 AI時代的存儲墻,哪種存算方案才能打破?
AI時代的存儲墻,哪種存算方案才能打破?

電子發燒友網報道(文/周凱揚)回顧計算行業幾十年的歷史,芯片算力提升在幾年前,還在遵循摩爾定律。可隨著如今摩爾定律顯著放緩,算力發展已經陷入瓶頸。而且禍不單行,陷入同樣困境的還有存儲。從新標準推進的角度來看,存儲市場依然在朝著更高性能的方向發展。但以這些通用標準推出的產品,終究還是會被用到馮諾依曼架構的計算體系中去。或許單個產品的性能有所增加,可面對AI計算的海量數據,這點提升還是有些不夠看。
以LLM這個熱門AI應用而言,其數據量已經在以2年750倍的速度爆發式增長,相較之下硬件算力正在以2年3倍的速度增長。但與存儲不同,硬件算力是可以靠堆規模來實現持續提升的,可存儲帶寬和互聯帶寬卻沒法擁有同樣的拓展性,只有存儲容量能夠勉強跟上。所以市場上多數都在追求某種形式的存算一體方案,但實現的形式和技術路線不盡相同。
近存方案,更大的SRAM和HBM
對于我們說的存儲墻而言,其實在SRAM上并不那么明顯,這種最接近處理單元的存儲,常被用作高速緩存,不僅讀寫速度極快,能效比更是遠超DRAM。但SRAM相對其他存儲而言,存儲密度最低,成本卻不低。所以盡管現如今雖然更大的SRAM設計越來越普遍,但容量離DRAM還差得很遠。
但這并不代表這樣的設計沒有人嘗試,對于愿意花大成本的廠商而言,還是很高效的一條技術路線。以特斯拉為例,其Tesla Dojo超算系統的自研芯片D1就采用了超大SRAM的技術路線。Dojo在其網格設計中采用了超快且平均分布的SRAM。
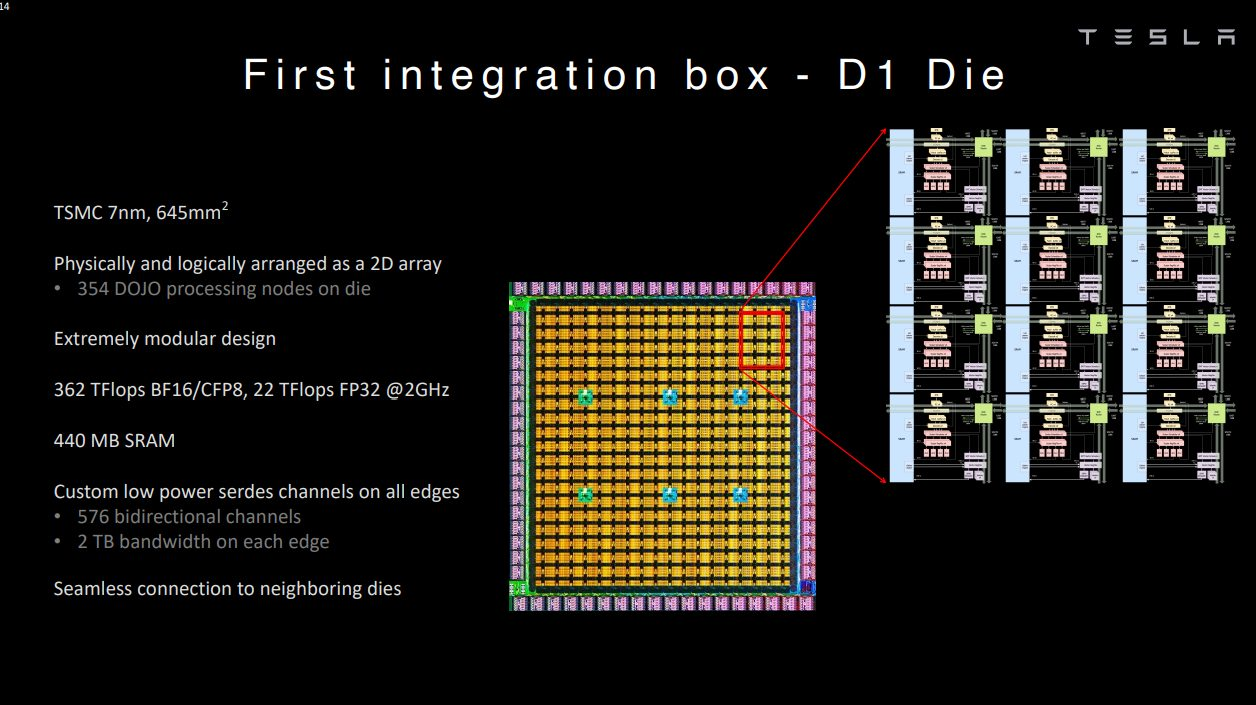
單個D1核心擁有1.25MB的SRAM,加載速度達到400GB/s,存儲速度達到270GB/s。單個D1芯片的SRAM緩存達到440MB。簡單來說,Dojo可以用遠超L2緩存級別的SRAM容量,實現L1緩存級別的帶寬和延遲。
當然了,這樣的設計注定代表了投入大量的成本。在特斯拉2023財年Q4的財報會議上,馬斯克強調他們做了英偉達和Dojo的兩手準備。Dojo作為長遠計劃,因為最終的回報可能會值回現在的投入,但他也強調這確實不是什么高收益的項目。
