") 簡單聊聊,AI全棧方案之AI存儲
簡單聊聊,AI全棧方案之AI存儲

看到不少AI行業(yè)的團(tuán)隊在同一個地方摔跤:花大價錢搭了 GPU 集群,挖來算法高手優(yōu)化模型,最后卻卡在數(shù)據(jù)這一環(huán)節(jié)。就像燒著最旺的炭火,拿著祖?zhèn)魇氖匙V,要做菜時卻發(fā)現(xiàn)食材要么鎖在深窖里拿不出來,要么已經(jīng)受潮變質(zhì) —— 這樣怎么可能做出好菜?AI圈子里現(xiàn)在逐漸形成一個共識:算力決定跑多快,算法決定以什么姿勢跑,而數(shù)據(jù)才真正決定能跑多遠(yuǎn),不管是在訓(xùn)練,還是在推理。
一、數(shù)據(jù)是AI 的 "命根子",沒好數(shù)據(jù)一切白搭
老話說"巧婦難為無米之炊",以AI 訓(xùn)練為例,本質(zhì)上和煉丹沒區(qū)別。把 AI 訓(xùn)練比作煉丹,數(shù)據(jù)就是那些珍貴藥材,算法是祖?zhèn)鞯牡し剑懔t是爐膛里的火焰。火焰再旺,丹方再妙,沒有足夠的好藥材,終究煉不出真東西。之前參加過一個技術(shù)沙龍,某大廠 AI 負(fù)責(zé)人分享過一個案例:他們用同樣的算法和算力,分別用 100 萬和 1000 萬樣本訓(xùn)練圖像識別模型,前者準(zhǔn)確率死活突破不了 85%,后者輕松飆到 95%—— 這就是數(shù)據(jù)量對模型上限的直接影響。
數(shù)據(jù)質(zhì)量的重要性更不用多說。Garbage in,garbage out(GIGO),優(yōu)質(zhì)標(biāo)注數(shù)據(jù)和雜亂數(shù)據(jù)訓(xùn)練出的模型,能力天差地別。之前跟某自動駕駛公司的朋友聊,模型在測試集上準(zhǔn)確率高達(dá) 99%,實際路測卻頻頻誤判。最后排查發(fā)現(xiàn),訓(xùn)練數(shù)據(jù)里有大量不清晰的、重復(fù)標(biāo)注的樣本(這里澄清一個觀點,即便是現(xiàn)在的自動駕駛端到端模型訓(xùn)練,也不是直接把所有數(shù)據(jù)不做甄別不做處理的一股腦扔進(jìn)去),相當(dāng)于用一堆過期藥材煉丹,藥效自然打折扣。
但光有好數(shù)據(jù)還不夠,得有地方好好存著,要用的時候能馬上拿到。一個做垂直模型的朋友提供的信息,他們之前用10 臺 A100做微調(diào), 每天有 60% 的時間在空轉(zhuǎn),就因為數(shù)據(jù)從存儲加載到內(nèi)存要花兩小時。后來換成高性能存儲方案,加載時間壓縮到 15 分鐘,同等算力下的模型迭代速度直接提升 3 倍。這就是存儲的核心價值 —— 讓數(shù)據(jù)在需要的時候,以最快的速度到達(dá)該去的地方。
現(xiàn)在大模型訓(xùn)練的數(shù)據(jù)量早就突破PB 級了。某 AI 公司的訓(xùn)練數(shù)據(jù)集,光是文本就存了 80 萬億 tokens,相當(dāng)于把四庫全書復(fù)印幾千萬次。這么龐大的數(shù)據(jù)量,普通存儲根本扛不住 —— 不是存不下,是調(diào)不出來。就像你有一倉庫藥材,卻只有一個小窗口能取,煉丹時能不手忙腳亂嗎?
