 最強AI芯片發布,Cerebras推出性能翻倍的WSE-3 AI芯片
最強AI芯片發布,Cerebras推出性能翻倍的WSE-3 AI芯片

前言: 近日,芯片行業的領軍企業Cerebras Systems宣布推出其革命性的產品——Wafer Scale Engine 3,該產品成功將現有最快AI芯片的世界紀錄提升了一倍。
WSE-3 AI芯片比英偉達H100大56倍
WSE-3芯片采用了臺積電先進的5納米工藝技術,集成了超過4萬億個晶體管與90萬個核心,展現出驚人的125 petaflops計算性能。
此芯片不僅是臺積電目前能制造的最大方形芯片,其獨特的44GB片上SRAM設計。
摒棄了傳統的片外HBM3E或DDR5內存方式,使內存與核心緊密結合,極大縮短了數據處理與計算的距離,提升了整體運算效率。
另一方面,Cerebras的CS-3系統代表了Wafer Scale技術的第三代成就。
其頂部配置有先進的MTP/MPO光纖連接,以及完備的冷卻系統包括電源、風扇和冗余泵,確保了系統在高負荷運行時的穩定與可靠。
相較于前代產品,CS-3系統及其新型芯片在保持相同功耗和成本的同時,實現了近兩倍的性能提升。
值得注意的是,WSE-3芯片的核心數量高達英偉達H100 Tensor Core的52倍。

