 Socionext推出神經網絡加速器,加速AI時代
Socionext推出神經網絡加速器,加速AI時代

先進視覺影像SoC應用技術領導廠商Socionext Inc.(以下“索喜科技”或“公司”)宣布推出神經網絡加速器 (Neural Network Accelerator engine,縮寫NNA),用于優化人工智能處理中的邊緣計算設備。它具備高速且低功耗的特性,是專用于深度學習中推理處理的加速器。相較以往的處理器,NNA在圖像識別等處理時性能提升約100倍。公司預計于2018年第三季度開始,配合FPGA軟件開發工具提供產品銷售。此外,搭載有NNA的SoC產品開發也正在規劃當中。
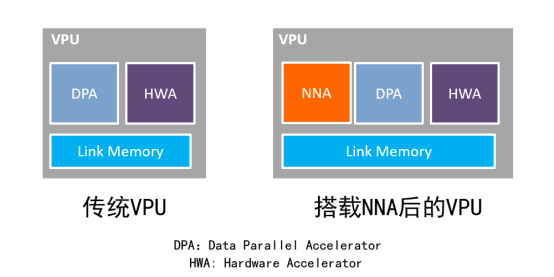
隨著消費電子、汽車電子、工業控制等越來越多的應用引入人工智能(AI),人工智能面臨著前所未有的快速發展,深度學習、神經網絡等技術迎來了發展高潮。神經網絡越大,需要的計算量就越大,傳統的VPU雖然也能完成人工智能運算,但因為高功耗和高延遲已經略顯疲憊。在VPU上加載人工智能計算能力則可以規避這些問題,而且具有更高的可靠性。
Socionext目前提供圖像處理SoC“SC1810”,這款芯片內置有技術標準化組織Khronos Group制定的API規范-OpenVX,內置有視覺處理器(VPU,Vision Processor Unit)。此次新推出的NNA加速器能VPU性能,可在汽車、數字標牌等多種應用中通過深度學習及傳統的影像識別執行多種電腦視覺處理,以便在較低功耗下提供更高的性能。
NNA采用量化技術整合了公司的專有構架,減少了深度學習所需的參數和激活值。通過量化技術能以較少的資源執行大量計算任務,大幅減少數據量,并顯著降低系統存儲器帶寬。此外,新開發的片上存儲器電路設計提高了深度學習所需的計算資源效率,能在非常小的封裝中實現最佳性能。搭載有NNA的VPU結合了最新的技術,能在圖像識別處理時比傳統VPU快100倍。
Socionext預計于2018年第三季度開始提供NNA FPGA軟件開發包。改軟件開發包可支持TensorFlow學習環境,并提供用于量化技術的專用庫和從學習模型到推論處理用的數據轉換工具。通過利用NNA優化后的學習環境,用戶無需模型壓縮或學習調諧(learning tuning)知識也能有效建立起他們自己的模型。今后Socionext還將計劃通過支持各種深度學習框架來支持應用廣泛的開發環境,讓用戶能簡單建立深度學習的應用程序。
與此同時,Socionext也計劃將載有NNA的SoC芯片投入市場。目標應用包括車載系統中的影像拍攝,以及基于行人、自行車等高精度物體識別的輔助駕駛以及自動泊車。另一個重要的應用便是顯示系統,例如電視、數字標牌,NNA可在超分辨率處理時增強圖像識別,提高4K/8K屏幕高清晰度成像。Socionext將不斷創新并開發出高效、高性能產品,以適應各種邊緣計算環境中廣泛的AI應用。
關于Socionext Inc.
Socionext Inc.是一家新成立的創新型企業,為全球客戶設計、開發和提供片上系統(System-on-chip)產品。公司專注于成像、網絡和電腦計算等其他能夠推動當今尖端應用發展的技術。Socionext集世界一流的專業知識、經驗和豐富的IP產品組合,致力于提供高效益的解決方案與更佳的客戶體驗。Socionext 成立于2015年,總部設在日本橫濱,在日本、亞洲、美國和歐洲設有辦事處,領導其產品開發和銷售。
-
soc
+關注
關注
40文章
4576瀏覽量
229148 -
人工智能
+關注
關注
1817文章
50098瀏覽量
265395 -
Socionext
+關注
關注
2文章
76瀏覽量
17247
發布評論請先 登錄
邊緣計算中的AI加速器類型與應用

一些神經網絡加速器的設計優化方案
CNN卷積神經網絡設計原理及在MCU200T上仿真測試
NMSIS神經網絡庫使用介紹
SNN加速器內部神經元數據連接方式
CICC2033神經網絡部署相關操作
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+神經形態計算、類腦芯片
神經網絡的并行計算與加速技術
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現深度學習AI芯片的創新方法與架構
Andes晶心科技推出新一代深度學習加速器
Arm神經技術是業界首創在 Arm GPU 上增添專用神經加速器的技術,移動設備上實現PC級別的AI圖形性能
MAX78000采用超低功耗卷積神經網絡加速度計的人工智能微控制器技術手冊
MAX78002帶有低功耗卷積神經網絡加速器的人工智能微控制器技術手冊
NVIDIA實現神經網絡渲染技術的突破性增強功能
嵌入式AI加速器DRP-AI 詳細介紹



 工商網監
工商網監
評論