") 英特爾和阿里云開發(fā)DDR5內(nèi)存故障預(yù)測(cè)和預(yù)防解決方案
英特爾和阿里云開發(fā)DDR5內(nèi)存故障預(yù)測(cè)和預(yù)防解決方案

背 景
在阿里云數(shù)據(jù)中心,內(nèi)存故障是服務(wù)器穩(wěn)定運(yùn)行面臨的主要挑戰(zhàn)之一。大規(guī)模數(shù)據(jù)中心中的內(nèi)存故障,不僅會(huì)降低服務(wù)器的可靠性,還可能中斷數(shù)據(jù)中心的服務(wù)并影響服務(wù)器的性能。因此,內(nèi)存可靠性成為數(shù)據(jù)中心中服務(wù)器可靠性、可用性和可維護(hù)性(Reliability, Availability, Serviceability–RAS)的關(guān)鍵要素。
新一代內(nèi)存標(biāo)準(zhǔn)DDR5具有更高的帶寬、更低的功耗和更高的密度。然而,它也為內(nèi)存可靠性帶來了新的挑戰(zhàn),其中包括:
DDR5引入了新的架構(gòu)和信號(hào)傳輸方式,需要更復(fù)雜的電路設(shè)計(jì)和優(yōu)化;
DDR5內(nèi)存模塊容量更大,但也增加了故障的風(fēng)險(xiǎn);
In-DRAM糾錯(cuò)碼(ECC)雖然可以糾正內(nèi)存中單比特的錯(cuò)誤,但它也導(dǎo)致主機(jī)錯(cuò)誤觀察不夠明確。
為了應(yīng)對(duì)這些挑戰(zhàn),阿里云與英特爾合作改進(jìn)了DDR5內(nèi)存的可靠性。具體措施包括:
1.主板管理控制器(BMC)的統(tǒng)一帶外(OOB)內(nèi)存錯(cuò)誤數(shù)據(jù)收集:通過BMC實(shí)現(xiàn)內(nèi)存錯(cuò)誤數(shù)據(jù)的統(tǒng)一收集,為后續(xù)分析提供數(shù)據(jù)基礎(chǔ)。
2.內(nèi)置人工智能輔助(AI輔助)的故障分析:BMC中集成AI輔助,實(shí)時(shí)預(yù)測(cè)和分析內(nèi)存故障。
3.英特爾Memory Resilience Technology(英特爾 MRT):英特爾 MRT已在阿里云數(shù)據(jù)中心部署,用于提前預(yù)警和預(yù)防潛在的內(nèi)存故障。
4.與阿里云巡洋艦系統(tǒng)(Alibaba Cruiser System)集成:將內(nèi)存健康評(píng)估和預(yù)測(cè)警報(bào)與阿里云的服務(wù)器監(jiān)控系統(tǒng)集成,以確保業(yè)務(wù)的穩(wěn)定性。
這些舉措共同為阿里云數(shù)據(jù)中心提供了快速且全面的硬件監(jiān)控服務(wù),幫助確保了服務(wù)器的可靠性和業(yè)務(wù)的正常運(yùn)行。
內(nèi)存可靠性面臨的挑戰(zhàn)
內(nèi)存故障可能由多種不同類型內(nèi)存底層錯(cuò)誤產(chǎn)生,例如單比特錯(cuò)誤(SBE)、行類型錯(cuò)誤、列類型錯(cuò)誤、多陣列錯(cuò)誤、存儲(chǔ)器模塊(DIMM)錯(cuò)誤等。每種內(nèi)存錯(cuò)誤都有其特定的頻率和受影響模式。例如,某些錯(cuò)誤類型會(huì)零星出現(xiàn)或間歇性發(fā)生,難以有效追蹤,而有些錯(cuò)誤類型則可能持續(xù)報(bào)錯(cuò)。有些錯(cuò)誤類型存在更高的不可糾正錯(cuò)誤(Uncorrectable Errors–UE)風(fēng)險(xiǎn),需要立即采取RAS(可靠性、可用性和可維護(hù)性)措施,而其他一些錯(cuò)誤類型觸發(fā)UE的風(fēng)險(xiǎn)相對(duì)較低,但在短時(shí)間內(nèi)可能導(dǎo)致大量可糾正錯(cuò)誤 (Correctable Errors–CE),從而影響系統(tǒng)性能。沒有一種通用的解決方案可以解決所有內(nèi)存錯(cuò)誤。
