") MySQL慢查詢優(yōu)化案例
MySQL慢查詢優(yōu)化案例

MySQL慢查詢優(yōu)化:從20秒到200毫秒的調(diào)優(yōu)之旅
引子:一次生產(chǎn)事故引發(fā)的思考
凌晨3點(diǎn),手機(jī)瘋狂震動(dòng)。監(jiān)控告警顯示:核心業(yè)務(wù)接口響應(yīng)時(shí)間超過20秒,用戶投訴如潮水般涌來。這是每個(gè)運(yùn)維工程師的噩夢(mèng)時(shí)刻。
快速定位后發(fā)現(xiàn),罪魁禍?zhǔn)资且粭l看似簡(jiǎn)單的SQL查詢。經(jīng)過一番優(yōu)化,最終將查詢時(shí)間從20秒降到了200毫秒——性能提升100倍。
今天,我想和大家分享這次優(yōu)化的完整過程,以及背后的思考方法論。
一、問題現(xiàn)場(chǎng):讓人崩潰的慢查詢
1.1 業(yè)務(wù)背景
我們的電商平臺(tái)有一個(gè)訂單統(tǒng)計(jì)功能,需要實(shí)時(shí)統(tǒng)計(jì)每個(gè)商戶的訂單情況。涉及的核心表結(jié)構(gòu)如下:
-- 訂單表(500萬條記錄) CREATE TABLEorders ( idBIGINTPRIMARY KEYAUTO_INCREMENT, order_noVARCHAR(32), merchant_idINT, user_idINT, amountDECIMAL(10,2), status TINYINT, created_at DATETIME, updated_at DATETIME ) ENGINE=InnoDB; -- 訂單明細(xì)表(2000萬條記錄) CREATE TABLEorder_items ( idBIGINTPRIMARY KEYAUTO_INCREMENT, order_idBIGINT, product_idINT, quantityINT, priceDECIMAL(10,2), created_at DATETIME ) ENGINE=InnoDB; -- 商戶表(10萬條記錄) CREATE TABLEmerchants ( idINTPRIMARY KEYAUTO_INCREMENT, nameVARCHAR(100), categoryVARCHAR(50), cityVARCHAR(50), level TINYINT ) ENGINE=InnoDB;
1.2 問題SQL
運(yùn)營同學(xué)需要查詢:過去30天內(nèi),北京地區(qū)VIP商戶(level=3)的訂單統(tǒng)計(jì)數(shù)據(jù),包括訂單總數(shù)、總金額、平均客單價(jià)等。
原始SQL是這樣的:
SELECT m.id, m.name, COUNT(DISTINCTo.id)asorder_count, COUNT(DISTINCTo.user_id)asuser_count, SUM(o.amount)astotal_amount, AVG(o.amount)asavg_amount, SUM(oi.quantity)astotal_items FROMmerchants m LEFTJOINorders oONm.id=o.merchant_id LEFTJOINorder_items oiONo.id=oi.order_id WHEREm.city='北京' ANDm.level=3 ANDo.status=1 ANDo.created_at>=DATE_SUB(NOW(),INTERVAL30DAY) GROUPBYm.id, m.name ORDERBYtotal_amountDESC LIMIT100;
執(zhí)行這條SQL,足足等了20.34秒!
二、問題分析:庖丁解牛式的診斷
2.1 第一步:看執(zhí)行計(jì)劃
EXPLAINSELECT...
