 BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解
BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解

BEVFusion 技術詳解總結
原始論文:*附件:bevfusion.pdf
介紹(Introduction)
背景:自動駕駛系統配備了多種傳感器,提供互補的信號。但是不同傳感器的數據表現形式不同。
自動駕駛系統配備了多樣的傳感器。 例如,Waymo的自動駕駛車輛有29個攝像頭、6個雷達和5個激光雷達。 **不同的傳感器提供互補的信號:**例如,攝像機捕捉豐富的語義信息,激光雷達提供精確的空間信息,而雷達提供即時的速度估計。 因此,多傳感器融合對于準確可靠的感知具有重要意義。**來自不同傳感器的數據以根本不同的方式表示:**例如,攝像機在透視圖中捕獲數據,激光雷達在3D視圖中捕獲數據。

1. 核心目標與創新?
- 目標? 解決多模態傳感器(攝像頭、激光雷達等)在3D感知任務中的異構數據融合難題,實現高效、通用的多任務學習(如3D檢測、BEV分割)
- 核心創新?
- ?統一BEV表示 將多模態特征映射到共享的鳥瞰圖(BEV)空間,保留幾何結構(激光雷達優勢)和語義密度(攝像頭優勢)
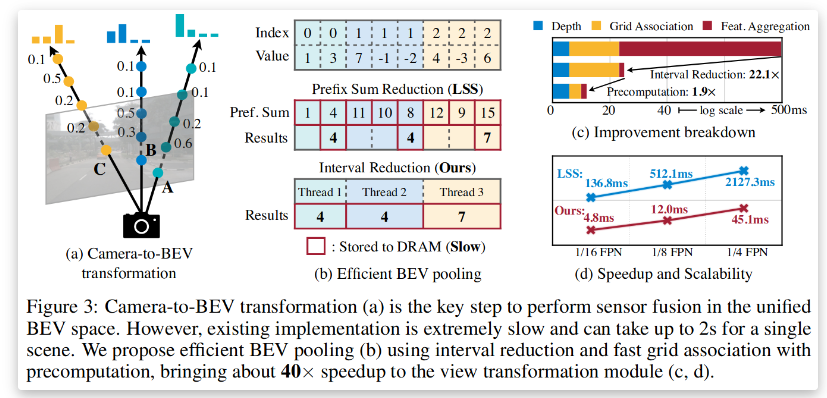
- ?優化BEV池化 通過預計算和間隔縮減技術,將BEV池化速度提升40%以上
- ?全卷積融合 解決激光雷達與攝像頭BEV特征的空間錯位問題,提升融合魯棒性
2. 技術框架與關鍵模塊?
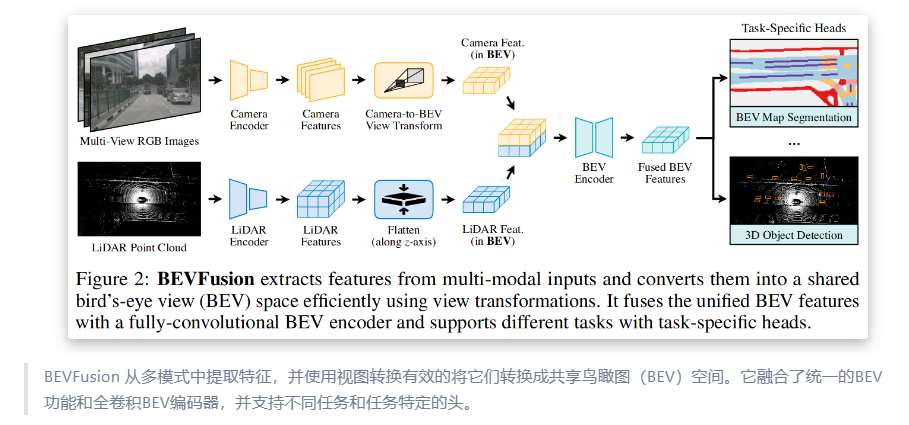
?2.1 多模態特征提取
- ?傳感器輸入
- ?攝像頭 多視角圖像(透視視圖)
- ?激光雷達 點云數據(3D視圖)
- ?模態專用編碼器
- ?攝像頭 2D卷積神經網絡(如ResNet)提取圖像特征
- ?激光雷達 3D稀疏卷積網絡(如VoxelNet)提取點云特征
?2.2 統一BEV表示構建
- ?攝像頭到BEV的轉換
- ?深度分布預測 顯式預測每個像素的離散深度分布(避免幾何失真)
- ?特征投影 沿相機射線將像素特征分散到離散3D點,通過BEV池化聚合特征(見圖1)
- ?優化加速 預計算相機內外參矩陣,減少實時計算開銷
- ?激光雷達到BEV的轉換 直接通過體素化將點云映射到BEV網格
?2.3 全卷積特征融合
- ?融合策略
- ?通道級聯 將攝像頭和激光雷達的BEV特征拼接,輸入全卷積網絡(FCN)
- ?空間對齊補償 通過可變形卷積或注意力機制緩解特征錯位問題
?2.4 多任務頭設計
- ?3D物體檢測 基于融合后的BEV特征,采用Anchor-free或CenterPoint范式預測邊界框
- ?BEV地圖分割 全卷積解碼器輸出語義分割結果(如車道線、可行駛區域)
?3. 性能優勢與實驗驗證
? 3.1 基準測試結果(NuScenes數據集)
| ?任務 | ?模型類型 | ?性能指標 | ?BEVFusion優勢 |
|---|---|---|---|
