") 基于NVIDIA AI的3D機(jī)器人感知與地圖構(gòu)建系統(tǒng)設(shè)計(jì)
基于NVIDIA AI的3D機(jī)器人感知與地圖構(gòu)建系統(tǒng)設(shè)計(jì)

機(jī)器人必須感知和理解其 3D 環(huán)境,才能安全高效地行動(dòng)。這一點(diǎn)在非結(jié)構(gòu)化或陌生空間中的自主導(dǎo)航、對(duì)象操作和遠(yuǎn)程操作等任務(wù)尤為重要。當(dāng)前機(jī)器人感知技術(shù)的進(jìn)展,越來越多地體現(xiàn)在通過統(tǒng)一的實(shí)時(shí)工作流與強(qiáng)大的感知模塊,實(shí)現(xiàn) 3D 場景理解、可泛化物體跟蹤與持久性空間記憶的集成。
本期“NVIDIA 機(jī)器人研究與開發(fā)摘要 (R2D2) ”將探討 NVIDIA 研究中心的多個(gè)感知模型和系統(tǒng),這些模型和系統(tǒng)支持統(tǒng)一的機(jī)器人 3D 感知堆棧。它們可在不同的真實(shí)世界環(huán)境中實(shí)現(xiàn)可靠的深度估計(jì)、攝像頭和物體位姿追蹤以及 3D 重建:
FoundationStereo(CVPR 2025 最佳論文提名):用于立體深度估計(jì)的基礎(chǔ)模型,可在各種環(huán)境(包括室內(nèi)、室外、合成和真實(shí)場景)中實(shí)現(xiàn)零樣本性能的泛化。
PyCuVSLAM:用于 cuVSLAM 的 Python Wrapper,支持 Python 用戶利用 NVIDIA 的 CUDA 加速 SLAM 庫,用于實(shí)時(shí)攝像頭位姿估計(jì)和環(huán)境建圖。
BundleSDF:用于 RGB-D 視頻中 6-DoF 物體位姿追蹤和密集 3D 重建的神經(jīng)系統(tǒng)。
FoundationPose:可泛化的 6D 物體位姿估計(jì)器和跟蹤器,適用于僅有最少先驗(yàn)信息的新物體。
nvblox Pytorch Wrapper:nvblox 庫的 Pytorch wrapper,nvblox 是一個(gè) CUDA 加速庫,用于 PyTorch 的深度攝像頭 3D 重建。
3D 空間表示:機(jī)器人感知的核心
這些項(xiàng)目的核心在于強(qiáng)調(diào) 3D 空間表示,即以機(jī)器人可以使用的形式捕獲環(huán)境或物體的結(jié)構(gòu)。FoundationStereo 可處理立體圖像深度估計(jì)的基本任務(wù)。它引入了一個(gè)用于立體深度的基礎(chǔ)模型,專為實(shí)現(xiàn)強(qiáng)零樣本泛化而設(shè)計(jì)。

圖 1. 使用 FoundationStereo 生成的視差圖像
FoundationStereo 已在超過 100 萬對(duì)合成立體圖像上進(jìn)行訓(xùn)練。它無需針對(duì)特定場景進(jìn)行調(diào)整,即可在各種環(huán)境(包括室內(nèi)、室外、合成和真實(shí)場景,如圖 1 所示)中推斷出準(zhǔn)確的視差,從而推理得到 3D 結(jié)構(gòu)。輸出包括表示場景 3D 結(jié)構(gòu)的密集深度圖或點(diǎn)云。
