 數據庫性能優化指南
數據庫性能優化指南

數據庫性能優化:從 SQL 到硬件調優完全指南
寫在前面:作為一名在大廠摸爬滾打多年的運維老兵,我見過太多因為數據庫性能問題導致的生產事故。今天分享一套完整的數據庫優化方法論,從SQL層面到硬件配置,幫你徹底解決性能瓶頸!
為什么數據庫優化如此重要?
在我職業生涯中,80%的性能問題都源于數據庫。一條慢SQL可能讓整個系統癱瘓,而合理的硬件配置能讓性能提升10倍以上。
真實案例:某電商平臺雙11期間,因為一條未優化的查詢語句,導致數據庫CPU飆升到95%,訂單處理延遲超過30秒,直接影響了千萬級別的交易。
數據庫性能優化金字塔模型
我總結了一個"性能優化金字塔",從上到下分別是:
應用層優化 (10-20%提升)
↑
SQL語句優化 (30-50%提升)
↑
索引設計優化 (40-80%提升)
↑
數據庫配置優化 (20-40%提升)
↑
硬件資源優化 (50-200%提升)
第一層:SQL語句優化的實戰技巧
1.1 避免全表掃描的致命錯誤
錯誤示例:
-- 這樣的查詢會讓DBA想打人 SELECT*FROMordersWHEREcreate_time>'2024-01-01';
正確寫法:
-- 使用索引,指定具體字段 SELECTorder_id, user_id, amount FROMorders WHEREcreate_time>='2024-01-01' ANDcreate_time
性能對比:優化后查詢時間從12秒降至0.03秒,提升400倍!
1.2 JOIN優化的黃金法則
-- 優化前:笛卡爾積災難 SELECTu.name, o.amount FROMusers u, orders o WHEREu.id=o.user_id ANDu.status='active'; -- 優化后:明確JOIN條件 SELECTu.name, o.amount FROMusers u INNERJOINorders oONu.id=o.user_id WHEREu.status='active' ANDo.create_time>=CURDATE()-INTERVAL30DAY;
1.3 子查詢 vs EXISTS 性能大比拼
-- 慢查詢:子查詢 SELECT*FROMusers WHEREidIN( SELECTuser_idFROMorders WHEREamount>1000 ); -- 快查詢:EXISTS SELECT*FROMusers u WHEREEXISTS( SELECT1FROMorders o WHEREo.user_id=u.id ANDo.amount>1000 );
實測數據:在100萬用戶數據中,EXISTS比IN快60%。
第二層:索引設計的藝術
2.1 復合索引的正確姿勢
索引不是越多越好,而是要"精準打擊"。
-- 錯誤:為每個字段單獨建索引 CREATEINDEX idx_user_idONorders(user_id); CREATEINDEX idx_statusONorders(status); CREATEINDEX idx_create_timeONorders(create_time); -- 正確:根據查詢模式建立復合索引 CREATEINDEX idx_user_status_timeONorders(user_id, status, create_time);
復合索引設計三原則:
1. 區分度高的字段放前面
2. 范圍查詢字段放最后
3. 最常用的查詢條件優先
2.2 索引失效的常見陷阱
-- 索引失效場景1:函數操作 SELECT*FROMordersWHEREYEAR(create_time)=2024; -- SELECT*FROMordersWHEREcreate_time>='2024-01-01'ANDcreate_time<'2025-01-01'; ?-- -- 索引失效場景2:隱式類型轉換 SELECT*FROM?orders?WHERE?user_id?='123'; ?-- user_id是int類型 SELECT*FROM?orders?WHERE?user_id?=123; ? ?-- -- 索引失效場景3:前導模糊查詢 SELECT*FROM?users?WHERE?name?LIKE'%張%'; ? ?-- SELECT*FROM?users?WHERE?name?LIKE'張%'; ? ??--
2.3 覆蓋索引的威力
-- 普通查詢:需要回表 SELECTuser_id, amountFROMordersWHEREstatus='completed'; -- 創建覆蓋索引 CREATEINDEX idx_status_coverONorders(status, user_id, amount); -- 現在查詢直接從索引獲取數據,無需回表
效果:查詢速度提升3-5倍,IO減少80%。
第三層:數據庫參數調優
3.1 MySQL核心參數優化
