 一文搞懂 Python 正則表達式用法
一文搞懂 Python 正則表達式用法

Python 正則表達式
正則表達式是一個特殊的字符序列,它能幫助你方便的檢查一個字符串是否與某種模式匹配。
Python 自1.5版本起增加了re 模塊,它提供 Perl 風格的正則表達式模式。
re 模塊使 Python 語言擁有全部的正則表達式功能。
compile 函數根據一個模式字符串和可選的標志參數生成一個正則表達式對象。該對象擁有一系列方法用于正則表達式匹配和替換。
re 模塊也提供了與這些方法功能完全一致的函數,這些函數使用一個模式字符串做為它們的第一個參數。
正則表達式模式
模式字符串使用特殊的語法來表示一個正則表達式:
字母和數字表示他們自身。一個正則表達式模式中的字母和數字匹配同樣的字符串。
多數字母和數字前加一個反斜杠時會擁有不同的含義。
標點符號只有被轉義時才匹配自身,否則它們表示特殊的含義。
反斜杠本身需要使用反斜杠轉義。
由于正則表達式通常都包含反斜杠,所以你最好使用原始字符串來表示它們。模式元素(如 r'\t',等價于 '\\t')匹配相應的特殊字符。
下表列出了正則表達式模式語法中的特殊元素。如果你使用模式的同時提供了可選的標志參數,某些模式元素的含義會改變。
模式
描述
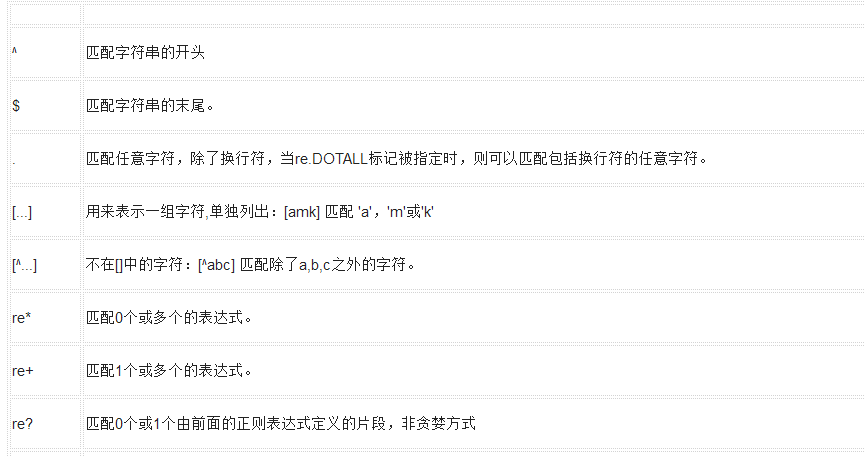

