") 邁向更高效的圖像分類:解析DeiT模型的移植和適配
邁向更高效的圖像分類:解析DeiT模型的移植和適配

1. DeiT概述
1.1 項目簡介
Deit(Data-efficient image Transformers)是由Facebook與索邦大學的Matthieu Cord教授合作開發(fā)的圖像分類模型。作為一種基于Transformer架構(gòu)的深度學習模型,DeiT在保持高性能的同時,能夠大大提高數(shù)據(jù)效率,為圖像識別領(lǐng)域帶來了顛覆性的變化。
與傳統(tǒng)的CNN不同,DeiT模型采用了Transformer的自注意力機制,將圖像分割成若干個固定大小的塊,并對每個塊進行編碼,捕捉圖像中的長程依賴關(guān)系。
本文將為大家介紹如何將DeiT移植到算能BM1684X平臺上。
1.2 模型介紹
DeiT目前有3個版本的模型(tiny, small, base),均由12個Attention結(jié)構(gòu)組成,模型區(qū)別在于輸入的header個數(shù)及embed_dim不同。
Attention結(jié)構(gòu)如下圖所示:
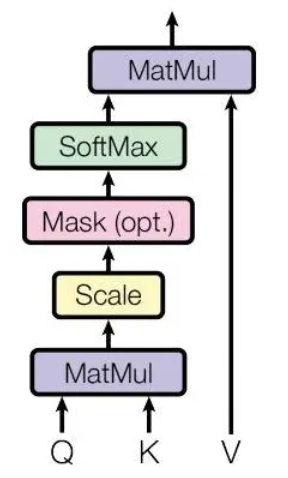 attention
attention
不同版本的模型具體參數(shù)區(qū)別如下表:
 version
version
2. 模型移植
以下部分介紹如何將DeiT移植到算能BM1684X平臺上。
2.1 模型trace
原始DeiT模型基于Pytorch框架訓練及推理。算能TPU-MLIR工具鏈可以編譯通過jit trace過的靜態(tài)模型。
首先進行模型trace,命令如下,需要修改原推理代碼。
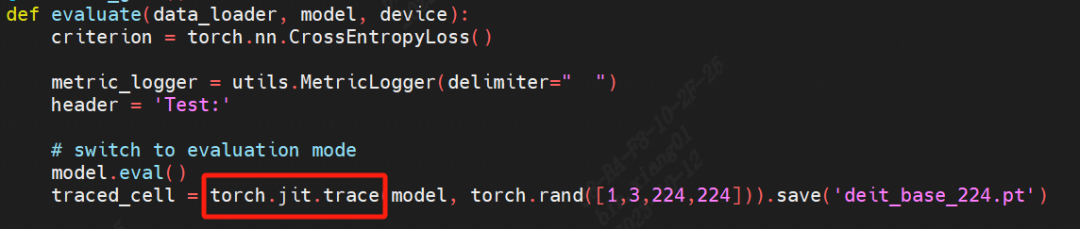 trace
trace
2.2 模型編譯
以下介紹如何使用算能TPU-MLIR工具鏈將上一步trace過的模型編譯成可以在算能BM1684X上推理的bmodel。在模型移植過程中遇到一些算子邊界的處理問題,均已修復。
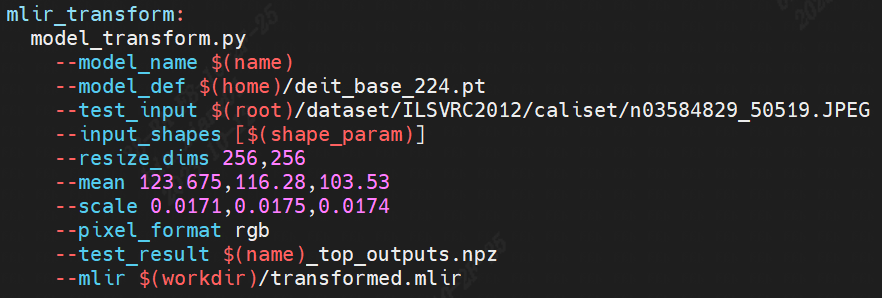 transform
transform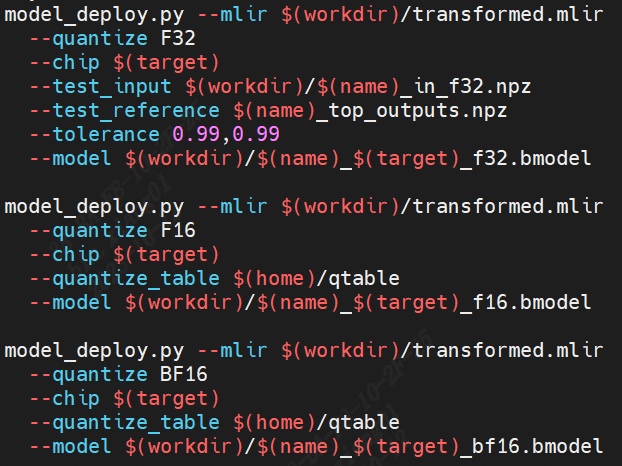 deploy
deploy
2.3 精度測試
DeiT為分類模型,精度測試采用topk來進行。
精度測試及性能測試結(jié)果如下:
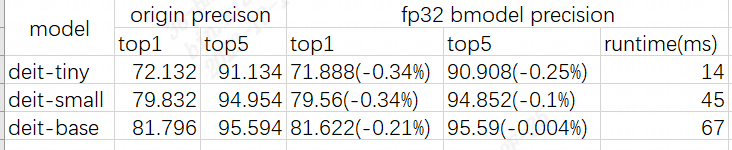 precision
precision
3 小結(jié)
總體看移植過程相對順利,在解決了部分算子邊界問題之后可以成功編譯出bmodel。F32精度基本可與原始框架對齊。由于第一個Conv stride > 15,在進行F16/BF16轉(zhuǎn)換時遇到比對問題,這部分代碼目前仍在重構(gòu),生成bmodel過程中這部分采用F32混精度處理。
-
圖像
+關(guān)注
關(guān)注
2文章
1096瀏覽量
42329 -
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111 -
深度學習
+關(guān)注
關(guān)注
73文章
5599瀏覽量
124398
發(fā)布評論請先 登錄
沐曦曦云C500/C550 GPU產(chǎn)品適配騰訊混元圖像3.0圖生圖模型
SAM(通用圖像分割基礎模型)丨基于BM1684X模型部署指南
飛騰多元化工控主板:賦能產(chǎn)業(yè)發(fā)展更智能、更高效、更便捷

千兆工業(yè)圖像采集卡 | 穩(wěn)定網(wǎng)絡傳輸,適配遠程工業(yè)檢測


在Ubuntu20.04系統(tǒng)中訓練神經(jīng)網(wǎng)絡模型的一些經(jīng)驗
迅為iTOP-RK3568人工智能開發(fā)板mobilenet圖像分類模型推理測試


RT-Thread Nano硬核移植指南:手把手實現(xiàn)VGLite圖形驅(qū)動適配 | 技術(shù)集結(jié)

翼輝信息RealEvo-Stream的高效移植過程
【正點原子STM32MP257開發(fā)板試用】基于 DeepLab 模型的圖像分割
壁仞科技完成Qwen3旗艦模型適配
基于RV1126開發(fā)板實現(xiàn)自學習圖像分類方案

愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

?VLM(視覺語言模型)?詳細解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論