 基于TPU-MLIR:詳解EinSum的完整處理過程!
基于TPU-MLIR:詳解EinSum的完整處理過程!

EinSum介紹
EinSum(愛因斯坦求和)是一個功能強大的算子,能夠簡潔高效地表示出多維算子的乘累加過程,對使用者非常友好。
本質上, EinSum是一個算子族,可以表示多種基礎操作,如矩陣乘法、Reduce。EinSum支持任意多的輸入,只要計算中只包含點乘(element-wise)、廣播(broadcast)、歸約求和(reduction sum)都可以使用EinSum來表示。以下給出一種將EinSum計算等價表達的流程:
- 將輸入的維度符號放入一個列表,移除重復元素后按升序排列;
- 對各輸入維度執行轉置操作,確保維度標識符按照升序對齊,實現維度對齊;
- 在缺失的維度上填充1(擴展維度),以便與第一步中定義的維度保持一致;
- 對所有輸入執行廣播點乘;
- 對那些不在輸出標識符中的維度執行累加操作;
- 利用轉置操作調整維度順序,使其與輸出標識符的順序一致。
下圖是以out = EinSum("ijk, lki-> li", in0, in1)為例,根據上述步驟進行等價轉換。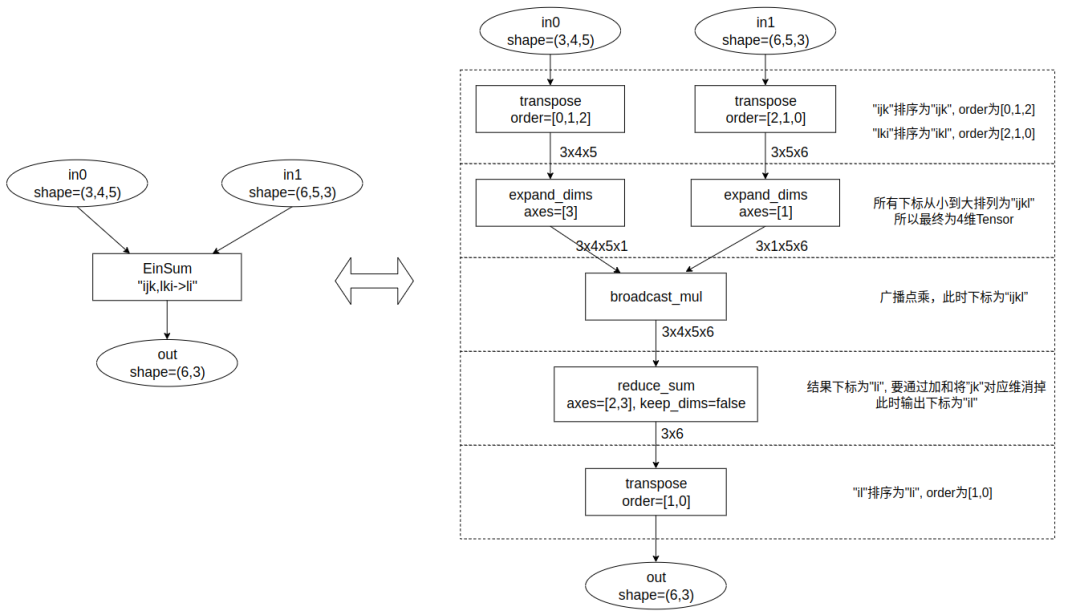
TPU-MLIR轉換
雖然使用上述流程可以完成對EinSum的計算轉換,但如果嚴格按照該流程執行,會帶來大量的Transpose和Reshape操作,這不僅會給TPU-MLIR的LayerGroup功能帶來挑戰,同時也難以顯式地識別出如矩陣乘法這類操作,從而無法充分利用硬件加速單元。因此,TPU-MLIR并未直接采用上述流程進行轉換。
接下來,我們將詳細介紹EinSum的完整處理過程。
前端接口
以下示例代碼摘自OnnxConverter.py文件,并附帶了注釋。代碼整體結構簡潔明了,我們可以看到,轉換函數目前僅支持兩個輸入的常見情況。特別需要注意的是公式的歸一化過程。由于EinSum的表達式可以使用任意非重復字符來表示下標,這雖然提高了可讀性,但也導致同一操作有多種不同的表示方式。歸一化操作就是將表達式字符重新映射,以字符'a'作為起始。例如,比如ij,jk->ik和dk,kv->dv都會映射為ab,bc->ac。
#https://pytorch.org/docs/1.13/generated/torch.einsum.html?highlight=einsum#torch.einsum
defconvert_einsum_op(self,onnx_node):
assert(onnx_node.op_type=="Einsum")
equation=onnx_node.attrs.get("equation").decode()
#公式歸一化
defnormalize_equation(equation_c):
equation=equation_c
new_equation=''
start='a'
translate_map={}
forsinequation:
ifs=='':
continue
elifnot((s>='a'ands<=?'z')or(s>='A'ands<=?'Z')):
translate_map[s]=s
elifsnotintranslate_map:
translate_map[s]=start
start=chr(ord(start)+1)
new_equation+=translate_map[s]
returnnew_equation
equation=normalize_equation(equation)
lhs=self.getOperand(onnx_node.inputs[0])#
#大多情況下rhs是Weight, self.getOp會先到Weight Map中查找;如果找不到,
#其會從Mutable Tensor中查找,然后返回對應的Value。
rhs=self.getOp(onnx_node.inputs[1])
new_op=top.EinsumOp(self.unranked_type,
[lhs,rhs],
mode=StringAttr.get(equation),
#設置loc信息,方便找到原圖對應算子
loc=self.get_loc("{}_{}".format(onnx_node.name,onnx_node.op_type)),
#將該算子插入到當前的block中
ip=self.mlir.insert_point).output
#將輸出放到MutableTensor列表中,供后面算子使用
self.addOperand(onnx_node.name,new_op)
內部轉換
TPU-MLIR目前支持了幾種常見的表達式,并根據不同的算子進行了優化轉換。所有的變換最終都利用了硬件的矩陣乘法加速單元,從而實現了對算子的有效加速。以下是部分代碼片段,該代碼來自tpu-mlir/lib/Dialect/Top/Canonicalize/Einsum.cpp,并在原有基礎上添加了注釋。
structConvertEinsum:publicOpRewritePattern{
usingOpRewritePattern::OpRewritePattern;
LogicalResultmatchAndRewrite(EinsumOpop,
PatternRewriter&rewriter)constoverride{
//目前只支持輸入個數為2或者輸入0為Weight的情況
if(op.getInputs().size()!=2||module::isWeight(op.getInputs()[0])){
llvm_unreachable("Notsupportnow.");
//returnfailure();
}
autonone=module::getNoneOp(op);
automode=op.getMode().str();
autolhs=op.getInputs()[0];
autorhs=op.getInputs()[1];
autolshape=module::getShape(lhs);
