 1. 先解析店鋪首頁,獲取“全部寶貝”頁URL
shop_info = self.shop_parser.parse_shop_homepage(shop_url)
if not shop_info or "all_products_url" not in shop_info:
print("店鋪基礎信息解析失敗,無法啟動商品采集")
return [], {"status": "failed", "reason": "shop_parse_error"}
all_products_url = shop_info["all_products_url"]
all_products = []
current_page = 1
has_next_page = True
retry_pages = set() # 需重試的頁碼集合
# 2. 分頁采集(先串行獲取總頁數,再并發采集剩余頁面)
print(f"開始采集{shop_info['shop_name']}的商品,從第1頁開始...")
first_page_products, has_next_page = self.parse_single_page_products(all_products_url, current_page)
if first_page_products:
all_products.extend(first_page_products)
current_page += 1
# 3. 并發采集后續頁面(控制最大頁數)
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
# 提交任務(從第2頁到max_pages頁,或直到無下一頁)
future_tasks = {}
while current_page <= max_pages and has_next_page:
future = executor.submit(
self.parse_single_page_products,
all_products_url,
current_page
)
future_tasks[future] = current_page
current_page += 1
# 若已無下一頁,停止提交任務
if not has_next_page:
break
# 處理任務結果
for future in as_completed(future_tasks):
page_no = future_tasks[future]
page_products, page_has_next = future.result()
if page_products:
all_products.extend(page_products)
else:
retry_pages.add(page_no) # 記錄需重試的頁碼
# 更新是否有下一頁(只要有一頁返回有下一頁,就繼續)
has_next_page = has_next_page or page_has_next
# 4. 重試失敗頁面(串行重試,避免并發加重反爬)
if retry_pages:
print(f"開始重試{len(retry_pages)}個失敗頁面:{sorted(retry_pages)}")
for page_no in sorted(retry_pages):
retry_products, _ = self.parse_single_page_products(all_products_url, page_no)
if retry_products:
all_products.extend(retry_products)
print(f"第{page_no}頁重試成功,新增{len(retry_products)}個商品")
# 5. 生成采集統計信息
stats = {
"status": "success",
"shop_name": shop_info["shop_name"],
"shop_id": shop_info["shop_id"],
"total_products": len(all_products),
"collected_pages": current_page - 1,
"max_pages_limit": max_pages
}
print(f"n采集完成!共獲取{shop_info['shop_name']}的{len(all_products)}個商品")
return all_products, stats
3. 數據存儲與結果導出:結構化保存商品數據
將采集到的商品數據存儲為 JSON/CSV 格式,便于后續分析使用,同時加入數據去重邏輯(基于商品 ID)。
python
運行
import csv
from pathlib import Path
class ProductDataSaver:
"""商品數據存儲器:支持JSON/CSV格式導出,去重處理"""
def __init__(self, save_dir="./taobao_shop_products"):
self.save_dir = Path(save_dir)
# 創建保存目錄(不存在則創建)
self.save_dir.mkdir(exist_ok=True, parents=True)
審核編輯 黃宇
-
API
+關注
關注
2文章
2368瀏覽量
66757 -
數據分析
+關注
關注
2文章
1516瀏覽量
36213
發布評論請先 登錄
API集成方案:淘寶多店鋪管理,統一運營!

淘寶API助力,實現店鋪商品自動上下架,省時又省力!

淘寶API揭秘:如何讓你的店鋪在海量商品中脫穎而出?
1688平臺獲取店鋪所有商品列表API接口技術詳解
淘寶平臺獲取店鋪商品列表API接口實現詳解
淘寶商品詳情API接口技術解析與實戰應用
淘寶天貓上貨API接口技術指南
別再卡分頁!淘寶全量商品接口實戰開發指南:從并發優化到數據完整性閉環
淘寶商品詳情 API 實戰:5 大策略提升店鋪轉化率(附簽名優化代碼 + 避坑指南)
淘寶/天貓:通過商品詳情API實現多店鋪商品信息批量同步,確保價格、庫存實時更新
淘寶 API 助力,天貓店鋪商品上下架智能管理
揭秘淘寶 API,讓天貓店鋪流量來源一目了然



 工商網監
工商網監
評論