在環(huán)境映射方面,nvblox 和 cuVSLAM 等庫會(huì)隨著時(shí)間的推移構(gòu)建空間表示。NVIDIA 的 nvblox 是一個(gè) GPU 加速的 3D 重建庫,可重建體素網(wǎng)格體素網(wǎng)格,并輸出用于導(dǎo)航的 Euclidean signed distance field (ESDF) 熱圖。這使移動(dòng)機(jī)器人能夠僅使用視覺進(jìn)行 3D 避障,為昂貴的 3D 激光雷達(dá)傳感器提供了一種經(jīng)濟(jì)高效的替代方案。
雖然 nvblox 擅長幾何映射,但缺乏對(duì)環(huán)境的語義理解。借助 nvblox_torch,我們引入了一個(gè) PyTorch Wrapper,它可以將 2D VLM 基礎(chǔ)模型的語義嵌入提升到 3D。
同樣,cuVSLAM 通過 Isaac ROS 為機(jī)器人提供 GPU 加速的視覺慣性 SLAM。cuVSLAM 以前僅限于 ROS 用戶,現(xiàn)在可以通過名為 PyCuVSLAM 的新 Python API 進(jìn)行訪問,這簡化了數(shù)據(jù)工程師和深度學(xué)習(xí)研究人員的集成工作。
深度和地圖構(gòu)建模塊可創(chuàng)建幾何支架(無論是點(diǎn)云、signed distance fields,還是特征網(wǎng)格),并在此基礎(chǔ)上構(gòu)建更高級(jí)別的感知和規(guī)劃。如果沒有可靠的 3D 呈現(xiàn),機(jī)器人就無法準(zhǔn)確感知、記憶或推理世界。
用于場景理解的實(shí)時(shí) SLAM和攝像頭位姿估計(jì)
將這些項(xiàng)目連接在一起的一個(gè)關(guān)鍵方面是通過 SLAM(同步定位與地圖構(gòu)建)實(shí)現(xiàn)實(shí)時(shí)場景理解。cuVSLAM 是一種高效的 CUDA 加速 SLAM 系統(tǒng),用于在機(jī)器人的板載 GPU 上運(yùn)行的立體視覺慣性 SLAM。

圖 2. 使用 cuVSLAM 生成的定位
對(duì)于更偏向使用 Python 的簡單性和通用性的開發(fā)者來說,利用強(qiáng)大而高效的 Visual SLAM 系統(tǒng)仍然是一項(xiàng)艱巨的任務(wù)。借助 PyCuVSLAM,開發(fā)者可以輕松地對(duì) cuVSLAM 進(jìn)行原型設(shè)計(jì)并將其用于應(yīng)用,例如通過互聯(lián)網(wǎng)規(guī)模的視頻生成機(jī)器人訓(xùn)練數(shù)據(jù)集。該 API 可以從第一人稱觀看視頻中估計(jì)自我攝像頭的位姿和軌跡,從而增強(qiáng)端到端決策模型。此外,將 cuVSLAM 集成到 MobilityGen 等訓(xùn)練流程中,可以通過學(xué)習(xí)真實(shí)的 SLAM 系統(tǒng)錯(cuò)誤來創(chuàng)建更穩(wěn)健的模型。功能示例如圖 2 所示。
