") 百度搜索內(nèi)容HTAP表格存儲系統(tǒng)
百度搜索內(nèi)容HTAP表格存儲系統(tǒng)

本文主要介紹百度搜索內(nèi)容存儲團(tuán)隊?wèi)?yīng)對海量互聯(lián)網(wǎng)數(shù)據(jù)分析計算需求時,在構(gòu)建HTAP表格存儲系統(tǒng)方向上的一些技術(shù)思考。
GEEK TALK
01
業(yè)務(wù)背景
百度搜索內(nèi)容存儲團(tuán)隊主要負(fù)責(zé)各類數(shù)據(jù),如網(wǎng)頁、圖片、網(wǎng)頁關(guān)系等,的在線存儲讀寫(OLTP)、離線高吞吐計算(OLAP)等工作。
原有架構(gòu)底層存儲系統(tǒng)普通采用百度自研表格存儲(Table)來完成數(shù)據(jù)的讀、寫、存工作,此存儲系統(tǒng)更偏向于OLTP業(yè)務(wù)場景。隨著近幾年大數(shù)據(jù)計算、AI模型訓(xùn)練的演進(jìn),對存儲系統(tǒng)OLAP業(yè)務(wù)場景的依賴越來越重,如數(shù)據(jù)關(guān)系分析、全網(wǎng)數(shù)據(jù)分析、AI樣本數(shù)據(jù)管理篩選。在OLTP存儲場景的架構(gòu)下,支持OLAP存儲需求對資源成本、系統(tǒng)吞吐、業(yè)務(wù)時效帶來了巨大挑戰(zhàn)。為此我們在百度自研表格存儲之外,結(jié)合業(yè)務(wù)實際workflow針對性優(yōu)化,增加構(gòu)建了一套符合業(yè)務(wù)需求的HTAP表格存儲系統(tǒng)。
以下我們將主要介紹在百度內(nèi)容HTAP表格存儲系統(tǒng)設(shè)計落地中的一些技術(shù)思考,文中的優(yōu)劣歡迎各位積極交流探討。
GEEK TALK
02
存儲設(shè)計
2.0 需求分析
整套存儲設(shè)計需要解決的核心問題是——如何在OLTP存儲系統(tǒng)中支持OLAP workflow?OLAP workflow在OLTP存儲系統(tǒng)上帶來的兩個最主要的問題是:嚴(yán)重的IO放大率、存算耦合。
嚴(yán)重的IO放大率。IO放大率主要來自兩方面,如下圖,數(shù)據(jù)行篩選、數(shù)據(jù)列篩選。
數(shù)據(jù)行篩選。在表格存儲中,數(shù)據(jù)按照主鍵從小到大排列,OLAP workflow根據(jù)條件篩選過濾出符合條件的數(shù)據(jù)行,會帶來嚴(yán)重的IO放大。
數(shù)據(jù)列篩選。表格存儲是寬表結(jié)構(gòu),業(yè)務(wù)在一次查詢中只會獲取部分列,但數(shù)據(jù)是以行結(jié)構(gòu)保存,需要獲取整行再提取出需要的字段,依舊會帶來嚴(yán)重的IO放大。
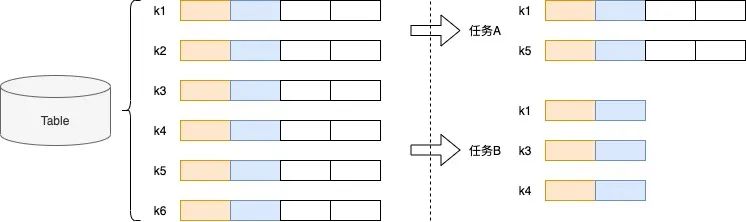
△圖2.1
存算耦合。存算耦合主要來自兩方面,如下圖,存儲節(jié)點資源冗余、存儲空間放大。
存儲節(jié)點資源冗余。在一個存儲節(jié)點中,OLTP vs OLAP占用的計算資源占比是3:7,為滿足OLAP需要,就需要對存儲節(jié)點進(jìn)行擴(kuò)容,然而存儲節(jié)點的擴(kuò)容又不僅僅是計算資源。同時,OLAP任務(wù)是間歇性的,就會造成忙時供給不足,閑時資源冗余等情況。
