 新火種AI|算力不足,小模型成AI模型發展下個方向?
新火種AI|算力不足,小模型成AI模型發展下個方向?

作者:一號
編輯:美美
大模型不是AI的唯一出路,把模型做小也是本事。
這段時間,AI模型界是真的熱鬧,新的模型不斷涌現,不管是開源還是閉源,都在刷新成績。就在前幾天,Meta就上演了一出“重奪開源鐵王座”的好戲。發布了Llama 3 8B和70B兩個版本,在多項指標上都超越了此前開源的Grok-1和DBRX,成為了新的開源大模型王者。

并且Meta還透露,之后還將推出400B版本的Llama 3,它的測試成績可是在很多方面上都追上了OpenAI閉源的GPT-4,讓很多人都直呼,開源版的GPT-4就要來了。盡管在參數量上來看,相比Llama 2,Llama 3并沒有特別大的提升,但是在某些表現上,Llama 3最小的8B版本都比Llama 2 70B要好。可見,模型性能的提升,并非只有堆參數這一種做法。
Llama 3重回開源之王
當地時間4月18日,“真·OpenAI”——Meta跑出了目前最強的開源大模型Llama 3。本次Meta共發布了兩款開源的Llama 3 8B和Llama 3 70B模型。根據Meta的說法,這兩個版本的Llama 3是目前同體量下,性能最好的開源模型。并且在某些數據集上,Llama 3 8B的性能比Llama 2 70B還要強,要知道,這兩者的參數可是相差了一個數量級。

能夠做到這點,可能是因為Llama 3的訓練效率要高3倍,它基于超過15T token訓練,這比Llama 2數據集的7倍還多。在MMLU、ARC、DROP等基準測試中,Llama 3 8B在九項測試中領先于同行,Llama 3 70B也同樣擊敗了Gemini 1.5 Pro和Claude 3 Sonnet。
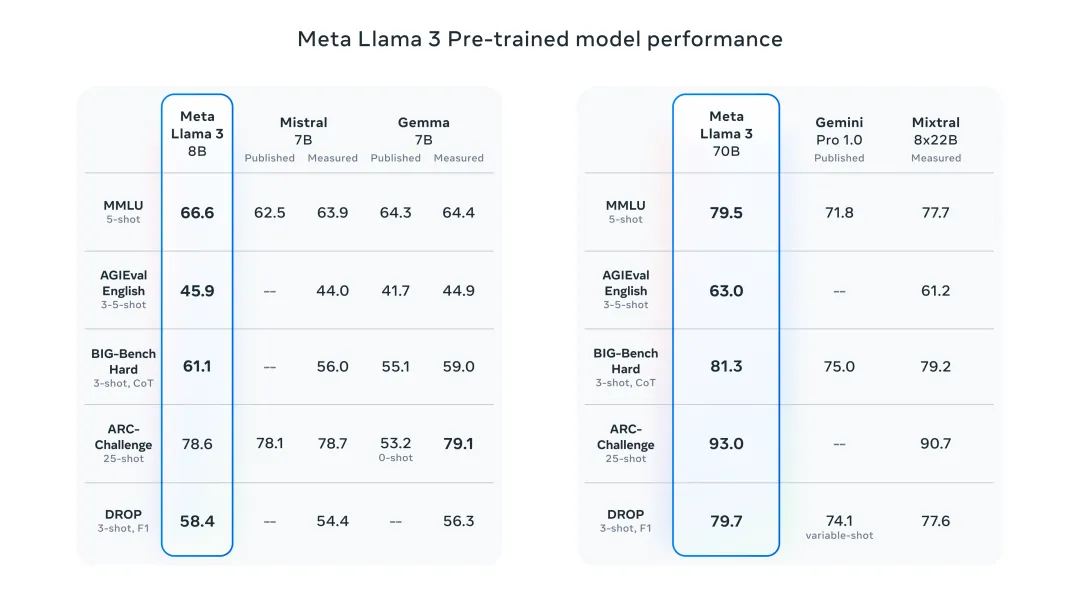
盡管在參數量上并沒有特別大的提升,但毫無疑問,Llama 3的性能已經得到了很大的進步,可以說是用相近的參數量獲得了更好的性能,這可能是在算力資源短期內無法滿足更大規模運算的情況下所作出的選擇,但這體現了AI模型的研發并非只有堆砌參數這一條“大力出奇跡”的道路。
把大模型做小正成業內共識
實際上,在Llama 3之間的兩位開源王者,Grok-1和DBRX也致力于把模型做小。和以往的大模型,使用一個模型解決一切問題的方式不同,Grok-1和DBRX都采用了MoE架構(專家模型架構),在面對不同問題的時候,調用不同的小模型來解決,實現在節省算力的情況下,保證回答的質量。
而微軟也在Llama 3發布后沒幾天,就出手截胡,展示了Phi-3系列小模型的技術報告。在這份報告中,僅3.8B參數的Phi-3-mini在多項基準測試中都超過了Llama 3 8B,并且為了方便開源社區使用,還特意把它設計成了與Llama系列兼容的結構。更夸張的是,微軟的這個模型,在手機上也能直接跑,經4bit量化后的phi-3-mini在iPhone 14 pro和iPhone 15使用的蘋果A16芯片上能夠跑到每秒12 token,這也就意味著,現在手機上能本地運行的最佳開源模型,已經做到了ChatGPT水平。
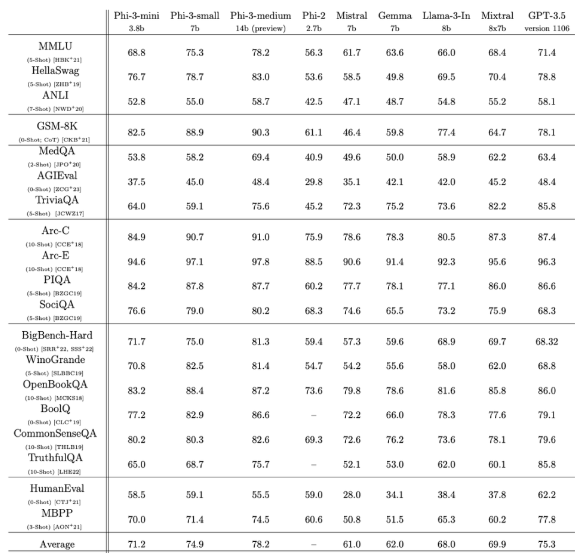
而除了mini杯外,微軟也一并發布了小杯和中杯,7B參數的Phi-3-small和14B參數的Phi-3-medium。在技術報告中,微軟也說了,去年研究團隊就發現,單純堆砌參數量并非提升模型性能的唯一路徑,反而是精心設計訓練的數據,尤其是利用大模型本身去生成合成數據,并配合嚴格過濾的高質量數據,能夠讓中小模型的能力大幅躍升,所以他們也說,Textbooks are all you need,教科書級別的高質量數據才是重要的。

