 從HumanEval到CoderEval: 你的代碼生成模型真的work嗎?
從HumanEval到CoderEval: 你的代碼生成模型真的work嗎?

本文主要介紹了一個名為CoderEval的代碼生成大模型評估基準,并對三個代碼生成模型(CodeGen、PanGu-Coder和ChatGPT)在該基準上的表現進行了評估和比較。研究人員從真實的開源項目中的選取了代碼生成任務來構建CoderEval,并根據對外部依賴的程度為標準將這些任務分為6個等級、根據生成的目標分為3類生成任務,以更多維地評估不同大模型在不同上下文場景中的生成效果。
實驗結果表明,這三個模型在生成自包含函數方面的效果明顯優于其他任務,但實際項目中的函數大部分依賴不同程度的上下文信息,因此提高模型對上下文信息的考慮和利用能力對于代碼生成技術的實際可用性非常重要。該工作由北京大學和華為云Paas技術創新LAB合作完成,論文已經被軟件工程頂會ICSE 2024錄用。

一.從HumanEval到CoderEval
就像ImageNet之于圖像識別,Defects4J之于缺陷檢測,在以工具和方法為主要貢獻的研究領域中,一個被廣泛接受和采用的評估數據集及其配套的基準指標,對該領域的研究和發展至關重要。一方面,評估方式作為度量尺,可以在同一維度上起到橫向對比各類方法的水平,并估計距離成熟實用的差距;另一方面,評估方式作為風向標,直接指導著各種方法共同的優化和迭代目標,決定了研究者們前進的方向。
在代碼生成領域,當前最廣泛被使用的是OpenAI在Codex論文中開源的HumanEval,該基準測試集由164道由OpenAI工程師手動編寫的編程任務組成,以一定程度上確保與訓練集的不重疊性。初版的HumanEval僅支持Python語言,每個編程任務包括了任務描述、參考代碼、若干測試樣例等。近期有部分研究者將HumanEval擴展到多種編程語言,例如:清華大學CodeGeex團隊基于HumanEval開源了HumanEval-X,將HumanEval擴展到C++、Java、JavaScript、Go等語言;于2022年8月19日發布在arXiv上發布的一篇論文提出了MultiPL-E,將HumanEval擴展到了18種語言。
然而,HumanEval本身存在一些問題,這些問題使得它并不適合成為代碼生成任務的一個評估平臺,特別是對于以實際開發為目標的代碼生成研究和工具。基于HumanEval進行擴展的一類工作僅僅是將HumanEval中的任務描述、參考代碼、測試樣例以及執行環境等翻譯或適配到了其他語言,實質上并未解決HumanEval自身存在的一些問題。那么,這些問題有哪些呢?經過對HumanEval中的任務和測試樣例、以及多個模型生成結果的人工檢視,我們主要歸納出以下問題:
1.領域單一,僅覆蓋了語言本身基礎的編程知識,如數據結構操作、簡單算法等;
2.任務本身過于簡單,參考代碼均為自包含的單一函數,并未考慮復雜類型、自定義類型、三方庫、跨過程調用等情況;
根據我們對GitHub倉庫數據的統計,HumanEval所對應的自包含單一函數在Top 100的Python項目中只占11.2%,在Top 100的Java項目中只占21.3%,因此,HumanEval可能實際上無法準確反映代碼生成模型在實際項目級開發中的表現。
針對HumanEval的限制和不足,我們提出了CoderEval,一個面向真實場景和實際用戶的代碼生成模型可用性評測系統。CoderEval在一定程度上解決了當前被廣泛使用的評測基準的問題,主要體現在以下幾點:
1.直接來源于真實的開源項目,覆蓋多個領域,從而可以全面評估代碼生成在不同領域中的表現;
2. 考慮了復雜數據類型或項目代碼中開發者自定義的類型,支持面向對象特性和跨過程調用;
3. 盡量保證覆蓋率和完備性,從而在一定程度上降低測試誤報率。
綜上所述,相比于HumanEval,CoderEval與實際開發場景中的生成任務更加對齊,在基于大模型的代碼生成工具逐步落地并商業化的背景下,可能更加真實地反映并比較不同模型在實際落地為工具之后的開發者體驗。接下來,我們將簡要介紹CoderEval的組成部分、構建過程以及使用方法。
CoderEval論文目前已被ICSE2024接收:
https://arxiv.org/abs/2302.00288
CoderEval-GitHub目前已開源:
https://github.com/CoderEval/CoderEval
二. CoderEval:面向實際開發場景的代碼生成模型評估

