 Text2SQL準確率暴漲22.6%!3大維度全拆
Text2SQL準確率暴漲22.6%!3大維度全拆

摘要
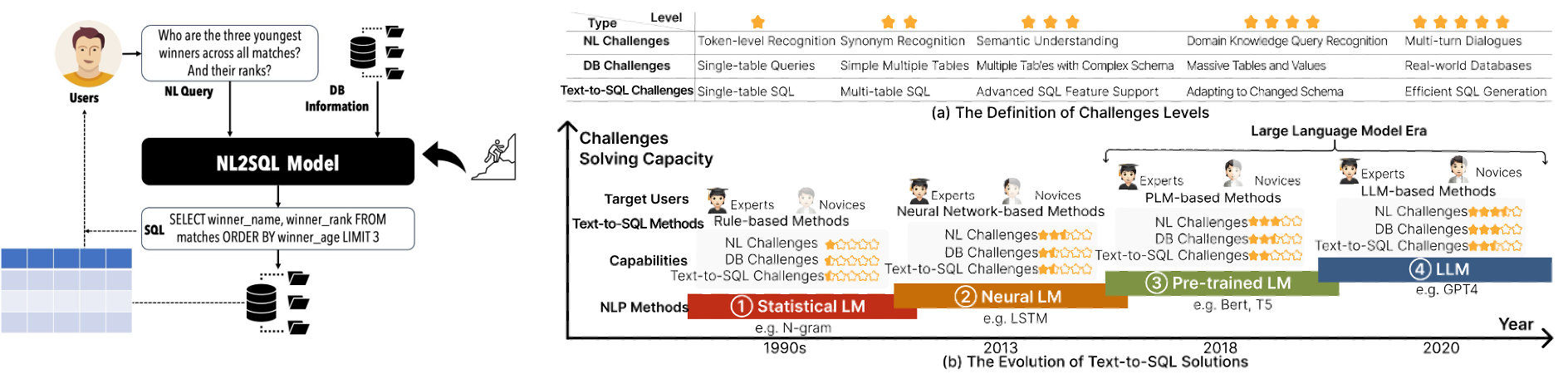
技術背景:Text2SQL 是將自然語言查詢轉為 SQL 的任務,經歷了基于規則、神經網絡、預訓練語言模型、大語言模型四個階段。當前面臨提示優化、模型訓練、推理時增強三大難題,研究基于 BIRD 數據集展開。
方法:提出 J-Schema 呈現數據庫結構并合理提供示例值,結合思維鏈引導模型推理。采用 Iterative DPO 迭代訓練,多輪迭代提升性能。用自洽性方法,通過硬 / 軟投票從多個候選答案中選最優,軟投票更優。
結果:解決 Text2SQL 性能提升的三大難題,將模型在 BIRD 數據集上的執行準確率從 56.6% 提升至 69.2%。
一、Text2SQL挑戰
自然語言到 SQL(Text-to-SQL),也稱為 NL2SQL,是將自然語言查詢轉換為可在關系數據庫上執行的相應SQL查詢的任務。具體來說,給定一個自然語言和一個關系數據庫,Text-to-SQL 的目標是生成一個SQL,該SQL能夠準確反映用戶的意圖,并在數據庫上執行時返回適當的結果。通過將自然語言查詢轉換為結構化查詢語言的能力,使復雜數據集更易于訪問。它極大地促進了非專業用戶和高級用戶從大量數據存儲中提取價值信息。
Text-to-SQL 解決方案的演進,經歷了四個不同階段:
1. 基于規則階段:早期的Text2SQL方法主要依賴于基于規則的統計語言模型,主要聚焦于單表查詢,理解能力僅限于詞元階段;
2. 基于神經網絡階段:神經網絡模型(序列模型、圖神經模型),提升了同義詞處理和意圖理解能力,使研究從單表擴展到多表場景。但其泛化能力仍受模型規模和訓練數據量限制;
3. 預訓練語言模型階段:預訓練語言模型(如BERT和T5)的引入顯著提升了性能,極大增強了自然語言理解能力;
4. 大語言模型階段:LLM憑借強大的涌現能力,成為當前Text2SQL領域的主流方案。研究重心轉向優化提示工程和微調LLM。
?
