 談談DeepSeek-v3提到的基礎設施演進
談談DeepSeek-v3提到的基礎設施演進

看DeepSeek-v3的感受是, 算法和Infra的非常緊密結合. 其實很多大模型團隊的算法和Infra是非常割裂的, 完全同時懂算法和Infra的人并不多, DeepSeek這個團隊就是其中之一, DeepSeek團隊中應該有不少OI競賽獲獎選手, 其實對于我們這些搞過OI的人, 對于計算上的優化策略基本上都是手到擒來,很多時候把處理器的體系結構也研究的很深, 所以同時做算法和Infra是非常自然的一件事情, 而如今很多算法崗的新人大多數人的代碼能力是非常有限的....
當然渣B稍微再得瑟一下, 比DeepSeek他們還更懂更底層的芯片以及它們的互聯, Maybe再多懂一點數學... 昨天還跟一朋友講了一個冷玩笑, FP8訓練這些Quantization不就是Quant變渣("za"tion)么,^o^.
1. 算力不再應當只是約束,而是一個可以聯合優化的變量
其實很多年前, 阿里媽媽團隊就在推薦系統引入深度學習時做過大量的算法和算力Infra協同的工作, 非常認同周國睿老師的一句話:“算力不再應當只是約束,而是一個可以聯合優化的變量”
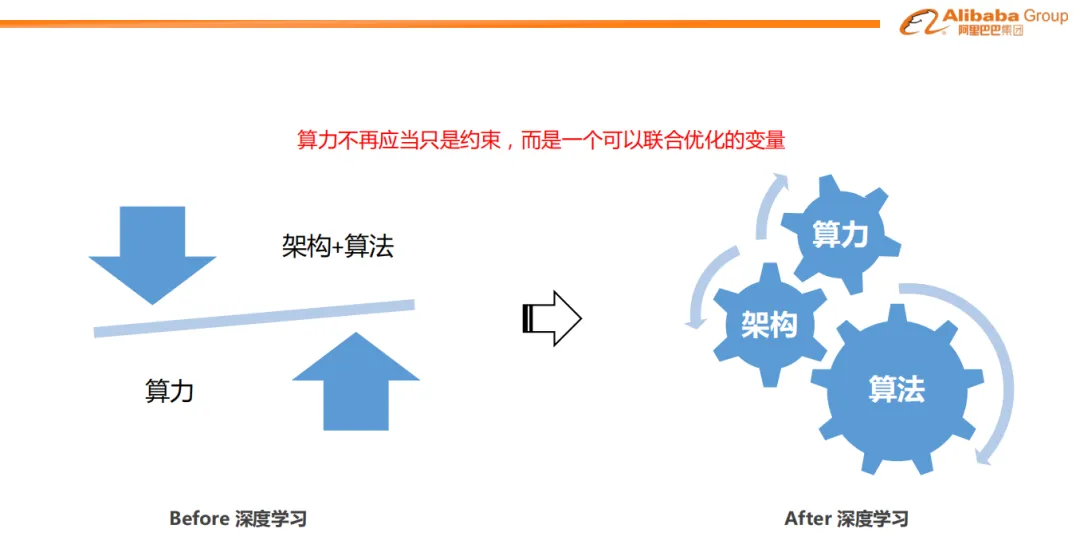
今年年初還把這一系列的算法和算力的協同發展整理了一下, 可以參考
《談談AI落地容易的業務-搜廣推》
其實再來說說量化交易這一塊, 它和搜廣推很類似的也是需要在一個時間約束下做到算力和算法的平衡, 對于很多高頻交易策略其實就更難了, 涉及到一系列硬件上和算法算力的協同了, 有些時候還可以犧牲穩定性為代價, 舉個例子有些高頻交易的團隊還在用家用CPU超頻的方式來獲得更快的運算速度, 另一個例子在很多網卡上連一個寄存器都要省....