autorshape=module::getShape(rhs);
std::stringlname=module::getName(lhs).str();
std::stringrname=module::getName(rhs).str();
std::stringname=module::getName(op.getOutput()).str();
std::vectoroperands;
std::vectorattrs;
if(mode=="a,b->ab"){
//外積操作:可看作[a,1]x[1,b]的矩陣乘法操作
//lhs->ReshapeOp():shape=[a]toshape[a,1]
rewriter.setInsertionPointAfter(lhs.getDefiningOp());
//
autonewType=RankedTensorType::get({lshape[0],1},module::getElementType(lhs));
autoloc=NameLoc::get(rewriter.getStringAttr(lname+"_to2dim"));
autolrsOp=rewriter.create(loc,newType,ValueRange{lhs});
operands.push_back(lrsOp);
//rhs->ReshapeOp():shape=[b]toshape[1,b]
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
newType=RankedTensorType::get({1,rshape[0]},module::getElementType(rhs));
loc=NameLoc::get(rewriter.getStringAttr(rname+"_to2dim"));
autorrsop=rewriter.create(loc,newType,ValueRange{rhs});
operands.push_back(rrsop);
operands.push_back(none);
//用MatMulOp實現[a,1]x[1,b]=[a,b],并替換原來的EinSum操作
rewriter.setInsertionPoint(op);
automatmulOp=rewriter.create(op.getLoc(),op.getType(),operands,attrs);
op.replaceAllUsesWith(matmulOp.getOperation());
rewriter.eraseOp(op);
}elseif(mode=="abcd,cde->abe"){
//可以轉換成矩陣乘法[a*b,c*d]x[c*d,e]->[a*b,e]->[a,b,e]
//lhs_reshape_rst=[lhs_shape[0]*lhs_shape[1],lhs_shape[2]*lhs_shape[3]]
rewriter.setInsertionPointAfter(lhs.getDefiningOp());
autonewType=RankedTensorType::get({lshape[0]*lshape[1],lshape[2]*lshape[3]},module::getElementType(lhs));
autoloc=NameLoc::get(rewriter.getStringAttr(lname+"_to2dim"));
autolrsOp=rewriter.create(loc,newType,ValueRange{lhs});
operands.push_back(lrsOp);
newType=RankedTensorType::get({rshape[0]*rshape[1],rshape[2]},module::getElementType(rhs));
if(module::isWeight(rhs)){
rhs.setType(newType);
operands.push_back(rhs);
}else{
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
loc=NameLoc::get(rewriter.getStringAttr(rname+"_to2dim"));
autorrsop=rewriter.create(loc,newType,ValueRange{rhs});
operands.push_back(rrsop);
}
operands.push_back(none);
rewriter.setInsertionPoint(op);
newType=RankedTensorType::get({lshape[0]*lshape[1],rshape[2]},module::getElementType(op));
loc=NameLoc::get(rewriter.getStringAttr(name+"_matmul"));
automatmulOp=rewriter.create(loc,newType,operands,attrs);
autoorsOp=rewriter.create(op.getLoc(),op.getType(),ValueRange{matmulOp});
op.replaceAllUsesWith(orsOp.getOperation());
rewriter.eraseOp(op);
}elseif(mode=="abcd,bed->abce"){
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
//轉換過程
//batchmatmuldoesnotsupportbroadcast
//temporarysolution
//[h,k,c]->[1,h,k,c]->[b,h,k,c]
operands.push_back(lhs);
RankedTensorTypenewType;