實(shí)時(shí) 3D 映射

圖 3. 上圖顯示了使用 nvblox_torch 構(gòu)建的重建,左下角展示了將視覺基礎(chǔ)模型特征融合到 3D voxel grid 中的過程,這是表示場景語義內(nèi)容的常用方法。
右下角顯示了從重建中提取的 3D 距離場切片
nvblox_torch 是一個(gè)易于使用的 Python 接口,用于 nvblox CUDA 加速重建庫,允許開發(fā)者輕松地對(duì)用于操作和導(dǎo)航應(yīng)用的 3D 地圖構(gòu)建系統(tǒng)進(jìn)行原型設(shè)計(jì)。
空間記憶是機(jī)器人完成較長距離任務(wù)的核心能力。機(jī)器人通常需要推理場景的幾何和語義內(nèi)容,其中場景的空間范圍通常大于單個(gè)攝像頭圖像所能捕獲的空間范圍。3D 地圖將多個(gè)視圖中的幾何和語義信息聚合為場景的統(tǒng)一表示。利用 3D 地圖的這些特性可以提供空間記憶,并支持機(jī)器人學(xué)習(xí)中的空間推理。
nvblox_torch 是一個(gè) CUDA 加速的 PyTorch 工具箱,用于使用 RGB-D 攝像頭進(jìn)行機(jī)器人映射。該系統(tǒng)允許用戶在 NVIDIA GPU 上將環(huán)境觀察結(jié)果與場景的 3D 呈現(xiàn)相結(jié)合。然后,可以查詢此 3D 表示形式的數(shù)量,例如障礙物距離、表面網(wǎng)格和占用概率(請(qǐng)見圖 3)。nvblox_torch 使用來自 PyTorch 張量的零復(fù)制輸入/ 輸出接口來提供超快性能。
此外,nvblox_torch 還添加了深度特征融合這一新功能。此功能允許用戶將視覺基礎(chǔ)模型中的圖像特征融合到 3D 重建中。隨后,生成的重建將同時(shí)表示場景的幾何圖形和語義內(nèi)容。3D 基礎(chǔ)模型特征正在成為基于語義的導(dǎo)航和語言引導(dǎo)操作的熱門表示方法。nvblox_torch 庫中現(xiàn)已提供此表示方法。
6-DoF 物體位姿追蹤和新物體的 3D 重建
以物體為中心的感知也同樣重要:了解場景中的物體是什么、它們?cè)谀睦镆约八鼈內(nèi)绾我苿?dòng)。FoundationPose 和 BundleSDF 這兩個(gè)項(xiàng)目解決了 6-DoF 物體位姿估計(jì)和追蹤的挑戰(zhàn),其中也包括機(jī)器人以前從未見過的物體。
FoundationPose 是一種基于學(xué)習(xí)的方法:它是用于 6D 物體位姿估計(jì)和跟蹤的統(tǒng)一基礎(chǔ)模型,適用于基于模型和無模型的場景。這意味著同一系統(tǒng)可以處理已知對(duì)象(如果有可用的 CAD 模型)或全新對(duì)象(僅使用少量參考圖像),而無需重新訓(xùn)練。FoundationPose 通過利用神經(jīng)隱式表示來合成物體的新視圖來實(shí)現(xiàn)這一點(diǎn),有效地彌合了完整 3D 模型與僅有稀疏觀察之間的差距。