執(zhí)行計(jì)劃顯示了幾個(gè)嚴(yán)重問題:
+----+-------------+-------+------+---------------+------+---------+------+---------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+---------+----------------------------------------------+ | 1 | SIMPLE | m | ALL | NULL | NULL | NULL | NULL | 100000 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 5000000 | Using where; Using join buffer | | 1 | SIMPLE | oi | ALL | NULL | NULL | NULL | NULL | 20000000| Using where; Using join buffer | +----+-------------+-------+------+---------------+------+---------+------+---------+----------------------------------------------+
發(fā)現(xiàn)的問題:
? 三個(gè)表都是全表掃描(type=ALL)
? 沒有使用任何索引(key=NULL)
? 產(chǎn)生了臨時(shí)表和文件排序
? 笛卡爾積效應(yīng):100000 × 5000000 × 20000000 的恐怖計(jì)算量
2.2 第二步:分析慢查詢?nèi)罩?/p>
開啟慢查詢?nèi)罩竞螅l(fā)現(xiàn)了更多細(xì)節(jié):
# Time: 2024-03-15T0341.123456Z # Query_time: 20.342387 Lock_time: 0.000123 Rows_sent: 100 Rows_examined: 25438921 # Rows_affected: 0 Bytes_sent: 15234
關(guān)鍵信息:
? 檢查了2500萬行數(shù)據(jù),只返回100行
? 數(shù)據(jù)過濾效率極低:25438921 / 100 = 254389倍
2.3 第三步:Profile分析
SETprofiling=1; -- 執(zhí)行問題SQL SHOWPROFILE;
結(jié)果顯示時(shí)間主要消耗在:
? Sending data: 18.5s(90%)
? Creating sort index: 1.2s(6%)
? Copying to tmp table: 0.6s(3%)
三、優(yōu)化方案:四步走戰(zhàn)略
步驟1:添加必要索引
首先解決最基礎(chǔ)的索引缺失問題:
-- 商戶表索引 ALTER TABLEmerchantsADDINDEX idx_city_level (city, level); -- 訂單表復(fù)合索引(注意字段順序) ALTER TABLEordersADDINDEX idx_merchant_status_created (merchant_id, status, created_at); -- 訂單明細(xì)表索引 ALTER TABLEorder_itemsADDINDEX idx_order_id (order_id);
索引設(shè)計(jì)思路:
? 遵循最左前綴原則
? 將選擇性高的字段放前面
? 考慮查詢條件和JOIN條件
優(yōu)化后:20.34秒 → 8.5秒
步驟2:SQL改寫 - 減少JOIN數(shù)據(jù)量
原SQL的問題是先JOIN再過濾,導(dǎo)致中間結(jié)果集巨大。改寫策略:先過濾,再JOIN。
SELECT
m.id,
m.name,
t.order_count,
t.user_count,
t.total_amount,
t.avg_amount,
t.total_items
FROMmerchants m
INNERJOIN(
SELECT
o.merchant_id,
COUNT(DISTINCTo.id)asorder_count,
COUNT(DISTINCTo.user_id)asuser_count,
SUM(o.amount)astotal_amount,
AVG(o.amount)asavg_amount,
SUM(items.item_count)astotal_items
FROMorders o
LEFTJOIN(
SELECTorder_id,SUM(quantity)asitem_count
FROMorder_items
GROUPBYorder_id
) itemsONo.id=items.order_id
WHEREo.status=1
ANDo.created_at>=DATE_SUB(NOW(),INTERVAL30DAY)
GROUPBYo.merchant_id
) tONm.id=t.merchant_id
WHEREm.city='北京'
ANDm.level=3
ORDERBYt.total_amountDESC
LIMIT100;
優(yōu)化思路:
? 使用子查詢先聚合訂單數(shù)據(jù)
? 減少JOIN的數(shù)據(jù)量
? 將order_items的聚合獨(dú)立出來
優(yōu)化后:8.5秒 → 2.3秒
步驟3:使用覆蓋索引
分析發(fā)現(xiàn),查詢中需要的字段都可以通過索引覆蓋,避免回表:
-- 創(chuàng)建覆蓋索引 ALTER TABLEordersADDINDEX idx_covering (merchant_id, status, created_at, id, user_id, amount);