| 3D物體檢測 | 純攝像頭模型 | mAP: 35.1% | ?mAP: 68.5%(+33.4%) |
| 3D物體檢測 | 純激光雷達模型 | mAP: 65.2% | ?mAP: 68.5%(+3.3%) |
| BEV地圖分割 | 純攝像頭模型 | mIoU: 44.7% | ?mIoU: 50.7%(+6.0%) |
| BEV地圖分割 | 純激光雷達模型 | mIoU: 37.1% | ?mIoU: 50.7%(+13.6%) |
?3.2 效率對比
- ?計算成本 BEVFusion的計算量僅為同類多模態模型的50%(1.9倍低于純激光雷達模型)
- ?推理速度 優化后的BEV池化使端到端延遲降低40%
?4. 與傳統方法的對比分析
?4.1 早期融合 vs. 晚期融合
| ?方法 | ?優勢 | ?劣勢 |
|---|---|---|
| 早期融合(特征級) | 保留原始數據信息 | 異構特征難以對齊(如幾何失真) |
| 晚期融合(決策級) | 模態獨立性高 | 語義信息丟失,任務性能受限 |
| ?BEVFusion | ?統一BEV空間平衡幾何與語義 | 需優化特征對齊與計算效率 |
?4.2 其他多模態模型對比
- ?PointPainting 將攝像頭語義注入點云,但依賴激光雷達主導,無法充分發揮攝像頭優勢
- ?TransFusion 基于Transformer的融合,計算復雜度高,實時性差
?5. 局限性與未來方向
- ?局限性
- ?動態場景適應性 BEV靜態假設可能影響運動物體感知
- ?傳感器依賴性 仍需激光雷達提供幾何先驗
- ?未來方向
- ?純視覺BEV泛化 探索無激光雷達的BEV感知(如4D標注數據增強)
- ?時序融合 引入多幀BEV特征提升動態場景理解
?總結
BEVFusion通過統一的BEV表示空間和高效融合機制,解決了多模態傳感器在幾何與語義任務中的權衡問題,成為自動駕駛多任務感知的標桿框架其設計范式為后續研究提供了重要啟發 ?**“統一表示+輕量優化”是多模態融合的核心方向**
項目鏈接
- 官方網頁:https://hanlab.mit.edu/projects/bevfusion
- 原始論文:https://arxiv.org/abs/2205.13542
- 項目地址:https://github.com/mit-han-lab/bevfusion
參考資料
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
自動駕駛
+關注
關注
793文章
14846瀏覽量
179122
發布評論請先 登錄
相關推薦
熱點推薦
如何設計自動駕駛傳感器失效檢測與容錯策略?
對于自動駕駛汽車而言,傳感器是它感知世界的窗口。攝像頭負責采集環境圖像,毫米波雷達和激光雷達則用于測量周圍物體的位置和速度,而GNSS(全球導航衛星系統)與慣性測量系統可提供車輛的定位信息。這些數據經過融合處理之后,
自動駕駛BEV Camera數據采集:時間同步技術解析與康謀解決方案
一、自動駕駛傳感器融合中的時間同步重要性 在自動駕駛感知體系中,BEV(Bird's-Eye-View,鳥瞰圖)感知技術憑借尺度變化小、視角