所以對于已有的計算架構來說,走近存路線,提高DRAM的性能是最為適合的,比如HBM。HBM作為主流的近存高帶寬方案,已經被廣泛應用在新一代的AI芯片、GPU上。以HBM3e為例,1.2TB/s的超大帶寬足以滿足現如今絕大多數AI芯片的數據傳輸。未來的HBM4更是承諾1.5TB/s到2TB/s的帶寬,
HBM的方案象征了目前DRAM堆疊的集大成技術,但目前還是存在不少問題,比如更高的成本以及對產能的要求。在現如今的AI需求驅動下,新發布的芯片很難再采用HBM設計的同時,保證大批量量產,無論是HBM產能還是CoWoS產能都處于滿載的階段,而且與制造廠商強綁定。可恰恰存儲帶寬決定了AI應用的速度,所以在HBM方案量產困難成本高昂的前提下,即便是英特爾和AMD這樣的廠商也經不起這樣揮霍,不少其他廠商更是選擇了看下存內計算。
存內計算與處理,需要解決算力與存儲雙瓶頸
為了解決AI計算中數據存取的效率問題,把數據處理和篩選的工作放在存儲端,就能極大地降低數據移動的能耗。以三星的PIM技術為例,其將關鍵的算法內核放在內存中的PCU模塊中執行,相比已有的HBM方案,PIM-HBM可以將能耗降低70%以上。而且不僅是HBM,PIM也可以集成到LPDDR、GDDR等存儲方案中。
不過存內處理的方案只解決了功耗和效率的問題,并沒有對計算性能和存儲性能帶來任何大幅提升。至于將主要計算工作交給存內的計算單元,就是存內計算的目標了,比如不少廠商嘗試的模擬存內計算(AIMC)。但這類方案實現大規模并行化運算的同時,還是需要昂貴的數模轉換器,以及逃不開的錯誤檢測。至于數字存內計算方案,一定程度上規避了模擬存內計算的缺陷,但還是犧牲了一些面積效率。對于一些大模型AI應用而言,單芯片的存儲容量擴展性堪憂。
所以數模混合成了新的研究方向,比如中科院微電子研究所就在今年的ISSCC大會上發表了數模混合存算一體芯片的論文,其采用模擬方案來進行陣列內位乘法計算,利用數字方案來進行陣列外多位移位累加計算,從而達到整體的高能量效率和面積效率,INT8精度下的計算峰值能效可達111.17TFLOPS/W.

