") 什么是檢索增強生成?
什么是檢索增強生成?

檢索增強生成是一種使用從外部來源獲取的事實,來提高生成式 AI 模型準(zhǔn)確性和可靠性的技術(shù)。
為了理解這一生成式 AI 領(lǐng)域的最新進(jìn)展,讓我們以法庭為例。
法官通常根據(jù)對法律的一般理解來審理和判決案件。但有些案件需要用到特殊的專業(yè)知識,如醫(yī)療事故訴訟或勞資糾紛等,因此法官會派法庭書記員去圖書館尋找可以引用的先例和具體案例。
與優(yōu)秀的法官一樣,大語言模型(LLM)能夠響應(yīng)人類的各種查詢。但為了能夠提供引經(jīng)據(jù)典的權(quán)威答案,模型需要一個助手來做一些研究。
AI 的“法庭書記員”就是一個被稱為檢索增強生成(RAG)的過程。
名稱的由來
這個名稱來自 2020 年的一篇論文(https://arxiv.org/pdf/2005.11401.pdf),論文的第一作者 Patrick Lewis 對 RAG 這個“不討喜”的縮寫詞表示了歉意,如今,這個詞被用來描述在數(shù)百篇論文和數(shù)十種商業(yè)服務(wù)中不斷發(fā)展壯大的某種方法,而在他看來,這些都代表著生成式 AI 的未來。
在一場于新加坡舉辦的數(shù)據(jù)庫開發(fā)者區(qū)域會議中,Lewis 接受了采訪,他提到:“如果我們當(dāng)時知道研究成果會被如此廣泛地使用,肯定會在起名時多花些心思。”