對于DeepSeek/幻方有了這樣的主營業務做大模型時,整個團隊的火力自然是滿滿的...當然渣B這樣的參與了國內幾乎所有交易所的交易網絡設計有合規問題和自身的職業操守就沒有去趟高頻這塊...
另一方面渣B對現在的大模型Transformer架構還是有更多的不認同, 它一定不是通往AGI的終態, 因為這樣的依賴極大算力的ScalingLaw的算法本質上應該是一個錯誤, 所以渣B更多的時間是在底層優化算力和頂層算法背后的數學原理上花了更多的精力.
在底層算力方面, 主要是GPU微架構的分析和Tensor運算相關的工作以及AI加速器高速互聯等
《GPU架構演化史》
《Tensor運算》
《AI加速器互聯》
在數學方面(嗯,學習J神“數學方面”), 渣B一直有一個暴論:這一次人工智能革命的數學基礎是:范疇論/代數拓撲/代數幾何這些二十世紀的數學第一登上商用計算的舞臺。, 因此一直也在做一些專題的研究
《大模型的數學基礎》
最近看到一些論文, 例如TOPOS的視角來看待多模態大模型, 還有一些Grothendieck圖神經網絡一類的東西, 似乎看到一些光了,但是這些東西是這個世界上為數不多英雄主義的存在, 一張紙一支筆的浪漫.
當然很多人懷疑這些代數上的東西以及GNN本身的一些稀疏計算的效率問題似乎跟AGI毫無關系. 但事實上它們可能是人腦里最精彩的存在. 昨天也到MTP時有一個觀點:
MTP讓我想到了Zen5的2-Ahead Branch Predictor 非常有趣的工作, 其實對于o3這樣的模型, 本質上是token as an intruction.
原來GPT是一個順序執行結果predic next token 類似于 pc++, 然后在棧上(historical tokens as stack)操作. 順序預測下一個token
o1/o3 Large Reasoning Model 無論是MoE或者是強化學習一類的PRM, 實質上是在Token Predict上做了Divergence, 例如跳轉/循環/回溯 等, PRM可以看作是一個CPU分支預測器. 從體系架構上漸漸的可以讓大模型做到類似于圖靈完備的處理能力.
基于這個觀點, 那么當前的GPU的TensorCore/Cuda Core實際上就構成了一個執行引擎, 外面還需要一系列控制, 分支預測, 譯碼器, LSU來配合, 對于基礎設施帶來的演進還是有很多有趣的話題可以去探索的
另外一個暴論:當前的Transformer模型本身作為一種生成Token的數據路徑, 而Grothendieck圖神經網絡一類的東西和相關的代數結構本身作為模型的控制路徑, 這是跑通LRM的一條路
2. 硬件和體系架構的演進
DeepSeek-v3的實現也非常優雅, 例如考慮H800被閹割的影響, 訓練沒有采用TP并行. 然后針對MoE的AlltoAll做了極致的優化, 例如PXN和IBGDA等, 還有warp specialization以及dualpipe等.
相反我們看看Meta那群人, AlltoAll去年的OCP還在叫喚著Call for Action, 然后Llama3的MoE聽李沐講了一個八卦他們訓練失敗了...也難怪要多花10倍的錢...
回到DS團隊提到的一些未來硬件的需求, 例如當前H800的132個SM中被分配了20個SM用于通信, 需要通信協處理器,以及為了減少應用程序編程的復雜性,希望這種硬件能夠從計算單元的角度統一ScaleOut和ScaleUp網絡。通過這種統一接口, 計算單元可以通過提交基于簡單原語的通信請求.
其實這些東西渣B幾年前就全部講清楚并做了一系列POC. 在2018年的時候, 看到Transformer出來以及模型開始越來越大通信成為瓶頸時, 渣B當時在Cisco就在做AI Infra相關的預研, 第一個把深度學習模型引入到Cisco路由器中做一系列Performance Assurance和Security Assurance相關的業務.