//右操作數處理
if(autowOp=dyn_cast(rhs.getDefiningOp())){
//對于Weight來說,可以將數據復制,解決不支持廣播問題,[b,e,d]->[a,b,e,d]
autostorage_type=module::getStorageType(rhs);
assert(storage_type.isF32()&&"Todo,supoortmoreweighttype");
autodata=wOp.read_as_byte();
uint8_t*dptr;
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
std::vector<float_t>new_filter(newType.getNumElements(),0);
dptr=(uint8_t*)new_filter.data();
//實際的數據復制過程
for(int32_ti=0;i0];i++){
autooffset=i*data->size();
memcpy(dptr+offset,data->data(),data->size());
}
autonew_op=top::create(op,"folder",new_filter,newType);
wOp.replaceAllUsesWith(new_op.getDefiningOp());
operands.push_back(new_op);
rewriter.eraseOp(wOp);
}else{
//對于普通tensor,先reshape成[1,b,e,d]再用tile算子翻倍數據為[a,b,e,d]
//Reshape操作
autoloc=NameLoc::get(rewriter.getStringAttr(rname+"_reshape"));
newType=RankedTensorType::get({1,rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
autorrsop=rewriter.create(loc,newType,ValueRange{rhs});
//Tile操作,各維tile倍數[a,1,1,1]
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
loc=NameLoc::get(rewriter.getStringAttr(rname+"_tile"));
attrs.push_back(rewriter.getNamedAttr("tile",rewriter.getI64ArrayAttr({lshape[0],1,1,1})));
autotileOp=rewriter.create(loc,newType,ValueRange{rrsop},attrs);
attrs.clear();
operands.push_back(tileOp);
}
operands.push_back(none);
//這里使用了右操作數轉置的批量矩陣乘法算子,硬件可直接支持
//[a*b,c,d]*[a*b,e,d]^T->[a*b,c,e]
attrs.push_back(rewriter.getNamedAttr("right_transpose",rewriter.getBoolAttr(true)));
rewriter.setInsertionPoint(op);
automatmulOp=rewriter.create(op.getLoc(),op.getType(),operands,attrs);
op.replaceAllUsesWith(matmulOp.getOperation());
rewriter.eraseOp(op);
}elseif(mode=="abcd,ced->abce"){
//dumbimplementation
//轉置lhs[a,b,c,d]->[a,c,b,d]
//trans_shape=[lhs_shape[0],lhs_shape[2],lhs_shape[1],lhs_shape[3]]
rewriter.setInsertionPointAfter(lhs.getDefiningOp());
autoloc=NameLoc::get(rewriter.getStringAttr(lname+"_trans"));
autonewType=RankedTensorType::get({lshape[0],lshape[2],lshape[1],lshape[3]},module::getElementType(lhs));
attrs.push_back(rewriter.getNamedAttr("order",rewriter.getI64ArrayAttr({0,2,1,3})));
autotranOp=rewriter.create(loc,newType,ValueRange{lhs},attrs);
attrs.clear();
operands.push_back(tranOp);
//復制或Tilelhs:[c,e,d]->[a,c,e,d]
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
if(autowOp=dyn_cast(rhs.getDefiningOp())){
//Weight翻倍數據
autostorage_type=module::getStorageType(rhs);
assert(storage_type.isF32()&&"Todo,supoortmoreweighttype");
autodata=wOp.read_as_byte();
uint8_t*dptr;
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
std::vector<float_t>new_filter(newType.getNumElements(),0);