存儲空間放大。為支持每一個OLAP任務(wù)的數(shù)據(jù)訪問,存儲引擎需要為每一個workflow創(chuàng)建對應(yīng)的Snapshot,保證workflow完成前所依賴的所有數(shù)據(jù)文件均有效。當(dāng)OLAP workflow耗時過長時,會導(dǎo)致Compaction后數(shù)據(jù)文件無法及時清理的情況,造成存儲空間放大。
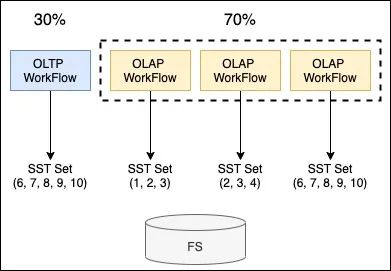
△圖2.2 Node
2.1 架構(gòu)設(shè)計
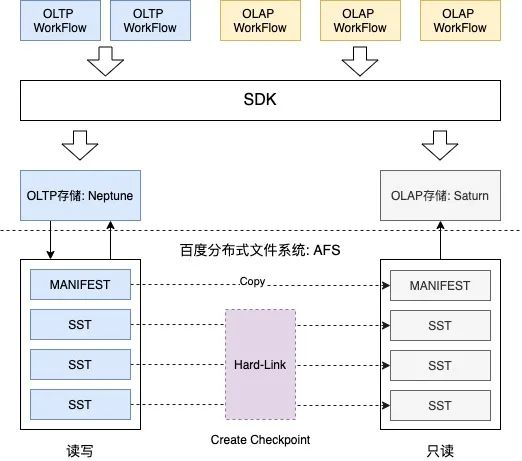
△圖2.3
1.架構(gòu)采用業(yè)界HTAP主流設(shè)計思想,將OLTP和OLAP workflow拆分到兩套存儲系統(tǒng)中,如F1 Lightning、ByteHTAP,在SDK層根據(jù)任務(wù)類型分發(fā)到不同的存儲系統(tǒng)中。
2.OLTP存儲系統(tǒng)——Neptune,采用Multi-Raft分布式協(xié)議組建存儲集群,采用本地磁盤(SSD/HDD等) + 百度分布式文件系統(tǒng)?AFS組成存儲介質(zhì)。
3.OLAP存儲系統(tǒng)——Saturn,Serverless?設(shè)計模式,無常駐Server,即用即加載,貼合OLAP workflow的不確定性和間歇性。
4.OLTP與OLAP存儲系統(tǒng)間,采用數(shù)據(jù)文件硬鏈的方式進(jìn)行數(shù)據(jù)同步,全版本替換,成本低、速度快,充分貼合Saturn Serverless設(shè)計模式。
如上架構(gòu)設(shè)計圖,可將OLTP與OLAP workflow拆分到兩套獨立的系統(tǒng)中,解決上述提到的存算耦合問題。
解決存儲空間放大問題。空間放大主要帶來的問題是存儲節(jié)點成本,Workflow分離的架構(gòu)將OLAP需要的數(shù)據(jù)文件采用AFS低成本存儲,減少了對存儲節(jié)點存儲空間的壓力。
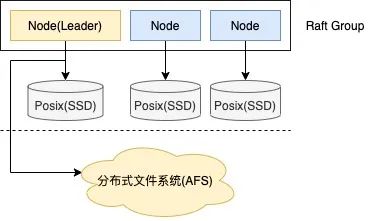
△圖2.4
OLAP存儲系統(tǒng)的數(shù)據(jù)寫入并沒有使用常見的log redo或raft learner模式,最主要還是在保證OLAP存儲系統(tǒng)的Serverless特性的同時,又能實時感知到OLTP系統(tǒng)的最新寫入結(jié)果。
解決存儲節(jié)點資源冗余問題。拆分后,分布式存儲節(jié)點將大量重型OLAP workflow轉(zhuǎn)移到OLAP存儲——Saturn中,將極大減少存儲節(jié)點的計算壓力。同時,OLAP存儲的Serverless設(shè)計模式又可貼合workflow的不確定性和間歇性。
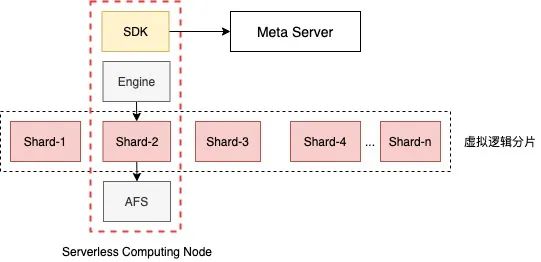
△圖2.5 Saturn Serverless模型
計算節(jié)點可以部署在任意計算集群中,如Map-Reduce、自研計算節(jié)點Pioneer等,在SDK中直接初始化存儲引擎,從AFS中訪問對應(yīng)分片的數(shù)據(jù)文件。計算節(jié)點可充分利用云原生系統(tǒng)(PaaS)的彈性資源,解決資源常駐冗余問題。
2.2 存儲引擎優(yōu)化思路
結(jié)合上面的分析以及設(shè)計思路,已有效地解決了存算耦合問題。在本節(jié)中,我們將重點介紹解決IO放大率問題的一些優(yōu)化思路。
