") 如何用FPGA加速神經(jīng)網(wǎng)絡(luò)
如何用FPGA加速神經(jīng)網(wǎng)絡(luò)

之前介紹的項(xiàng)目《優(yōu)秀的 Verilog/FPGA開源項(xiàng)目介紹(十四)- 使用FPGA實(shí)現(xiàn)LeNet-5 深度神經(jīng)網(wǎng)絡(luò)模型》最后我們分析了,純FPGA實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)的缺點(diǎn),以及現(xiàn)在FPGA廠家的加速方案,這里引用一下:
到底純FPGA適不適合這種大型神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)?這個(gè)問題其實(shí)我們不適合回答,但是FPGA廠商是的實(shí)際操作是很有權(quán)威性的,現(xiàn)在不論是Intel還是Xilinx都沒有在自己傳統(tǒng)的FPGA上推廣AI,都是在基于FPGA的SoC上推廣(Vitis和OpenVINO,前者Xilinx后者Intel),總結(jié)來看就是:純 RTL 硬件設(shè)計(jì)不是AI的好選擇。特別是對(duì)于大規(guī)模網(wǎng)絡(luò),權(quán)重和中間結(jié)果需要存儲(chǔ)在外部存儲(chǔ)器中。并且數(shù)據(jù)迭代器會(huì)更加復(fù)雜。設(shè)計(jì)周期長(zhǎng),AI相關(guān)領(lǐng)域迭代速度快,綜上以上幾點(diǎn),可以很容易給你們指引一條道路。
目前主流的解決方案就是使用通用或?qū)S?a target="_blank">處理器來做控制工作,讓硬件來執(zhí)行計(jì)算(加速的概念),今天就介紹兩個(gè)針對(duì)以上解決方案的開源項(xiàng)目,這兩個(gè)項(xiàng)目是用FPGA進(jìn)行硬件加速的必備項(xiàng)目。
AI算法流程
在進(jìn)行項(xiàng)目介紹前,我們先介紹一下軟件架構(gòu)和工具集。這個(gè)后面會(huì)影響理解。
一個(gè)完整的深度學(xué)習(xí)框架中主要分為下面幾個(gè)流程:
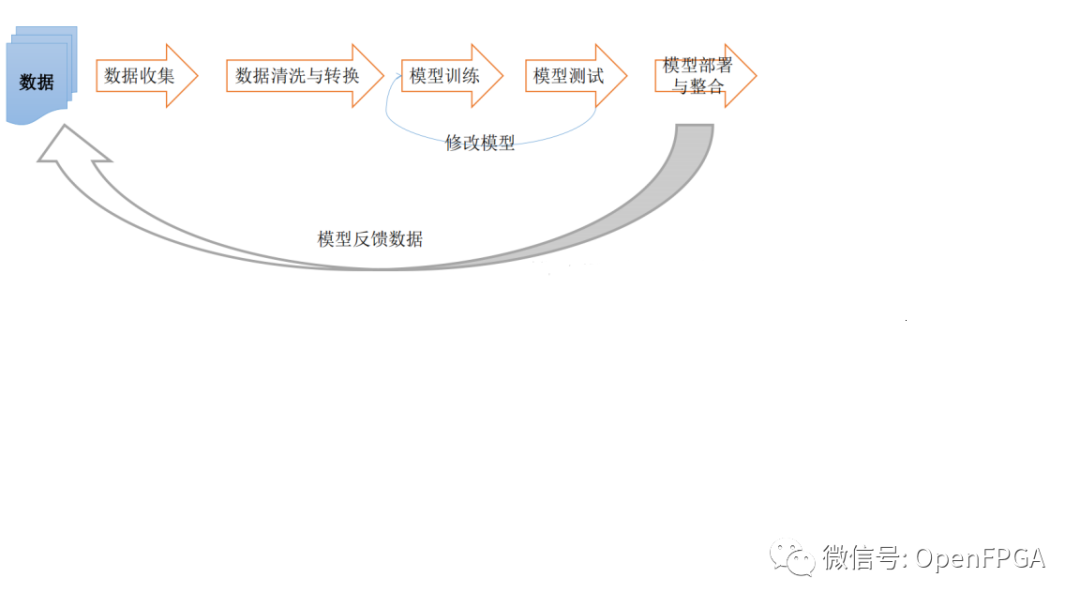
有一些是我們不太關(guān)心的部分(對(duì)于FPGA實(shí)現(xiàn)應(yīng)用),即數(shù)據(jù)收集等,所以上訴流程再簡(jiǎn)單分為幾個(gè)主要部分,即訓(xùn)練(training)和推理(inference)、部署(deployment)。
訓(xùn)練(Training)