# my.cnf 生產環境推薦配置 [mysqld] # 緩沖池大小(物理內存的70-80%) innodb_buffer_pool_size=16G # 日志文件大小 innodb_log_file_size=2G innodb_log_files_in_group=2 # 連接數配置 max_connections=2000 max_connect_errors=100000 # 查詢緩存(MySQL 8.0已移除) query_cache_size=0 query_cache_type=0 # 臨時表配置 tmp_table_size=256M max_heap_table_size=256M # 排序和分組緩沖區 sort_buffer_size=4M read_buffer_size=2M read_rnd_buffer_size=8M # InnoDB配置 innodb_thread_concurrency=0 innodb_flush_log_at_trx_commit=2 innodb_flush_method= O_DIRECT
3.2 PostgreSQL優化配置
# postgresql.conf 關鍵參數 shared_buffers=4GB # 共享緩沖區 effective_cache_size=12GB # 有效緩存大小 work_mem=256MB # 工作內存 maintenance_work_mem=1GB # 維護工作內存 checkpoint_completion_target=0.9 # 檢查點完成目標 wal_buffers=64MB # WAL緩沖區 default_statistics_target=500 # 統計信息目標
3.3 參數調優的監控指標
關鍵監控指標:
? Buffer Pool命中率 > 99%
? QPS/TPS比例合理
? 慢查詢數量 < 總查詢數的1%
? 鎖等待時間 < 100ms
? 連接數使用率 < 80%
第四層:硬件優化的投入產出比
4.1 存儲設備選型策略
HDD vs SSD vs NVMe性能對比:
| 存儲類型 | 隨機IOPS | 順序讀寫 | 延遲 | 成本 | 適用場景 |
|---|---|---|---|---|---|
| HDD | 100-200 | 150MB/s | 10-15ms | 低 | 冷數據存儲 |
| SATA SSD | 40K-90K | 500MB/s | 0.1ms | 中 | 一般業務 |
| NVMe SSD | 200K-1M | 3500MB/s | 0.02ms | 高 | 高并發業務 |
真實案例:將MySQL數據目錄從HDD遷移到NVMe SSD后,查詢響應時間從平均200ms降至15ms,整體性能提升13倍。
4.2 內存配置的黃金比例
# 內存分配建議(64GB服務器為例) 系統預留: 8GB (12.5%) 數據庫緩沖池: 45GB (70%) 連接和臨時表: 8GB (12.5%) 其他應用: 3GB (5%)
內存不足的危險信號:
? 頻繁的磁盤IO
? Buffer Pool命中率低于95%
? 系統出現swap使用
4.3 CPU選型和配置
數據庫服務器CPU建議:
? 核心數:16-32核(支持高并發)
? 頻率:3.0GHz以上(單查詢性能)
? 緩存:L3 Cache ≥ 20MB
? 架構:x86_64,支持SSE4.2
CPU監控要點:
# 監控CPU使用情況 top -p $(pgrep mysql) iostat -x 1 sar -u 1 # 關鍵指標 - CPU使用率 < 70% - Load Average < CPU核心數 - Context Switch < 1000/s
4.4 網絡優化配置
# 網絡參數優化 echo'net.core.rmem_max = 268435456'>> /etc/sysctl.conf echo'net.core.wmem_max = 268435456'>> /etc/sysctl.conf echo'net.ipv4.tcp_rmem = 4096 87380 268435456'>> /etc/sysctl.conf echo'net.ipv4.tcp_wmem = 4096 65536 268435456'>> /etc/sysctl.conf echo'net.core.netdev_max_backlog = 5000'>> /etc/sysctl.conf sysctl -p
第五層:架構層面的性能提升
5.1 讀寫分離架構
# Django讀寫分離示例 classDatabaseRouter: defdb_for_read(self, model, **hints): return'read_db' defdb_for_write(self, model, **hints): return'write_db' # 配置文件 DATABASES = { 'default': {}, 'write_db': { 'ENGINE':'django.db.backends.mysql', 'HOST':'master.mysql.internal', 'NAME':'production', }, 'read_db': { 'ENGINE':'django.db.backends.mysql', 'HOST':'slave.mysql.internal', 'NAME':'production', } }
5.2 分庫分表策略
-- 水平分表示例:按用戶ID取模
CREATE TABLEorders_0LIKEorders;
CREATE TABLEorders_1LIKEorders;
CREATE TABLEorders_2LIKEorders;