除此之外,還有存間計算的廠商,將計算單元放在不同的SRAM之間。以存間計算初創公司Untether AI為例,他們以打造存內推理加速器AI為主,通過將計算單元放在兩個存儲單元之間,其IC可以提供更高能效比的推理性能。比如他們在打造的第二代IC,speedAI240,集成了1400個定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可達30 TFLOPS/W。
除了各種存算一體架構的算力瓶頸外,存儲本身也需要做出突破。以三星的PIM為例,其雖然在DRAM上引入了PIM計算單元,但并未對DRAM本身的帶寬的性能帶來提升,這就造成了在存算一體的架構中,依然存在計算單元與存儲器性能不平衡的問題,各種其他類型的存儲器,包括MRAM、PCM、RRAM,除了量產問題外,寫入速度和功耗的問題也還未實現突破。
西安紫光國芯為此提出了一種3D異質集成DRAM架構,邏輯晶圓通過3D混合鍵合工藝堆疊至SeDRAM晶圓上,進一步提升了訪存帶寬,降低了單位比特能耗,還能實現超大容量。從去年紫光國芯在VLSI 2023發布的論文來看,其SeDRAM已經發展至新一代多層陣列架構。結合低溫混合鍵合技術和mini-TSV堆疊技術,可以實現135Gbps/Gbit的帶寬和0.66pJ/bit的能效。
寫在最后
其實無論是哪一種突破存儲墻瓶頸的方式,最終都很難逃脫復雜工藝帶來的挑戰。行業遲遲不愿普及相關的存算技術,還是在制造工藝上沒有達到適合普及的標準,無論是良率、成本還是所需的設計、制造流水線變化。已經占據主導地位的計算芯片廠商,也不會選擇非得和存儲綁在一條船上,但行業必然會朝這個方向發展。
此外,不少存內計算的堆疊方案中,還沒有選擇將主計算資源的CPU或GPU與存儲垂直堆疊,而是把部分計算負載交給與存儲結合的計算單元。這樣一來既提高了AI計算的效率,又不會因為結構變化而出現不兼容的情況。從行業發展的角度來看,近存計算和存內處理最有可能先普及開來。
以LLM這個熱門AI應用而言,其數據量已經在以2年750倍的速度爆發式增長,相較之下硬件算力正在以2年3倍的速度增長。但與存儲不同,硬件算力是可以靠堆規模來實現持續提升的,可存儲帶寬和互聯帶寬卻沒法擁有同樣的拓展性,只有存儲容量能夠勉強跟上。所以市場上多數都在追求某種形式的存算一體方案,但實現的形式和技術路線不盡相同。
近存方案,更大的SRAM和HBM
對于我們說的存儲墻而言,其實在SRAM上并不那么明顯,這種最接近處理單元的存儲,常被用作高速緩存,不僅讀寫速度極快,能效比更是遠超DRAM。但SRAM相對其他存儲而言,存儲密度最低,成本卻不低。所以盡管現如今雖然更大的SRAM設計越來越普遍,但容量離DRAM還差得很遠。
但這并不代表這樣的設計沒有人嘗試,對于愿意花大成本的廠商而言,還是很高效的一條技術路線。以特斯拉為例,其Tesla Dojo超算系統的自研芯片D1就采用了超大SRAM的技術路線。Dojo在其網格設計中采用了超快且平均分布的SRAM。
D1芯片 / 特斯拉
單個D1核心擁有1.25MB的SRAM,加載速度達到400GB/s,存儲速度達到270GB/s。單個D1芯片的SRAM緩存達到440MB。簡單來說,Dojo可以用遠超L2緩存級別的SRAM容量,實現L1緩存級別的帶寬和延遲。
當然了,這樣的設計注定代表了投入大量的成本。在特斯拉2023財年Q4的財報會議上,馬斯克強調他們做了英偉達和Dojo的兩手準備。Dojo作為長遠計劃,因為最終的回報可能會值回現在的投入,但他也強調這確實不是什么高收益的項目。
所以對于已有的計算架構來說,走近存路線,提高DRAM的性能是最為適合的,比如HBM。HBM作為主流的近存高帶寬方案,已經被廣泛應用在新一代的AI芯片、GPU上。以HBM3e為例,1.2TB/s的超大帶寬足以滿足現如今絕大多數AI芯片的數據傳輸。未來的HBM4更是承諾1.5TB/s到2TB/s的帶寬,