使用訓(xùn)練模型(Caffe、TensorFlow、MxNET、ONNX等)根據(jù)訓(xùn)練數(shù)據(jù)得到相關(guān)的參數(shù)。舉個(gè)例子,我現(xiàn)在想要設(shè)備識(shí)別貓和狗,我首先需要收集貓和狗的圖片(這些圖片稱為訓(xùn)練數(shù)據(jù)集(training dataset)),但是這些數(shù)據(jù)集在進(jìn)行訓(xùn)練前要有標(biāo)簽(即每張照片是狗,那張照片是貓),選擇好訓(xùn)練模型后,將上訴數(shù)據(jù)給訓(xùn)練模型進(jìn)行訓(xùn)練,訓(xùn)練模型不是萬能的,雖然能通過訓(xùn)練不斷的優(yōu)化參數(shù),但是在訓(xùn)練完還不一定能達(dá)到你想要的識(shí)別率(比如100張圖片有50張能識(shí)別),接下來就是通過優(yōu)化參數(shù),讓另外50張錯(cuò)的也變成對(duì)的。這整個(gè)過程就稱之為訓(xùn)練(Traning)。
推理(Inference)
這個(gè)過程比較簡(jiǎn)單,就是把上面訓(xùn)練好的模型,去識(shí)別不是訓(xùn)練集里的圖片(這種圖片就叫做現(xiàn)場(chǎng)數(shù)據(jù)(live data)),如果對(duì)這些現(xiàn)場(chǎng)數(shù)據(jù)的識(shí)別也非常NICE,那么證明你的網(wǎng)絡(luò)訓(xùn)練的是非常好的,如果不是特別好,就需要把訓(xùn)練數(shù)據(jù)集增加,重復(fù)這一過程,直到現(xiàn)場(chǎng)數(shù)據(jù)也達(dá)到比較好的效果。把訓(xùn)練好的模型拿出來進(jìn)行現(xiàn)場(chǎng)實(shí)驗(yàn)推理的過程,稱為推理(Inference)。
部署(deployment)
部署的理解很簡(jiǎn)單,就是經(jīng)過上面兩個(gè)步驟的模型應(yīng)用,把它放在某個(gè)硬件平臺(tái)上運(yùn)行,這個(gè)過程稱之為部署(deployment)。
其實(shí)各大廠家推出自己的架構(gòu)/工具都是基于上訴流程,不同點(diǎn)就是會(huì)針對(duì)自家的硬件做細(xì)節(jié)優(yōu)化。
現(xiàn)在常見的模型推理部署框架有很多,比如:英特爾的OpenVINO,英偉達(dá)的TensorRT,谷歌的Mediapipe,Xilinx Vitis。
Intel FPGA OpenVINO
介紹
OpenVINO是Intel推出的用于優(yōu)化和部署 AI 推理的開源工具包。
提升計(jì)算機(jī)視覺、自動(dòng)語音識(shí)別、自然語言處理和其他常見任務(wù)中的深度學(xué)習(xí)性能
使用通過 TensorFlow、PyTorch 等流行框架訓(xùn)練的模型
減少資源需求并在從邊緣到云的一系列英特爾平臺(tái)上高效部署