它在大規(guī)模合成數(shù)據(jù)上進(jìn)行訓(xùn)練(借助基于 LLM 的數(shù)據(jù)生成工作流等技術(shù)),具有強(qiáng)大的泛化能力。事實(shí)上,只要提供最少的信息,比如模型或圖像,就可以在測試時(shí)即時(shí)應(yīng)用于新對(duì)象。這種基礎(chǔ)模型方法在位姿基準(zhǔn)測試中實(shí)現(xiàn)了最出色的準(zhǔn)確性,在保持對(duì)新物體的零樣本能力的同時(shí),性能優(yōu)于專門方法。

圖 4. FoundationPose 在機(jī)器人機(jī)械臂中的應(yīng)用
BundleSDF 采用在線優(yōu)化驅(qū)動(dòng)的方法來解決此問題,提供了一種近實(shí)時(shí) (~ 10 Hz) 方法,用于從 RGB-D 視頻中同時(shí)進(jìn)行 6-DoF 位姿追蹤和神經(jīng) 3D 重建。它僅假設(shè)第一幀中的分割;之后不需要先驗(yàn) CAD 模型或類別知識(shí)。
BundleSDF 的關(guān)鍵是并發(fā)學(xué)習(xí)的 Neural Object Field,一種神經(jīng)隱式 SDF,可在觀察時(shí)捕獲物體的幾何圖形和外觀。當(dāng)物體移動(dòng)時(shí),BundleSDF 會(huì)使用過去的幀不斷優(yōu)化位姿圖,隨著時(shí)間的推移優(yōu)化位姿軌跡和形狀估計(jì)。位姿估計(jì)與形狀學(xué)習(xí)的集成可有效解決大型位姿變化、遮擋、低紋理表面和鏡面反射等挑戰(zhàn)。在交互結(jié)束時(shí),機(jī)器人可以擁有一致的 3D 模型并追蹤動(dòng)態(tài)獲取的位姿序列。
該框架概述如圖 5 所示。首先,在連續(xù)圖像之間匹配特征以獲得粗略的位姿估計(jì) (Sec. 3.1),一些位姿幀存儲(chǔ)在內(nèi)存池中一遍后續(xù)進(jìn)行優(yōu)化 (Sec. 3.2),根據(jù)池中的一個(gè)子集動(dòng)態(tài)創(chuàng)建位姿圖 (Sec. 3.3),在線優(yōu)化會(huì)細(xì)化圖中的所有位姿以及當(dāng)前位姿,更新的位姿存儲(chǔ)回池中。最后,池中的所有位姿幀在單獨(dú)的線程中,學(xué)習(xí) Neural Object Field,用于對(duì)幾何和視覺紋理進(jìn)行建模 (Sec. 3.4),同時(shí)調(diào)整之前估計(jì)的位姿。
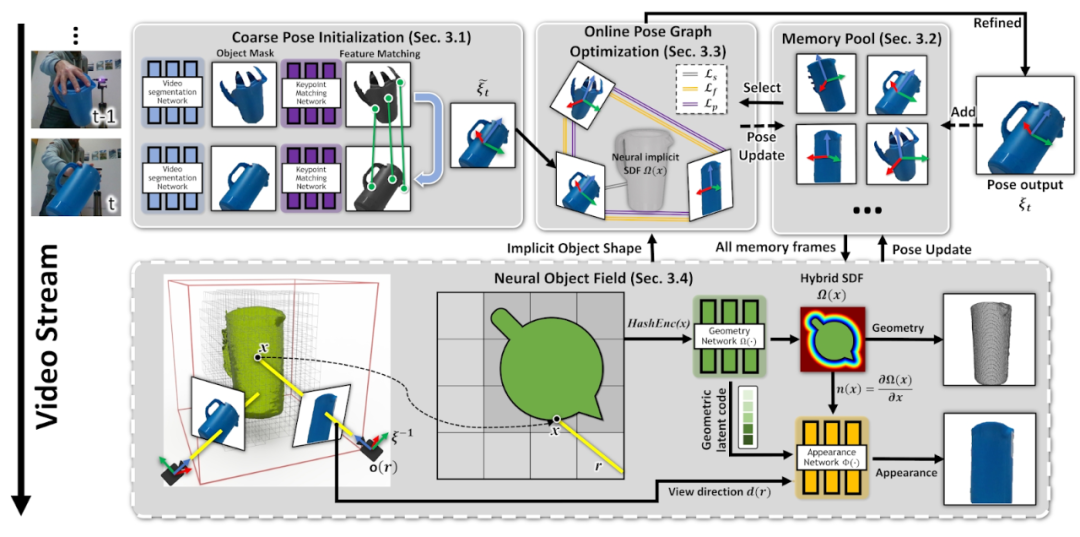
圖 5. BundleSDF 框架,該框架使用內(nèi)存增強(qiáng)的位姿圖來估計(jì)和優(yōu)化視頻流中的 3D 物體位姿,
并學(xué)習(xí)幾何圖形和外觀的神經(jīng)物體表示