然后2020年的時候和第四范式的一些研討后, 然后設計和實現了NetDAM. 到如今你會發現Tesla TTPoE也是在做同樣的事情.
《NetDAM專題》
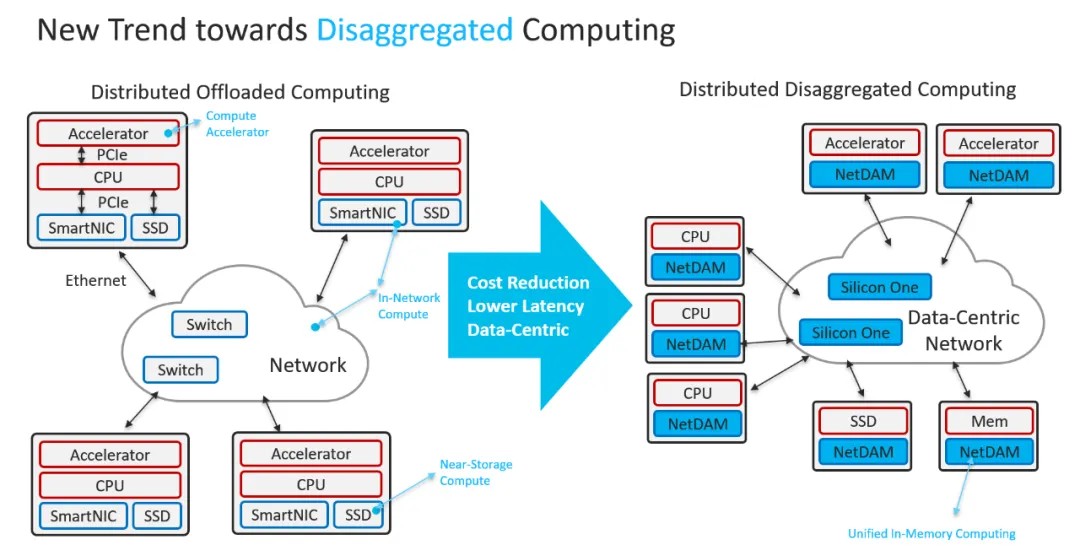
時至今日, 你會發現DeepSeek對未來硬件的演進, 都在這一套框架內完全實現.
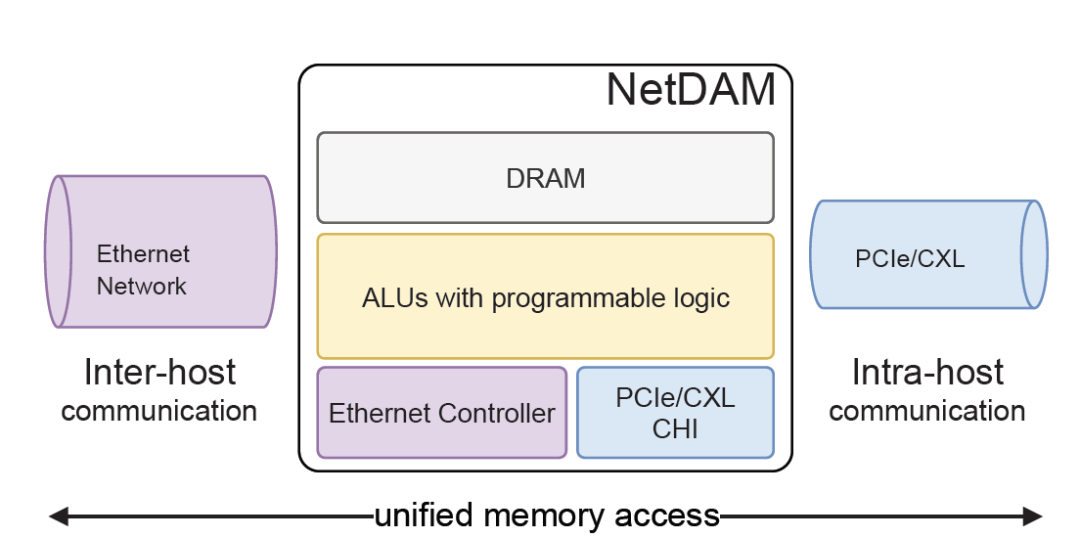
首先, 它對GPU側是一個標準的內存接口, 通過在NetDAM上的一片內存, 基于內存語義把ScaleOut(Inter-Host)和ScaleUP(Intra-host)的通信完全融合了. 然后DS提到的Read/Write/multicast/reduce這些也是NetDAM一開始就做的功能, 例如RoCE需要多次訪問GPU內存并引入CPU控制流
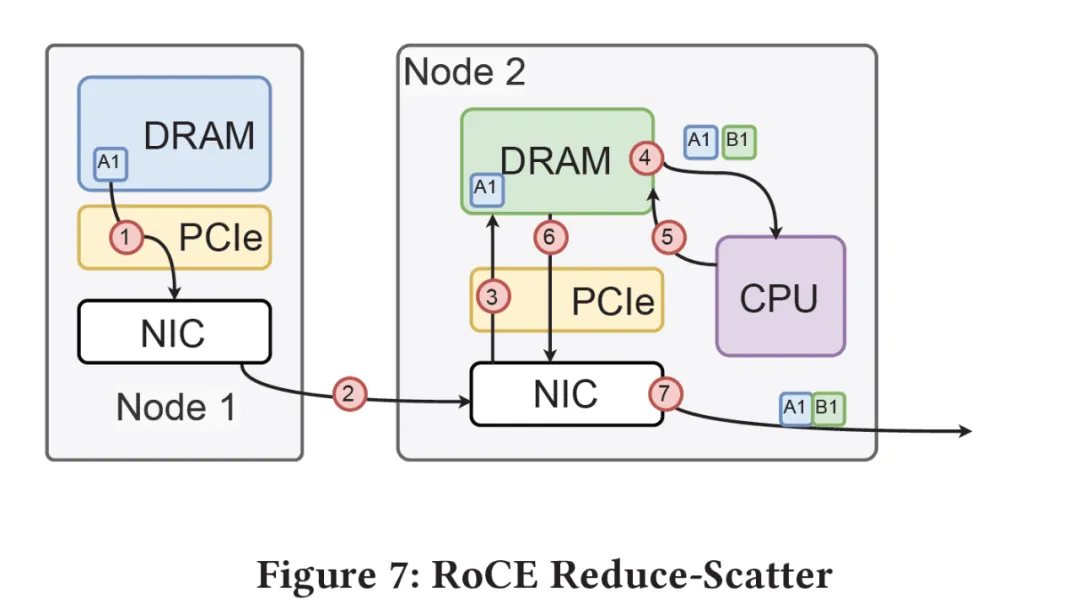
而NetDAM直接進行了卸載:
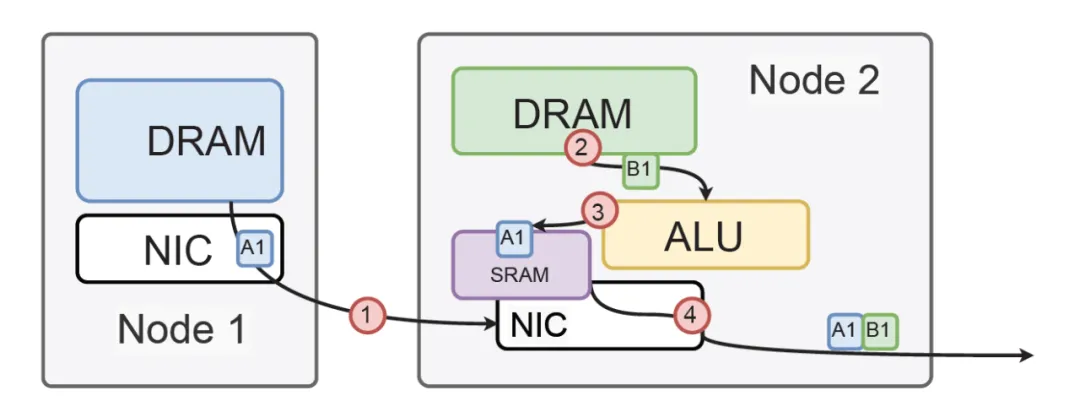