??
?
Text2SQL性能的提升,面臨著以下三個難題。
提示優化:怎么引導大模型給出明確的推理過程?數據庫的Schema要怎么設計,才能讓大模型更容易理解?
模型訓練:如何通過訓練方法提升模型的基礎能力?
推理時增強:大模型生成答案時好時壞,有什么辦法能讓輸出更加穩定可靠?
我們從這三個維度,分別給出了我們的答案。在本文中使用的數據集來自BIRD(BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation)。BIRD考察了大規模數據庫內容對文本到 SQL 解析的影響。BIRD 包含超過12,751個獨特的[問題-SQL]對,95 個大型數據庫,還涵蓋了超過 37 個專業領域,例如區塊鏈、冰球、醫療保健和教育等。
??
二、Prompt & J-Schema
要讓 LLM 理解數據庫結構,需在提示中提供數據庫模式。為此,我們提出一種名為 J-Schema 的新型數據庫表達方式。J-Schema 以完全結構化的格式呈現數據、表與列之間的層次關系,并采用特殊標記進行識別:用 “#DB_ID” 標記數據庫,“#Table” 表示表,“#Foreign keys” 表示外鍵。對于每個表,會給出表名;列信息則通過 “basic_info” 標識,其中包含列名、列描述、主鍵標識符,且為每個列提供示例值。
?

??
?
對于單一模型而言,在無法執行值檢索的情況下,提供盡可能豐富的示例值有助于模型深化對列的理解。然而,示例值過多會受限于上下文長度。為平衡示例值數量與上下文長度之間的關系,我們為值建立了新的顯示規則。
1.“DATE”、“TIME”、“DATETIME”、“TIMESTAMP”等表示時間的數據類型,只保留一個示例;
2.“REAL”浮點數據類型,保留兩位小數一個示例;
3.針對“INTEGER”整型,保留一個示例;
4.針對“TEXT”文本類型,根據分詞長度保留。小于10 token保留多個示例。
在這套規則背后,包含了我們對大量錯誤樣本的分析。對于日期、浮點數、整數這些數據類型,大模型往往是根據問題中的日期、時間要求來取值,因此增加這些數據類型的示例對最終的結果影響不大。而針對文本數據類型,往往涉及到用戶查詢和數據庫中值格式不統一問題。例如問題詢問的關鍵字是大寫的“North Bohemia”,而數據庫中的值為小寫的“north Bohemia”,若給出的示例中包含“north Bohemia”,則可以正確檢索。實驗驗證J-Schema在多個模型上均有執行準確率較大提升。
?
| 問題 | 正確答案 | 錯誤答案 | 原因分析 |
|---|---|---|---|
| What is the city location of the high school level school with Lunch Provision 2 whose lowest grade is 9 and the highest grade is 12 in the county of Merced? | SELECT T2.City FROM frpm AS T1 INNER JOIN schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1.`NSLP Provision Status` = 'Lunch Provision 2' AND T2.County = 'Merced' AND T1.`Low Grade` = 9 AND T1.`High Grade` = 12 AND T2.EILCode = 'HS' | SELECT T2.City FROM main.frpm AS T1 INNER JOIN main.schools AS T2 ON T1.CDSCode = T2.CDSCode WHERE T1."NSLP Provision Status" = 'Breakfast Provision 2' AND T1."Low Grade" = '9' AND T1."High Grade" = '12' AND T1."County Name" = 'Merced'; | 要求檢索的是“Lunch Provision 2”,因為示例值只給出了“Breakfast Provision 2”,導致檢索錯誤。可以通過增加示例解決。 |
| How many accounts who choose issuance after transaction are staying in East Bohemia region? | SELECT COUNT(T2.account_id) FROM district AS T1 INNER JOIN account AS T2 ON T1.district_id = T2.district_id WHERE T1.A3 = 'east Bohemia' AND T2.frequency = 'POPLATEK PO OBRATU' | SELECT COUNT(T1.account_id) FROM main.account AS T1 INNER JOIN main.district AS T2 ON T1.district_id = T2.district_id WHERE T1.frequency = 'POPLATEK PO OBRATU' AND T2.A3 = 'East Bohemia' | 問題的格式“East Bohemia”與示例值“east Bohemia”的格式不統一,增加示例值,讓模型學習到標準的值格式。 |
?