FoundationPose 和 BundleSDF 都強(qiáng)調(diào)了對(duì)象級(jí) 3D 理解在機(jī)器人開發(fā)中的重要性。機(jī)器人如果需要抓取或操控任意物體,必須能夠感知物體的 3D 位置和方向(位姿),通常還需要感知其形狀。這些項(xiàng)目展示了兩條互補(bǔ)的路徑:預(yù)訓(xùn)練的基礎(chǔ)模型,通過學(xué)習(xí)廣泛的先驗(yàn)來泛化到新對(duì)象;以及用于構(gòu)建自定義模型的對(duì)象的在線 neural SLAM 。在實(shí)踐中,這些功能甚至可以協(xié)同工作,例如,基礎(chǔ)模型可以提供初步猜測,然后通過在線重建進(jìn)行改進(jìn)。機(jī)器人正在朝著新物體的實(shí)時(shí) 6D 感知發(fā)展,而不是局限于識(shí)別一組固定的已知物體。
基礎(chǔ)模型:跨任務(wù)的泛化和統(tǒng)一
更多的機(jī)器人感知系統(tǒng)利用基礎(chǔ)模型,即只需極少調(diào)整即可跨任務(wù)泛化的大型神經(jīng)網(wǎng)絡(luò)。這在 FoundationStereo 和 FoundationPose 中很明顯,它們分別為立體深度估計(jì)和 6D 物體位姿追蹤提供了強(qiáng)有力的基準(zhǔn)。
FoundationStereo 將之前于 DepthAnythingV2 的側(cè)調(diào)整單目深度整合到立體模型框架中,無需重新訓(xùn)練即可增強(qiáng)魯棒性和域泛化。它在各種環(huán)境中使用超過 100 萬個(gè)合成立體對(duì)進(jìn)行訓(xùn)練,在 Middlebury、KITTI 和 ETH3D 數(shù)據(jù)集等基準(zhǔn)測試中實(shí)現(xiàn)了先進(jìn)的零樣本性能。該模型改進(jìn)了成本體積編碼器和解碼器,增強(qiáng)了遠(yuǎn)程差異估計(jì)。
在圖 6 中,Side-Tuning Adapter (STA) 利用來自凍結(jié)的 DepthAnythingV2 的豐富單目先驗(yàn),以及來自多級(jí) CNN 的詳細(xì)高頻特征來提取一元特征。Attentive Hybrid Cost Filtering (AHCF) 將 Axial-Planar Convolution (APC) 過濾與 Disparity Transformer (DT) 模塊相結(jié)合,在 4D 混合成本體積中有效聚合跨空間和差異維度的特征。根據(jù)此過濾后的成本量預(yù)測初始差異,并使用 GRU 塊進(jìn)行細(xì)化。每個(gè)優(yōu)化階段都會(huì)使用更新后的差異從過濾后的混合成本體積和相關(guān)體積中查找特征,從而指導(dǎo)下一個(gè)優(yōu)化步驟,并產(chǎn)生最終的輸出差異。
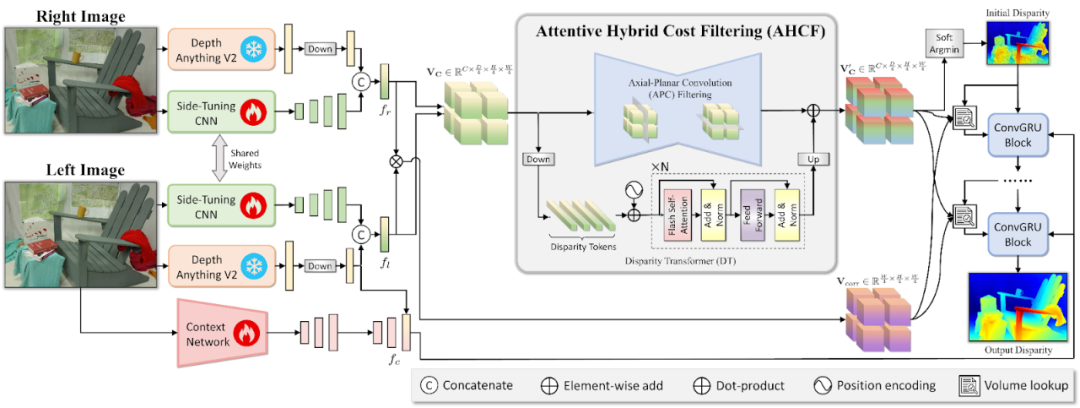
圖 6. 通過 AHCF 從輸入圖像到輸出差異的 FoundationStereo 流
FoundationPose 是一個(gè)統(tǒng)一模型,用于對(duì)新物體進(jìn)行單幀 6D 位姿估計(jì)和多幀位姿追蹤。它通過學(xué)習(xí)物體幾何圖形的神經(jīng)隱式表示,支持基于模型和基于圖像的推理。它使用 CAD 模型或一些 RGB 引用泛化到不可見的對(duì)象。它基于大語言模型生成的大型合成數(shù)據(jù)集進(jìn)行訓(xùn)練,包括各種任務(wù)提示和場景變體。