CoderEval組成部分
整體而言,CoderEval主要由三部分組成:
1.生成任務:以函數/方法為基本單位的代碼生成任務,包括任務描述(即自然語言注釋)、函數簽名、參考代碼(即原始代碼實現)、所在文件所有上下文代碼、所在項目其他文件內容等;
2. 測試代碼:針對某一編程任務的單元測試,一個編程任務可能對應一到多個測試文件、一到多個測試方法,以及附加的測試數據(如操作文件的編程任務中的文件等);
3. 測試環境:由于CoderEval中的函數/方法允許使用自定義類型、調用語言標準庫或三方庫、調用項目中其他方法等,因此需要在配置好所在項目的環境中執行。為此,CoderEval基于Docker構建了沙箱測試環境,其中包含了所有被測項目及其依賴,并且附有單一入口的自動化執行程序。此測試環境預計將以線上服務的形式提供。
CoderEval構建過程

圖1 CoderEval的構建過程
圖1展示了針對某一種編程語言(目標語言)構建CoderEval的一般性的過程,主要分為三個部分:
1.目標選取:從GitHub或CodeHub選擇目標語言為主的項目中的高質量目標函數/方法,作為測試任務
2. 數據收集:針對每個候選測試任務,分析和收集目標函數/方法的元信息、自身信息、測試信息等
3. 環境構建:準備目標項目和依賴,為測試代碼提供執行環境,并通過執行測試驗證測試代碼和目標代碼的正確性
作為第一個版本,CoderEval首先支持了兩大語言:
? CoderEval4Python:包含來自43個項目的230個生成任務
? CoderEval4Java:包含來自10個項目的230個生成任務
為了真實反映代碼生成模型在實際項目開發中的效果和價值,我們需要從真實、多元的開源項目中選取高質量的生成任務,并配備盡可能完善的測試。為此,我們首先爬取了GitHub上Python和Java項目的所有標簽,根據最頻繁的14個標簽和標星數篩選出若干項目,然后抽取出項目中所有的測試代碼以及被測函數/方法,僅保留符合以下全部條件的部分:
?并非以測試為目的的、deprecated的、接口形式的函數/方法
?包含一段英文自然語言描述作為函數/方法級注釋
?可以在測試環境中正確執行并通過原始測試
經過這些篩選保留下來的函數/方法,再經過人工篩選和程序分析,構成了CoderEval中的代碼生成任務,每個生成任務提供的信息有:
?元信息(Meta):所在項目地址、文件路徑、行號范圍等
?自身信息(Native):該函數/方法的原始注釋、簽名、代碼等
?上下文信息(Context,可選):所在文件內容、可訪問上下文信息、所使用上下文信息、運行級別分類等
?測試信息(Test):人工標注的自然語言描述、在原始代碼上的若干測試樣例等