思維鏈(Chain of Thought, CoT)是一種提升大語言模型復雜推理能力的提示工程技術,核心是引導模型在輸出最終答案前,先生成連貫的中間推理步驟,模擬人類逐步思考的過程。在我們的提示中首先給出完整的數據庫信息,然后添加用戶查詢和外部知識,并給出引導大模型分步進行推理的提示,將推理過程輸出在和標記內,將最終的SQL答案輸出在和標記內。
?
三、訓練方法
Iterative DPO
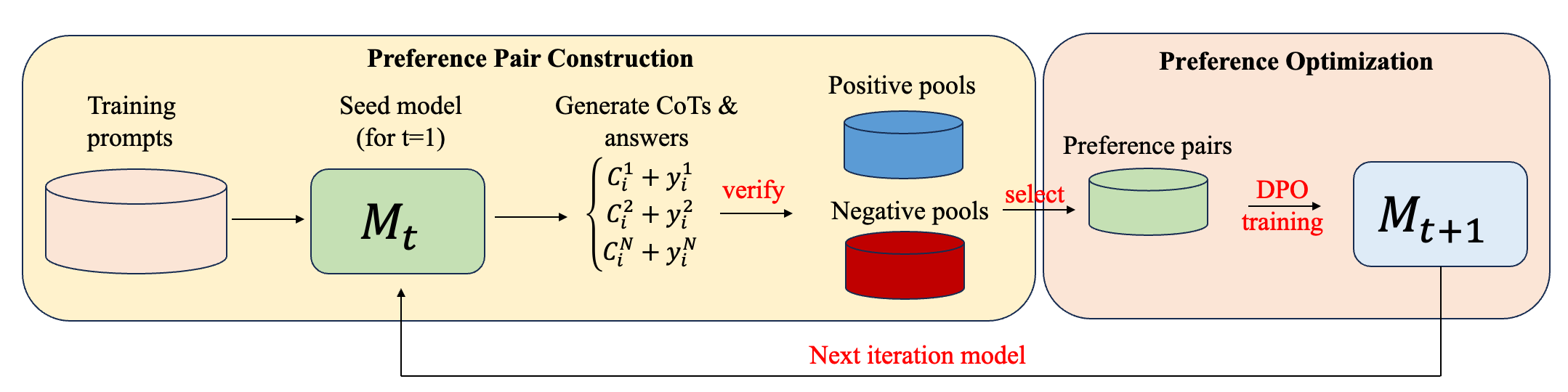
偏好優化已被證明,在將預訓練語言模型與人類需求對齊時,相較于單獨的監督微調能帶來巨大的收益。DPO等離線方法因其簡單性和效率而越來越受歡迎。最近的研究結果表明,迭代應用這種離線流程是有益的,其中更新后的模型被用來構建更具有信息量的新偏好關系,從而進一步改善結果。為了提高模型的基礎能力,我們采用迭代式的DPO訓練方法。
具體而言,在每次迭代中,我們從訓練提示中采樣多個思維鏈推理步驟和最終答案,通過驗證最終答案,構建正例池和負例池,在正、負例池根據距離挑選來構建偏好對,然后進行DPO訓練。在訓練新模型后,我們通過生成新偏好對并重新訓練來迭代該過程。我們發現推理性能在多次迭代后逐漸提高,最終達到飽和。
?
??
?