二、協(xié)議選擇:數(shù)據(jù)流轉(zhuǎn)的"交通規(guī)則"
搞AI 存儲,最容易被忽略的就是協(xié)議選擇。存儲的協(xié)議就像城市里的交通系統(tǒng)規(guī)則,不同路段得有不同規(guī)則:有的要兼容各種車型,有的要保證通行速度,有的得兼顧成本。選錯協(xié)議,就像在鄉(xiāng)村馬路上飆法拉利,再好的車也跑不起來。
數(shù)據(jù)收集階段就像在全國各地收藥材,得兼容各種運(yùn)輸方式。這時候NFS/SMB 協(xié)議就派上用場了,不管是監(jiān)控攝像頭的實時數(shù)據(jù),還是實驗室的測試樣本,還是企業(yè)塵封已久的生產(chǎn)數(shù)據(jù),都能通過這些通用協(xié)議匯總。某傳統(tǒng)AI公司(之前的幾小龍之一)做城市 AI 監(jiān)控項目時,接入的數(shù)據(jù)源有幾十種,從老舊模擬攝像頭到 4K 智能相機(jī),全靠傳統(tǒng)文件存儲協(xié)議的兼容性,才把分散的視頻幀統(tǒng)一存起來。
對象存儲的S3 協(xié)議適合收集互聯(lián)網(wǎng)數(shù)據(jù)。爬網(wǎng)頁、下圖片、存日志,這些非結(jié)構(gòu)化數(shù)據(jù)用 S3 協(xié)議管理效率最高。之前某搜索引擎公司搭的數(shù)據(jù)湖,用 S3 協(xié)議存了 200 億張圖片,既能按時間戳檢索,又能批量導(dǎo)出,比傳統(tǒng)文件系統(tǒng)省了非常多的管理成本。
這里稍微啰嗦一下文件存儲與對象存儲。對象存儲和文件存儲的核心區(qū)別,藏在數(shù)據(jù)組織的邏輯里。
文件存儲像傳統(tǒng)的戶籍檔案管理,用層層嵌套的文件夾構(gòu)建樹狀結(jié)構(gòu)—— 就像按 "省 - 市 - 區(qū) - 街道 - 小區(qū)" 的層級存放居民信息,要找某個人,得順著目錄一級級點開。這種結(jié)構(gòu)適合人機(jī)交互,我們能直觀理解 "文檔 / 項目報告 / 2025Q2" 這樣的路徑,但面對海量數(shù)據(jù)時,層級越多,查找效率越受影響,就像翻查跨省的老檔案,得先找省檔案館,再轉(zhuǎn)市檔案館,中間環(huán)節(jié)多了,自然慢下來。
對象存儲則是給每個數(shù)據(jù)單元發(fā)了"身份證",用鍵值對(Key-Value)的扁平結(jié)構(gòu)直接映射 —— 不管是北京的張三還是上海的李四,都用唯一標(biāo)識符關(guān)聯(lián)信息,無需層級跳轉(zhuǎn)。就像全國人口數(shù)據(jù)庫,輸入身份證號能直接調(diào)出信息,省去了翻找各級目錄的麻煩。