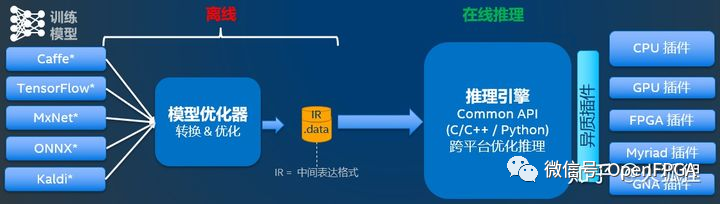
來源:知乎@火狐貍
上圖就是OpenVINO的組成,針對(duì)第一節(jié)的 AI算法流程 理解起來不是很難。其中,模型優(yōu)化器是線下模型轉(zhuǎn)換,推理引擎是部署在設(shè)備上運(yùn)行的AI負(fù)載。
因?yàn)镺penVINO還有針對(duì)自己CPU的架構(gòu),沒有對(duì)FPGA部分過多介紹,所以一些細(xì)節(jié)會(huì)在下一個(gè)項(xiàng)目介紹。
視頻介紹
關(guān)于OpenFPGA在FPGA方面的加速應(yīng)用,可以查看下面的兩個(gè)官方中文視頻介紹,這里就不再贅述。
Xilinx FPGA Vitis AI
2019年10月,Xilinx正式發(fā)布了統(tǒng)一開發(fā)軟件平臺(tái)Vitis。Vitis平臺(tái)無需用戶深入掌握硬件專業(yè)知識(shí),即軟件和算法自動(dòng)適配到Xilinx的硬件架構(gòu)。Xilinx Vitis AI是針對(duì)自家硬件平臺(tái)推出的針對(duì)AI模型的硬件實(shí)現(xiàn)。Vitis AI 提供的工具鏈能在數(shù)分鐘內(nèi)完成優(yōu)化、量化和編譯操作,在賽靈思器件上高效地運(yùn)行預(yù)先訓(xùn)練好的AI模型。
介紹
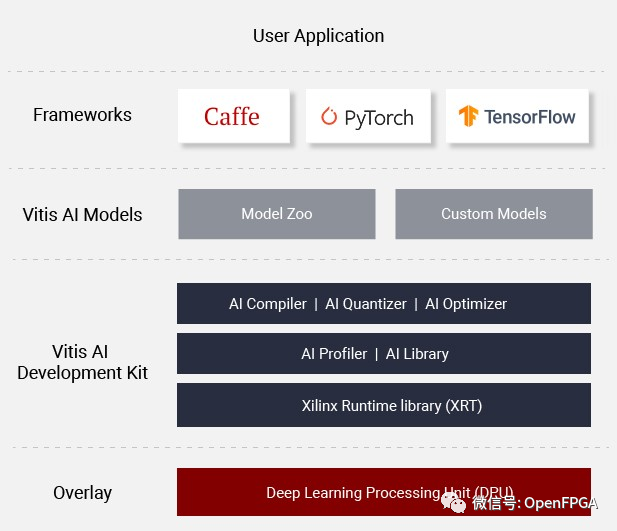
上圖就是Vitis AI的整體架構(gòu),主要分為AI Model Zoo、AI 優(yōu)化器、AI 量化器、AI 編譯器、AI 配置器、AI 庫(kù)、XRT、以及核心DPU。
整個(gè)流程和上圖類似,下面針對(duì)每個(gè)部分簡(jiǎn)單介紹(Intel的類似)。
AI Model Zoo
這個(gè)就是最流行框架 Pytorch、Tensorflow、Tensorflow 2 和 Caffe 的現(xiàn)成深度學(xué)習(xí)模型的集合,也就是我們可以簡(jiǎn)單及快速的進(jìn)行AI模型的訓(xùn)練和優(yōu)化。
AI 優(yōu)化器、AI 量化器、AI 編譯器
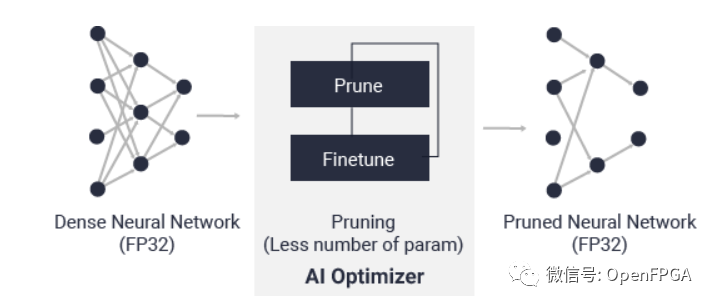
AI 優(yōu)化器功能簡(jiǎn)介
這三個(gè)作用就是將訓(xùn)練好的模型進(jìn)行優(yōu)化,其中AI 優(yōu)化器是在犧牲很少的精度情況下降模型的復(fù)雜度;AI 量化器的作用其實(shí)和FPGA的結(jié)構(gòu)有關(guān)(FPGA無法處理浮點(diǎn)數(shù)據(jù)),AI 量化器就是將32 位浮點(diǎn)權(quán)值和激活量轉(zhuǎn)換為 INT8 這樣的定點(diǎn)數(shù)據(jù)。