dptr=(uint8_t*)new_filter.data();
for(int32_ti=0;i0];i++){
autooffset=i*data->size();
memcpy(dptr+offset,data->data(),data->size());
}
autonew_op=top::create(op,"folder",new_filter,newType);
wOp.replaceAllUsesWith(new_op.getDefiningOp());
operands.push_back(new_op);
rewriter.eraseOp(wOp);
}else{
//rehshape+tile:[c,e,d]-reshape->[1,c,e,d]-tile->[a,c,e,d]
loc=NameLoc::get(rewriter.getStringAttr(rname+"_reshape"));
newType=RankedTensorType::get({1,rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
autorrsop=rewriter.create(loc,newType,ValueRange{rhs});
loc=NameLoc::get(rewriter.getStringAttr(rname+"_tile"));
attrs.push_back(rewriter.getNamedAttr("tile",rewriter.getI64ArrayAttr({lshape[0],1,1,1})));
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
autotileOp=rewriter.create(loc,newType,ValueRange{rrsop},attrs);
attrs.clear();
operands.push_back(tileOp);
}
operands.push_back(none);
//右操作數帶轉置批量矩陣乘法:[a*c, b, d]*[a*c, e, d]^T ->[a*c, b, e]->[a, c, b, e]
newType=RankedTensorType::get({lshape[0],lshape[2],lshape[1],rshape[1]},module::getElementType(op));
attrs.push_back(rewriter.getNamedAttr("right_transpose",rewriter.getBoolAttr(true)));
rewriter.setInsertionPoint(op);
loc=NameLoc::get(rewriter.getStringAttr(name+"_matmul"));
automatmulOp=rewriter.create(loc,newType,operands,attrs);
attrs.clear();
//[b,w,h,k]->[b,h,w,k]
attrs.push_back(rewriter.getNamedAttr("order",rewriter.getI64ArrayAttr({0,2,1,3})));
autotranBackOp=rewriter.create(op.getLoc(),op.getType(),ValueRange{matmulOp},attrs);
op.replaceAllUsesWith(tranBackOp.getOperation());
rewriter.eraseOp(op);
}elseif(mode=="abcd,abed->abce"||mode=="abcd,abde->abce"){
//lhs(abcd)*rhs(abed)^T->abce
//lhs(abcd)*rhs(abde)->abce
autonewType=RankedTensorType::get({lshape[0],lshape[1],lshape[2],rshape[2]},module::getElementType(op));
if(mode=="abcd,abde->abce"){
newType=RankedTensorType::get({lshape[0],lshape[1],lshape[2],rshape[3]},module::getElementType(op));
}
rewriter.setInsertionPoint(op);
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
operands.push_back(lhs);
operands.push_back(rhs);
operands.push_back(none);
if(mode=="abcd,abed->abce"){
//rhs(abed)^T
attrs.push_back(rewriter.getNamedAttr("right_transpose",rewriter.getBoolAttr(true)));
}
autoloc=NameLoc::get(rewriter.getStringAttr(name));
automatmulOp=rewriter.create(loc,newType,operands,attrs);
op.replaceAllUsesWith(matmulOp.getOperation());
attrs.clear();
rewriter.eraseOp(op);
} elseif(mode=="abcd,cde->abce"){
//lhs:
//abcd->acbd(pemute)
//rhs:
//cde->1cde(reshape)
//acde->acde(tile)
//matmul:
//lhs(acbd)*rhs(acde)=result(acbe)
//result:
//acbe->abce(pemute)
//success!