2.2.1 數(shù)據(jù)行分區(qū)
數(shù)據(jù)行分區(qū)思想在很多OLAP存儲系統(tǒng)中很常見,如當(dāng)前比較流行的一些數(shù)據(jù)湖架構(gòu),ClickHouse、IceBerg等。在表格存儲中,數(shù)據(jù)行分區(qū)的好處是可以極大減少在數(shù)據(jù)行篩選過程中IO放大率。以下是我們在存儲引擎中支持?jǐn)?shù)據(jù)行分區(qū)的設(shè)計思路:
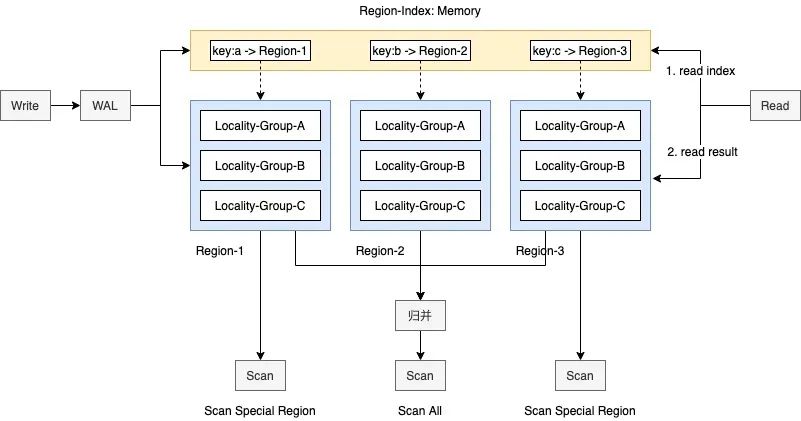
△圖2.6
數(shù)據(jù)行分區(qū)的思想在OLTP和OLAP存儲引擎中都有使用,OLTP存儲引擎以數(shù)據(jù)行分區(qū)構(gòu)建的數(shù)據(jù)文件可直接被OLAP存儲引擎加載,減少了OLAP存儲的數(shù)據(jù)構(gòu)建工作。
數(shù)據(jù)行分區(qū)在Write、Read、Scan場景下的處理流程分別為:
1.Write操作。Write時會根據(jù)請求中的特殊Region描述,如分區(qū)鍵,找到需要寫入的Region-Index和Region上下文,前者保存Key的分區(qū)索引信息,后者中保存實際數(shù)據(jù),操作記錄由WAL中保存。
2.Read操作。Read操作相比通常直接訪問數(shù)據(jù),需要多進(jìn)行一次分區(qū)索引訪問,為減少多一次訪問帶來的性能折損,我們將分區(qū)索引信息全內(nèi)存化。由于索引數(shù)據(jù)非常小,因此全內(nèi)存化是可接受的。
3.Scan操作。Scan操作相比之下沒有任何變更,但在Scan特殊分區(qū)場景下可大量減少IO放大。因為相比之前的行過濾模式,可直接跳過大量不需要的數(shù)據(jù)。
在業(yè)務(wù)存儲支持時,合理設(shè)置數(shù)據(jù)行分區(qū),可極大減少數(shù)據(jù)行篩選過程中的IO放大率。
2.2.2 增量數(shù)據(jù)篩選
在實際業(yè)務(wù)中,有很大一個場景時獲取近期(如近幾個小時、近一天)有值變化的數(shù)據(jù),常規(guī)的做法是Scan全量數(shù)據(jù),以時間區(qū)間作為過濾條件,篩選出符合條件的結(jié)果。但如此的篩選邏輯會帶來嚴(yán)重的IO放大,因為滿足條件的結(jié)果只占全量結(jié)果的一小部分。為此,我們在引擎層調(diào)整優(yōu)化Compaction時機(jī)以及調(diào)整篩選流程,減少增量數(shù)據(jù)篩選過程中需要訪問的數(shù)據(jù)文件集合,降低IO放大,業(yè)務(wù)提速。
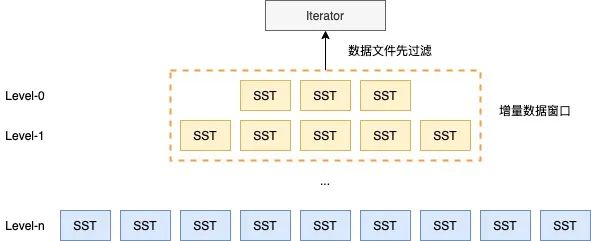
△圖2.7 LSMT
2.2.3 動態(tài)列結(jié)構(gòu)
在OLAP存儲引擎中,還存在一類訪問場景會帶來IO放大問題,數(shù)據(jù)列篩選。在表格存儲系統(tǒng)中,一個Key可以包含多個列族(Column Family),一個列族中可以包含任何多個數(shù)據(jù)字段,這些字段以行結(jié)構(gòu)存儲在同一物理存儲(Locality Group)中,當(dāng)篩選特定數(shù)據(jù)列時,需要進(jìn)行整行讀取,然后過濾出需要的字段,這也將帶來IO放大問題。