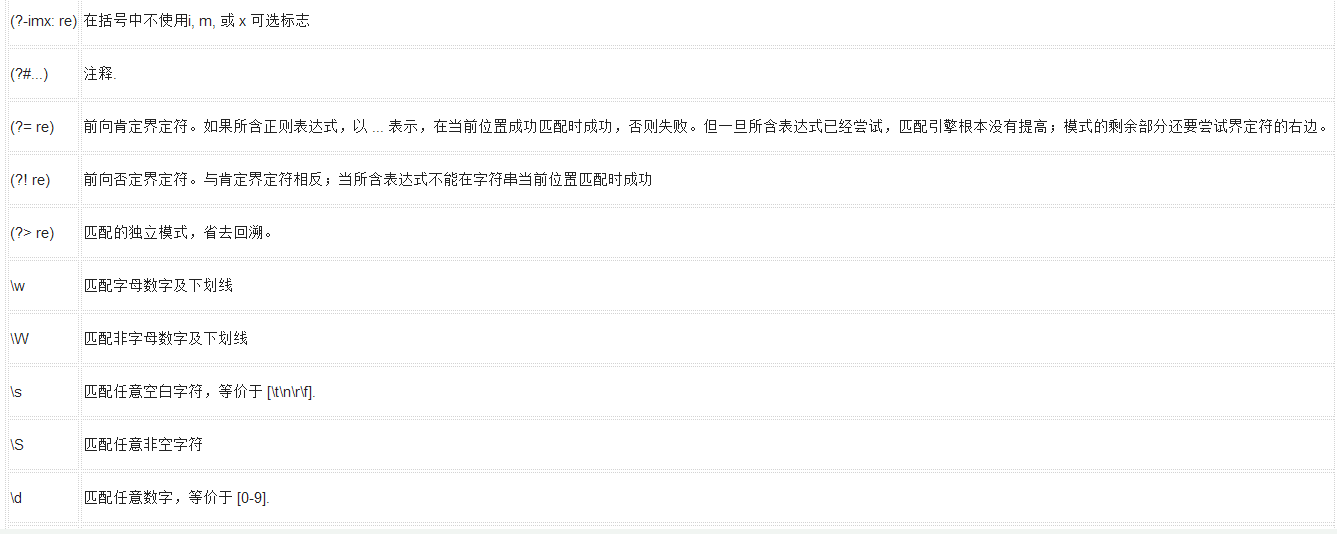
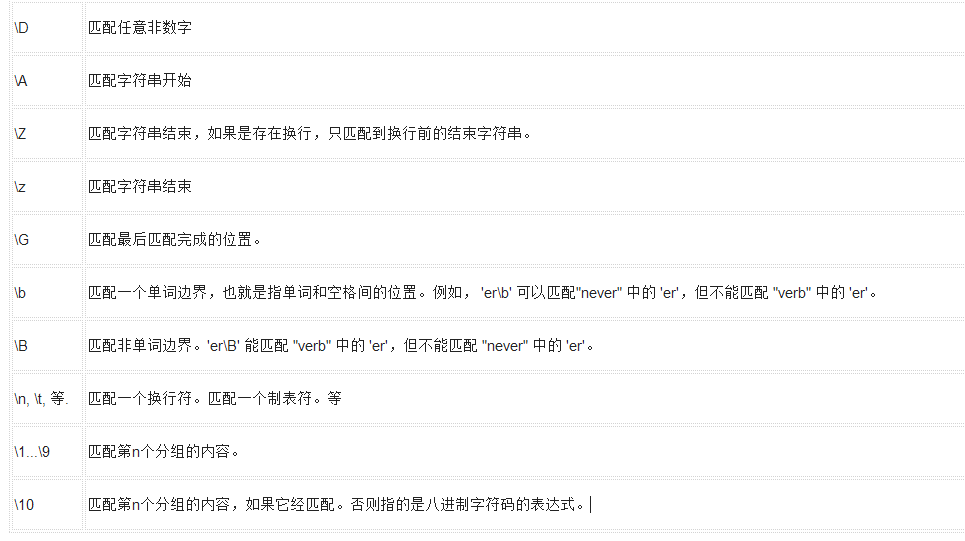
字符匹配正則表達式實例
實例
描述