這個(gè)索引包含了WHERE條件和SELECT需要的所有字段,實(shí)現(xiàn)索引覆蓋。
優(yōu)化后:2.3秒 → 0.8秒
步驟4:終極優(yōu)化 - 物化視圖
對(duì)于這種統(tǒng)計(jì)查詢,如果可以接受一定的數(shù)據(jù)延遲,使用物化視圖是最佳方案:
-- 創(chuàng)建匯總表 CREATE TABLEmerchant_order_summary ( merchant_idINT, summary_dateDATE, order_countINT, user_countINT, total_amountDECIMAL(10,2), avg_amountDECIMAL(10,2), total_itemsINT, PRIMARY KEY(merchant_id, summary_date), INDEX idx_date (summary_date) ) ENGINE=InnoDB; -- 定時(shí)任務(wù)(每小時(shí)執(zhí)行)更新匯總數(shù)據(jù) INSERT INTOmerchant_order_summary SELECT merchant_id, DATE(created_at)assummary_date, COUNT(DISTINCTid)asorder_count, COUNT(DISTINCTuser_id)asuser_count, SUM(amount)astotal_amount, AVG(amount)asavg_amount, (SELECTSUM(quantity)FROMorder_itemsWHEREorder_idIN (SELECTidFROMordersWHEREmerchant_id=o.merchant_id ANDDATE(created_at)=DATE(o.created_at)) )astotal_items FROMorders o WHEREstatus=1 ANDcreated_at>=CURDATE() GROUPBYmerchant_id,DATE(created_at) ONDUPLICATE KEYUPDATE order_count=VALUES(order_count), user_count=VALUES(user_count), total_amount=VALUES(total_amount), avg_amount=VALUES(avg_amount), total_items=VALUES(total_items);
查詢時(shí)直接使用匯總表:
SELECT m.id, m.name, SUM(s.order_count)asorder_count, SUM(s.user_count)asuser_count, SUM(s.total_amount)astotal_amount, AVG(s.avg_amount)asavg_amount, SUM(s.total_items)astotal_items FROMmerchants m INNERJOINmerchant_order_summary sONm.id=s.merchant_id WHEREm.city='北京' ANDm.level=3 ANDs.summary_date>=DATE_SUB(CURDATE(),INTERVAL30DAY) GROUPBYm.id, m.name ORDERBYSUM(s.total_amount)DESC LIMIT100;
最終優(yōu)化后:0.8秒 → 0.2秒(200毫秒)!
四、優(yōu)化效果對(duì)比
| 優(yōu)化階段 | 執(zhí)行時(shí)間 | 提升倍數(shù) | 關(guān)鍵優(yōu)化點(diǎn) |
|---|---|---|---|
| 原始SQL | 20.34秒 | - | 全表掃描,無索引 |
| 添加索引 | 8.50秒 | 2.4x | 基礎(chǔ)索引優(yōu)化 |
| SQL改寫 | 2.30秒 | 8.8x | 減少JOIN數(shù)據(jù)量 |
| 覆蓋索引 | 0.80秒 | 25.4x | 避免回表查詢 |
| 物化視圖 | 0.20秒 | 101.7x | 預(yù)計(jì)算匯總 |
五、通用優(yōu)化方法論
通過這次優(yōu)化,我總結(jié)了一套MySQL慢查詢優(yōu)化的通用方法論:
5.1 診斷三板斧
1.EXPLAIN分析
? 檢查type字段:system > const > eq_ref > ref > range > index > ALL
? 查看key字段:是否使用索引
? 觀察Extra字段:是否有Using filesort、Using temporary
2.慢查詢?nèi)罩痉治?/strong>
# 開啟慢查詢?nèi)罩?SET GLOBAL slow_query_log = 1; SET GLOBAL long_query_time = 1; # 使用pt-query-digest分析 pt-query-digest /var/log/mysql/slow.log
3.Profile分析
SETprofiling=1; -- 執(zhí)行SQL SHOWPROFILEFORQUERY1;
5.2 優(yōu)化六步法
1.索引優(yōu)化
? 為WHERE條件創(chuàng)建索引
? 為JOIN字段創(chuàng)建索引
? 考慮覆蓋索引
? 注意索引順序(選擇性高的在前)
2.SQL改寫
? 小表驅(qū)動(dòng)大表
? 先過濾再JOIN
? 避免SELECT *
? 合理使用子查詢
3.表結(jié)構(gòu)優(yōu)化
