 推薦系統的算法、評估和冷啟動解決方案
推薦系統的算法、評估和冷啟動解決方案

推薦系統是機器學習技術在企業中最成功和最廣泛的應用之一。

Machine Learning for Recommender systems?—?Part 1 (algorithms, evaluation and cold start)
引言
你可以在許多用戶與項目交互的場景中應用推薦系統。
你可以在零售、視頻點播或音樂流中找到大型推薦系統。為了開發和維護這樣的系統,公司通常需要一群昂貴的數據科學家和工程師。這就是為什么即使是像BBC這樣的大公司也決定外包其推薦服務的原因。
我們公司總部設在布拉格,開發了一個通用的自動化推薦引擎,能夠適應多個領域的業務需求。我們的引擎已被世界各地的數百家企業使用。

令人驚訝的是,對于媒體的新聞或視頻推薦、旅行和零售中的產品推薦或個性化推薦,都可以通過類似的機器學習算法來處理。此外,這些算法還可以在每次推薦請求中使用我們特有的查詢語言進行調整。
算法

推薦系統中的機器學習算法通常分為兩類:基于內容的推薦方法和協同過濾方法,盡管現代推薦者將這兩種方法結合在一起。基于內容的方法是基于項目屬性的相似性和協作方法,從交互中計算相似度。下面我們主要討論協同過濾方法,使用戶能夠發現與過去查看過的項目不同的新內容。

協同過濾方法與交互矩陣一起工作,當用戶提供項目的顯式評分時,這種交互矩陣也可以稱為評分矩陣。機器學習的任務是學習一個函數,它可以預測項目對每個用戶的效果。矩陣通常很大,非常稀疏,而且大多數值都丟失了。

最簡單的算法是計算行(用戶)或列(項)的余弦或其他相關相似性,并推薦k個最近鄰居喜歡的項。
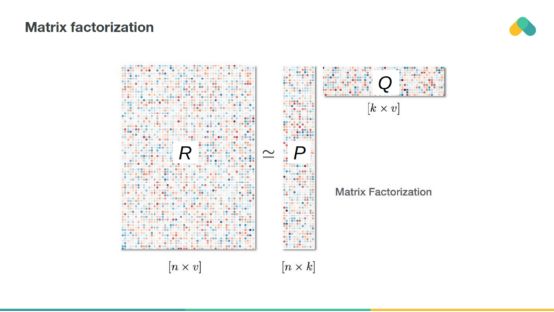
基于矩陣因式分解的方法試圖降低相互作用矩陣的維數,并將其近似為兩個或多個具有k個潛在分量的小矩陣。

通過將相應的行和列相乘,你可以根據用戶預測項目的評分。訓練誤差可以通過比較非空評分和預測評分來獲得。還可以通過增加懲罰項,保持潛在向量的低值來調整訓練損失。

最流行的訓練算法是隨機梯度下降算法,通過對p q矩陣的列和行進行梯度更新,使下降損失最小化。

或者,可以使用交替最小二乘法,通過一般最小二乘步驟迭代優化矩陣p和矩陣q。

關聯規則也可用于推薦。經常在一起消費的項目與圖形中的邊緣相關聯。你可以看到一組暢銷書(幾乎每個人都與之交互的緊密連接的項目)和小的、分離的內容集群。

從交互矩陣中挖掘出的規則至少應該有一些最小的支持度(support)和置信度(confidence)。支持度與發生頻率有關,比如暢銷書有很高的支持度。高置信度意味著規則不會經常被違反。
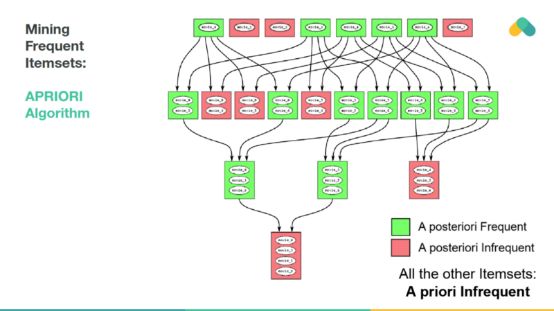
挖掘規則的規模不大,先驗算法探索了可能的頻繁項集的狀態空間,消除了搜索空間中不頻繁的分支。
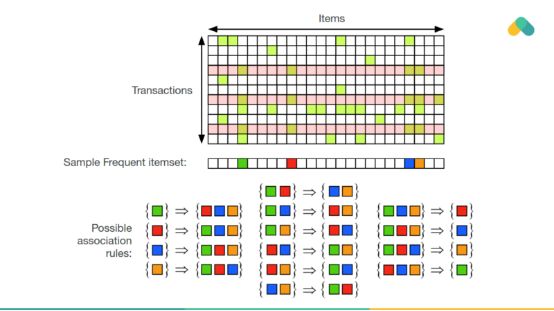
頻繁項集用于生成規則,這些規則產生推薦。