字符類
實例
描述
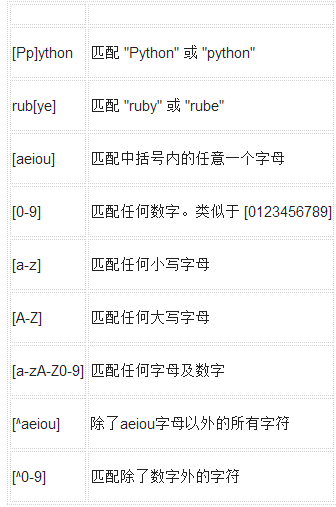
特殊字符類
實例
描述

1.Re模塊簡介
re模塊是python中處理正則表達式的一個模塊,通過re模塊的方法,把正則表達式pattern編譯成正則對象,以便使用正則對象的方法
效率問題:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:02# @Author : Feng Xiaoqing# @File : test.py# @Function: -----------import reimport timeit print(timeit.timeit(setup='''import re; reg = re.compile('<(?Pxxx
')''', number=1000000)) print(timeit.timeit(setup='''import re''', stmt='''re.match('<(?Pxxx
')''', number=1000000)) reg = re.compile('<(?Pxxx
')
執行結果:
0.42296138327572711.0246964437151256
常用方法:先申明一個正則對象,在通過正則對象去匹配。這樣的效率高。
1 re.compile(pattern[, flags])方法
re.I(re.IGNORECASE): 忽略大小寫(括號內是完整寫法,下同)
M(MULTILINE): 多行模式,改變'^'和'$'的行為
S(DOTALL): 點任意匹配模式,改變'.'的行為
L(LOCALE): 使預定字符類 \w \W \b \B \s \S 取決于當前區域設定
U(UNICODE): 使預定字符類 \w \W \b \B \s \S \d \D 取決于unicode定義的字符屬性
X(VERBOSE): 詳細模式。這個模式下正則表達式可以是多行,忽略空白字符,并可以加入注釋。以下兩個正則表達式是等價的:
compile 函數用于編譯正則表達式,生成一個正則表達式( Pattern )對象,供 match() 和 search() 這兩個函數使用。
語法格式為:
re.compile(pattern[, flags])
參數:
pattern: 一個字符串形式的正則表達式
flags: 可選,表示匹配模式,比如忽略大小寫,多行模式等,具體參數為:
re.I忽略大小寫
re.L表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境
re.M多行模式
re.S即為.并且包括換行符在內的任意字符(.不包括換行符)
re.U表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依賴于 Unicode 字符屬性數據庫
re.X為了增加可讀性,忽略空格和#后面的注釋
實例
>>>import re>>> pattern = re.compile(r'\d+') # 用于匹配至少一個數字>>> m = pattern.match('one12twothree34four') # 查找頭部,沒有匹配>>> print mNone>>> m = pattern.match('one12twothree34four', 2, 10) # 從'e'的位置開始匹配,沒有匹配>>> print mNone>>> m = pattern.match('one12twothree34four', 3, 10) # 從'1'的位置開始匹配,正好匹配>>> print m # 返回一個 Match 對象<_sre.SRE_Match object at 0x10a42aac0>>>> m.group(0) # 可省略 0'12'>>> m.start(0) # 可省略 03>>> m.end(0) # 可省略 05>>> m.span(0) # 可省略 0(3, 5)
在上面,當匹配成功時返回一個 Match 對象,其中:
group([group1, …])方法用于獲得一個或多個分組匹配的字符串,當要獲得整個匹配的子串時,可直接使用group()或group(0);
start([group])方法用于獲取分組匹配的子串在整個字符串中的起始位置(子串第一個字符的索引),參數默認值為 0;
end([group])方法用于獲取分組匹配的子串在整個字符串中的結束位置(子串最后一個字符的索引+1),參數默認值為 0;
span([group])方法返回(start(group), end(group))。
再看看一個例子:
實例
>>>import re>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小寫>>> m = pattern.match('Hello World Wide Web')>>> print m # 匹配成功,返回一個 Match 對象<_sre.SRE_Match object at 0x10bea83e8>>>> m.group(0) # 返回匹配成功的整個子串'Hello World'>>> m.span(0) # 返回匹配成功的整個子串的索引(0, 11)>>> m.group(1) # 返回第一個分組匹配成功的子串'Hello'>>> m.span(1) # 返回第一個分組匹配成功的子串的索引(0, 5)>>> m.group(2) # 返回第二個分組匹配成功的子串'World'>>> m.span(2) # 返回第二個分組匹配成功的子串(6, 11)>>> m.groups() # 等價于 (m.group(1), m.group(2), ...)('Hello', 'World')>>> m.group(3) # 不存在第三個分組Traceback (most recent call last): File "
2.findall方法
在字符串中找到正則表達式所匹配的所有子串,并返回一個列表,如果沒有找到匹配的,則返回空列表。
注意:match 和 search 是匹配一次 findall 匹配所有。
語法格式為:
findall(string[, pos[, endpos]])
參數:
string: 待匹配的字符串。
pos: 可選參數,指定字符串的起始位置,默認為 0。
endpos: 可選參數,指定字符串的結束位置,默認為字符串的長度。
查找字符串中的所有數字:
實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re pattern = re.compile(r'\d+') # 查找數字result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)
輸出結果:
['123', '456'] ['88', '12']
Re模塊的方法:
(1)re.match函數
re.match 嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回none。
函數語法:
re.match(pattern, string, flags=0)
函數參數說明:
參數
描述