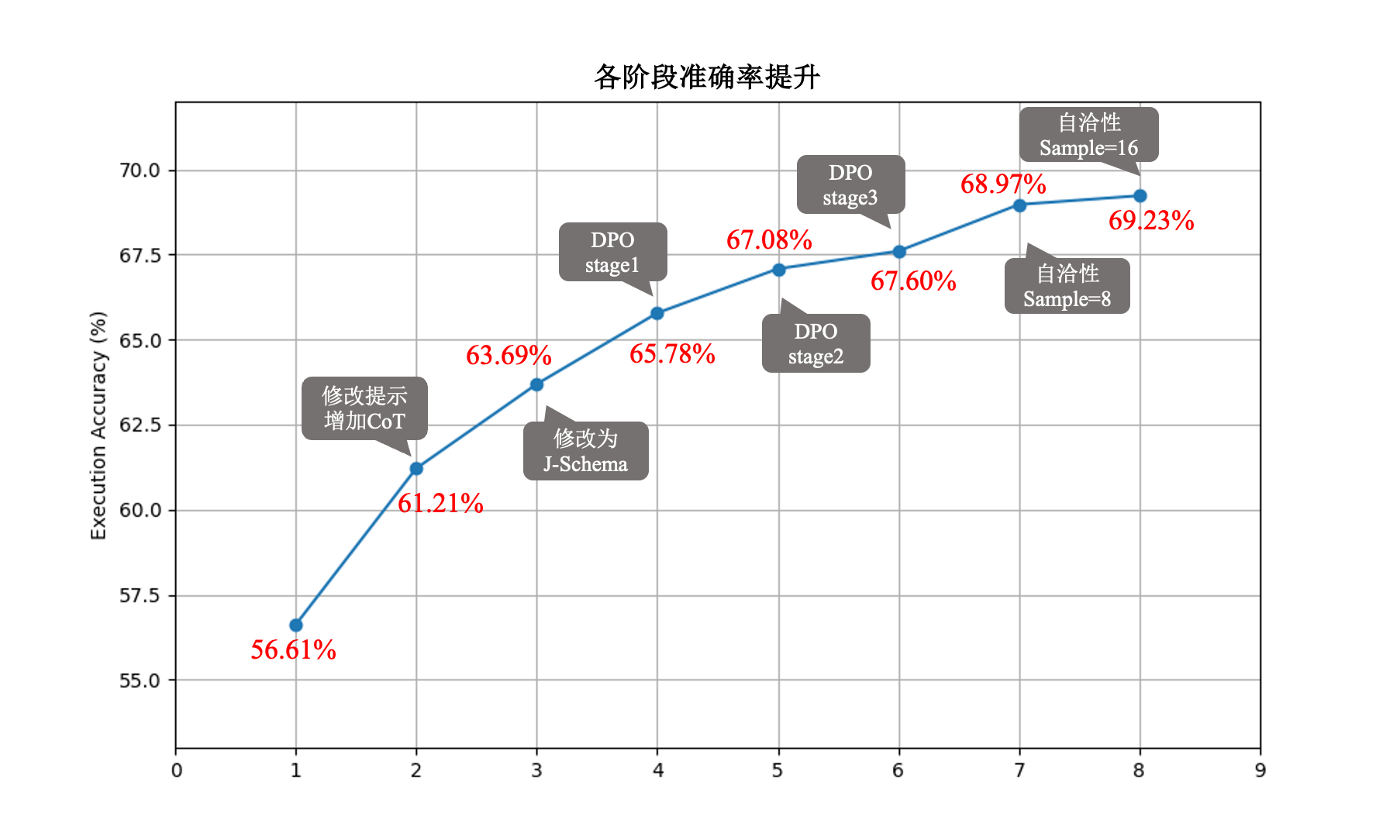
每一輪迭代中Text2SQL準確率提升如下表所示。在第三輪迭代中執行準確率達到最高,并飽和,繼續迭代執行準確率下降。并且隨著迭代輪次的增加,思維鏈的長度也在不斷增加。
| 模型 | 平均CoT token長度 | 執行準確率EX |
|---|---|---|
| Qwen2.5-Coder-32B | 334 | 63.69% |
| iterative stage1 | 377 | 65.78% |
| iterative stage2 | 377 | 67.08% |
| iterative stage3 | 380 | 67.60% |
| iterative stage4 | 384 | 67.40% |
?