CoderEval使用方法
CoderEval支持函數/方法塊級生成(Block Generation):根據注釋形式的任務描述和/或函數簽名,生成實現對應功能的完整函數體。
CoderEval支持的指標:基于運行的指標(Comparison-based Metrics)。與HumanEval一致,我們同樣采取了Pass@k作為測試指標,從而評估所生成代碼實際的運行效果,允許模型生成不同版本的實現。
CoderEval支持更細粒度的評估:
1. 上下文感知能力評估:我們在研究中發現,對于非自包含函數/方法,其代碼實現中的外部依賴信息對于其功能和行為非常關鍵。因此,模型的上下文感知能力(Context-awareness,即正確生成外部依賴信息的能力)是另一個重要指標。CoderEval提供了生成任務所在項目以及文件內容可作為輸入,原始代碼中實際用到的上下文信息作為期望輸出,因此,可以分析并計算生成代碼中上下文信息的準確率以及召回率,作為上下文感知能力的評估指標。
2. 分級評估:如圖2所示,依據所依賴的上下文信息,CoderEval進一步將生成任務分成了6個級別(self_contained、slib_runnable、plib_runnable、class_runnable、project_runnable),代表所對應代碼可執行的環境(標準庫、第三方庫、當前文件、當前項目等)。CoderEval支持更細粒度地測試和分析模型在每個級別上的生成能力,從而可以全面地分析當前模型的不足和待優化的方向(如引入課程學習、針對性微調、上下文可感知度的針對性提升等)。
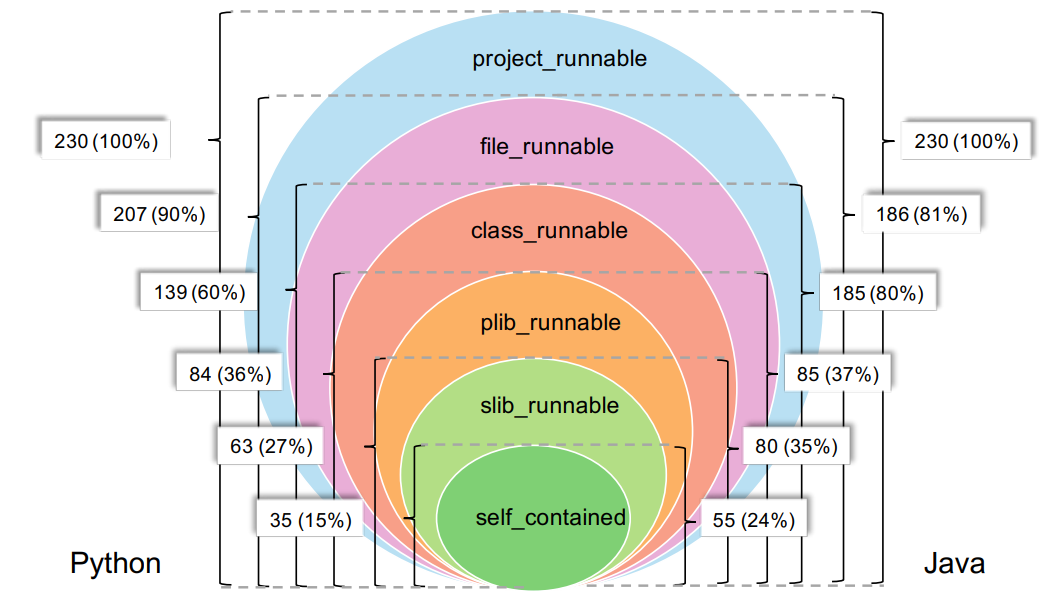
圖2 CoderEval中按依賴級別的數據分布
3. Prompt評估:CoderEval同時提供了原始注釋和開發者另外標注的代碼功能描述,從而研究模型記憶效應、Prompt形式、Prompt質量對不同模型的影響。
由于CoderEval源于實際的開源項目,并且我們無法精確獲得或控制各個模型訓練數據,因此可能無法避免存在因模型的記憶效應和復制機制產生的誤差。CoderEval緩解此類誤差的主要措施包括:
1.為所有任務補充了人工改寫的注釋替代原注釋,該部分可確保不存在于訓練集中。為此,我們同時會測試。
2. 可增大采樣次數并綜合基于運行的指標和基于比較的指標進行分析,從而分析模型是否能實現與原代碼不同、但又可通過測試的方案。
CoderEval實測結果
我們測試了工業界為主提出的、具有代表性的三個模型在CoderEval上的表現,被測模型包括:
1.CodeGen(Salesforce):采用GPT-2架構,在自然語言上先進行預訓練,再在多種編程語言混合語料上繼續訓練,最后在單一編程語言上進行微調。
