") 谷歌模型訓(xùn)練軟件有哪些?谷歌模型訓(xùn)練軟件哪個(gè)好?
谷歌模型訓(xùn)練軟件有哪些?谷歌模型訓(xùn)練軟件哪個(gè)好?

谷歌在模型訓(xùn)練方面提供了一些強(qiáng)大的軟件工具和平臺(tái)。以下是幾個(gè)常用的谷歌模型訓(xùn)練軟件及其特點(diǎn):
1.TensorFlow:
特點(diǎn):TensorFlow 是谷歌開(kāi)源的一個(gè)廣泛使用的機(jī)器學(xué)習(xí)框架。它支持分布式訓(xùn)練,可以在多種硬件上運(yùn)行,包括 CPU、GPU 和 TPU。TensorFlow 提供了高級(jí)的編程接口,使得模型開(kāi)發(fā)更加靈活和高效。
適用場(chǎng)景:適合從研究到生產(chǎn)的各種機(jī)器學(xué)習(xí)項(xiàng)目,包括深度學(xué)習(xí)、強(qiáng)化學(xué)習(xí)等。
2.TensorFlow Extended (TFX):
特點(diǎn):TFX 是 TensorFlow 的一個(gè)擴(kuò)展,專(zhuān)注于機(jī)器學(xué)習(xí)工作流的管理和部署。它提供了一套組件和工具,用于數(shù)據(jù)驗(yàn)證、模型訓(xùn)練、模型評(píng)估和模型部署等階段。
適用場(chǎng)景:適合需要管理和自動(dòng)化機(jī)器學(xué)習(xí)工作流的企業(yè)級(jí)項(xiàng)目。
3.Colaboratory (Colab):
特點(diǎn):Colab 是一個(gè)基于云的 Jupyter 筆記本服務(wù),內(nèi)置了 TensorFlow 和其他機(jī)器學(xué)習(xí)庫(kù)。用戶(hù)可以在瀏覽器中編寫(xiě)和運(yùn)行代碼,無(wú)需在本地安裝任何軟件。此外,Colab 提供了免費(fèi)的 GPU 使用權(quán),對(duì)于需要加速計(jì)算的模型訓(xùn)練非常有用。
適用場(chǎng)景:適合快速原型設(shè)計(jì)、實(shí)驗(yàn)和模型開(kāi)發(fā),尤其對(duì)于初學(xué)者和需要快速迭代的項(xiàng)目。
4.TPU Pods:
特點(diǎn):TPU Pods 是谷歌的專(zhuān)用硬件,專(zhuān)為 TensorFlow 設(shè)計(jì)。它們結(jié)合了多個(gè) Tensor Processing Units (TPUs),提供了極高的計(jì)算性能,用于加速大規(guī)模的機(jī)器學(xué)習(xí)訓(xùn)練。
適用場(chǎng)景:適合需要高性能計(jì)算和大規(guī)模模型訓(xùn)練的項(xiàng)目,如圖像識(shí)別、自然語(yǔ)言處理等。
哪個(gè)谷歌模型訓(xùn)練軟件好?
選擇哪個(gè)模型訓(xùn)練軟件取決于你的具體需求。如果你是一個(gè)初學(xué)者或需要快速原型設(shè)計(jì),Colab 可能是一個(gè)很好的選擇,因?yàn)樗子谑褂们姨峁┝嗣赓M(fèi)的 GPU 資源。如果你正在進(jìn)行大規(guī)模的生產(chǎn)級(jí)項(xiàng)目,并需要高級(jí)的性能和靈活性,TensorFlow 和 TPU Pods 可能是更好的選擇。而如果你需要管理和自動(dòng)化整個(gè)機(jī)器學(xué)習(xí)工作流,TFX 可能更適合你。
在選擇模型訓(xùn)練軟件時(shí),還應(yīng)考慮你的團(tuán)隊(duì)和項(xiàng)目的具體需求、預(yù)算、硬件資源以及與其他工具和服務(wù)的集成能力。
-
谷歌
+關(guān)注
關(guān)注
27文章
6254瀏覽量
111407 -
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136954
發(fā)布評(píng)論請(qǐng)先 登錄
從訓(xùn)練到推理:大模型算力需求的新拐點(diǎn)已至

谷歌云發(fā)布最強(qiáng)自研TPU,性能比前代提升4倍

在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗(yàn)
ai_cube訓(xùn)練模型最后部署失敗是什么原因?
沐曦MXMACA軟件平臺(tái)在大模型訓(xùn)練方面的優(yōu)化效果