同時,OLAP workflow的訪問不確定性導(dǎo)致存儲層無法及時調(diào)整數(shù)據(jù)在物理存儲中的結(jié)構(gòu)。為此,我們引入動態(tài)列結(jié)構(gòu)的概念,在邏輯層對業(yè)務(wù)透明,在物理層根據(jù)近期OLAP workflow特性及時調(diào)整物理結(jié)構(gòu)。
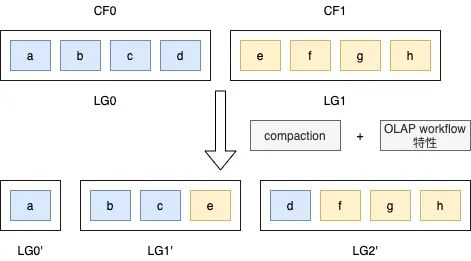
△圖2.8
如上圖,在邏輯存儲中,分為兩個LG,根據(jù)workflow特性,把業(yè)務(wù)常用的訪問字段在Compaction階段存放在同一物理存儲結(jié)構(gòu)中,反之,這樣可以減少字段篩選階段的IO放大率。
動態(tài)列結(jié)構(gòu)只在OLAP存儲引擎中生效,我們在原有OLAP存儲中引入workflow收集以及compaction任務(wù),將從OLTP存儲中同步的數(shù)據(jù)構(gòu)建成更適合OLAP場景的存儲結(jié)構(gòu)。
GEEK TALK
03
計算與調(diào)度
在本節(jié),我們將介紹在此HTAP表格存儲系統(tǒng)基礎(chǔ)上,如何設(shè)計實現(xiàn)任務(wù)計算和調(diào)度系統(tǒng),簡化業(yè)務(wù)使用成本,提升業(yè)務(wù)效率。
在大量搜索內(nèi)容OLAP workflow中,從表格存儲系統(tǒng)中提取篩選數(shù)據(jù)只占全部任務(wù)的一小部分,大量任務(wù)需要對數(shù)據(jù)進(jìn)行加工處理得到需要的結(jié)果。常規(guī)的做法是多任務(wù)串聯(lián),這樣做的缺陷是大量中間臨時數(shù)據(jù)存儲開銷。
為此我們?yōu)镠TAP表格存儲系統(tǒng)構(gòu)建了一套計算與調(diào)度系統(tǒng),系統(tǒng)兩大特點:任務(wù)開發(fā)SQL化、數(shù)據(jù)處理FaaS化。
3.1 SQL化與FaaS化
我們充分貼合上述存儲系統(tǒng)特性,自研了一套數(shù)據(jù)查詢語言——KQL,KQL類似于SQL Server語法。同時,又結(jié)合存儲系統(tǒng)特性以及計算框架,支持一些特殊語言能力,最主要的是能支持原生FaaS函數(shù)定義,當(dāng)然也支持外部FaaS函數(shù)包依賴。
如下是一段KQL語句例子以及說明:
function classify = { #定義一個Python FaaS函數(shù) def classify(cbytes, ids): unique_ids=set(ids) classify=int.from_bytes(cbytes, byteorder=‘little’, signed=False) while classify != 0: tmp = classify & 0xFF if tmp in unique_ids: return True classify = classify 》》 8 return False } declare ids = [2, 8]; declare ts_end = function@gettimeofday_us(); # 調(diào)用Native Function獲取時間 declare ts_beg = @ts_end - 24 * 3600 * 1000000; # 四則運(yùn)算 select * from