由WSE-3驅動的Cerebras CS-3系統在訓練速度上比英偉達的DGX H100系統快了8倍,內存擴大了1900倍。
更令人震驚的是,CS-3系統能夠支持高達24萬億個參數的AI模型訓練,這一數字是DGX H100的600倍。Cerebras公司高管表示,CS-3系統的能力已全面超越DGX H100。
舉例來說,原本在GPU上需要30天才能完成的Llama 700億參數模型訓練,現在通過CS-3集群僅需一天即可完成。
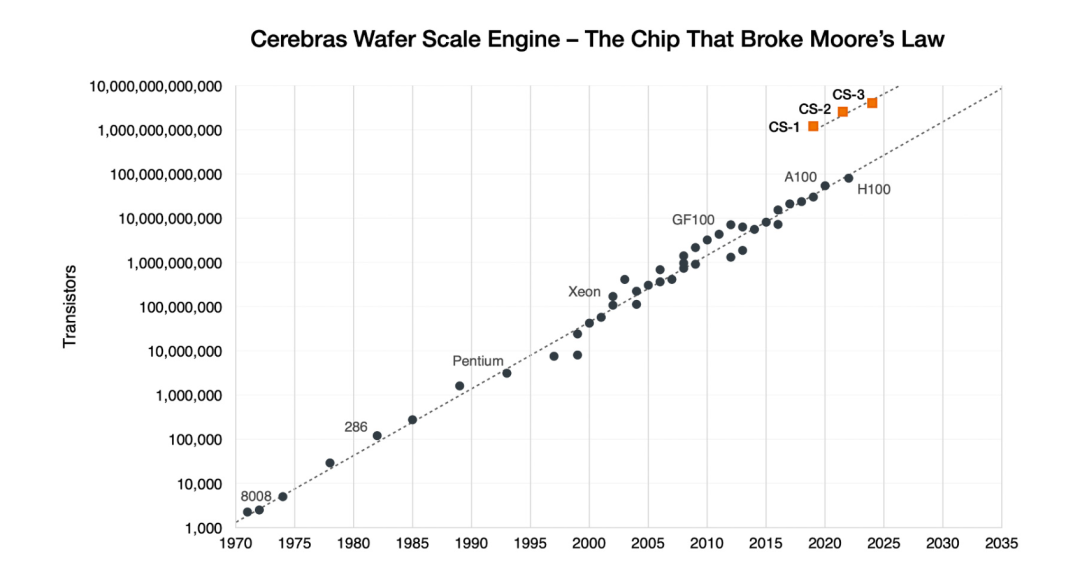
第三代產品成功破圈
WSE-3在保持與前代產品Cerebras WSE-2相同功耗和價格的同時,其性能卻實現了翻番,這無疑是對市場的一次重大突破。
WSE-3是Cerebras第三代產品,展現了其在晶圓級芯片設計和制造方面的技術積累。
第一代WSE于2019年推出,采用臺積電16nm工藝;第二代WSE-2于2021年發布,采用7nm工藝;WSE-3則使用5nm技術。
相比第一代,WSE-3的晶體管數量增加了兩倍以上,達到了4萬億的規模。根據其官方介紹,與晶體管數量的增長相比,芯片上的計算單元、內存和帶寬的增長速度有所放緩。
這反映出Cerebras在追求整體性能提升的同時,也在芯片面積、功耗和成本之間進行權衡。
通過多代產品的迭代,Cerebras掌握了晶圓級芯片設計和制造的核心技術,為未來的創新奠定了基礎。
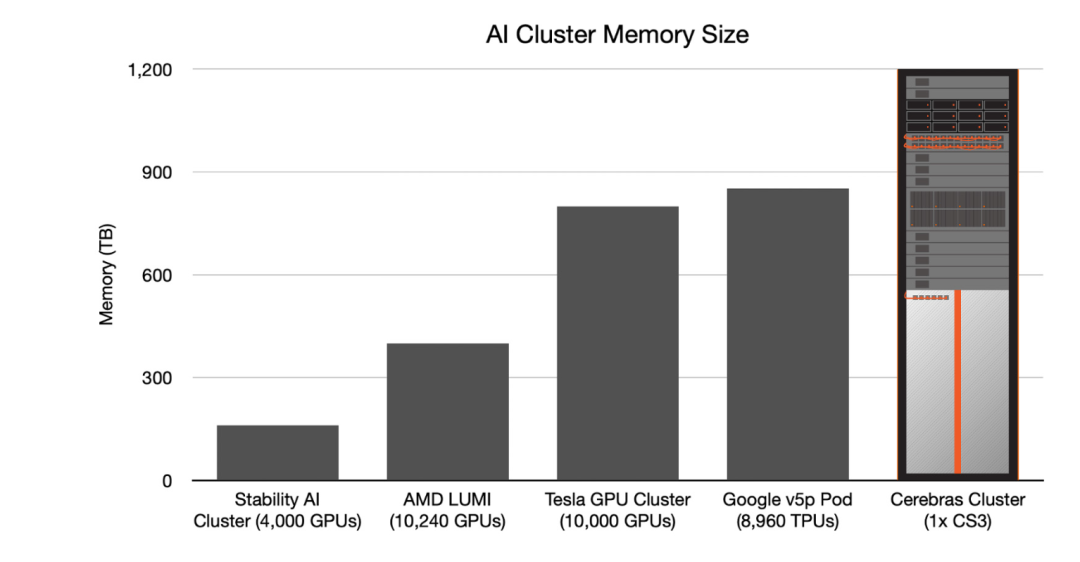
專為AI打造的計算能力
以往,在傳統的GPU集群環境下,研究團隊在分配模型時不僅需要科學嚴謹,還需應對一系列復雜的挑戰,如處理器單元的內存容量限制、互聯帶寬的瓶頸以及同步機制的協調等。
此外,團隊還需持續調整超參數并開展優化實驗,以確保模型的性能達到最佳狀態。
然而,這些努力常常因微小的變動而受到影響,導致解決問題所需的總時間進一步延長,增加了研究的復雜性和不確定性。
相比之下,WSE-3的每一個核心均具備獨立編程的能力,并且針對神經網絡訓練和深度學習推理中所需的基于張量的稀疏線性代數運算進行了專門的優化。
這一特點使得研究團隊能夠在WSE-3的支持下,以前所未有的速度和規模高效地訓練和運行AI模型,同時避免了復雜分布式編程技巧的需求。
WSE-3配備的44GB片上SRAM內存均勻分布在芯片表面,使得每個核心都能在單個時鐘周期內以極高的帶寬(21 PB/s)訪問到快速內存,是當今地表最強GPU英偉達H100的7000倍。
而WSE-3的片上互連技術,更是實現了核心間驚人的214 Pb/s互連帶寬,是H100系統的3715倍。
CS-3可以配置為多達2048個系統的集群,可實現高達256 exaFLOPs的AI計算,專為快速訓練GPT-5規模的模型而設計。