超參數掃描
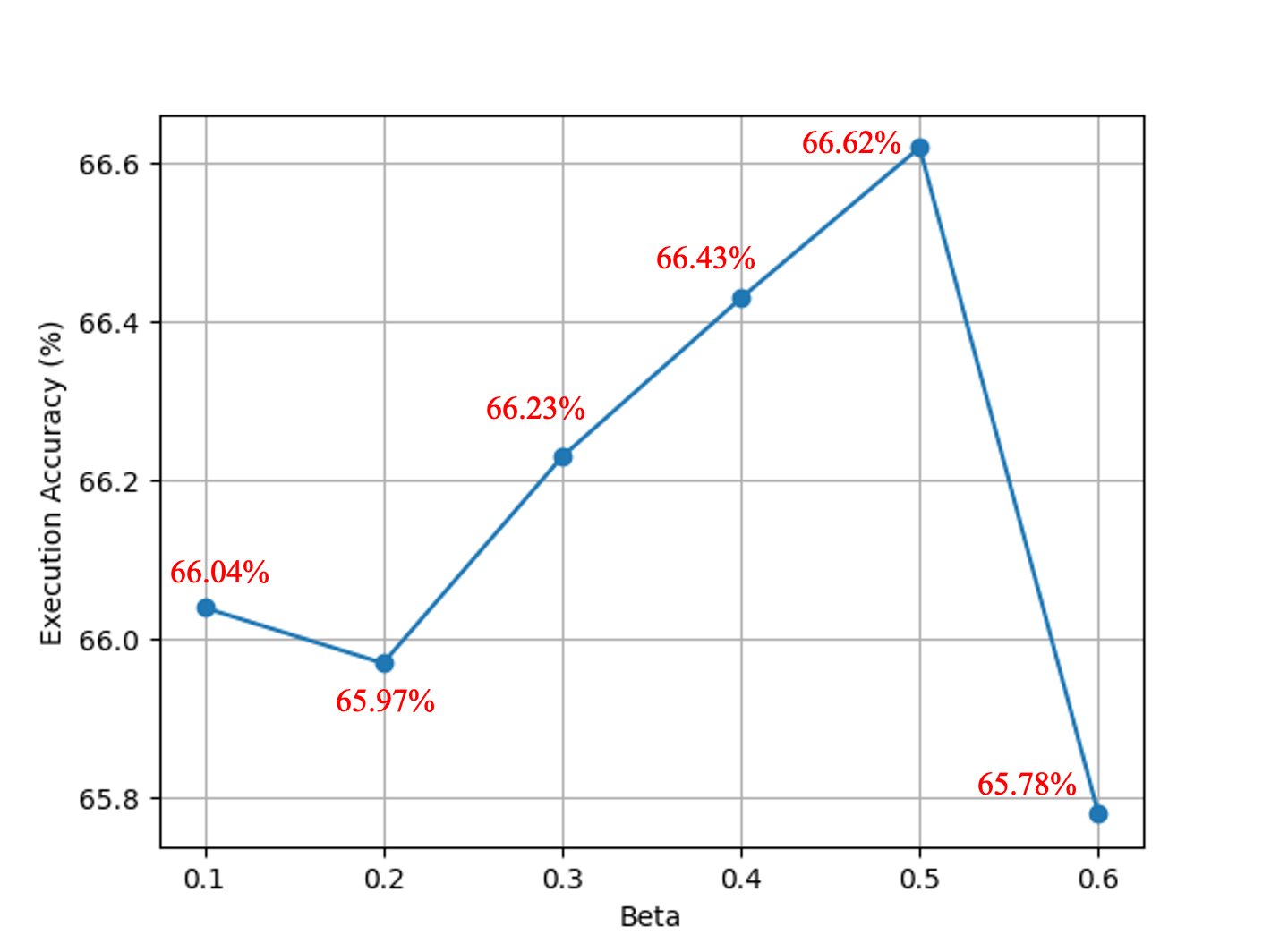
我們通過DPO方法進行訓練, beta是DPO Loss中的權重系數,數值越小越忽略參考模型,通常取0.1~0.5。因為我們觀察到DPO對齊算法對這一參數特別敏感。我們設置了beta從0.1、0.2 、...、0.6變化。所有實驗均訓練兩個 epoch。每次運行時,其他超參數保持不變,包括隨機種子。不同beta值對應的執行準確率如下圖所示。當beta取0.5時,達到最高的執行準確率,后續的DPO迭代中我們都延續使用該beta值。
?