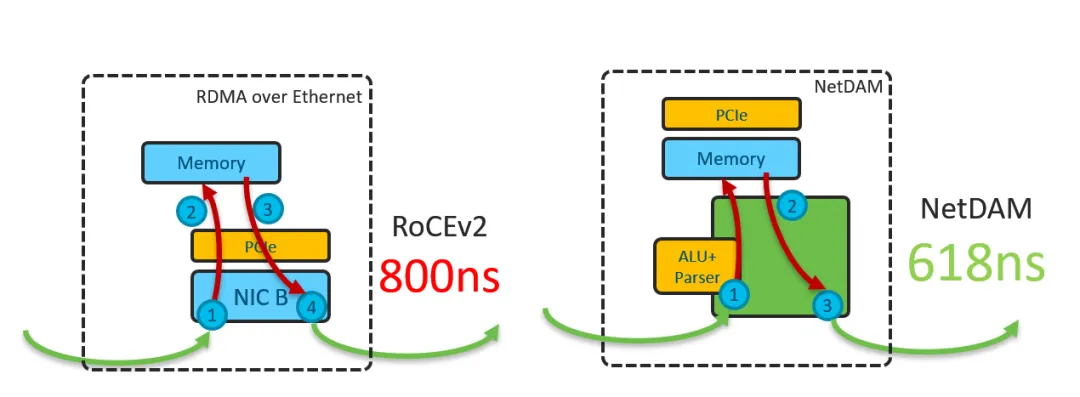
而對于DS后面提到的一系列量化和Scale相關的近內存計算, 本質上在NetDAM上是最好的附著點. 例如很多人說Mellanox延遲低, NetDAM直接bypass PCIe延遲輕松秒殺
但是這個世界并不是完美的, 因為人總歸是有屁股的. 例如思科當時的重心全部放在了Silicon One上, Intel守著自己的UPI在CXL上扣扣搜搜的, 而同樣Nvidia在B200這一代雖然把IB和NVSwitch融合在一起做交換芯片, 但最終在未來還是分開了...
而如今呢?當一切的事情越來越清晰的時候, 或許這些廠商們會明白這個問題了...
-
芯片
+關注
關注
463文章
54010瀏覽量
466138 -
算法
+關注
關注
23文章
4784瀏覽量
98064 -
大模型
+關注
關注
2文章
3650瀏覽量
5186 -
DeepSeek
+關注
關注
2文章
835瀏覽量
3270
原文標題:談談DeepSeek-v3提到的基礎設施演進
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
華為推動電信云加速向AI基礎設施演進
軌道計算基礎設施:太空光伏為太空AI算力供電的電源架構演進

正面對決GPT-5和Germini-3,DeepSeek-V3.2震撼發布

【「DeepSeek 核心技術揭秘」閱讀體驗】+混合專家
【「DeepSeek 核心技術揭秘」閱讀體驗】--全書概覽
【「DeepSeek 核心技術揭秘」閱讀體驗】第三章:探索 DeepSeek - V3 技術架構的奧秘
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
科大訊飛深度解析DeepSeek-V3/R1推理系統成本
中科馭數高性能網卡產品 成就DeepSeek推理模型網絡底座

摩爾線程GPU成功適配Deepseek-V3-0324大模型


DeepSeek在昇騰上的模型部署的常見問題及解決方案



 工商網監
工商網監
評論