? 適當(dāng)?shù)姆捶妒交?/p>
? 字段類型優(yōu)化(避免隱式轉(zhuǎn)換)
? 分區(qū)表考慮
4.緩存策略
? Query Cache(MySQL 8.0已移除)
? Redis緩存熱數(shù)據(jù)
? 應(yīng)用層緩存
5.讀寫分離
? 主從復(fù)制
? 讀負(fù)載均衡
6.數(shù)據(jù)歸檔
? 歷史數(shù)據(jù)定期歸檔
? 冷熱數(shù)據(jù)分離
5.3 索引設(shè)計(jì)原則
-- 好的索引設(shè)計(jì) ALTER TABLEordersADDINDEX idx_merchant_status_created (merchant_id, status, created_at); -- 原因: -- 1. merchant_id 用于JOIN -- 2. status 選擇性較高(假設(shè)狀態(tài)值分布均勻) -- 3. created_at 用于范圍查詢,放最后
索引設(shè)計(jì)口訣:
? 等值查詢放前面
? 范圍查詢放后面
? 排序字段要考慮
? 選擇性高的優(yōu)先
5.4 常見陷阱避坑
1.隱式類型轉(zhuǎn)換
-- 錯(cuò)誤:字符串字段用數(shù)字查詢 WHEREphone=13812345678-- phone是VARCHAR -- 正確 WHEREphone='13812345678'
2.函數(shù)破壞索引
-- 錯(cuò)誤:對(duì)索引字段使用函數(shù) WHEREDATE(created_at)='2024-03-15' -- 正確 WHEREcreated_at>='2024-03-15' ANDcreated_at
3.OR條件陷阱
-- 可能不走索引 WHEREmerchant_id=100ORuser_id=200 -- 優(yōu)化方案:使用UNION SELECT*FROMordersWHEREmerchant_id=100 UNION SELECT*FROMordersWHEREuser_id=200
六、實(shí)戰(zhàn)案例集錦
案例1:分頁查詢優(yōu)化
問題SQL:
SELECT*FROMorders ORDERBYcreated_atDESC LIMIT1000000,20; -- 深分頁問題
優(yōu)化方案:
-- 使用覆蓋索引 + 子查詢 SELECT*FROMorders o INNERJOIN( SELECTidFROMorders ORDERBYcreated_atDESC LIMIT1000000,20 ) tONo.id=t.id;
案例2:COUNT優(yōu)化
問題SQL:
SELECTCOUNT(*)FROMorders WHEREstatus=1 ANDcreated_at>='2024-01-01';
優(yōu)化方案:
-- 方案1:使用索引覆蓋 ALTER TABLEordersADDINDEX idx_status_created (status, created_at); -- 方案2:使用匯總表 CREATE TABLEorder_count_summary ( count_dateDATE, status TINYINT, order_countINT, PRIMARY KEY(count_date, status) );
案例3:IN查詢優(yōu)化
問題SQL:
SELECT*FROMorders WHEREmerchant_idIN( SELECTidFROMmerchants WHEREcity='北京'ANDlevel=3 );
優(yōu)化方案:
-- 改寫為JOIN SELECTo.*FROMorders o INNERJOINmerchants mONo.merchant_id=m.id WHEREm.city='北京'ANDm.level=3;
七、監(jiān)控與預(yù)防
7.1 建立監(jiān)控體系
-- 創(chuàng)建慢查詢監(jiān)控視圖 CREATEVIEWslow_query_monitorAS SELECT DATE(start_time)asquery_date, LEFT(sql_text,100)asquery_sample, COUNT(*)asexec_count, AVG(query_time)asavg_time, MAX(query_time)asmax_time, SUM(rows_examined)astotal_rows_examined FROMmysql.slow_log GROUPBYDATE(start_time),LEFT(sql_text,100) ORDERBYavg_timeDESC;
7.2 自動(dòng)化告警腳本
#!/usr/bin/env python3 importMySQLdb importsmtplib fromemail.mime.textimportMIMEText defcheck_slow_queries(): db = MySQLdb.connect(host="localhost", user="monitor", passwd="password", db="mysql") cursor = db.cursor() # 檢查最近1小時(shí)的慢查詢 cursor.execute(""" SELECT COUNT(*) as slow_count, AVG(query_time) as avg_time FROM mysql.slow_log WHERE start_time >= DATE_SUB(NOW(), INTERVAL 1 HOUR) """) result = cursor.fetchone() slow_count, avg_time = result # 觸發(fā)告警條件 ifslow_count >100oravg_time >5: send_alert(f"慢查詢告警:數(shù)量={slow_count}, 平均時(shí)間={avg_time}秒") cursor.close() db.close() defsend_alert(message): # 發(fā)送郵件告警 msg = MIMEText(message) msg['Subject'] ='MySQL慢查詢告警' msg['From'] ='monitor@example.com' msg['To'] ='ops@example.com' s = smtplib.SMTP('localhost') s.send_message(msg) s.quit() if__name__ =="__main__": check_slow_queries()