匹配成功re.match方法返回一個匹配的對象,否則返回None。
我們可以使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
匹配對象方法
描述

#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re pattern = re.compile(r'\d+') # 查找數字result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)實例
以上實例運行輸出結果為:
(0, 3) None
實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:55# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re line = "Cats are smarter than dogs" matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj: print "matchObj.group() : ", matchObj.group() print "matchObj.group(1) : ", matchObj.group(1) print "matchObj.group(2) : ", matchObj.group(2)else: print "No match!!"
以上實例執行結果如下:
matchObj.group() : Cats are smarter than dogsmatchObj.group(1) : CatsmatchObj.group(2) : smarter
(2)re.search方法
re.search 掃描整個字符串并返回第一個成功的匹配。
函數語法:
re.search(pattern, string, flags=0)
函數參數說明:
參數
描述

匹配成功re.search方法返回一個匹配的對象,否則返回None。
我們可以使用group(num) 或 groups() 匹配對象函數來獲取匹配表達式。
匹配對象方法
描述

#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配實例
以上實例運行輸出結果為:
(0, 3) (11, 14)
實例
#!/usr/bin/pythonimport re line = "Cats are smarter than dogs"; searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj: print "searchObj.group() : ", searchObj.group() print "searchObj.group(1) : ", searchObj.group(1) print "searchObj.group(2) : ", searchObj.group(2)else: print "Nothing found!!"
以上實例執行結果如下:
searchObj.group() : Cats are smarter than dogssearchObj.group(1) : CatssearchObj.group(2) : smarter
re.match與re.search的區別
re.match只匹配字符串的開始,如果字符串開始不符合正則表達式,則匹配失敗,函數返回None;而re.search匹配整個字符串,直到找到一個匹配。
實例
#!/usr/bin/pythonimport re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I)if matchObj: print "match --> matchObj.group() : ", matchObj.group()else: print "No match!!" matchObj = re.search( r'dogs', line, re.M|re.I)if matchObj: print "search --> matchObj.group() : ", matchObj.group()else: print "No match!!"
以上實例運行結果如下:
No match!! search --> matchObj.group() : dogs
Match從開頭開始匹配,匹配不到,返回空
Search從開頭開始匹配,然后第第二個開始匹配,只匹配一個結果。
Match的效率是最高的,就要求我們正則表達式要寫正確
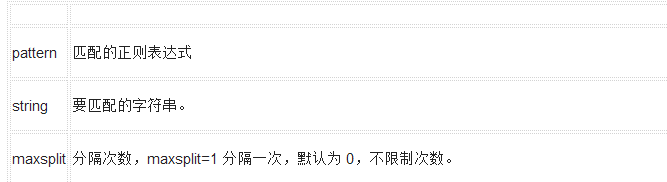
(3)Split方法
re.split
split 方法按照能夠匹配的子串將字符串分割后返回列表,它的使用形式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
參數:
參數
描述
實例
>>>import re >>> re.split('\W+', 'runoob, runoob, runoob.') ['runoob', 'runoob', 'runoob', ''] >>> re.split('(\W+)', ' runoob, runoob, runoob.') ['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', ''] >>> re.split('\W+', ' runoob, runoob, runoob.', 1) ['', 'runoob, runoob, runoob.'] >>> re.split('a*', 'hello world') # 對于一個找不到匹配的字符串而言,split 不會對其作出分割 ['hello world']
split(string[, maxsplit])
按照能夠匹配的子串將string分割后返回列表。maxsplit用于指定最大分割次數,不指定將全部分割。
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re p = re.compile(r'\d+') print(p.split('one1two2three3four4'))
結果:
['one', 'two', 'three', 'four', '']
(4)sub檢索和替換
Python 的 re 模塊提供了re.sub用于替換字符串中的匹配項。
語法:
re.sub(pattern, repl, string, count=0, flags=0)
參數:
pattern : 正則中的模式字符串。
repl : 替換的字符串,也可為一個函數。
string : 要被查找替換的原始字符串。
count : 模式匹配后替換的最大次數,默認 0 表示替換所有的匹配。
實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:33# @Author : Feng Xiaoqing# @File : test2.py# @Function: ----------- import re phone = "2004-959-559 # 這是一個國外電話號碼" # 刪除字符串中的 Python注釋 num = re.sub(r'#.*$', "", phone)print "電話號碼是: ", num # 刪除非數字(-)的字符串 num = re.sub(r'\D', "", phone)print "電話號碼是 : ", num
以上實例執行結果如下:
電話號碼是: 2004-959-559 電話號碼是 : 2004959559
repl 參數是一個函數
以下實例中將字符串中的匹配的數字乘以 2:
實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re pattern = re.compile(r'\d+') # 查找數字result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)
執行輸出結果為:
A46G8HFD1134
(5)findall方法
在字符串中找到正則表達式所匹配的所有子串,并返回一個列表,如果沒有找到匹配的,則返回空列表。
注意:match 和 search 是匹配一次 findall 匹配所有。
語法格式為:
findall(string[, pos[, endpos]])
參數:
string: 待匹配的字符串。
pos: 可選參數,指定字符串的起始位置,默認為 0。
endpos: 可選參數,指定字符串的結束位置,默認為字符串的長度。
查找字符串中的所有數字:
實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: ----------- import re pattern = re.compile(r'\d+') # 查找數字result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)
輸出結果:
['123', '456'] ['88', '12']
(6)finditer方法
和 findall 類似,在字符串中找到正則表達式所匹配的所有子串,并把它們作為一個迭代器返回。
re.finditer(pattern, string, flags=0)
參數:
參數
描述