大幅簡化并行編程復雜度
傳統的集群建設方式,通常需要數以萬計的GPU或AI加速器來協同解決某一問題。
在英偉達所構建的GPU集群中,這些集群通過Infiniband、以太網、PCIe和NVLink交換機等設備進行連接,其中大部分功率和成本均投入到芯片間的重新連接上。
此外,為了管理這些芯片間的互連、通信和同步,還需編寫大量的代碼,這無疑增加了并行編程的復雜性。
然而,Cerebras采用了一種與英偉達截然不同的方法。他們選擇保留整個晶圓,因此所需的芯片數量減少了50倍以上,從而顯著降低了互連和網絡的復雜性和成本。
在軟件層面,Cerebras提供了一套優化的軟件棧,其中包括內置的通信機制和自動化的內存管理。
這使得開發人員能夠使用更少的代碼實現復雜的模型,從而大幅降低了編程負擔。
這種軟硬件協同優化的策略,不僅簡化了開發過程,也加速了AI應用的開發和部署。
業務模式與傳統廠商存在顯著差異
傳統上,英偉達、AMD、英特爾等公司傾向于采用大型臺積電晶圓,并將其切割成更小的部分以生產芯片。
然而,Cerebras卻選擇了一種截然不同的路徑,它保留了晶圓的完整性。
在當前高度互聯的計算集群中,數以萬計的GPU或AI加速器協同工作以處理復雜問題。
Cerebras的策略將芯片數量減少50倍以上,從而顯著降低了互連和網絡成本,同時減少了功耗。
在英偉達GPU集群中,這些集群配備了Infiniband、以太網、PCIe和NVLink交換機,大量的電力和成本消耗在重新鏈接芯片上。
通過維持整個芯片的完整性,Cerebras有效地解決了這一問題。
憑借WSE-3,Cerebras繼續鞏固其作為全球最大單芯片生產者的地位。
這款芯片呈正方形,邊長達到21.5厘米,幾乎占據了整個300毫米硅片的面積。
將Cerebras的設計理念與拼圖游戲進行類比,可以清晰地揭示其創新之處。
傳統的芯片制造過程類似于將拼圖切成小塊并逐一拼接,而Cerebras的方法則更像是保持拼圖的完整性,使得各部件之間的連接更加緊密,從而提升了整體效率和性能。
這種前瞻性的設計理念為WSE-3芯片的成功提供了堅實的基石。
結尾:
綜合評估,WSE-3標志著人工智能芯片設計領域的新趨勢,它以單片規模之巨實現了性能與效率的顯著提升。
對于其他公司而言,若要復制此類產品,必須在晶圓制造、封裝互連、系統集成及軟件棧等多個領域投入長期的研發努力,并克服眾多技術難關。
Cerebras之所以能夠在市場中脫穎而出,其關鍵在于這些領域中所展現的持續創新能力及突破。
審核編輯:劉清
-
處理器
+關注
關注
68文章
20255瀏覽量
252295 -
晶圓
+關注
關注
53文章
5410瀏覽量
132293 -
晶體管
+關注
關注
78文章
10396瀏覽量
147760 -
AI芯片
+關注
關注
17文章
2128瀏覽量
36779 -
DDR5
+關注
關注
1文章
474瀏覽量
25735
原文標題:熱點丨最強AI芯片發布,Cerebras推出性能翻倍的WSE-3 AI芯片
文章出處:【微信號:World_2078,微信公眾號:AI芯天下】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
亞馬遜發布新一代AI芯片Trainium3,性能提升4倍

今日看點:高通發布云端AI芯片;艾為電子推出低功耗Hyper-Hall?芯片 高通發布云端AI芯片 近日,美國高通公
蘋果AI革命:M5芯片10核GPU、AI處理速度翻倍,Apple Glass在路上




 工商網監
工商網監
評論