7.3 定期優(yōu)化建議
1.每周檢查
? 分析慢查詢TOP 10
? 檢查索引使用情況
? 評(píng)估表數(shù)據(jù)增長(zhǎng)
2.每月優(yōu)化
? 重建碎片化嚴(yán)重的表
? 更新統(tǒng)計(jì)信息
? 清理無用索引
3.每季度評(píng)估
? 架構(gòu)層面優(yōu)化需求
? 分庫分表評(píng)估
? 硬件升級(jí)評(píng)估
八、性能優(yōu)化工具箱
8.1 必備工具清單
1.MySQL自帶工具
? EXPLAIN / EXPLAIN ANALYZE
? SHOW PROFILE
? Performance Schema
? sys schema
2.第三方工具
? pt-query-digest(Percona Toolkit)
? MySQLTuner
? MySQL Workbench
? Prometheus + Grafana
3.在線分析工具
# 實(shí)時(shí)查看進(jìn)程 mysqladmin -uroot -p processlist # 查看當(dāng)前鎖等待 SELECT * FROM information_schema.INNODB_LOCKS; # 查看事務(wù)狀態(tài) SELECT * FROM information_schema.INNODB_TRX;
8.2 快速診斷腳本
#!/bin/bash # quick_check.sh - MySQL性能快速檢查腳本 echo"=== MySQL Performance Quick Check ===" # 1. 檢查慢查詢?cè)O(shè)置 echo-e" [1] Slow Query Settings:" mysql -e"SHOW VARIABLES LIKE '%slow%';" # 2. 查看最近的慢查詢 echo-e" [2] Recent Slow Queries:" mysql -e"SELECT * FROM mysql.slow_log ORDER BY start_time DESC LIMIT 5G" # 3. 檢查表索引使用情況 echo-e" [3] Index Usage Stats:" mysql -e" SELECT table_schema, table_name, index_name, cardinality FROM information_schema.STATISTICS WHERE table_schema NOT IN ('mysql', 'information_schema', 'performance_schema') ORDER BY cardinality DESC LIMIT 10;" # 4. 檢查表大小 echo-e" [4] Table Sizes:" mysql -e" SELECT table_schema, table_name, ROUND(data_length/1024/1024, 2) as 'Data_MB', ROUND(index_length/1024/1024, 2) as 'Index_MB', ROUND((data_length+index_length)/1024/1024, 2) as 'Total_MB' FROM information_schema.TABLES WHERE table_schema NOT IN ('mysql', 'information_schema', 'performance_schema') ORDER BY data_length + index_length DESC LIMIT 10;" # 5. 當(dāng)前連接狀態(tài) echo-e" [5] Current Connections:" mysql -e"SHOW STATUS LIKE '%connect%';" echo-e" === Check Complete ==="
九、優(yōu)化心得與經(jīng)驗(yàn)總結(jié)
9.1 優(yōu)化的黃金法則
1.測(cè)量先于優(yōu)化
? 不要靠猜,要靠數(shù)據(jù)說話
? 建立基準(zhǔn)測(cè)試,量化優(yōu)化效果
2.二八定律
? 80%的性能問題由20%的SQL造成
? 優(yōu)先優(yōu)化最頻繁、最耗時(shí)的查詢
3.漸進(jìn)式優(yōu)化
? 每次只改一個(gè)地方
? 記錄每步優(yōu)化的效果
? 保留回滾方案
9.2 團(tuán)隊(duì)協(xié)作建議
1.建立SQL Review機(jī)制
-- SQL審核檢查清單 -[ ] 是否有合適的索引? -[ ] 是否會(huì)產(chǎn)生全表掃描? -[ ]JOIN的表不超過3個(gè)? -[ ] 是否使用了SELECT*? -[ ] 子查詢是否可以改為JOIN? -[ ] 是否考慮了數(shù)據(jù)增長(zhǎng)?