實例
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 22:15# @Author : Feng Xiaoqing# @File : test2.py# @Function: -----------import re it = re.finditer(r"\d+","12a32bc43jf3") for match in it: print (match.group() )
輸出結果:
12 32 43 3
group()
group(0) group(1) group(“tagname”)
gourps()
groupdict()
findall
import re
p = re.compile(r'\d+')
print(findall('one1two2three3four4'))
結果:
['1', '2', '3', '4']
finditer
sub
Split \d+
‘one1two2three3four4’
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/4/29 20:24# @Author : fengxiaoqing# @File : test.py'''
xxx
查看不同匹配規則的效率'''import reimport timeit# print(timeit.timeit(setup='''import re; reg = re.compile('<(?Pxxx
')''', number=1000000))# print(timeit.timeit(setup='''import re''', stmt='''re.match('<(?Pxxx
')''', number=1000000))s = "abxxx
dsafasdfsdfads"reg = re.compile(r"(<(?P-
python
+關注
關注
57文章
4876瀏覽量
90025
原文標題:一文搞懂 Python 正則表達式用法
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
布爾表達式及范圍檢查
第4章 C語言基礎以及流水燈的實現(4.5 4.6)
inline ASM(內聯匯編)的細節分享
labview如何使用VISA串口資源查找的正則表達式提取串口的資源名稱?
基礎篇3:掌握Python中的條件語句與循環
Cubeide1.18.1在線調試改變\"現場表達式\"中的值提示找不到地址,為什么?
《ESP32S3 Arduino開發指南》第三章 C/C++語言基礎
Cubeide1.18.1在線調試改變\"現場表達式\"中的值提示找不到地址是怎么回事?
干貨分享 | 零基礎上手!TSMaster圖形信號表達式實操指南

Cubeide1.18.1在線調試改變\"現場表達式\"中的值提示找不到地址,怎么解決?
Cubeide1.18.1在線調試改變\"現場表達式\"中的值提示找不到地址怎么解決?
Linux中文本處理命令的用法



 工商網監
工商網監
評論