FoundationPose 利用對(duì)比訓(xùn)練和基于 Transformer 的編碼器,在 YCB-Video、T-LESS 和 LM-OCC 等基準(zhǔn)測試中的表現(xiàn)明顯優(yōu)于 CosyPose 和 StablePose 等特定任務(wù)基準(zhǔn)。圖 7 展示了 FoundationPose 的工作原理。為了減少大規(guī)模訓(xùn)練的人工工作量,我們使用新興技術(shù)和資源(包括 3D 模型數(shù)據(jù)庫、LLMs 和 diffusion models)創(chuàng)建了合成數(shù)據(jù)生成工作流 (Sec. 3.1)。為了將無模型設(shè)置和基于模型的設(shè)置連接起來,我們使用 object-centric neural field (Sec. 3.2),用于新穎的視圖 RGB-D 渲染和渲染與比較。對(duì)于位姿估計(jì),我們會(huì)在物體周圍均勻地初始化全局位姿,并通過 refinement network 進(jìn)行優(yōu)化 (Sec. 3.3)。最后,我們將優(yōu)化后的位姿發(fā)送到位姿選擇模塊,以預(yù)測其分?jǐn)?shù),并選擇具有最佳分?jǐn)?shù)的姿勢作為輸出 (Sec. 3.4)。
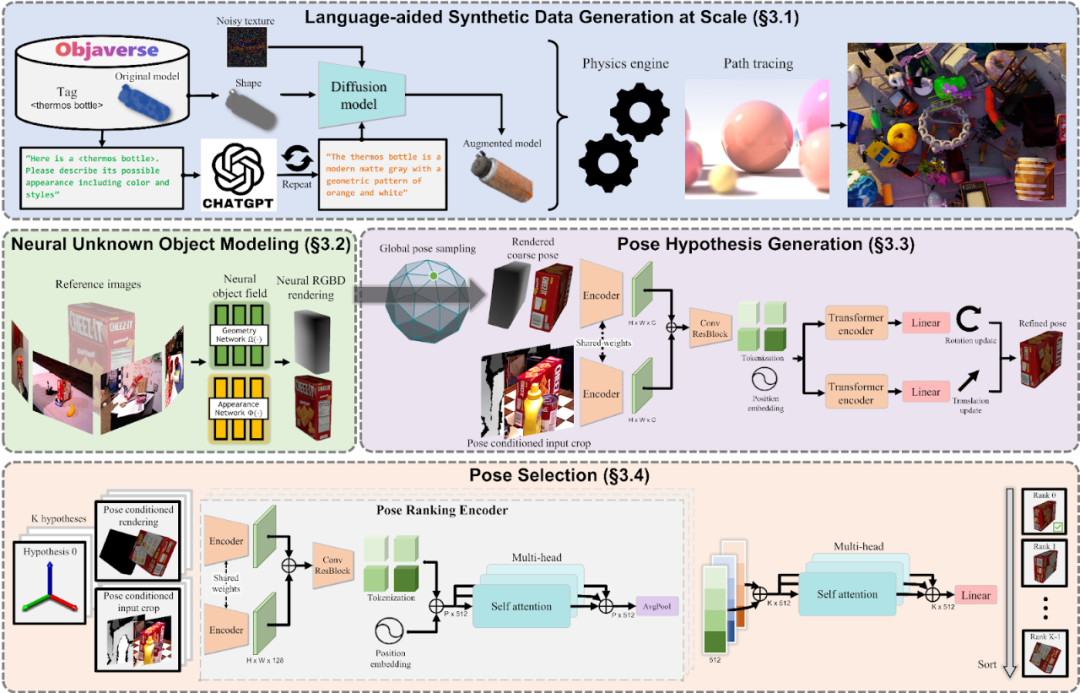
圖 7. 該工作流通過結(jié)合神經(jīng)渲染、細(xì)化和位姿假設(shè)排序來生成合成訓(xùn)練數(shù)據(jù)并估計(jì)物體位姿
這些模型共同標(biāo)志著機(jī)器人技術(shù)在構(gòu)建統(tǒng)一可復(fù)用感知主干的道路上邁出了關(guān)鍵一步。通過將深度和物體幾何的通用先驗(yàn)知識(shí)嵌入實(shí)時(shí)系統(tǒng),機(jī)器人能夠在零樣本場景中(包括訓(xùn)練未涉及的環(huán)境中以及從未見過的物體交互場景)實(shí)現(xiàn)可靠性能,隨著機(jī)器人技術(shù)朝著更具適應(yīng)性的開放世界部署發(fā)展,基礎(chǔ)模型提供了在通用感知框架內(nèi)支持廣泛任務(wù)所需的靈活性和可擴(kuò)展性。
邁向集成式 3D 感知堆棧
這些項(xiàng)目共同指向一個(gè)統(tǒng)一的 3D 感知堆棧,其中深度估計(jì)、SLAM、物體追蹤和重建作為緊密集成的組件運(yùn)行。FoundationStereo 可提供可靠的深度,cuVSLAM 可跟蹤攝像頭位姿以進(jìn)行實(shí)時(shí)定位和映射,而 BundleSDF 和 FoundationPose 可處理物體級(jí)理解,包括 6-DoF 追蹤和形狀估計(jì),即使是未見過的物體也不例外。