傳統(tǒng)的解決方案之一是在觀察到不可糾正錯(cuò)誤(UE)后更換故障的DIMM。然而,此舉無法避免系統(tǒng)崩潰的成本。另一種方法是基于計(jì)數(shù)的可糾正錯(cuò)誤(CE)評(píng)級(jí)策略來預(yù)測(cè)內(nèi)存故障這種策略在預(yù)測(cè)復(fù)雜內(nèi)存故障方面效果較差,因?yàn)镃E和UE的發(fā)生不僅取決于硬件的內(nèi)存故障狀態(tài),還取決于隱性的運(yùn)行時(shí)上下文、ECC糾正能力和內(nèi)存特定的故障模式。因此,內(nèi)存錯(cuò)誤具有高度的不確定性,預(yù)測(cè)UE非常困難。
雖然沒有通用的解決方案,但我們可以探索更智能的方法來處理內(nèi)存故障。例如,結(jié)合機(jī)器學(xué)習(xí)和實(shí)時(shí)監(jiān)測(cè),以更精確地預(yù)測(cè)UE和CE的發(fā)生。內(nèi)存錯(cuò)誤是一個(gè)復(fù)雜且關(guān)鍵的問題,需要綜合考慮多種因素來優(yōu)化系統(tǒng)的可靠性和性能。
基于BMC的人工智能輔助故障分析助力提升DDR5內(nèi)存的可靠性
阿里云和英特爾聯(lián)合研究和開發(fā)了面向DDR5的內(nèi)存故障預(yù)測(cè)和預(yù)防解決方案。該方案通過BMC實(shí)現(xiàn)內(nèi)存錯(cuò)誤數(shù)據(jù)的統(tǒng)一收集,為后續(xù)分析提供數(shù)據(jù)基礎(chǔ)。在BMC中集成英特爾 MRT技術(shù)提供AI輔助的實(shí)時(shí)預(yù)測(cè)和分析內(nèi)存故障,用于提前預(yù)警和預(yù)防潛在的內(nèi)存故障。數(shù)據(jù)收集、故障分析和預(yù)警與阿里云的服務(wù)器監(jiān)控系統(tǒng)集成(阿里云巡洋艦系統(tǒng)),為阿里云的數(shù)據(jù)中心提供快速而全面的硬件監(jiān)控服務(wù),以確保業(yè)務(wù)的穩(wěn)定性。
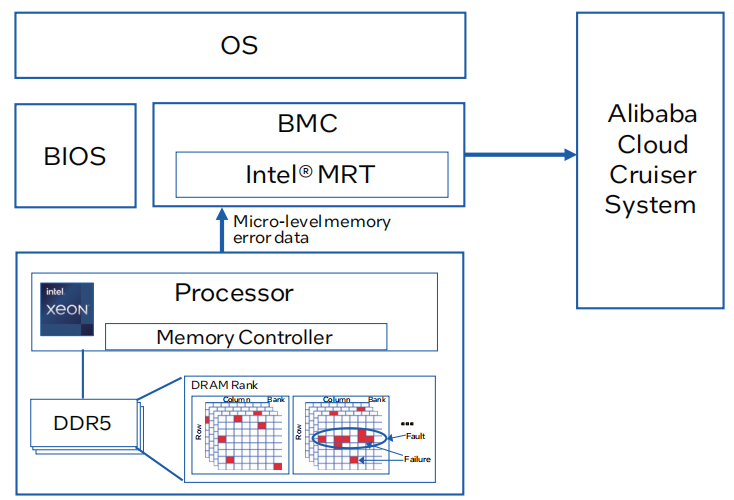
圖1. 解決方案架構(gòu)圖
這一解決方案的關(guān)鍵特點(diǎn)包括:
基于BMC的細(xì)粒度內(nèi)存故障采集
通過BMC收集細(xì)粒度的可糾正錯(cuò)誤(CE)和不可糾正錯(cuò)誤(UE)信息,包括詳細(xì)的位級(jí)錯(cuò)誤數(shù)據(jù)。相比使用帶內(nèi)(in-band)方式收集內(nèi)存錯(cuò)誤數(shù)據(jù),例如錯(cuò)誤檢測(cè)和糾正(EDAC)驅(qū)動(dòng)程序或基于BIOS SMI中斷觸發(fā),基于BMC的帶外內(nèi)存收集更可靠且統(tǒng)一,具有細(xì)粒度的數(shù)據(jù)粒度和豐富的錯(cuò)誤信息。
基于微觀內(nèi)存故障類型的錯(cuò)誤分析
通過歷史可糾正錯(cuò)誤(CE)信息的詳細(xì)數(shù)據(jù),檢測(cè)底層內(nèi)存故障類型。與僅關(guān)注CE計(jì)數(shù)不同,該解決方案從多個(gè)因素檢查內(nèi)存錯(cuò)誤數(shù)據(jù),包括空間分布(例如channel、rank、sub-channel、 bank、row、column等)、時(shí)間模式(例如瞬態(tài)、間歇、永久)、錯(cuò)誤位(error bit)位置、內(nèi)存特定故障模式、CPU錯(cuò)誤糾錯(cuò)碼(ECC)設(shè)計(jì)以及系統(tǒng)RAS配置等綜合評(píng)估故障風(fēng)險(xiǎn)。