rewriter.setInsertionPointAfter(lhs.getDefiningOp());
autoloc=NameLoc::get(rewriter.getStringAttr(lname+"_trans"));
autonewType=RankedTensorType::get({lshape[0],lshape[2],lshape[1],lshape[3]},module::getElementType(lhs));
attrs.push_back(rewriter.getNamedAttr("order",rewriter.getI64ArrayAttr({0,2,1,3})));
autotranOp=rewriter.create(loc,newType,ValueRange{lhs},attrs);
attrs.clear();
operands.push_back(tranOp);
rewriter.setInsertionPointAfter(rhs.getDefiningOp());
if(autowOp=dyn_cast(rhs.getDefiningOp())){
autodata=wOp.read_as_byte();
uint8_t*dptr;
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
std::vector<float_t>new_filter(newType.getNumElements(),0);
dptr=(uint8_t*)new_filter.data();
for(int32_ti=0;i0];i++){
autooffset=i*data->size();
memcpy(dptr+offset,data->data(),data->size());
}
autonew_op=top::create(op,"folder",new_filter,newType);
wOp.replaceAllUsesWith(new_op.getDefiningOp());
operands.push_back(new_op);
rewriter.eraseOp(wOp);
}else{
loc=NameLoc::get(rewriter.getStringAttr(rname+"_reshape"));
newType=RankedTensorType::get({1,rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
autorrsop=rewriter.create(loc,newType,ValueRange{rhs});
loc=NameLoc::get(rewriter.getStringAttr(rname+"_tile"));
attrs.push_back(rewriter.getNamedAttr("tile",rewriter.getI64ArrayAttr({lshape[0],1,1,1})));
newType=RankedTensorType::get({lshape[0],rshape[0],rshape[1],rshape[2]},module::getElementType(rhs));
autotileOp=rewriter.create(loc,newType,ValueRange{rrsop},attrs);
attrs.clear();
operands.push_back(tileOp);
}
operands.push_back(none);
newType=RankedTensorType::get({lshape[0],lshape[2],lshape[1],rshape[2]},module::getElementType(op));
rewriter.setInsertionPoint(op);
loc=NameLoc::get(rewriter.getStringAttr(name+"_matmul"));
automatmulOp=rewriter.create(loc,newType,operands,attrs);
attrs.clear();
attrs.push_back(rewriter.getNamedAttr("order",rewriter.getI64ArrayAttr({0,2,1,3})));
autotranBackOp=rewriter.create(op.getLoc(),op.getType(),ValueRange{matmulOp},attrs);
op.replaceAllUsesWith(tranBackOp.getOperation());
rewriter.eraseOp(op);
}else{
llvm_unreachable("Einsumnotsupportthismodenow");
}
returnsuccess();
}
總結
TPU-MLIR對EinSum的實現雖然不完全,但已經足夠實用,能滿足目前常見網絡的需求。通過Converter直接表達式規范化,降低了編譯器優化或模式分析的復雜性。在算子分析時,我們不僅需要在計算上實現等價變換,還需充分了解實際硬件的特性。針對不同硬件架構及其對算子的支持情況,需具體分析以找到最佳實現方法。此外,我們可以看到在工程實踐中,人們更注重實用性和效率,在實現上不必追求完備,是要覆蓋實際應用場景即可。EinSum的轉換還有改進空間,我們也歡迎社區提出寶貴的建議并貢獻代碼。
-
前端
+關注
關注
1文章
243瀏覽量
18812 -
代碼
+關注
關注
30文章
4968瀏覽量
73977 -
TPU
+關注
關注
0文章
170瀏覽量
21660
發布評論請先 登錄
直擊英偉達腹地?谷歌TPU v7開放部署,催生OCS產業鏈紅利
什么是TPU?萬協通帶你看懂AI算力的“變形金剛”

AI芯片大單!Anthropic從博通采購100萬顆TPU v7p芯片
凱米斯科技:智監污水過程,賦能處理提質

速通音頻處理:掌握TTS播放、文件播放與錄音核心,實現完整功能

NICE指令的完整執行過程
擁抱DeepSeek開源生態| 算能TPU接入TileLang,集結北大復旦山大頂尖團隊!

基于碳納米材料的TPU導電長絲制備與性能研究

請問Einsum(opset7) 是否支持 OpenVINO??
HarmonyOS實戰:高德地圖定位功能完整流程詳解
邊緣計算網關在水產養殖尾水處理中的實時監控應用

TPU處理器的特性和工作原理
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命




 工商網監
工商網監
評論