my_table region in timeliness # 利用存儲分區(qū)特性,從my_table中的timeliness分區(qū)獲取數(shù)據(jù) where timestamp between @ts_beg and @ts_end # 利用存儲增量區(qū)間特性,篩選增量數(shù)據(jù) filter by function@classify(@cf0:types, @ids) # 在Filter階段調(diào)用自定義FaaS函數(shù) convert by json outlet by row; desc: # 對計算框架進(jìn)行特殊描述 --multi_output=true;
3.2 任務(wù)生成與調(diào)度
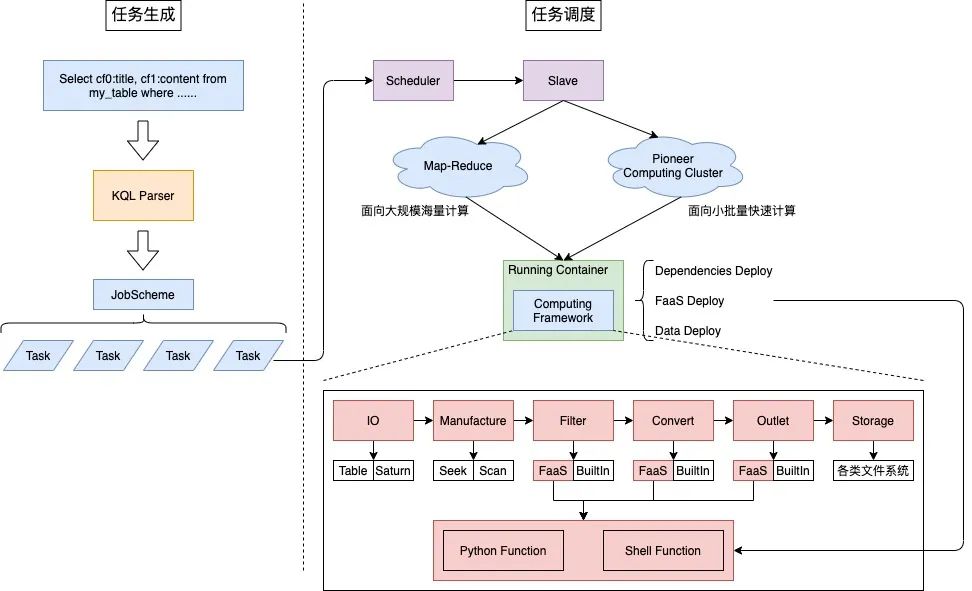
1.任務(wù)生成。在任務(wù)生成階段將KQL語句解析優(yōu)化成相關(guān)的調(diào)度任務(wù),一個Job包含多個Task。
2.任務(wù)調(diào)度。
任務(wù)調(diào)度的計算節(jié)點可以是Map-Reduce,也可以是自研計算集群Pioneer,負(fù)責(zé)不同計算場景。
任務(wù)運(yùn)行容器負(fù)責(zé)數(shù)據(jù)依賴部署和運(yùn)行計算框架。
計算框架采用插件化設(shè)計思想,依托KQL語言進(jìn)行差異化描述。計算框架的最大特點是,可在數(shù)據(jù)處理節(jié)點執(zhí)行用戶自定義FaaS函數(shù)。
GEEK TALK
04
總結(jié)
當(dāng)前HTAP表格存儲系統(tǒng)已在全網(wǎng)網(wǎng)頁數(shù)據(jù)離線加速、AI模型訓(xùn)練數(shù)據(jù)管理、圖片存儲以及各類在線離線業(yè)務(wù)場景落地,數(shù)據(jù)存儲規(guī)模達(dá)》15P,業(yè)務(wù)提速》50%。
與此同時,隨著大模型時代的到來,對存儲系統(tǒng)帶來了更多的挑戰(zhàn),我們也將繼續(xù)深度優(yōu)化,設(shè)計更高性能、高吞吐的HTAP表格存儲系統(tǒng)。
-
耦合
+關(guān)注
關(guān)注
13文章
607瀏覽量
103397 -
存儲系統(tǒng)
+關(guān)注
關(guān)注
2文章
433瀏覽量
41891 -
大模型
+關(guān)注
關(guān)注
2文章
3648瀏覽量
5177
原文標(biāo)題:百度搜索內(nèi)容HTAP表格存儲系統(tǒng)
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄

百度搜索、文庫等全新升級!以智能體為支點,撬動時代紅利

發(fā)現(xiàn)百度搜索頁的網(wǎng)站前加了圖標(biāo)
如何消滅百度搜索的廣告
百度回應(yīng)搜索引擎半數(shù)文章出自百家號:屬于特例
百度、英偉達(dá)聯(lián)合舉辦搜索創(chuàng)新大賽 搜索引擎變革 搜索+AI
百度攜手 NVIDIA 舉辦“第二屆百度搜索創(chuàng)新大賽”火熱進(jìn)行中,五大賽道等你挑戰(zhàn)!

百度搜索exgraph圖執(zhí)行引擎設(shè)計與實踐分享



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論