例如,我們展示了從捷克共和國的銀行交易中提取的規則。節點(交互)是終端,邊緣是頻繁的交易。你可以根據過去的取款/付款推薦相關的銀行終端。
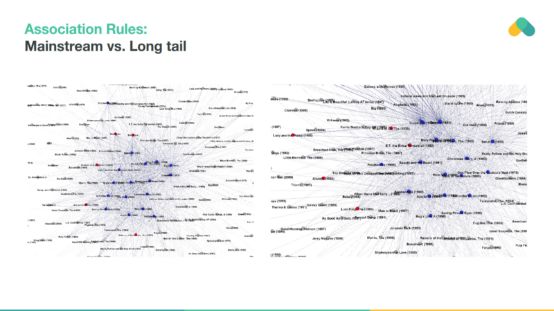
懲罰受歡迎的項目和提取支持度較低的長尾規則會產生有趣的規則,使推薦多樣化并有助于發現新的內容。
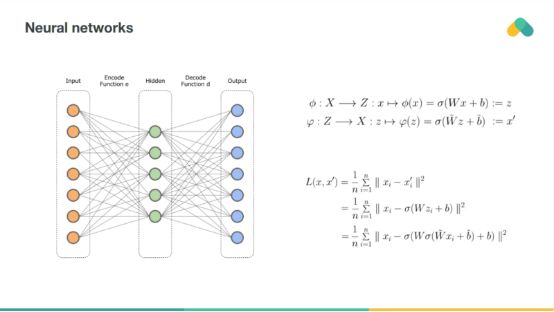
評分矩陣也可以用神經網絡進行壓縮,所謂的自編碼器與矩陣分解非常相似,具有多個隱藏層和非線性的深層自編碼器更強大,但更難訓練。神經網絡也可以用來預處理項屬性,這樣就可以將基于內容的方法和協同過濾方法結合起來。

上面給出了user-KNN Top-N推薦偽代碼。

關聯規則可以通過多種不同的算法來挖掘。這里我們給出了最佳規則推薦(Best-Rule recommendations)的偽代碼。

上面給出了矩陣因式分解的偽代碼。

在協同深度學習中,結合項目屬性與自編碼器同時訓練矩陣因式分解,當然還有更多的算法可用于推薦,本文的下一部分介紹了一些基于深度學習和強化學習的方法。
推薦系統的評估
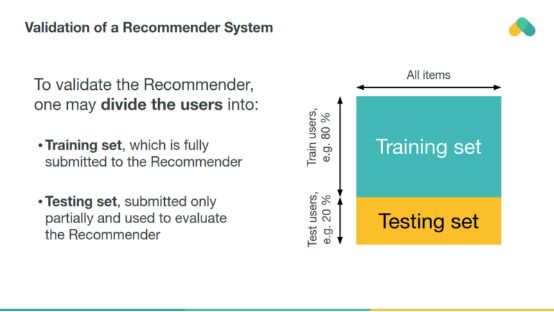
推薦者可以與歷史數據上的經典機器學習模型(離線評估)進行類似的評估。
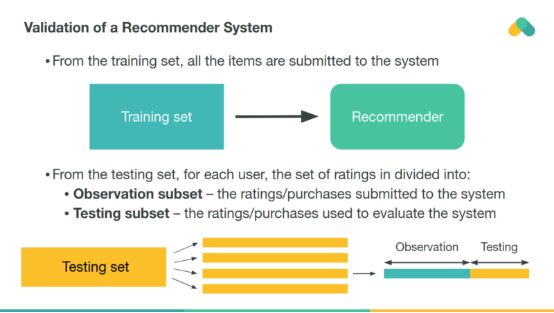
隨機選擇的測試用戶之間的交互作用被交叉驗證,以估計推薦者在未見的評級上的性能。