AI模型發展正著力于擺脫限制
自英偉達乘著AI的東風,成為行業內說一不二,當之無愧的“賣鏟子的人”,各家AI公司都將英偉達的GPU視為“硬通貨”,以致于誰囤有更多的英偉達的GPU,誰的AI實力就強。但英偉達的GPU的交付并未能始終跟上市場的需求。
因此,很多AI公司開始另謀出路,要么找其他的GPU生產商,要么決定自己研發AI芯片。即使你囤夠了英偉達的GPU,也還有其他限制,OpenAI在前段時間就被爆出,因為訓練GPT-6,差點把微軟的電網搞癱瘓。馬斯克也曾說過,當前限制AI發展的主要因素是算力資源,但在未來,電力會成為限制AI發展的另一阻礙。

顯然,如果持續“大力出奇跡”,通過堆砌參數量來實現AI性能的提升,那么以上這些問題遲早會遇到,但是如果把大模型做小,使用較小的參數量,實現同樣或者更好的性能,那么將可以顯著減少對算力資源的需求,進而減少對電力資源的消耗,從而讓AI在有限資源的情況下,得到更好的發展。
因此,接下來,誰能在將模型做小的同時,還能實現性能的增長,也是實力的體現。
審核編輯 黃宇
-
AI
+關注
關注
91文章
39793瀏覽量
301403 -
算力
+關注
關注
2文章
1532瀏覽量
16742
發布評論請先 登錄
華為發布AI容器技術Flex:ai,算力平均利用率提升30%
國產AI芯片真能扛住“算力內卷”?海思昇騰的這波操作藏了多少細節?


【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+內容總覽
算力網絡的“神經突觸”:AI互聯技術如何重構分布式訓練范式





 工商網監
工商網監
評論