HBM的方案象征了目前DRAM堆疊的集大成技術,但目前還是存在不少問題,比如更高的成本以及對產能的要求。在現如今的AI需求驅動下,新發布的芯片很難再采用HBM設計的同時,保證大批量量產,無論是HBM產能還是CoWoS產能都處于滿載的階段,而且與制造廠商強綁定。可恰恰存儲帶寬決定了AI應用的速度,所以在HBM方案量產困難成本高昂的前提下,即便是英特爾和AMD這樣的廠商也經不起這樣揮霍,不少其他廠商更是選擇了看下存內計算。
存內計算與處理,需要解決算力與存儲雙瓶頸
為了解決AI計算中數據存取的效率問題,把數據處理和篩選的工作放在存儲端,就能極大地降低數據移動的能耗。以三星的PIM技術為例,其將關鍵的算法內核放在內存中的PCU模塊中執行,相比已有的HBM方案,PIM-HBM可以將能耗降低70%以上。而且不僅是HBM,PIM也可以集成到LPDDR、GDDR等存儲方案中。
不過存內處理的方案只解決了功耗和效率的問題,并沒有對計算性能和存儲性能帶來任何大幅提升。至于將主要計算工作交給存內的計算單元,就是存內計算的目標了,比如不少廠商嘗試的模擬存內計算(AIMC)。但這類方案實現大規模并行化運算的同時,還是需要昂貴的數模轉換器,以及逃不開的錯誤檢測。至于數字存內計算方案,一定程度上規避了模擬存內計算的缺陷,但還是犧牲了一些面積效率。對于一些大模型AI應用而言,單芯片的存儲容量擴展性堪憂。
所以數模混合成了新的研究方向,比如中科院微電子研究所就在今年的ISSCC大會上發表了數模混合存算一體芯片的論文,其采用模擬方案來進行陣列內位乘法計算,利用數字方案來進行陣列外多位移位累加計算,從而達到整體的高能量效率和面積效率,INT8精度下的計算峰值能效可達111.17TFLOPS/W.
speedAI240 / Untether AI
除此之外,還有存間計算的廠商,將計算單元放在不同的SRAM之間。以存間計算初創公司Untether AI為例,他們以打造存內推理加速器AI為主,通過將計算單元放在兩個存儲單元之間,其IC可以提供更高能效比的推理性能。比如他們在打造的第二代IC,speedAI240,集成了1400個定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可達30 TFLOPS/W。
除了各種存算一體架構的算力瓶頸外,存儲本身也需要做出突破。以三星的PIM為例,其雖然在DRAM上引入了PIM計算單元,但并未對DRAM本身的帶寬的性能帶來提升,這就造成了在存算一體的架構中,依然存在計算單元與存儲器性能不平衡的問題,各種其他類型的存儲器,包括MRAM、PCM、RRAM,除了量產問題外,寫入速度和功耗的問題也還未實現突破。
西安紫光國芯為此提出了一種3D異質集成DRAM架構,邏輯晶圓通過3D混合鍵合工藝堆疊至SeDRAM晶圓上,進一步提升了訪存帶寬,降低了單位比特能耗,還能實現超大容量。從去年紫光國芯在VLSI 2023發布的論文來看,其SeDRAM已經發展至新一代多層陣列架構。結合低溫混合鍵合技術和mini-TSV堆疊技術,可以實現135Gbps/Gbit的帶寬和0.66pJ/bit的能效。
寫在最后
其實無論是哪一種突破存儲墻瓶頸的方式,最終都很難逃脫復雜工藝帶來的挑戰。行業遲遲不愿普及相關的存算技術,還是在制造工藝上沒有達到適合普及的標準,無論是良率、成本還是所需的設計、制造流水線變化。已經占據主導地位的計算芯片廠商,也不會選擇非得和存儲綁在一條船上,但行業必然會朝這個方向發展。