四、自洽性(Self-consistency)
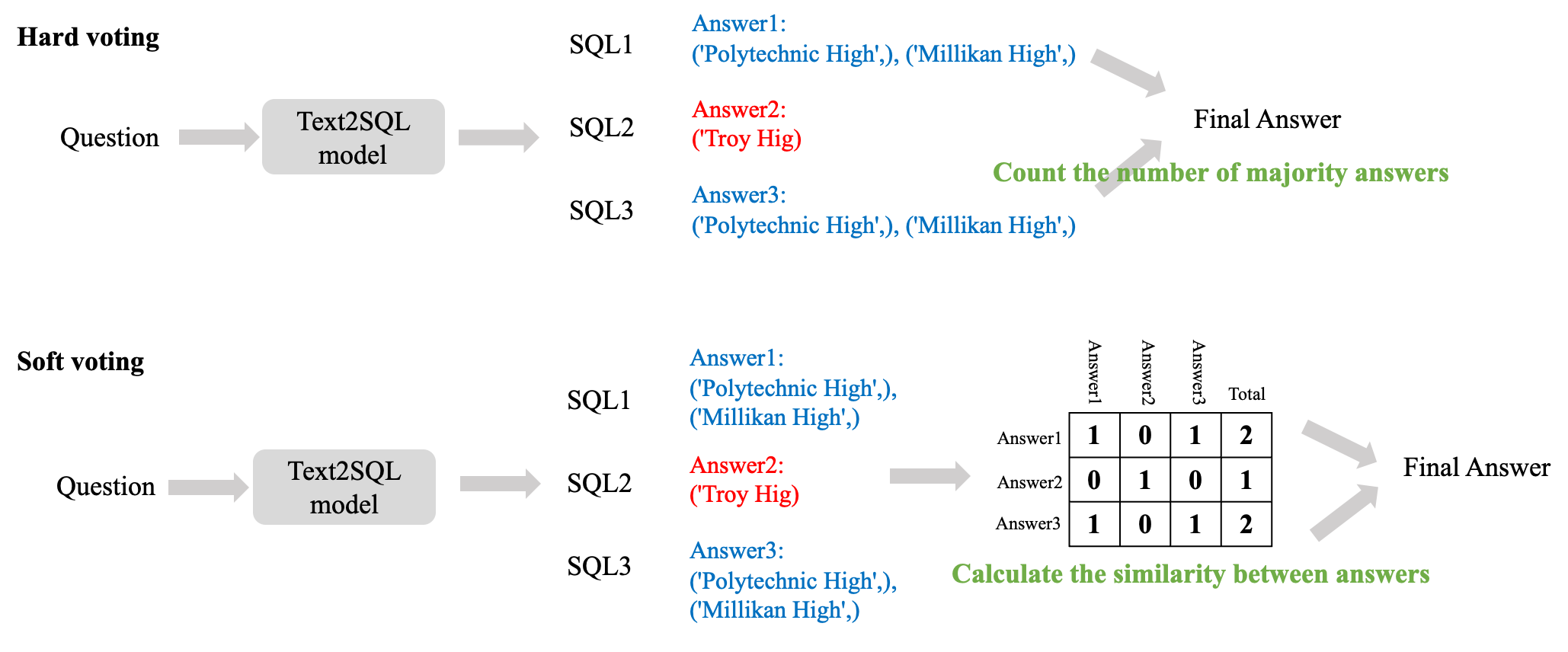
自一致性的核心思想是:讓模型對同一問題生成多個候選答案,然后通過投票機制選擇最優解,而不是只依賴單次生成結果。在單訓練模型賽道自洽性是被允許的,因為它反映了模型自身的性能。
在實現自洽性的過程中,我們使用了硬投票和軟投票兩種方式。硬投票直接根據模型生成結果的最終表現(如執行結果是否正確,二元判斷)進行投票,不考慮結果之間的相似程度。軟投票的決策依據是根據結果之間的相似程度(連續值)。如下圖所示。
?