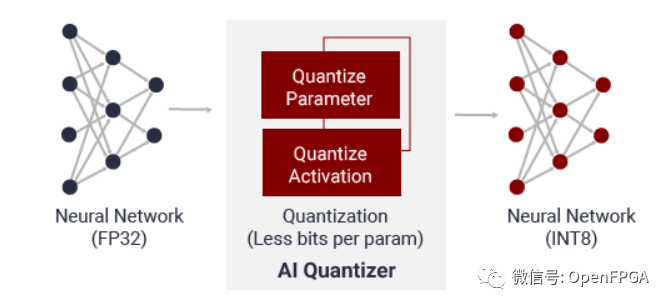
AI 量化器功能簡(jiǎn)介
AI 編譯器的作用就是將 AI 模型進(jìn)行高級(jí)優(yōu)化,主要包括指令集、數(shù)據(jù)流、層融合和指令排程等,并可盡量重復(fù)使用片上內(nèi)存。
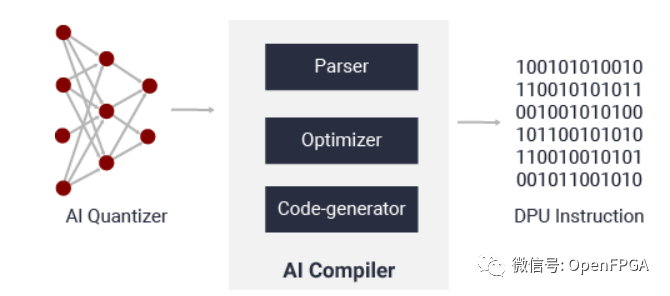
AI 編譯器功能簡(jiǎn)介
AI 配置器、AI 庫(kù)
AI 配置器功能簡(jiǎn)介
AI 配置器主要是輔助開發(fā)人員對(duì)AI模型的方案實(shí)施的效率和利用率進(jìn)行分析的性能分析器。
AI 庫(kù)功能簡(jiǎn)介
AI庫(kù)主要功能就是將DPU和上層進(jìn)行鏈接(基于帶有統(tǒng)一 API 的 Vitis AI Runtime 構(gòu)建)。
XRT、DPU
這兩個(gè)是Xilinx的“王牌”了,其中DPU大家應(yīng)該不陌生,是DNNDK的升級(jí)版本(DNNDK官方應(yīng)該已經(jīng)不維護(hù)了)。
XRT
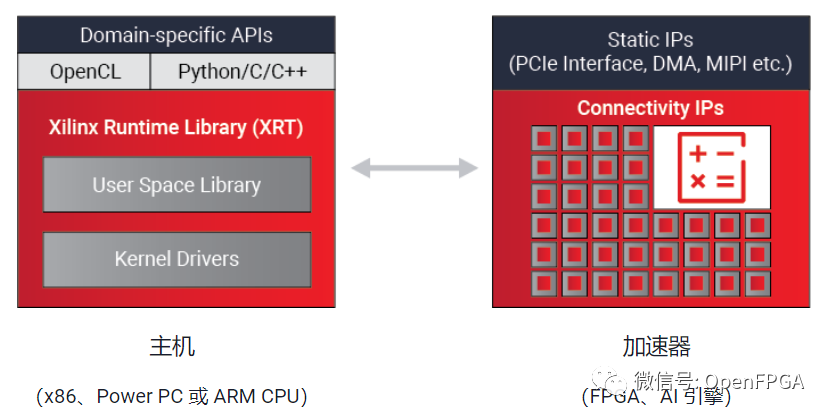
Xilinx 運(yùn)行時(shí)庫(kù) (XRT) 是 Vitis 統(tǒng)一軟件平臺(tái)和 Vitis AI 開發(fā)環(huán)境的一個(gè)重要組成部分,其可幫助開發(fā)人員繼續(xù)使用熟悉的編程語言(如 C/C++、Python 以及高層次特定域框架 TensorFlow 和咖啡等)在 Xilinx 靈活應(yīng)變的平臺(tái)上部署。
主要功能如下圖所示:
DPU
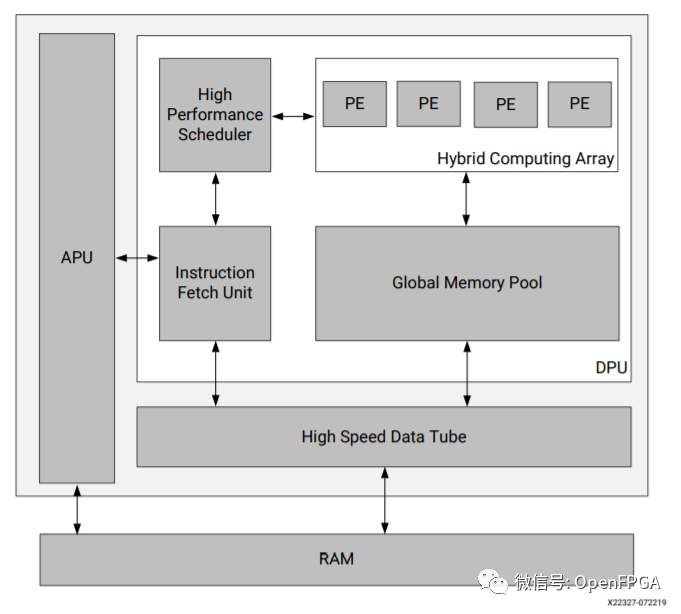
詳細(xì)介紹:PG338 PG366
Xilinx深度學(xué)習(xí)處理器單元 (DPU) 是一個(gè)專門用于卷積神經(jīng)網(wǎng)絡(luò)的可編程引擎。該單元包含寄存器配置模塊、數(shù)據(jù)控制器模塊和卷積計(jì)算模塊。在 DPU 中部署的卷積神經(jīng)網(wǎng)絡(luò)包括 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet 以及 FPN 等。


總結(jié)
今天介紹了兩個(gè)最重要的FPGA加速神經(jīng)網(wǎng)絡(luò)的開源項(xiàng)目,而且經(jīng)過幾年的發(fā)展越發(fā)穩(wěn)定,總結(jié)一下就是,如果想用FPGA加速神經(jīng)網(wǎng)絡(luò)就快點(diǎn)去看看吧,這里在簡(jiǎn)單推薦一下這兩個(gè)項(xiàng)目的入門開發(fā)板。
Intel C5P 開發(fā)板
Intel OpenVINO入門開發(fā)板