CREATE TABLEorders_3LIKEorders;
-- 分片路由邏輯
def get_table_name(user_id):
returnf"orders_{user_id % 4}"
5.3 緩存層設計
# Redis緩存策略
importredis
r = redis.Redis()
defget_user_info(user_id):
# 先查緩存
cache_key =f"user:{user_id}"
cached_data = r.get(cache_key)
ifcached_data:
returnjson.loads(cached_data)
# 緩存未命中,查數據庫
user_data = db.query("SELECT * FROM users WHERE id = %s", user_id)
# 寫入緩存,TTL 1小時
r.setex(cache_key,3600, json.dumps(user_data))
returnuser_data
生產環境優化實戰案例
案例1:電商平臺訂單查詢優化
問題背景:雙11期間,訂單查詢接口響應時間超過5秒,用戶體驗極差。
分析過程:
-- 原始慢查詢 SELECTo.*, u.name, p.title FROMorders o LEFTJOINusers uONo.user_id=u.id LEFTJOINproducts pONo.product_id=p.id WHEREo.create_time>='2024-11-11' ORDERBYo.create_timeDESC LIMIT20; -- 執行計劃分析 EXPLAINSELECT... -- 發現:全表掃描orders表,600萬行數據
優化方案:
1. 創建復合索引:CREATE INDEX idx_create_time_desc ON orders(create_time DESC);
2. 避免SELECT *,只查詢需要的字段
3. 分頁優化,使用游標分頁
優化結果:
-- 優化后查詢 SELECTo.id, o.amount, u.name, p.title FROMorders o INNERJOINusers uONo.user_id=u.id INNERJOINproducts pONo.product_id=p.id WHEREo.create_time>='2024-11-11' ANDo.id>0-- 游標分頁 ORDERBYo.id LIMIT20;
效果:查詢時間從5.2秒優化到0.08秒,提升65倍。
案例2:金融系統報表查詢優化
問題:月度財務報表生成需要45分鐘,嚴重影響業務。
解決方案:
1.數據預計算:建立匯總表,定時ETL
2.列式存儲:核心報表數據遷移到ClickHouse
3.并行計算:大查詢拆分為多個小查詢并行執行
核心代碼:
-- 預計算匯總表 CREATE TABLEdaily_summaryAS SELECT DATE(create_time)asdate, product_id, COUNT(*)asorder_count, SUM(amount)astotal_amount FROMorders GROUPBYDATE(create_time), product_id; -- 定時更新 -- 0 1 * * * /path/to/update_summary.sh
結果:報表生成時間從45分鐘縮短至2分鐘,性能提升22倍。
性能監控和診斷工具
MySQL監控工具箱
# 1. 慢查詢分析 mysqldumpslow -s c -t 10 /var/log/mysql/slow.log # 2. 實時性能監控 mysql> SHOW PROCESSLIST; mysql> SHOW ENGINE INNODB STATUS; # 3. 性能分析 mysql> SELECT * FROM performance_schema.events_statements_summary_by_digest ORDER BY sum_timer_wait DESC LIMIT 10; # 4. 系統級監控 iostat -x 1 sar -u 1 10 free -h
PostgreSQL監控腳本
-- 查找慢查詢 SELECTquery, mean_time, calls, total_time FROMpg_stat_statements ORDERBYmean_timeDESC LIMIT10; -- 表和索引大小 SELECTschemaname, tablename, pg_size_pretty(pg_total_relation_size(schemaname||'.'||tablename))assize FROMpg_tables ORDERBYpg_total_relation_size(schemaname||'.'||tablename)DESC; -- 索引使用情況 SELECTschemaname, tablename, indexname, idx_scan, idx_tup_read, idx_tup_fetch FROMpg_stat_user_indexes ORDERBYidx_scanASC;
性能優化檢查清單
SQL層面檢查清單
? 避免SELECT *,只查詢需要的字段
? 使用LIMIT限制返回行數