通過基于 foundation models 和神經(jīng) 3D 表征構(gòu)建,這些系統(tǒng)實(shí)現(xiàn)了通用的實(shí)時(shí)感知,支持在復(fù)雜環(huán)境中進(jìn)行導(dǎo)航、操作和交互。機(jī)器人技術(shù)的未來在于這種集成堆棧,其中感知模塊共享表示和上下文,使機(jī)器人能夠以空間和語義意識(shí)進(jìn)行感知、記憶和行動(dòng)。
總結(jié)
本期 R2D2 探討了立體深度估計(jì)、SLAM、物體位姿跟蹤和 3D 重建等領(lǐng)域的最新進(jìn)展,以及如何融合到統(tǒng)一的機(jī)器人 3D 感知堆棧中。這些工具大多由基礎(chǔ)模型驅(qū)動(dòng),使機(jī)器人能夠?qū)崟r(shí)理解環(huán)境并與之交互,即使面對(duì)新物體或陌生場景也能應(yīng)對(duì)自如。
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
31263瀏覽量
223170 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5674瀏覽量
110015 -
AI
+關(guān)注
關(guān)注
91文章
40578瀏覽量
302170 -
模型
+關(guān)注
關(guān)注
1文章
3789瀏覽量
52208
原文標(biāo)題:R2D2:利用 NVIDIA 研究中心的研究成果,構(gòu)建 AI 驅(qū)動(dòng)的 3D 機(jī)器人感知與地圖構(gòu)建系統(tǒng)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于3D視覺技術(shù)的機(jī)器人系統(tǒng)
《電子發(fā)燒友電子設(shè)計(jì)周報(bào)》聚焦硬科技領(lǐng)域核心價(jià)值 第20期:2025.07.14--2025.07.18
《電子發(fā)燒友電子設(shè)計(jì)周報(bào)》聚焦硬科技領(lǐng)域核心價(jià)值 第21期:2025.07.21--2025.07.25
走到哪都不會(huì)迷路,全自動(dòng)機(jī)器人是怎么導(dǎo)航的?
Voxel 3D 飛行時(shí)間傳感器機(jī)器人視覺參考設(shè)計(jì)
怎么構(gòu)建一張滿足機(jī)器人導(dǎo)航需求的地圖?
未來的機(jī)器人3D視覺系統(tǒng)將會(huì)發(fā)生什么樣的變化?
全球3D芯片及模組引領(lǐng)者,強(qiáng)勢登陸中國市場
基于Arduino的3D打印2輪機(jī)器人
INDEMIND 3D語義地圖構(gòu)建技術(shù)在機(jī)器人上的應(yīng)用
機(jī)器人如何構(gòu)建3D語義地圖?
NVIDIA Isaac 平臺(tái)先進(jìn)的仿真和感知工具助力 AI 機(jī)器人技術(shù)加速發(fā)展
利用NVIDIA Isaac平臺(tái)構(gòu)建、設(shè)計(jì)并部署機(jī)器人應(yīng)用




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論