激光雷達傳感器在自動駕駛中的作用
2024 年至 2030 年間,高度自動化汽車每年的出貨量將以 41% 的復合年增長率增長。這種快速增長導致汽車品牌對精確可靠傳感器技術的需求空前高漲,因為他們希望提供精準、可靠且最終完全自動
自動駕駛仿真測試有什么具體要求?
、動力響應和操控穩定性,自動駕駛系統的復雜性主要體現在感知、決策與控制等軟件層面,其運行行為高度依賴于交通環境、傳感器輸入和系統邏輯。這也就意味著,傳統的物理測試方法已經難以全面覆蓋自動駕駛系統所面臨的所有

邊聊安全 | 以L3級自動駕駛為例,詳解DDT、DDT Fallback、MRC、MRM概念
以L3級自動駕駛為例,詳解DDT、DDTFallback、MRC、MRM概念寫在前面:在自動駕駛技術迅猛發展的今天,動態駕駛

康謀分享 | 基于多傳感器數據的自動駕駛仿真確定性驗證
自動駕駛仿真測試中,游戲引擎的底層架構可能會帶來非確定性的問題,侵蝕測試可信度。如何通過專業仿真平臺,在多傳感器配置與極端天氣場景中實現測試數據零差異?確定性驗證方案已成為自動駕駛研發

自動駕駛汽車是如何準確定位的?
厘米級的定位精度,并能夠實時響應環境變化。為此,自動駕駛系統通常采用多傳感器融合的方式,將全球導航衛星系統(GNSS)、慣性測量單元(IMU)、激光雷達(LiDAR)、攝像頭、超寬帶(
自動駕駛技術落地前為什么要先測試?
大量的傳感器、復雜的算法和強大的計算平臺來取代人類駕駛員的感知、判斷和操作。在技術落地之前,“測試”便成了自動駕駛從實驗室走向真實道路的“安全閥”和“試金石”。如果沒有充分的測試,無論
Vicor高效電源模塊優化自動駕駛系統
低壓(48V)自動駕駛電動穿梭車配備了先進的自動駕駛系統,能夠在復雜的城市道路上自動行駛。GPU 和傳感器是自動駕駛系統的關鍵組件,依賴高性
新能源車軟件單元測試深度解析:自動駕駛系統視角
、道路塌陷)的測試用例庫,通過虛擬仿真和真實路測數據回灌驗證算法的魯棒性。
?第二部分:自動駕駛軟件單元測試技術體系****?
?測試對象分類與測試策略?
? 數據驅動型模塊(如傳感器融合
發表于 05-12 15:59
AI將如何改變自動駕駛?
自動駕駛帶來哪些變化?其實AI可以改變自動駕駛技術的各個環節,從感知能力的提升到決策框架的優化,從安全性能的增強到測試驗證的加速,AI可以讓自動駕駛
自動駕駛大模型中常提的Token是個啥?對自動駕駛有何影響?
、多模態傳感器數據的實時處理與決策。在這一過程中,大模型以其強大的特征提取、信息融合和預測能力為自動駕駛系統提供了有力支持。而在大模型的中,有一個“Token”的概念,有些人看到后或許
技術分享 |多模態自動駕駛混合渲染HRMAD:將NeRF和3DGS進行感知驗證和端到端AD測試
多模態自動駕駛混合渲染HRMAD,融合NeRF與3DGS技術,實現超10萬㎡場景重建,多傳感器實

激光雷達技術:自動駕駛的應用與發展趨勢
隨著近些年科技不斷地創新,自動駕駛技術正逐漸從概念走向現實,成為汽車行業的重要發展方向。在眾多傳感器技術中,激光雷達(LiDAR)因其獨特的優勢,被認為是實現高級




 工商網監
工商網監
評論