2. PanGuCoder(Huawei):基于PanGu-alpha架構,采用<自然語言描述, 程序語言代碼>對的形式和多階段預訓練方法,專注于Text2Code任務,對中文支持較好。
3. ChatGPT(OpenAI):基于GPT-3.5系列模型使用人類反饋進行微調,可以根據用戶的指令或問題來生成代碼。
部分實驗結果如下:
1. 如表1所示,在CoderEval和HumanEval上,ChatGPT的效果都大幅超出其他兩個模型,原因可能來自于更大的模型規模、更充分的訓練度、更優的超參數等方面。
表1 三個模型在CoderEval上和HumanEval上的
總體效果對比
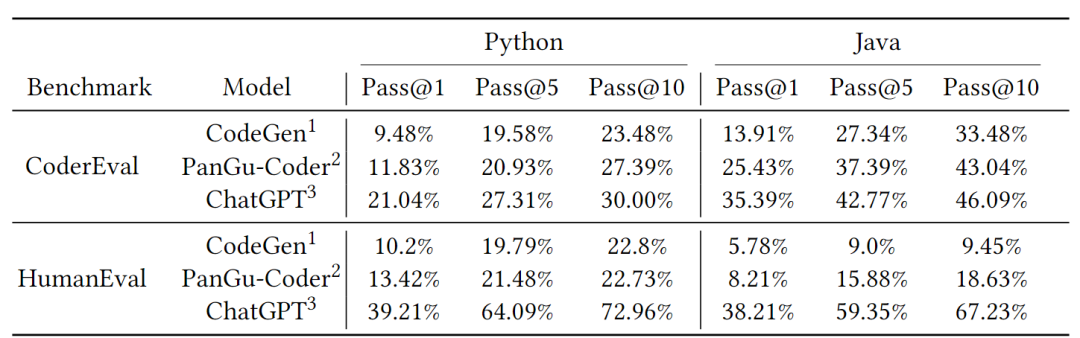
2. 如表1所示,在HumanEval上,ChatGPT的效果更是大幅超過其他模型,幅度要遠大于在CoderEval上三個模型的差距。考慮到HumanEval的局限性,這一結果從側面表明HumanEval可能已經不適合作為單一的代碼生成Benchmark。
3. 如圖3所示,在CoderEval上,三個模型正確生成的任務存在較大的交集(Python:32,Java:56),說明三個模型在解決部分任務上有共性能力;同時,對于僅有一個模型能正確生成、而其他兩個模型未正確生成的任務而言,ChatGPT在Python和Java上都是最多的(Python:18,Java:27),說明ChatGPT在解決這部分任務上的能力具有顯著優勢;最后,三個模型一共解決的任務數仍僅占CoderEval所有任務數的約40%(Python:91/230)和59%(Java:136/230),說明三個模型的能力具有一定的互補性,且各自仍有較大提升空間。
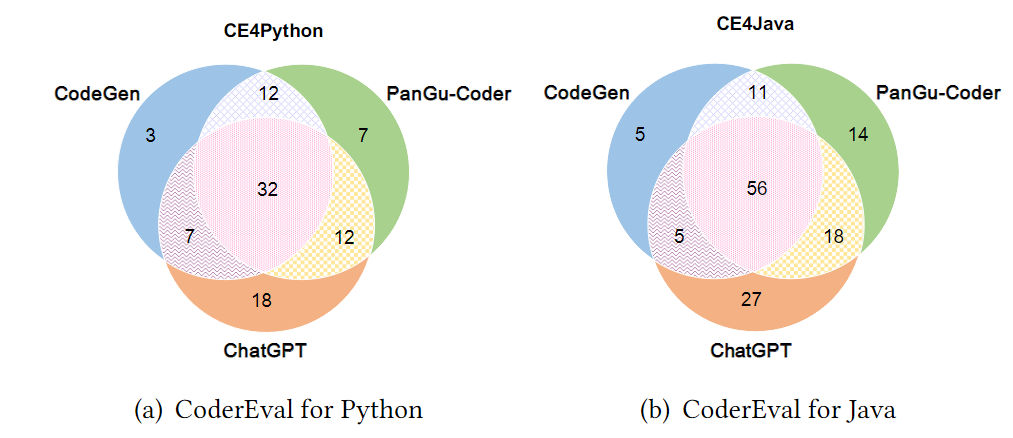
圖3 三個模型在CoderEval上和HumanEval上
正確生成的題目數對比
4. 如表2所示,在CoderEval的standalone子集上,三個模型的表現與HumanEval上基本接近,ChatGPT的表現大幅超過另外兩個模型;但是,在其他依賴于上下文信息的生成任務上(占實際情況的60%以上),三個模型的表現都有較大下降,即使是最強大的ChatGPT的表現也有很大波動,甚至在部分級別上三個模型生成10次的結果均錯誤,這一定程度上說明了依賴上下文的代碼生成任務是大模型代碼生成下一步優化的重點方向。
表2 三個模型在CoderEval的兩類子集上的表現對比
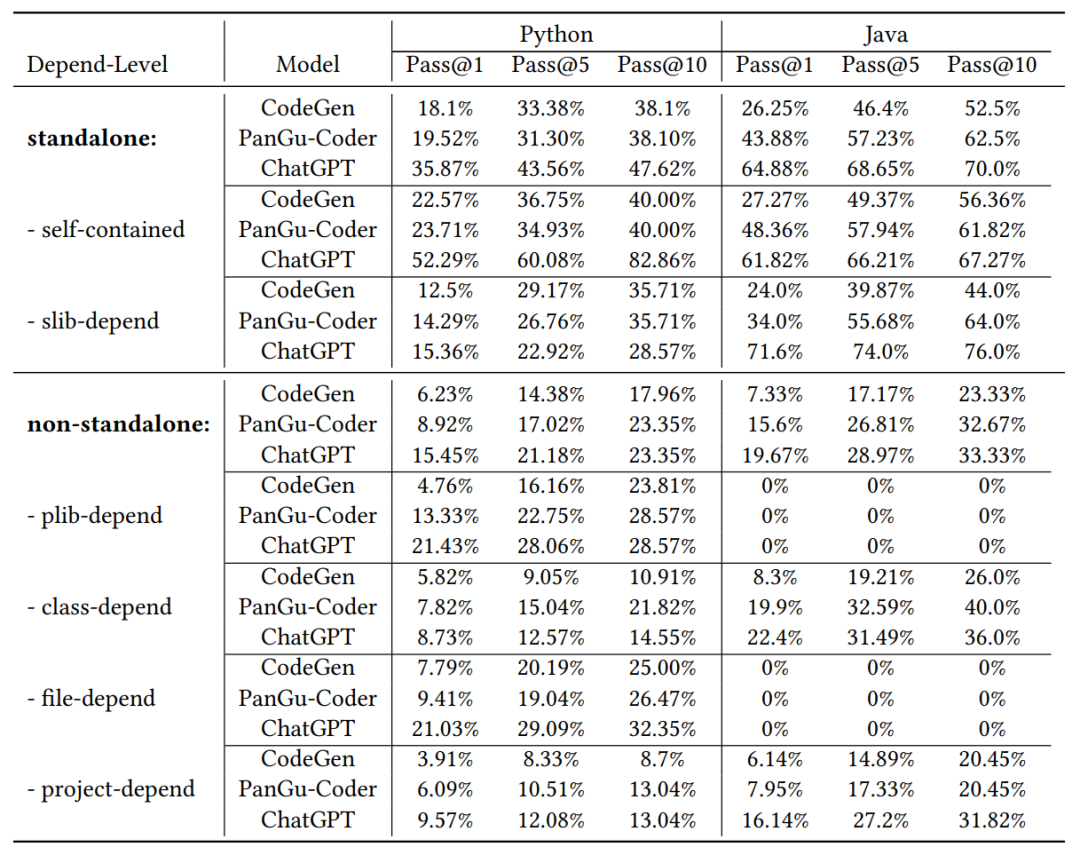
更多的實驗數據以及分析過程,請見CoderEval論文。
