") 論文遭首屆ICLR拒稿、代碼被過度優(yōu)化,word2vec作者Tomas Mikolov分享背后的故事
論文遭首屆ICLR拒稿、代碼被過度優(yōu)化,word2vec作者Tomas Mikolov分享背后的故事

除了表達(dá)自己獲得 NeurIPS 2023 時(shí)間檢驗(yàn)獎(jiǎng)的感想之外,Tomas Mikolo 還對(duì) NLP 和 ChatGPT 的現(xiàn)狀給出了自己的一些思考。
幾天前,NeurIPS 2023 公布了獲獎(jiǎng)?wù)撐模渲袝r(shí)間檢驗(yàn)獎(jiǎng)?lì)C給了十年前的 NeurIPS 論文「Distributed Representations of Words and Phrases and their Compositionality」。這項(xiàng)工作引入了開創(chuàng)性的詞嵌入技術(shù) word2vec,展示了從大量非結(jié)構(gòu)化文本中學(xué)習(xí)的能力,推動(dòng)了自然語言處理新時(shí)代的到來。
這篇論文由當(dāng)時(shí)都還在谷歌的 Tomas Mikolov、Ilya Sutskever、Kai Chen、Greg Corrado、Jeffrey Dean 等人撰寫,被引量超過 4 萬次。

不過,Word2vec 首篇論文是 Tomas Mikolov 等同一作者的「Efficient Estimation of Word Representations in Vector Space」。這篇論文的引用量也已經(jīng)接近 4 萬。

論文地址:https://arxiv.org/abs/1301.3781
近日,Tomas Mikolov 分享了論文背后更多的故事,包括被首屆 ICLR 拒稿以及之后的進(jìn)展等。