海思SD3403邊緣計(jì)算AI數(shù)據(jù)訓(xùn)練概述
恩智浦eIQ Time Series Studio工具使用教程之模型訓(xùn)練
請(qǐng)問(wèn)如何在imx8mplus上部署和運(yùn)行YOLOv5訓(xùn)練的模型?
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

數(shù)據(jù)標(biāo)注服務(wù)—奠定大模型訓(xùn)練的數(shù)據(jù)基石
標(biāo)貝數(shù)據(jù)標(biāo)注服務(wù):奠定大模型訓(xùn)練的數(shù)據(jù)基石

利用RAKsmart服務(wù)器托管AI模型訓(xùn)練的優(yōu)勢(shì)
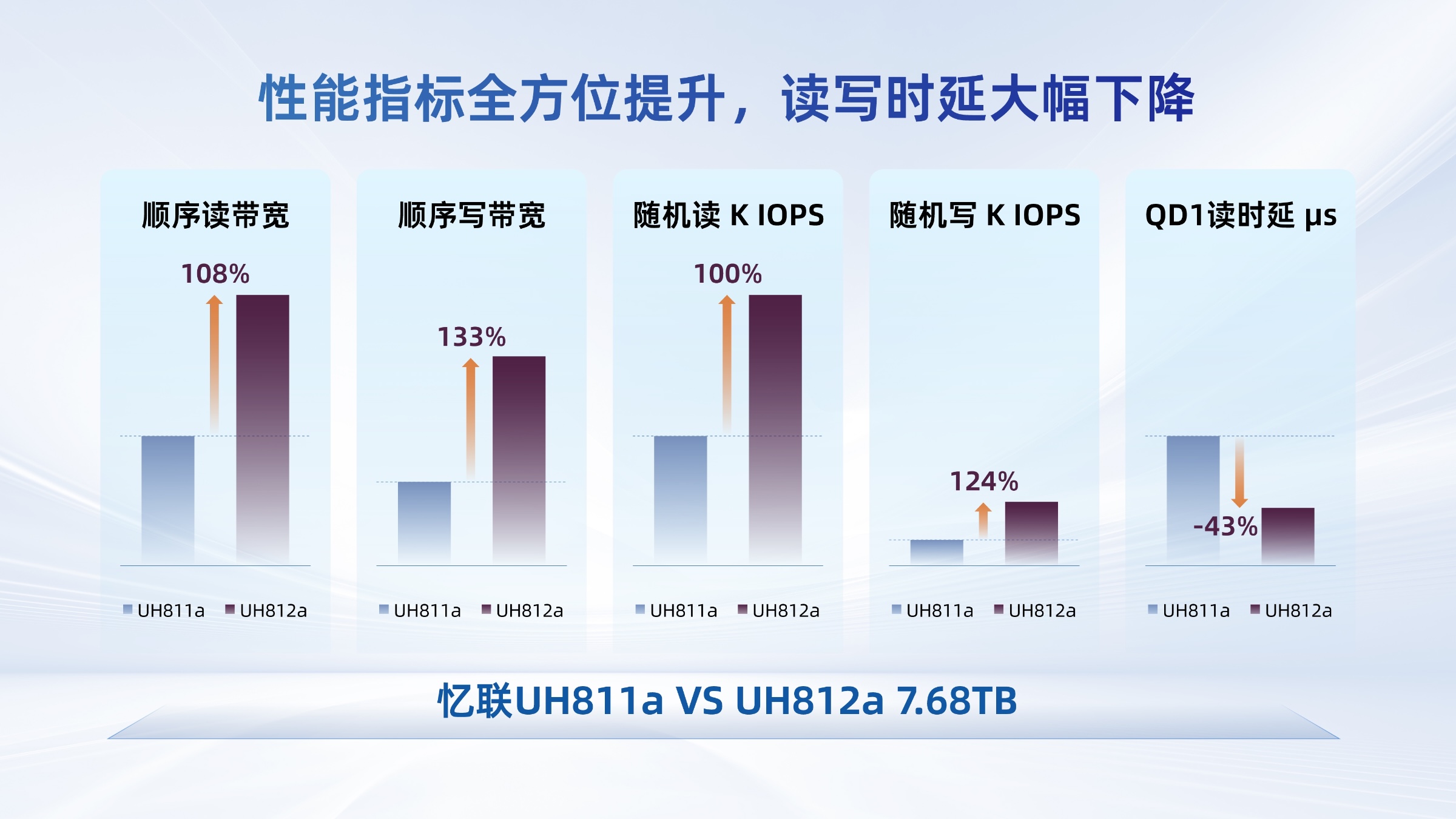
憶聯(lián)PCIe 5.0 SSD支撐大模型全流程訓(xùn)練



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論