這種結(jié)構(gòu)在數(shù)據(jù)量突破億級后優(yōu)勢明顯,某客戶的對象存儲系統(tǒng)里存了 10+ 億張圖片,用對象 ID 查找只需 10 毫秒,換成文件存儲按路徑查找,平均要花 300 毫秒。形象點說,文件存儲是按書架分類放書,找書得先看大類標(biāo)簽,再查小類抽屜;對象存儲則是給每本書貼了唯一二維碼,掃碼直接定位,哪怕書堆成山,也能一秒找到。這就是為什么 AI 訓(xùn)練的海量樣本、互聯(lián)網(wǎng)的非結(jié)構(gòu)化數(shù)據(jù),越來越多地選擇對象存儲 —— 不是樹狀結(jié)構(gòu)不好,而是當(dāng)數(shù)據(jù)多到像漫天繁星時,扁平的 "身份證" 式管理,顯然更高效。
到了數(shù)據(jù)處理階段,就像在倉庫里分揀藥材,需要靈活高效的操作。這時候HDFS 協(xié)議的優(yōu)勢就顯出來了,特別適合大數(shù)據(jù)處理框架。有電商平臺的客戶做用戶畫像訓(xùn)練,每天要處理 50TB 用戶行為數(shù)據(jù),用 HDFS 協(xié)議配合 Spark 集群,3 小時就能完成清洗和特征提取,換成普通文件協(xié)議得折騰一整夜。
最關(guān)鍵的模型訓(xùn)練階段,必須上"高速路"。POSIX 協(xié)議就像專為賽車設(shè)計的賽道,能讓數(shù)據(jù)以數(shù)十GB 級速度涌向 GPU。同樣的訓(xùn)練任務(wù),采用 POSIX 協(xié)議后,性能更高,GPU利用更高效。因為訓(xùn)練時 GPU 需要隨機(jī)讀取大量小文件,POSIX 協(xié)議的元數(shù)據(jù)處理能力遠(yuǎn)超其他協(xié)議,能避免 "賽車等紅燈" 的尷尬。
三、介質(zhì)選擇:給數(shù)據(jù)找對合適的承載對象
存儲介質(zhì)的選擇,本質(zhì)上是在速度、容量和成本之間找平衡。就像不同食材需要不同保鮮方式:有的要冷凍,有的要冷藏,有的常溫保存,有的做成熟食隨蒸隨用。選對介質(zhì),既能保證數(shù)據(jù)"新鮮",又能省下不少錢。
HDD 硬盤就像老家的地窖,容量大、成本低,適合存冷數(shù)據(jù)。比如科研機(jī)構(gòu)的氣象 AI 模型,要存過去 幾十0 年的全球氣象數(shù)據(jù),總量超 幾十 PB。用氦氣密封 HDD 組建歸檔存儲,每 TB 成本不到 NVMe SSD 的六分之一。雖然讀取慢點,但這些數(shù)據(jù)每月最多調(diào)用一次,完全能接受。