圖源:https://www.facebook.com/tomas.mikolov
以下為原貼內(nèi)容,我們做了不改變?cè)獾恼怼?/p>
我非常高興 word2vec 論文獲得了 NeurIPS 2023 時(shí)間檢驗(yàn)獎(jiǎng),這是我獲得的第一個(gè)最佳論文類型的獎(jiǎng)項(xiàng)。實(shí)際上,word2vec 原始論文在 2013 年首屆 ICLR 會(huì)議被拒絕接收了(盡管接收率很高),這讓我想到審稿人預(yù)測(cè)論文的未來影響是多么困難。
這些年,我聽到了很多關(guān)于 word2vec 的評(píng)論,正面的還有負(fù)面的,但至今沒有在網(wǎng)絡(luò)上認(rèn)真地發(fā)表過評(píng)論。我覺得研究界正在不斷地被一些研究人員的 PR 式宣傳淹沒,他們通過這樣的方式獲得他人的論文引用和注意力。我不想成為其中的一部分,但 10 年后,分享一些關(guān)于論文背后的故事可能會(huì)很有趣。
我經(jīng)常聽到的一個(gè)評(píng)論是,代碼很難理解,以至于有些人認(rèn)為是我故意地讓代碼不可讀。但我沒有那么邪惡,代碼最終被過度優(yōu)化了,因?yàn)槲业攘撕脦讉€(gè)月才被批準(zhǔn)發(fā)布它。我也試圖讓代碼更快更短。回想起來,如果當(dāng)時(shí)團(tuán)隊(duì)中沒有 Greg Corrado 和 Jeff Dean,我懷疑自己是否會(huì)獲得批準(zhǔn)。我認(rèn)為 word2vec 可能是谷歌開源的第一個(gè)廣為人知的 AI 項(xiàng)目。
在 word2vec 發(fā)布一年多后,斯坦福 NLP 小組的 GloVe 項(xiàng)目也引發(fā)了很大爭(zhēng)議。雖然該項(xiàng)目從我們的項(xiàng)目中復(fù)刻了很多技巧,但總感覺 GloVe 倒倒退了一步:速度較慢,還需要更多內(nèi)存,生成的向量質(zhì)量比 word2vec 低。然而,GloVe 是基于在更多數(shù)據(jù)上預(yù)訓(xùn)練的詞向量發(fā)布的,因而很受歡迎。之后,我們?cè)?fastText 項(xiàng)目中修復(fù)了相關(guān)問題,在使用相同數(shù)據(jù)進(jìn)行訓(xùn)練時(shí),word2vec 比 GloVe 好得多。
盡管 word2vec 是我被引用最多的論文,但我從未認(rèn)為它是我最有影響力的項(xiàng)目。實(shí)際上,word2vec 代碼最初只是我之前項(xiàng)目 RNNLM 的一個(gè)子集,我感覺 RNNLM 很快就被人們遺忘了。但在我看來,它應(yīng)該和 AlexNet 一樣具有革命性意義。
在這里,我列舉一些在 2010 年 RNNLM 中首次展示的想法:遞歸神經(jīng)網(wǎng)絡(luò)的可擴(kuò)展訓(xùn)練、首次通過神經(jīng)語言模型生成文本、動(dòng)態(tài)評(píng)估、字符和子詞級(jí)別的神經(jīng)語言建模、神經(jīng)語言模型自適應(yīng)(現(xiàn)在稱為微調(diào))、首個(gè)公開可用的 LM 基準(zhǔn)。
我發(fā)布了第一項(xiàng)研究,顯示當(dāng)一切正確完成時(shí),訓(xùn)練數(shù)據(jù)越多,神經(jīng)網(wǎng)絡(luò)就能比 n-gram 語言模型更勝一籌。這在今天聽起來是顯而易見的,但在當(dāng)時(shí)這被廣泛認(rèn)為是不可能的,甚至大多數(shù)谷歌員工都認(rèn)為,數(shù)據(jù)越多,除了 n-gram 和平滑技術(shù)外,其他任何工作都是徒勞的。
我很幸運(yùn)能在 2012 年加入谷歌 Brain 團(tuán)隊(duì),那里有很多大規(guī)模神經(jīng)網(wǎng)絡(luò)的「信徒」,他們?cè)试S我參與 word2vec 項(xiàng)目,展示了它的潛力。但我不想給人留下到這里就足夠完美的印象。在 word2vec 之后,作為后續(xù)項(xiàng)目,我希望通過改進(jìn)谷歌翻譯來普及神經(jīng)語言模型。我確實(shí)與 Franz Och 和他的團(tuán)隊(duì)開始了合作,在此期間我提出了幾種模型,這些模型可以補(bǔ)充基于短語的機(jī)器翻譯,甚至可以取代它。
其實(shí)在加入谷歌之前,我就提出了一個(gè)非常簡(jiǎn)單的想法,通過在句子對(duì)(比如法語 - 英語)上訓(xùn)練神經(jīng)語言模型來實(shí)現(xiàn)端到端的翻譯,然后在看到第一句話后使用生成模式生成翻譯。這對(duì)短句子效果很好,但在長(zhǎng)句子上就不那么奏效了。
我在谷歌 Brain 內(nèi)部多次討論過這個(gè)項(xiàng)目,主要是與 Quoc 和 Ilya,在我轉(zhuǎn)到 Facebook AI 后他們接手了這個(gè)項(xiàng)目。我感到非常意外的是,他們最終以「從序列到序列(sequence to sequence)」為名發(fā)表了我的想法,不僅沒有提到我是共同作者,而且在長(zhǎng)長(zhǎng)的致謝部分提及了谷歌 Brain 中幾乎所有的人,唯獨(dú)沒有我。那時(shí)是資金大量涌入人工智能領(lǐng)域的時(shí)期,每一個(gè)想法都價(jià)值連城。看到深度學(xué)習(xí)社區(qū)迅速變成某種權(quán)力的游戲,我感到很悲哀。
總之,多年來人們對(duì)語言模型的興趣增長(zhǎng)緩慢,但自從 ChatGPT 發(fā)布以來,人們對(duì)它的興趣呈爆炸式增長(zhǎng),看到這么多人終于將人工智能和語言聯(lián)系在一起,真的很酷。我們還沒有到達(dá)那個(gè)階段,我個(gè)人認(rèn)為我們需要有新的發(fā)現(xiàn)來突破神經(jīng)模型的泛化極限。我們無疑生活在一個(gè)激動(dòng)人心的時(shí)代。但是,讓我們不要過分信任那些想要壟斷基于數(shù)十位甚至數(shù)百位科學(xué)家辛勤工作的技術(shù),同時(shí)聲稱這一切都是為了人類的利益的人。
不過,Tomas Mikolov 的發(fā)言也讓人感嘆,他也要步 LSTM 之父 Jürgen Schmidhuber 的后塵嗎?
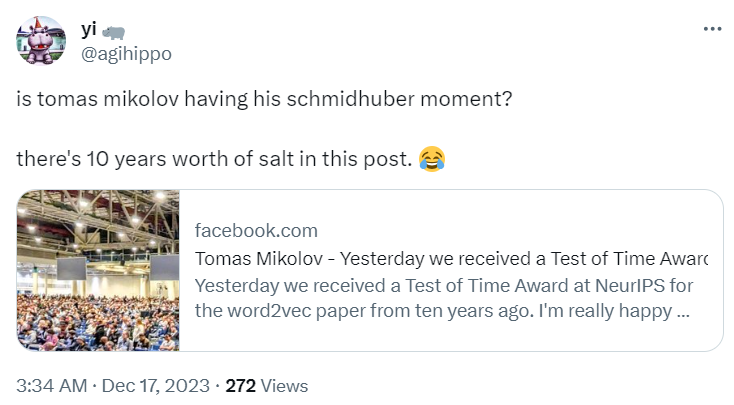
圖源:https://twitter.com/agihippo/status/1736107652407849208
你們?cè)趺纯茨兀?/p>
-
代碼
+關(guān)注
關(guān)注
30文章
4968瀏覽量
73974 -
nlp
+關(guān)注
關(guān)注
1文章
491瀏覽量
23280 -
ChatGPT
+關(guān)注
關(guān)注
31文章
1598瀏覽量
10269
原文標(biāo)題:論文遭首屆ICLR拒稿、代碼被過度優(yōu)化,word2vec作者Tomas Mikolov分享背后的故事
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
西井科技攜手同濟(jì)大學(xué) 三篇AI研究成果入選頂會(huì)ICLR 2026

后摩智能4篇論文入選人工智能頂會(huì)ICLR 2026
c語言中的代碼優(yōu)化
代碼里的青春——我與RT-Thread的故事

MediaTek多篇論文入選全球前沿國(guó)際學(xué)術(shù)會(huì)議
SAA認(rèn)證常見被拒原因分析:如何一次通過審核順利清關(guān)?

pdf轉(zhuǎn)換成word文檔格式亂了
通過優(yōu)化代碼來提高M(jìn)CU運(yùn)行效率
怎么把UI設(shè)計(jì)稿轉(zhuǎn)為代碼?在線UI設(shè)計(jì)工具一鍵生成!



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論