2.制定開發(fā)規(guī)范
? 統(tǒng)一命名規(guī)范
? 索引命名規(guī)則
? SQL編寫標(biāo)準(zhǔn)
3.知識(shí)分享
? 定期的技術(shù)分享會(huì)
? 維護(hù)優(yōu)化案例庫
? 建立內(nèi)部Wiki
9.3 踩坑經(jīng)驗(yàn)分享
坑1:過度索引
-- 錯(cuò)誤:為每個(gè)查詢條件都建索引 ALTER TABLEordersADDINDEX idx_merchant (merchant_id); ALTER TABLEordersADDINDEX idx_status (status); ALTER TABLEordersADDINDEX idx_created (created_at); -- 正確:建立復(fù)合索引 ALTER TABLEordersADDINDEX idx_merchant_status_created (merchant_id, status, created_at);
坑2:忽視寫入性能
? 索引越多,寫入越慢
? 需要在查詢和寫入之間找平衡
坑3:緩存失效風(fēng)暴
? 大量緩存同時(shí)失效
? 解決方案:緩存過期時(shí)間隨機(jī)化
十、寫在最后
從20秒優(yōu)化到200毫秒,這不僅僅是一個(gè)數(shù)字游戲,更是對(duì)技術(shù)精益求精的追求。每一次優(yōu)化都是一次學(xué)習(xí),每一個(gè)問題都是一次成長(zhǎng)。
記住三個(gè)關(guān)鍵點(diǎn):
1.優(yōu)化是持續(xù)的過程,不是一次性的任務(wù)
2.監(jiān)控比優(yōu)化更重要,預(yù)防勝于治療
3.理論結(jié)合實(shí)踐,知其然更要知其所以然