SATA SSD 好比家里的雙門冰箱,比地窖存取快,又比臺面保鮮盒能裝。之前有個銀行客戶的智能風(fēng)控系統(tǒng),要實時調(diào)取近 3 個月交易數(shù)據(jù),約 50TB。用 SATA SSD 組建存儲池后,相比于之前的HDD存儲系統(tǒng),單筆查詢時間從 HDD 的 2 秒壓到 0.3 秒,既滿足性能需求,又比全 NVMe 方案省了 60% 成本(這是之前的數(shù)據(jù),現(xiàn)在SATA SSD和Nvme SSD價格已經(jīng)差不多了)。但 SATA SSD 有瓶頸,接口速度最高 6Gbps,就像冰箱門太小,拿東西快不到哪去。
NVMe SSD 是真正的 "臺面保鮮盒",存取速率極高,PCIe 4.0 規(guī)格的順序讀寫速度能到 5GB/s以上,隨機(jī)讀寫 IOPS 輕松突破百萬,相當(dāng)于把藥材直接攤在煉丹爐邊。有自動駕駛公司訓(xùn)練決策模型時,要同時加載數(shù)十路高清攝像頭數(shù)據(jù),每路每秒 200MB,只有 NVMe SSD 能扛住這吞吐量。現(xiàn)在 PCIe 5.0 的 NVMe SSD 也普及了,速度比 4.0 翻一倍,極限性能又更高了。
實際使用時,合理的規(guī)劃是做數(shù)據(jù)分層:熱數(shù)據(jù)(正在訓(xùn)練的樣本、高頻訪問的模型參數(shù))放TLC 介質(zhì)的 NVMe SSD,像把新鮮菜放冰箱;溫數(shù)據(jù)(上周用過的訓(xùn)練集、模型 checkpoint)存 QLC 介質(zhì)的 NVMe SSD,相當(dāng)于放冷凍室;冷數(shù)據(jù)(歷史日志、原始采集數(shù)據(jù))歸檔到 HDD,就像放進(jìn)地窖。既保證性能,又把存儲成本控制在預(yù)算內(nèi)。
這里得注意一下:QLC 介質(zhì)雖便宜,但寫入壽命比 TLC 短。如果用 QLC做長期的數(shù)據(jù)讀寫,很容易出現(xiàn)壞塊(因為SSD有DWPD的限制)。正確做法是 TLC 存寫入頻繁的數(shù)據(jù),QLC 存以讀為主的數(shù)據(jù)。
四、部署形式:怎么擺"灶臺" 和 "食材庫"
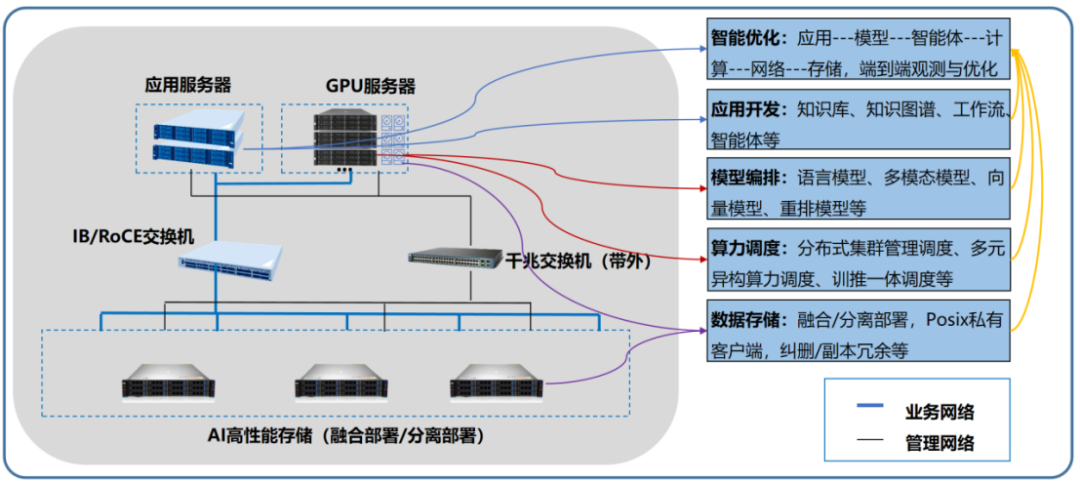
存儲和計算的部署方式,直接影響AI 系統(tǒng)的效率。
計算與存儲分離部署,就像把廚房和倉庫分開。倉庫做大些,存更多食材,廚房按需調(diào)整大小。這種方式的好處是靈活,某項目這樣規(guī)劃:因為計算和數(shù)據(jù)的需求沒有嚴(yán)格的對應(yīng)關(guān)系,用10 臺存儲服務(wù)器集中存數(shù)據(jù)和模型文件,前端根據(jù)業(yè)務(wù)部門的需求動態(tài)增減 GPU 節(jié)點,存儲資源卻不用動。對數(shù)據(jù)量比較大,且算力和數(shù)據(jù)需求非同步增長的場景,分離部署能省不少錢 —— 畢竟存儲和計算的生命周期不一樣,沒必要一起升級。