三.總結
CoderEval論文目前已發表在ICSE2024(https://arxiv.org/abs/2302.00288 ),其開源項目版可在GitHub獲得(https://github.com/CoderEval/CoderEval ),歡迎大家關注并一鍵Follow+Star。我們致力于將CoderEval打造為一個客觀、公正、全面的Benchmark,不過,盡量我們已努力完善,但它仍然不可避免地存在一些限制和錯誤。因此,我們希望借助代碼生成研究者社區的力量,持續迭代和更新CoderEval的版本,以擴展和完善其語言支持、數據集、測試方式等方面,從而持續推動代碼智能社區的研究與落地。
PaaS技術創新Lab隸屬于華為云,致力于綜合利用軟件分析、數據挖掘、機器學習等技術,為軟件研發人員提供下一代智能研發工具服務的核心引擎和智慧大腦。我們將聚焦軟件工程領域硬核能力,不斷構筑研發利器,持續交付高價值商業特性!加入我們,一起開創研發新“境界”!(詳情歡迎聯系:
bianpan@huawei.com;mayuchi1@huawei.com)
原文標題:從HumanEval到CoderEval: 你的代碼生成模型真的work嗎?
文章出處:【微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
-
華為
+關注
關注
218文章
36003瀏覽量
262081
原文標題:從HumanEval到CoderEval: 你的代碼生成模型真的work嗎?
文章出處:【微信號:華為DevCloud,微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型 ai coding 比較
端側大模型上車:從“語音助手”到“車內 AI 智能體”的躍遷革命
大模型支撐后勤保障方案生成系統軟件平臺
AI智能大模型,你身邊的最好用的辦公提效小能手
vision board部署模型到openmv的代碼導致連接超時怎么解決?
干貨分享 | TSMaster MBD模塊全解析:從模型搭建到自動化測試的完整實踐

低代碼物聯網平臺典型場景落地全流程:從需求到實現的路徑解析
AI生成的測試用例真的靠譜嗎?

模型捉蟲行家MV:致力全流程模型動態測試

從FA模型切換到Stage模型時:module的切換說明
【經驗分享】玩轉FPGA串口通信:從“幻覺調試”到代碼解析
代碼革命的先鋒:aiXcoder-7B模型介紹

小白學大模型:從零實現 LLM語言模型

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現



 工商網監
工商網監
評論