AI輔助故障分析
利用機(jī)器學(xué)習(xí)方法訓(xùn)練了一個(gè)AI模型,通過對(duì)海量DDR5內(nèi)存日志進(jìn)行比較,預(yù)測(cè)內(nèi)存故障。預(yù)先訓(xùn)練的內(nèi)存故障預(yù)測(cè)AI模型集成到主板管理控制器(BMC)中,通過BMC為服務(wù)器提供內(nèi)存故障的實(shí)時(shí)預(yù)測(cè)與分析,從而減少大規(guī)模數(shù)據(jù)中心中的服務(wù)器停機(jī)時(shí)間。
集成阿里云巡洋艦硬件故障檢測(cè)系統(tǒng)
實(shí)時(shí)內(nèi)存健康評(píng)估和預(yù)測(cè)警報(bào)已與阿里云巡洋艦系統(tǒng)集成,為阿里云數(shù)據(jù)中心的物理服務(wù)器提供快速而全面的硬件監(jiān)控服務(wù)。
英特爾Memory Resilience Technology
英特爾 Memory Resilience Technology(英特爾 MRT)是一項(xiàng)旨在提高數(shù)據(jù)中心內(nèi)存可靠性的技術(shù),它使數(shù)據(jù)中心運(yùn)營商能夠主動(dòng)預(yù)測(cè)潛在的內(nèi)存故障風(fēng)險(xiǎn),確保數(shù)據(jù)中心的運(yùn)行和工作負(fù)載的連續(xù)性。以下是該技術(shù)的關(guān)鍵功能:
1.基于帶外的細(xì)粒度內(nèi)存故障數(shù)據(jù)收集:實(shí)現(xiàn)細(xì)粒度內(nèi)存錯(cuò)誤數(shù)據(jù)的統(tǒng)一收集,為后續(xù)分析提供數(shù)據(jù)基礎(chǔ)。
2.分析定位內(nèi)存故障點(diǎn):提供底層內(nèi)存故障定位及分析。
3.預(yù)測(cè)性故障警報(bào):提前發(fā)現(xiàn)可能出現(xiàn)的內(nèi)存故障。
4.基于預(yù)測(cè)的內(nèi)存頁面離線:根據(jù)預(yù)測(cè),將內(nèi)存頁面離線,以防止?jié)撛诠收嫌绊憽?/p>
5.基于預(yù)測(cè)的內(nèi)存故障區(qū)域隔離:根據(jù)預(yù)測(cè)及系統(tǒng)相應(yīng)RAS配置,隔離內(nèi)存故障區(qū)域,以避免潛在內(nèi)存錯(cuò)誤發(fā)生。
英特爾 Memory Resilience Technology利用多維模型和人工智能算法,在微觀層面檢測(cè)內(nèi)存故障。它為每個(gè)DIMM分配健康分?jǐn)?shù),并實(shí)時(shí)檢測(cè)潛在的故障。通過人工智能分析海量的內(nèi)存錯(cuò)誤日志優(yōu)化內(nèi)存故障預(yù)測(cè)模型,該技術(shù)可以準(zhǔn)確地定位潛在問題,并在故障發(fā)生之前識(shí)別和防止內(nèi)存故障。
雖然沒有通用的解決方案可以解決所有內(nèi)存錯(cuò)誤,但英特爾Memory Resilience Technology為數(shù)據(jù)中心提供了一種智能且綜合的方法,以優(yōu)化系統(tǒng)的可靠性和性能。
利用BDAT數(shù)據(jù)診斷硬件故障
英特爾BIOS參考代碼實(shí)現(xiàn)了系統(tǒng)驗(yàn)證功能,可以生成包括內(nèi)存余量數(shù)據(jù)在內(nèi)的全面系統(tǒng)數(shù)據(jù)。這些數(shù)據(jù)從標(biāo)準(zhǔn)的BIOS數(shù)據(jù)ACPI表 (BDAT)中暴露出來,該表在ACPI表中定義。BDAT數(shù)據(jù)是系統(tǒng)BIOS的基本支持,它在整個(gè)BIOS引導(dǎo)流程中生成,并集成到ACPI RSDT表中。通過分析BDAT數(shù)據(jù),可以有效提升生產(chǎn)系統(tǒng)的診斷和問題調(diào)試的效率。