此外,不少存內計算的堆疊方案中,還沒有選擇將主計算資源的CPU或GPU與存儲垂直堆疊,而是把部分計算負載交給與存儲結合的計算單元。這樣一來既提高了AI計算的效率,又不會因為結構變化而出現不兼容的情況。從行業發展的角度來看,近存計算和存內處理最有可能先普及開來。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
存儲
+關注
關注
13文章
4791瀏覽量
90061 -
sram
+關注
關注
6文章
820瀏覽量
117467 -
AI
+關注
關注
91文章
39793瀏覽量
301402 -
HBM
+關注
關注
2文章
431瀏覽量
15831 -
存算一體
+關注
關注
1文章
121瀏覽量
5135 -
存內計算
+關注
關注
0文章
35瀏覽量
1661
發布評論請先 登錄
相關推薦
熱點推薦
ReRAM:AI時代的潛力存儲技術
,逐漸成為存儲領域和人工智能(AI)領域的焦點。 ? ReRAM是一種非易失性存儲器,由富士通率先研制成功。它基于憶阻器原理,采用金屬 - 介質層 - 金屬(MIM)的三層結構,通過電阻狀態的變化來
如何突破AI存儲墻?深度解析ONFI 6.0高速接口與Chiplet解耦架構
1. 行業核心痛點:AI“存儲墻”危機在大模型訓練與推理場景中,算力演進速度遠超存儲帶寬,計算與存儲
發表于 01-29 17:32
國產高性能ONFI IP解決方案全解析
PHY IP 方案展現了行業領先的性能,專為滿足存算一體及大容量存儲需求而優化:? 高速率傳輸:全面支持先進規范,傳輸速率可達 3600/4800 Mbps。? 卓越信號完整性:支持
發表于 01-13 16:15
2025年曙光存儲以先進存力構建開放的算力底座并加速AI進化
數據存儲作為AI基礎設施的重要組成,戰略價值日益凸顯。2025年,曙光存儲以先進存力構建開放的算力底座、加速
AI存算一體,這家ReRAM新型存儲受關注
及相關芯片產品的研發,涵蓋AI存算一體(Computing in Memory, CIM)IP及大模型加速方案、高性

曙光存儲推出面向金融的可信AI存儲
近日,曙光存儲推出面向金融的可信AI存儲,助力金融行業高效、安全、穩定地使用關鍵業務敏感數據。該方案基于全球領先的集中式全閃存儲FlashN
江波龍攜AI存儲創新亮相中國移動合作伙伴大會,合創AI+時代
經濟發展新機遇。作為中國移動合作伙伴,江波龍在本屆大會集中展示面向AI、云計算及數據中心的企業級存儲方案,與產業鏈伙伴合創AI+時代。


2025端側AI芯片爆發:存算一體、非Transformer架構誰主浮沉?邊緣計算如何選型?
各位技術大牛好!最近WAIC 2025上端側AI芯片密集發布,徹底打破傳統算力困局。各位大佬在實際項目中都是如何選型的呢?
發表于 07-28 14:40
力積存儲港股IPO,蓄力研發AI存算方案
電子發燒友網綜合報道,5月28日,浙江力積存儲科技股份有限公司(以下簡稱"力積存儲")向港交所提交上市申請書,獨家保薦人為中信證券(香港)有限公司。 ? 力積存儲是中國領先的內存芯片設計公司及
蘋芯科技 N300 存算一體 NPU,開啟端側 AI 新征程
隨著端側人工智能技術的爆發式增長,智能設備對本地算力與能效的需求日益提高。而傳統馮·諾依曼架構在數據處理效率上存在瓶頸,“內存墻”問題成為制約端側AI性能突破的關鍵掣肘。在這一背景下,存

存力接棒算力,慧榮科技以主控技術突破AI存儲極限
電子發燒友網報道(文/黃山明)在AI的高速增長下,尤其是以DeepSeek為代表的AI大模型推動存儲需求激增,算力增長倒逼存力升級。而

Solidigm高密度方案解決數據中心存儲難題,賦能AI創新發展
QLC在內的豐富產品組合,打破從數據中心到邊緣應用面臨的存儲瓶頸,提升人工智能效率,釋放人工智能潛能。 當AI的發展突破界限,算力與存力的天



 工商網監
工商網監
評論