但分離部署有個繞不開的問題:數(shù)據(jù)搬運(yùn)。比如做圖像生成模型推理時,每次生成圖片都要從存儲加載**GB 數(shù)據(jù),分離部署時數(shù)據(jù)讀取時間很長,換成融合部署后,數(shù)據(jù)直接從本地讀取,延遲降到毫秒級。這就是計算存儲融合部署的優(yōu)勢:數(shù)據(jù)不用跑路,直接在本地處理。
計算存儲融合部署,相當(dāng)于把食材柜嵌在灶臺邊,拿取極快。某超算中心做大語言模型的二次訓(xùn)練時,用融合架構(gòu)把**TB 訓(xùn)練數(shù)據(jù)直接存在 GPU 服務(wù)器的本地 NVMe SSD 里,加載速度比分離部署快 4 倍,原本 10 天的訓(xùn)練周期縮短到 7 天。對數(shù)據(jù)密集型訓(xùn)練任務(wù),這種部署方式能把算力利用率拉滿 —— 畢竟 GPU 每空轉(zhuǎn)一秒都是錢。
比較合理的做法是"混合部署":訓(xùn)練微調(diào)階段的熱數(shù)據(jù)用融合部署(注意:這里的訓(xùn)練不是基礎(chǔ)模型的訓(xùn)練,是指做一些小型的微調(diào)),讓數(shù)據(jù)離算力越近越好;訓(xùn)練階段的冷數(shù)據(jù)和推理階段的數(shù)據(jù)用分離部署,方便靈活擴(kuò)縮容;冷數(shù)據(jù)歸檔則用獨(dú)立的HDD存儲,節(jié)省成本。
五、訓(xùn)練環(huán)節(jié):全流程的存儲需求
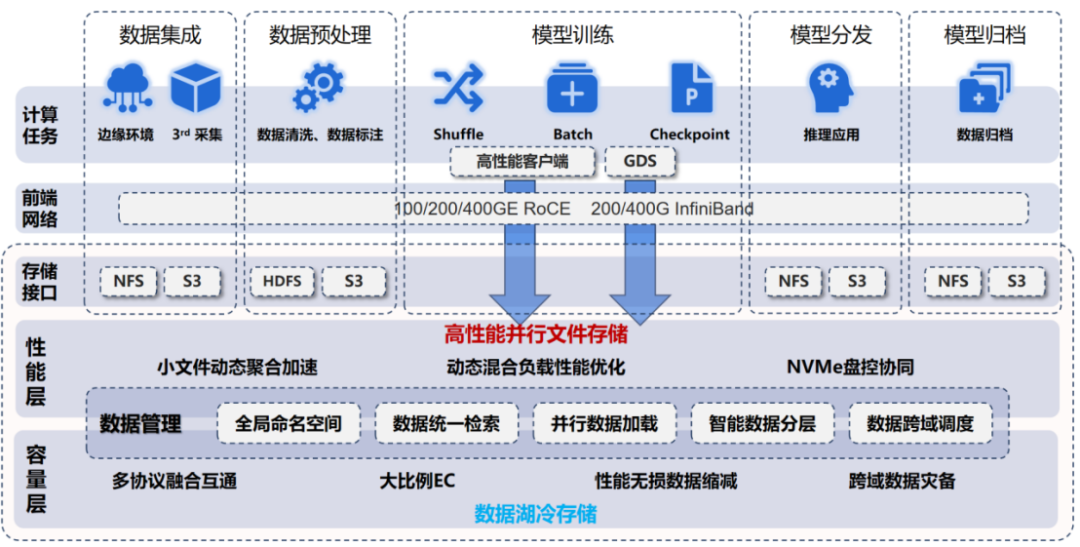
數(shù)據(jù)收集階段講究"全",不管結(jié)構(gòu)化表格還是非結(jié)構(gòu)化視頻,都得能存。某做垂直行業(yè)(農(nóng)業(yè))的 AI 公司收集農(nóng)田數(shù)據(jù)時,既用 S3 協(xié)議存無人機(jī)航拍圖,又用 NFS 協(xié)議取傳感器數(shù)據(jù),最后匯總到統(tǒng)一存儲池。這個階段存儲不用太快,但一定要能接各種數(shù)據(jù)源,就像收納箱得有不同尺寸的格子。
數(shù)據(jù)處理階段更看重"活"。清洗、標(biāo)注、格式轉(zhuǎn)換這些操作,需要存儲支持高并發(fā)小文件讀寫。某自動駕駛公司標(biāo)注 3D 點云數(shù)據(jù)時,每天要處理數(shù)百萬個小文件,用普通存儲時標(biāo)注軟件經(jīng)常卡殼,換成支持 POSIX 協(xié)議的并行文件系統(tǒng)后,100 個標(biāo)注員同時工作也不卡頓。
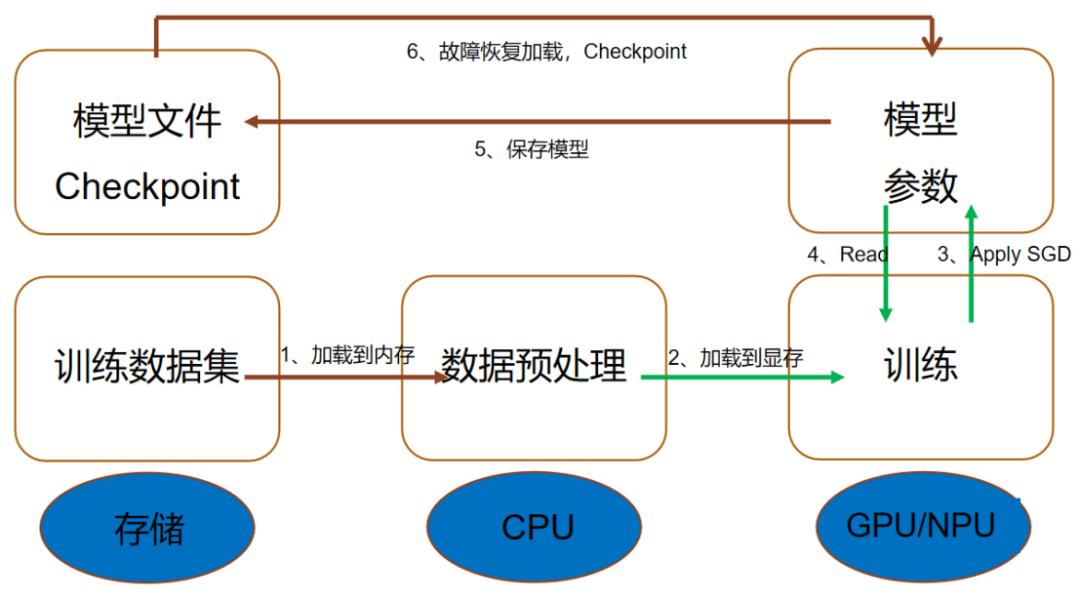