結(jié)果與分析
阿里云已在不同工作負(fù)載下的阿里云數(shù)據(jù)中心的數(shù)千臺(tái)采用第四代英特爾 至強(qiáng) 可擴(kuò)展處理器的平臺(tái)上部署了英特爾 Memory Resilience Technology,并正在將平臺(tái)升級(jí)至第五代英特爾至強(qiáng) 可擴(kuò)展處理器。
新一代處理器擁有更可靠的性能,更出色的能效。它在運(yùn)行各種工作負(fù)載時(shí)均可實(shí)現(xiàn)顯著的每瓦性能增益,在AI、數(shù)據(jù)中心、網(wǎng)絡(luò)和科學(xué)計(jì)算的性能和總體擁有成本(TCO)方面亦有更出色的表現(xiàn)。相較上一代產(chǎn)品,第五代英特爾 至強(qiáng) 可擴(kuò)展處理器可在相同功耗范圍內(nèi)提供更高的算力和更快的內(nèi)存。此外,它與上一代產(chǎn)品的軟件和平臺(tái)兼容,因此部署新系統(tǒng)時(shí)可大大減少測(cè)試和驗(yàn)證工作。

圖2. 第五代英特爾 至強(qiáng) 可擴(kuò)展處理器具備更強(qiáng)大性能
初步結(jié)果表明,該解決方案可以在不可糾正錯(cuò)誤(UE)發(fā)生之前有效地預(yù)測(cè),并在傳統(tǒng)的基于CE計(jì)數(shù)的CE風(fēng)暴識(shí)別機(jī)制被觸發(fā)之前警報(bào)可糾正錯(cuò)誤(CE)風(fēng)暴案例。UE和CE風(fēng)暴警報(bào)的預(yù)測(cè)提前時(shí)間因底層故障模型而異,從幾分鐘到幾小時(shí)甚至幾天不等。該方案經(jīng)過迭代,預(yù)期能夠通過優(yōu)化的DDR5模型預(yù)測(cè)57%的UE和74%的CE風(fēng)暴6 。
除了有效的UE和CE風(fēng)暴預(yù)測(cè)外,從BMC收集的帶外(OOB)內(nèi)存錯(cuò)誤對(duì)于進(jìn)一步診斷和排除內(nèi)存和系統(tǒng)問題至關(guān)重要。
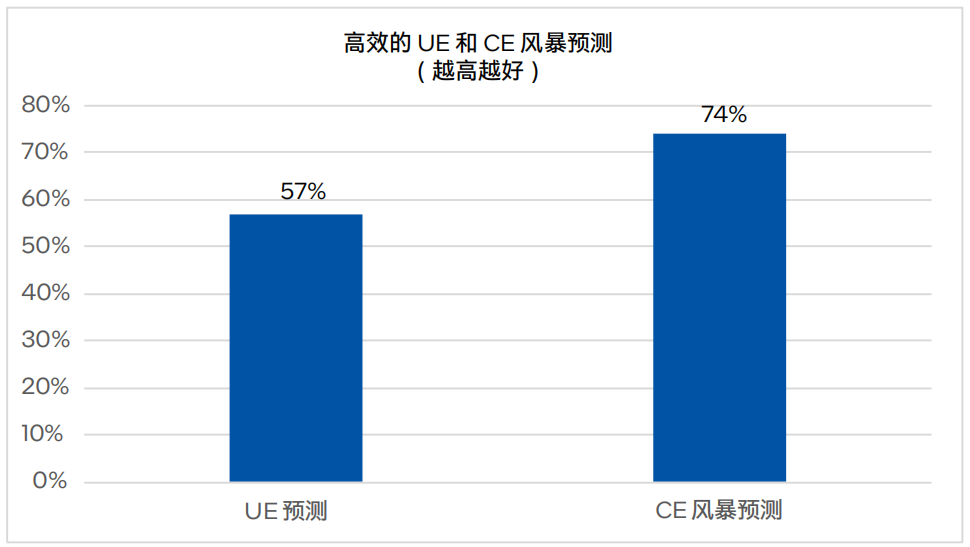
圖3. 高效的UE和CE風(fēng)暴預(yù)測(cè)
結(jié) 論
通過BMC集成英特爾 Memory Resilience Technology技術(shù),可以有效提高阿里云數(shù)據(jù)中心DDR5內(nèi)存可靠性。對(duì)于阿里云而言,改善整體數(shù)據(jù)中心的總體擁有成本(TCO)至關(guān)重要。英特爾和阿里云正在合作開發(fā)下一代的DDR5故障預(yù)測(cè)技術(shù)和提供對(duì)新內(nèi)存技術(shù)的方法。
-
英特爾
+關(guān)注
關(guān)注
61文章
10310瀏覽量
180865 -
內(nèi)存
+關(guān)注
關(guān)注
9文章
3220瀏覽量
76441 -
阿里云
+關(guān)注
關(guān)注
3文章
1042瀏覽量
45813 -
DDR5
+關(guān)注
關(guān)注
1文章
479瀏覽量
25794
原文標(biāo)題:英特爾攜手阿里云提升DDR5內(nèi)存的可靠性
文章出處:【微信號(hào):英特爾中國,微信公眾號(hào):英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論