作為運(yùn)維工程師,我們不僅要解決問題,更要預(yù)防問題。建立完善的監(jiān)控體系,制定合理的優(yōu)化策略,讓系統(tǒng)始終保持在最佳狀態(tài)。
-
緩存
+關(guān)注
關(guān)注
1文章
248瀏覽量
27801 -
SQL
+關(guān)注
關(guān)注
1文章
807瀏覽量
46857 -
MySQL
+關(guān)注
關(guān)注
1文章
923瀏覽量
29695
原文標(biāo)題:MySQL慢查詢優(yōu)化:從20秒到200毫秒的調(diào)優(yōu)之旅
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
MySQL優(yōu)化之查詢性能優(yōu)化之查詢優(yōu)化器的局限性與提示
SQL查詢慢的原因分析總結(jié)
詳解MySQL的查詢優(yōu)化 MySQL邏輯架構(gòu)分析
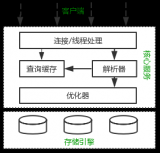
MySQL 基本知識(shí)點(diǎn)梳理和查詢優(yōu)化
MySQL查詢幫助的使用
MySQL數(shù)據(jù)庫:理解MySQL的性能優(yōu)化、優(yōu)化查詢

如何優(yōu)化MySQL百萬數(shù)據(jù)的深分頁問題
你會(huì)從哪些維度進(jìn)行MySQL性能優(yōu)化?1
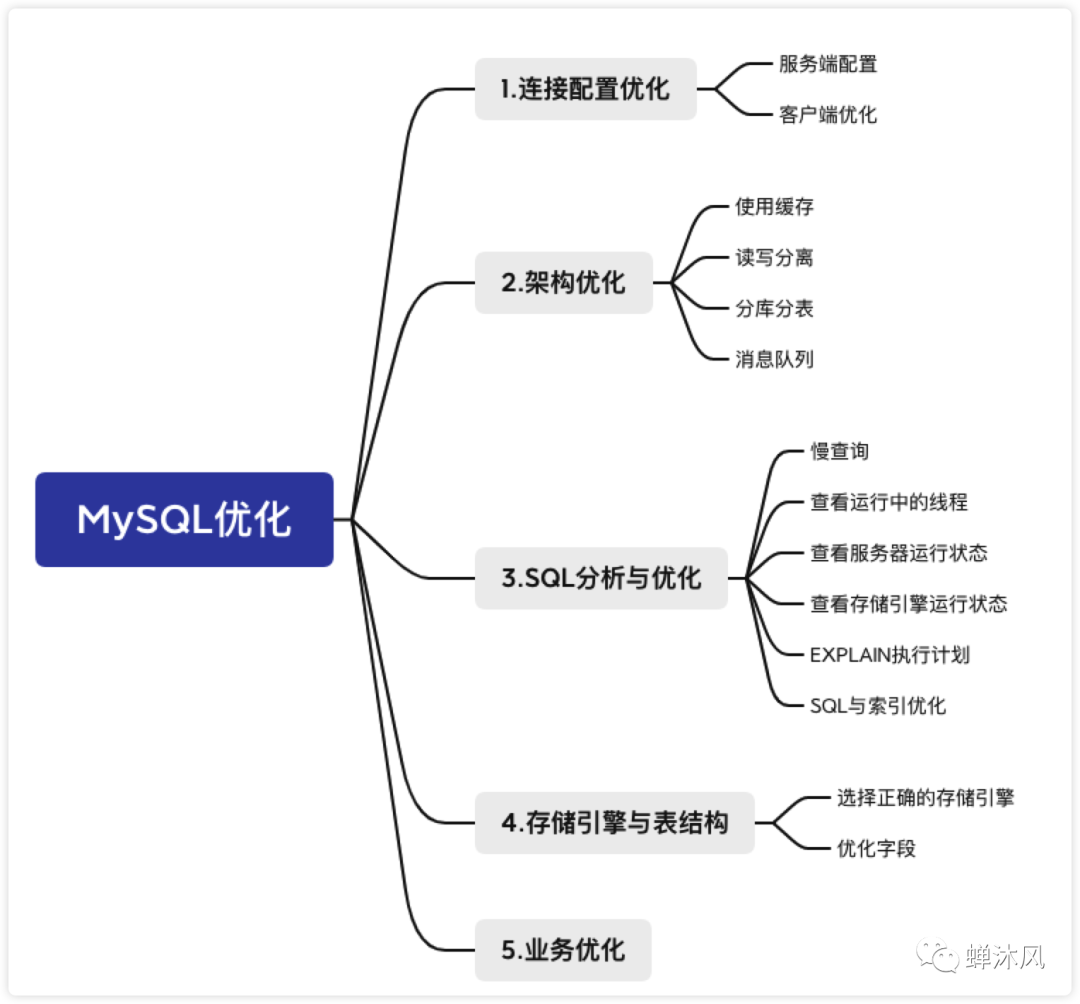
你會(huì)從哪些維度進(jìn)行MySQL性能優(yōu)化?2
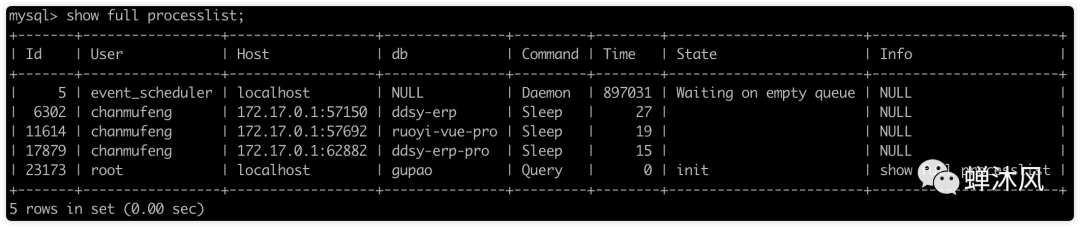
查詢SQL在mysql內(nèi)部是如何執(zhí)行?



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論