Xilinx Kria KV260開發(fā)板
最后,還是感謝各個(gè)大佬開源的項(xiàng)目,讓我們受益匪淺。后面有什么感興趣方面的項(xiàng)目,大家可以在后臺(tái)留言或者加微信留言,今天就到這,我是爆肝的碎碎思,期待下期文章與你相見。
審核編輯:湯梓紅
-
FPGA
+關(guān)注
關(guān)注
1660文章
22408瀏覽量
636210 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4838瀏覽量
107742 -
Xilinx
+關(guān)注
關(guān)注
73文章
2200瀏覽量
131116 -
開源
+關(guān)注
關(guān)注
3文章
4203瀏覽量
46122
原文標(biāo)題:想用FPGA加速神經(jīng)網(wǎng)絡(luò),這兩個(gè)開源項(xiàng)目你必須要了解
文章出處:【微信號(hào):Open_FPGA,微信公眾號(hào):OpenFPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【PYNQ-Z2申請(qǐng)】基于PYNQ的卷積神經(jīng)網(wǎng)絡(luò)加速
基于賽靈思FPGA的卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)設(shè)計(jì)
如何設(shè)計(jì)BP神經(jīng)網(wǎng)絡(luò)圖像壓縮算法?
如何移植一個(gè)CNN神經(jīng)網(wǎng)絡(luò)到FPGA中?
基于FPGA的神經(jīng)網(wǎng)絡(luò)的性能評(píng)估及局限性
如何用ARM和FPGA搭建神經(jīng)網(wǎng)絡(luò)處理器通信方案?
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
EdgeBoard中神經(jīng)網(wǎng)絡(luò)算子在FPGA中的實(shí)現(xiàn)方法是什么?
如何使用stm32cube.ai部署神經(jīng)網(wǎng)絡(luò)?
請(qǐng)問一下fpga加速神經(jīng)網(wǎng)絡(luò)為什么要用arm核呢
用FPGA去實(shí)現(xiàn)大型神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)
基于FPGA的SIMD卷積神經(jīng)網(wǎng)絡(luò)加速器
基于FPGA的神經(jīng)網(wǎng)絡(luò)硬件實(shí)現(xiàn)方法
FPGA加速神經(jīng)網(wǎng)絡(luò)的矩陣乘法




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論