到了模型訓(xùn)練階段,存儲性能直接決定訓(xùn)練速度。Checkpoint 機(jī)制是存儲性能的 "照妖鏡"。簡單說,Checkpoint 就是訓(xùn)練過程中的 "存檔",定期把模型參數(shù)、優(yōu)化器狀態(tài)、訓(xùn)練步數(shù)這些關(guān)鍵信息存起來。為什么要存檔?某團(tuán)隊曾因 GPU 突然斷電,丟失了 3 天的訓(xùn)練進(jìn)度,不得不從頭再來 —— 這就是 Checkpoint 的價值。但存檔操作很費(fèi)存儲:一個 2000 億參數(shù)的模型,每次 Checkpoint 要寫 2T左右數(shù)據(jù),每小時存一次,一天就產(chǎn)生 48TB 數(shù)據(jù)。
更麻煩的是Checkpoint 的讀寫性能。某團(tuán)隊用普通存儲(基于Ceph架構(gòu)) 存 Checkpoint,每次寫入要等 10分鐘以上,為不影響訓(xùn)練,只能兩小時存一次,結(jié)果某天服務(wù)器故障,丟了近兩小時進(jìn)度。換成高性能存儲后,寫入時間壓縮到 30 秒,他們改成每 15 分鐘存一次,安全性大大提高,訓(xùn)練效率反而更高 —— 畢竟等待時間短了。在分布式訓(xùn)練中,Checkpoint 還得同步,100 個節(jié)點同時寫數(shù)據(jù),存儲系統(tǒng)要是扛不住,整個集群都得等著。
六、推理環(huán)節(jié):存儲性能的"精細(xì)活"
如果說訓(xùn)練對存儲是"暴飲暴食",那推理就是 "細(xì)水長流"—— 看似量小,實則講究精準(zhǔn)快速。
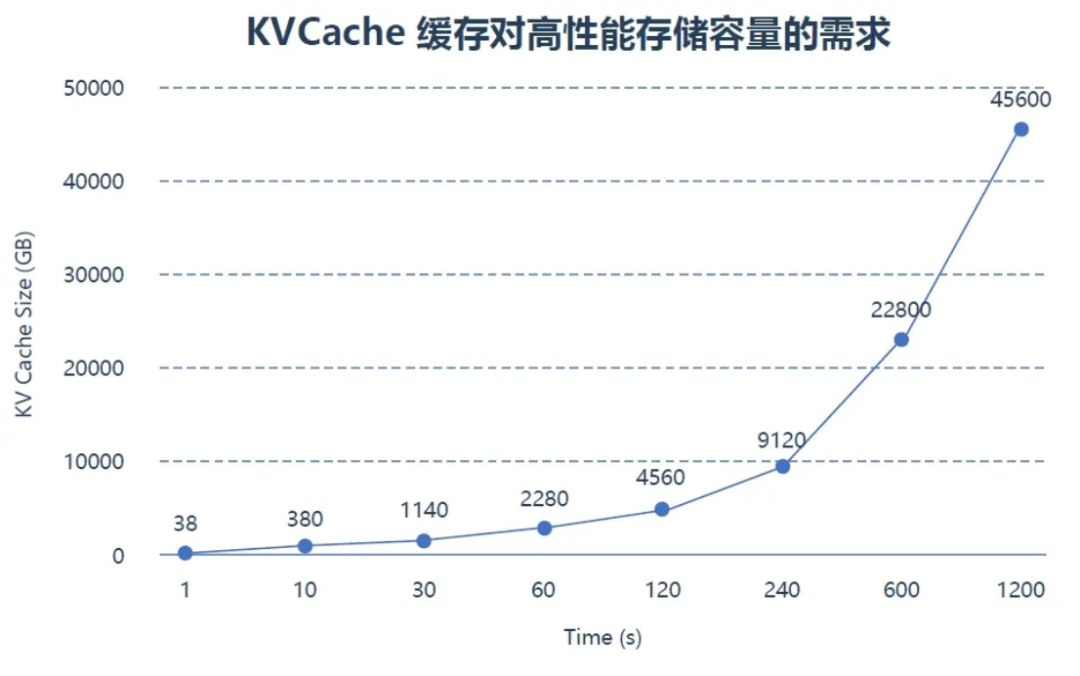
KV Cache 是大語言模型推理的 "內(nèi)存殺手"。簡單說,模型處理每段文本時,會生成一堆中間結(jié)果(Key 和 Value 向量)存在緩存里,后面接著處理時直接用,不用重算。就像廚師切菜時把常用配料放在手邊,不用每次去冰箱拿。但 GPU 的顯存就像廚房臺面,空間有限還貴得離譜 ——H100 的 80GB 顯存,每 GB 成本比 NVMe SSD 高 10 倍以上。
當(dāng)新用戶發(fā)來請求,GPU 顯存滿了怎么辦?只能把老用戶的 KV Cache 清掉。等老用戶繼續(xù)聊天時,又得重新生成這些緩存,非常浪費(fèi)算力,相當(dāng)于廚師把切好的配料扔了再重切,純屬浪費(fèi)功夫。
這時候高性能存儲就成了"救星"。把暫時不用的 KV Cache 挪到 NVMe SSD 里,用戶回來時再快速加載,比重新生成快 10 倍。之前做過測試:用 PCIe 4.0 NVMe SSD 存 KV Cache,恢復(fù)一個 1000 輪對話的上下文只需 80 毫秒,而重新生成要 1 秒,還省了 90% 算力。