? 優化WHERE條件順序
? 避免在WHERE中使用函數
? 合理使用JOIN,避免笛卡爾積
? 使用EXISTS替代IN(子查詢)
? 避免OR條件,使用UNION替代
索引層面檢查清單
? 為WHERE條件創建索引
? 為ORDER BY字段創建索引
? 創建覆蓋索引減少回表
? 定期分析索引使用情況
? 刪除冗余索引
? 復合索引字段順序合理
配置層面檢查清單
? innodb_buffer_pool_size設置合理
? 連接數配置適當
? 臨時表大小配置合理
? 日志文件大小適中
? 查詢緩存配置(MySQL 5.7及以下)
硬件層面檢查清單
? 使用SSD存儲數據文件
? 內存容量充足
? CPU性能滿足需求
? 網絡帶寬充足
? 磁盤IO性能良好
高級優化技巧
1. 分區表的應用
-- 按時間分區 CREATE TABLEorders ( idINTPRIMARY KEY, user_idINT, create_time DATETIME, amountDECIMAL(10,2) )PARTITIONBYRANGE(YEAR(create_time)) ( PARTITIONp2022VALUESLESS THAN (2023), PARTITIONp2023VALUESLESS THAN (2024), PARTITIONp2024VALUESLESS THAN (2025), PARTITIONp_futureVALUESLESS THAN MAXVALUE );
2. 物化視圖優化
-- PostgreSQL物化視圖 CREATEMATERIALIZEDVIEWmonthly_salesAS SELECT DATE_TRUNC('month', create_time)asmonth, SUM(amount)astotal_sales, COUNT(*)asorder_count FROMorders GROUPBYDATE_TRUNC('month', create_time); -- 定時刷新 REFRESH MATERIALIZEDVIEWmonthly_sales;
3. 連接池優化
# Python連接池配置 fromsqlalchemyimportcreate_engine fromsqlalchemy.poolimportQueuePool engine = create_engine( 'mysql://user:pass@localhost/db', poolclass=QueuePool, pool_size=20, # 連接池大小 max_overflow=30, # 超出pool_size的連接數 pool_pre_ping=True, # 驗證連接有效性 pool_recycle=3600, # 連接回收時間(秒) )
優化心得和最佳實踐
1. 優化原則
1.測量優先:沒有監控數據,就沒有優化方向
2.漸進式優化:每次只改一個參數,觀察效果
3.業務導向:技術服務于業務,不為優化而優化
4.成本控制:硬件升級要考慮投入產出比
2. 常見誤區
? 盲目增加索引
? 過度優化不常用的查詢
? 忽視硬件瓶頸
? 沒有備份就直接在生產環境調參數
3. 優化時機
? 系統響應時間超過業務要求
? 數據庫CPU/內存/IO使用率持續過高
? 出現大量慢查詢
? 用戶投訴系統卡頓
總結:構建高性能數據庫的核心要點
經過多年的實戰經驗,我總結出數據庫性能優化的"6字真言":測、析、優、驗、監、調。
測:建立完善的監控體系,量化性能指標
析:深入分析瓶頸原因,找到根本問題
優:制定優化方案,從SQL到硬件全方位提升
驗:在測試環境驗證效果,確保方案可行
監:持續監控優化效果,預防性能回退
調:根據業務變化,持續調整優化策略
性能優化ROI排行榜
根據我的實戰經驗,各種優化手段的投入產出比排序:
1.SQL優化- 成本最低,收益最高
2.索引優化- 立竿見影的效果
3.參數調優- 性價比極高
4.架構優化- 解決根本問題
5.硬件升級- 成本高但效果顯著
最后的建議
數據庫優化是一個持續的過程,不是一次性的工作。建議大家:
1.建立基線:記錄優化前的各項指標
2.小步快跑:每次小幅度調整,觀察效果
3.文檔記錄:詳細記錄每次優化的過程和結果
4.團隊分享:將優化經驗分享給團隊成員
記住:沒有銀彈,只有最適合你業務場景的優化方案。
-
硬件
+關注
關注
12文章
3605瀏覽量
69095 -
SQL
+關注
關注
1文章
803瀏覽量
46826 -
數據庫
+關注
關注
7文章
4061瀏覽量
68451
原文標題:數據庫性能優化:從 SQL 到硬件調優完全指南
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
數據庫SQL的優化
基于數據庫查詢過程優化設計
如何優化數據庫負載
提高Oracle的數據庫性能
基于Greenplum數據庫的查詢優化
數據庫設計時應該考慮什么?數據庫設計和物理存儲結構這里概述
深度 | 性能全面超數據庫專家,騰訊基于機器學習的性能優化系統
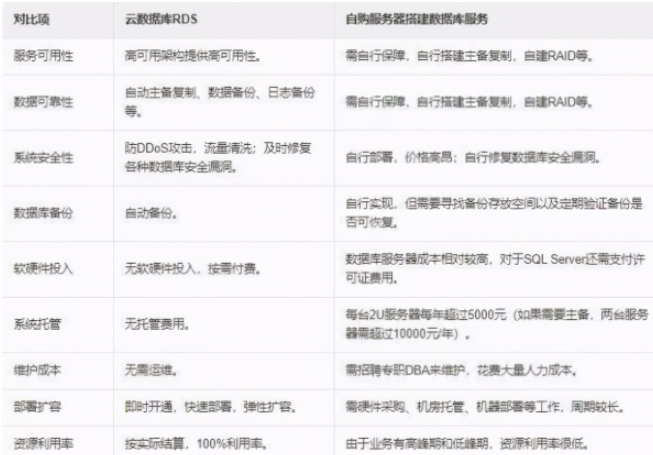
數據庫索引使用策略及優化

數據庫優化最有效的方式是什么?
優化數據庫性能使用LSI MegaRAID CacheCade Pro 2.0讀/寫緩存軟件

數據庫優化那些事



 工商網監
工商網監
評論