盡管許多研究表明,均方誤差(RMES)對在線性能的估計能力較差,但它仍得到了廣泛的應用。

更實用的離線評估措施是召回率(Recall)或準確率(Precision)評估正確推薦項目的百分比(不包括推薦項目或相關項目)。DCG還考慮到了假設項目的相關性對數下降時的位置。
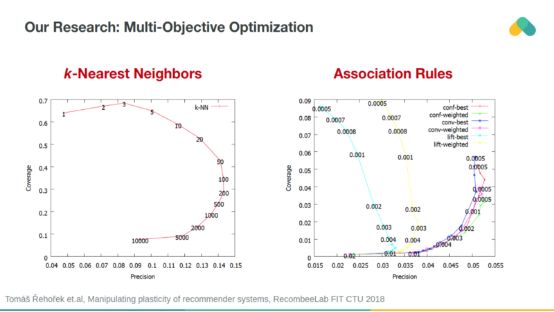
我們可以使用對離線數據偏差不太敏感的附加度量。Catalog coverage以及Recall或Precision可以用于多目標優化。我們在所有算法中引入正則化參數,允許對它們的可塑性進行操作,并懲罰對流行項的推薦。
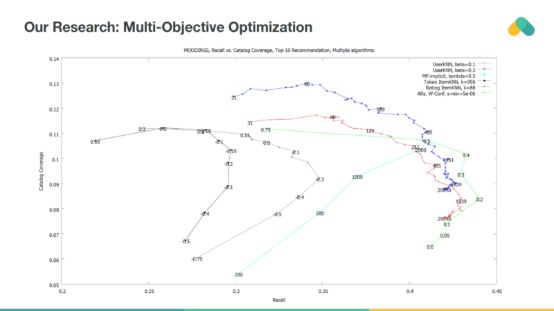
Recall和coverage都應該最大化,因此推動推薦系統向準確和多樣化發展,使用戶能夠探索新的內容。
冷啟動和基于內容的推薦

交互有時會丟失。冷啟動產品或冷啟動用戶沒有足夠的交互來可靠地度量其交互相似性,因此協同過濾方法無法產生推薦。
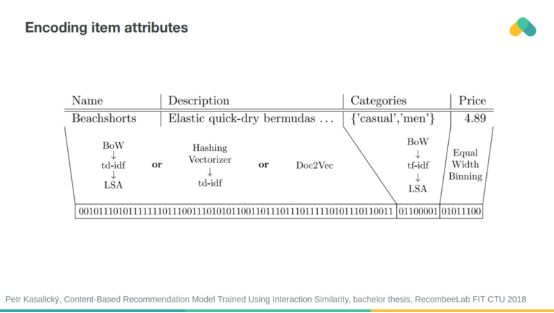
當考慮到屬性相似性時,冷啟動問題可以減少。你可以將屬性編碼成二進制向量,并提供系統進行推薦。
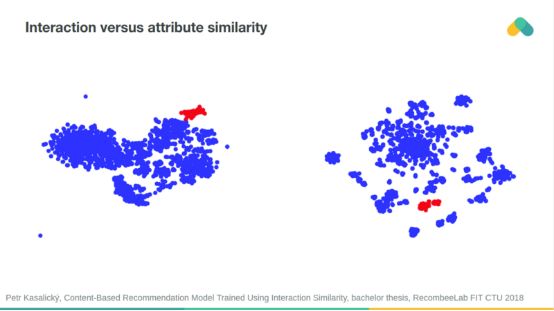
基于交互相似性和屬性相似性的項目聚類往往是對齊的。
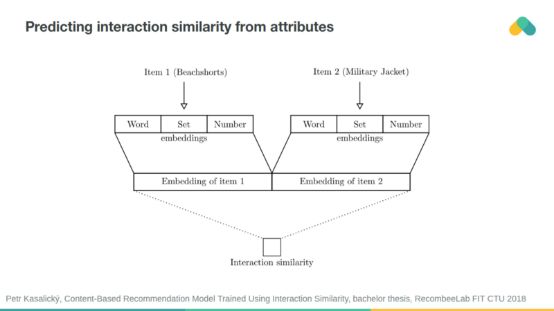
你可以使用神經網絡從屬性相似性預測交互相似性,反之亦然。
有很多其他方法使我們能夠減少冷啟動問題,提高推薦質量。在第二部分中,我們將會討論基于會話(sessionbased)的推薦技術、深度推薦、集成算法和自動化,使我們能夠在生產中運行和優化數千種不同的推薦算法。
-
機器學習
+關注
關注
66文章
8558瀏覽量
137115 -
推薦系統
+關注
關注
1文章
44瀏覽量
10466
原文標題:【干貨】推薦系統中的機器學習算法與評估實戰
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
單片機復位和冷啟動詳細介紹

鴻蒙原生頁面高性能解決方案上線OpenHarmony社區 助力打造高性能原生應用
Android熱修復升級探索——代碼修復冷啟動方案
針對汽車冷啟動優化的雙開關降壓升壓單電感器設計方案
協同過濾系統項目冷啟動的混合推薦算法
冷啟動傳感器開關特性測量系統


西門子PLC的暖啟動、冷啟動、熱啟動有何區別
華為云發布冷啟動加速解決方案:助力Serverless計算速度提升90%+
基于DPU的容器冷啟動加速解決方案



 工商網監
工商網監
評論