推理存儲還有個特殊需求:低延遲。比如實時翻譯系統(tǒng)要求響應(yīng)時間低于100 毫秒,其中存儲讀取模型片段的時間必須控制在 30 毫秒內(nèi)。可以把常用小模型存在 GPU 顯存,大模型分片存在 NVMe SSD,用預(yù)加載技術(shù)提前把可能用到的片段讀進(jìn)內(nèi)存,既省了顯存,又保證了速度。
七、數(shù)據(jù)的未來
當(dāng)算力的火焰在集群中熊熊燃燒,當(dāng)算法的丹方在代碼中流轉(zhuǎn)迭代,真正決定AI 價值高度的,永遠(yuǎn)是那些靜默存儲的數(shù)據(jù)。它們是智能時代的原油,是訓(xùn)練模型的基石,是企業(yè)落地效果的保障,更是開啟AI認(rèn)知革命的密鑰。AI高性能存儲的價值,在于讓每一份數(shù)據(jù)都能在恰當(dāng)?shù)臅r刻迸發(fā)能量,如同精準(zhǔn)調(diào)配的藥材,在煉丹爐中淬煉出改變世界的力量。
數(shù)據(jù)存儲 + 算力調(diào)度 + 模型管理 + 知識庫 + Agent開發(fā) +E2E觀測優(yōu)化,AI全棧解決方案,六合一!
-
存儲
+關(guān)注
關(guān)注
13文章
4791瀏覽量
90066 -
AI
+關(guān)注
關(guān)注
91文章
39793瀏覽量
301443
發(fā)布評論請先 登錄

純4G?血版AI小智產(chǎn)品方案 #小智AI #AI方案商 #4G通話 #AI終端產(chǎn)品
黑芝麻智能AI全棧機(jī)器人計算平臺榮膺國際大獎
高達(dá)2070TFLOPS算力|騰視科技基于NVIDIA Jetson Thor系列模組,重磅推出全棧AI邊緣智算大腦解決方案

高達(dá)2070TFLOPS算力|騰視科技基于NVIDIA Jetson Thor系列模組,重磅推出全棧AI邊緣智算大腦解決方案
高達(dá)2070TFLOPS算力騰視科技基于NVIDIA Jetson Thor系列模組,重磅推出全棧AI邊緣智算大腦解決方案

AI應(yīng)用創(chuàng)新與全棧技術(shù)融合分論壇即將召開
NVIDIA全棧加速代理式AI應(yīng)用落地
德明利亮相COMPUTEX 2025: 以全棧存儲技術(shù)賦能AI產(chǎn)業(yè)落地
COMPUTEX 2025:德明利以全棧存儲技術(shù)賦能“AI NEXT”產(chǎn)業(yè)落地

從云端到終端:RAKsmart服務(wù)器構(gòu)筑AI云平臺智慧城市全棧解決方案
移遠(yuǎn)通信全棧 AI 解決方案沙龍圓滿收官,攜手火山引擎共啟消費(fèi)品AI升級新征程




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論