??
?
在某些場景下,硬投票可能過于嚴格:
?語義等價但結果有細微差異:例如 SQL 查詢結果的順序不同,但邏輯上是等價的。
?近似正確的結果:例如模型生成了一個接近正確答案的解,但存在小誤差。軟投票通過相似度計算,可以將這些 “近似正確” 的結果納入考慮,從而提高最終答案的可靠性。
不同的checkpoint模型使用自洽性均獲得了1%以上的執行準確率提升,其中軟投票方法要優于硬投票方法。
| 模型 | 無自洽性 | 硬投票 | 軟投票 |
|---|---|---|---|
| iterative stage3 | 67.60% | 67.93% | 68.97% |
| iterative stage4 | 67.40% | 67.40% | 68.45% |
五、未來探索
1.數據構造
SynSQL-2.5M是百萬規模的文本到 SQL 數據集,包含超過250萬份多樣且高質量的數據樣本,涵蓋來自不同領域的 16000 多個數據庫。如何從250萬份樣本中篩選出對于BIRD有益的數據將會是未來的重點嘗試方向。
2. 其他訓練方法
?GRPO通過組內相對獎勵來優化策略模型,在Text2SQL任務中,只需要定義獎勵函數(例如執行正確獎勵為1,執行錯誤獎勵為0),而不需要預先構建偏好數據對。9N LLM的新鏡像中提供了提交GRPO的訓練任務可作嘗試。在目前的嘗試中,GRPO的訓練時長主要受到reward驗證的影響,采樣n次時,每一個SQL樣本都需要連接數據庫執行驗證來獲取獎勵。為了縮短訓練時間,可以事先刪除執行時長過長的樣本。
?在BIRD訓練集中,針對多輪DPO后的模型,進行多次采樣時,仍然全錯的樣本,經過檢查有很大部分是自身標簽錯誤,使用LLM-as-Judge訓練方法,使模型能夠具備判斷正負樣本的能力,并且進一步刪除標簽錯誤的樣本,保留正確樣本。
3. 增加測試該優化方法的數據集和真實場景
用多個測試數據集有助于魯棒性,能夠更加全面的檢驗模型的性能。其中知名的數據集還有SPIDER、ScienceBenchmark、EHRSQL等。我們將在這些測試集驗證我們的優化方案。并且我們會逐步推廣到DataAgent的真實應用中。對于企業級的大型數據庫來說,還會有哪些新的挑戰?我們會持續關注,不斷探索和改進!
審核編輯 黃宇
-
SQL
+關注
關注
1文章
807瀏覽量
46882 -
數據庫
+關注
關注
7文章
4074瀏覽量
68490 -
LLM
+關注
關注
1文章
349瀏覽量
1382
發布評論請先 登錄
兆易創新年報,利潤暴漲的核心全在這

慢SQL分析選型:DMS/DAS與NineData該如何選擇

NineData 社區版的慢SQL分析,比查看日志+看EXPLAIN適合中小團隊

靠聽診器查故障?這套系統靠 “聽聲紋”,準確率 96%
RTOS Crash 問題全維度分析與解決指南
智慧光伏綜合管理系統中的“全維度監測”
構建CNN網絡模型并優化的一般化建議
除了準確率,電能質量在線監測裝置在諧波源識別方面還有哪些重要指標?
電能質量在線監測裝置識別諧波源的準確率有多高?
深海連接器: 從原理到應用的全維度解析
精準匹配哈爾濱零碳標準!安科瑞EMS3.0實現碳排放數據準確率≥98%



 工商網監
工商網監
評論