圖 1:Partick Lewis
Lewis 現(xiàn)在是 AI 初創(chuàng)企業(yè) Cohere 的 RAG 團隊負(fù)責(zé)人。他表示:“我們當(dāng)時一直想取一個好聽的名字,但到了寫論文的時候,大家都想不出更好的了。”
什么是檢索增強生成?
檢索增強生成是一種使用從外部來源獲取的事實,來提高生成式 AI 模型準(zhǔn)確性和可靠性的技術(shù)。
換言之,它填補了 LLM 工作方式的缺口。LLM 其實是一種神經(jīng)網(wǎng)絡(luò),以其所含參數(shù)數(shù)量來衡量,參數(shù)本質(zhì)上等同于人類一般的遣詞造句方式。
這種深度理解有時被稱為參數(shù)化知識,使 LLM 能夠在瞬間對一般的指令作出響應(yīng)。但如果用戶希望深入了解當(dāng)前或更加具體的主題,它就不夠用了。
結(jié)合內(nèi)部與外部資源
Lewis 與其同事所開發(fā)的檢索增強生成技術(shù)能夠連接生成式 AI 服務(wù)與外部資源,尤其是那些具有最新技術(shù)細(xì)節(jié)的資源。
這篇論文的共同作者們來自前 Facebook AI Research(現(xiàn) Meta AI)、倫敦大學(xué)學(xué)院和紐約大學(xué)。由于 RAG 幾乎可以被任何 LLM 用于連接任意外部資源,因此他們把 RAG 稱為“通用的微調(diào)秘方”。
建立用戶信任
檢索增強生成為模型提供了可以引用的來源,就像研究論文中的腳注一樣。這樣用戶就可以對任何說法進(jìn)行核實,從而建立起信任。
另外,這種技術(shù)還能幫助模型消除用戶查詢中的歧義,降低模型做出錯誤猜測的可能性,該現(xiàn)象有時被稱為“幻覺”。
RAG 的另一大優(yōu)勢就是相對簡單。Lewis 與該論文的其他三位共同作者在博客中表示,開發(fā)者只需五行代碼就能實現(xiàn)這一流程。
這使得該方法比使用額外的數(shù)據(jù)集來重新訓(xùn)練模型更快、成本更低,而且還能讓用戶隨時更新新的來源。
如何使用檢索增強生成
借助檢索增強生成技術(shù),用戶基本上可以實現(xiàn)與數(shù)據(jù)存儲庫對話,從而獲得全新的體驗。這意味著用于 RAG 的應(yīng)用可能是可用數(shù)據(jù)集數(shù)量的數(shù)倍。
例如,一個帶有醫(yī)療數(shù)據(jù)索引的生成式 AI 模型可以成為醫(yī)生或護士的得力助手;金融分析師將受益于一個與市場數(shù)據(jù)連接的“助手”。
實際上,幾乎所有企業(yè)都可以將其技術(shù)或政策手冊、視頻或日志轉(zhuǎn)化為“知識庫”資源,以此增強 LLM。這些資源可以啟用客戶或現(xiàn)場技術(shù)支持、員工培訓(xùn)、開發(fā)者生產(chǎn)力等用例。
AWS、IBM、Glean、谷歌、微軟、NVIDIA、Oracle 和 Pinecone 等公司正是因為這一巨大的潛力而采用 RAG。
開始使用檢索增強生成
為了幫助用戶入門,NVIDIA 開發(fā)了檢索增強生成參考架構(gòu)(https://docs.nvidia.com/ai-enterprise/workflows-generative-ai/0.1.0/technical-brief.html)。該架構(gòu)包含一個聊天機器人示例和用戶使用這種新方法創(chuàng)建個人應(yīng)用所需的元素。
該工作流使用了專用于開發(fā)和自定義生成式 AI 模型的框架NVIDIA NeMo,以及用于在生產(chǎn)中運行生成式 AI 模型的軟件,例如NVIDIA Triton推理服務(wù)器和NVIDIA TensorRT-LLM等。
這些軟件組件均包含在NVIDIA AI Enterprise軟件平臺中,其可加速生產(chǎn)就緒型 AI 的開發(fā)和部署,并提供企業(yè)所需的安全性、支持和穩(wěn)定性。
為了讓 RAG 工作流獲得最佳性能,需要大量內(nèi)存和算力來移動和處理數(shù)據(jù)。NVIDIA GH200 Grace Hopper 超級芯片配備 288 GB 高速 HBM3e 內(nèi)存和每秒 8 千萬億次的算力,堪稱最佳的選擇,其速度相比使用 CPU 提升了 150 倍。
一旦企業(yè)熟悉了 RAG,就可以將各種現(xiàn)成或自定義的 LLM 與內(nèi)部或外部知識庫相結(jié)合,創(chuàng)造出各種能夠幫助其員工和客戶的助手。
RAG 不需要數(shù)據(jù)中心。在 Windows PC 上已可直接使用 LLM,其實這都要歸功于 NVIDIA 軟件所提供的支持,使用戶可以在筆記本電腦上輕松訪問各種應(yīng)用。

圖 2:一個在 PC 上的 RAG 示例應(yīng)用程序。
配備NVIDIA RTX GPU的 PC 如今可以在本地運行一些 AI 模型。通過在 PC 上使用 RAG,用戶可以連接私人知識來源(無論是電子郵件、筆記還是文章),以改善響應(yīng)。這樣,用戶可以對其數(shù)據(jù)來源、指令和回答的私密性和安全性放心。
在最近的一篇博客(https://blogs.nvidia.com/blog/tensorrt-llm-windows-stable-diffusion-rtx/)中,就提供了一個在 Windows 上使用 TensorRT-LLM 加速的 RAG 以快速獲得更好結(jié)果的例子。
檢索增強生成的發(fā)展史
這項技術(shù)的起源至少可以追溯到 20 世紀(jì) 70 年代初。當(dāng)時,信息檢索領(lǐng)域的研究人員推出了所謂的問答系統(tǒng)原型,即使用自然語言處理(NLP)訪問文本的應(yīng)用程序,最初涵蓋的是棒球等狹隘的主題。
多年以來,這種文本挖掘背后的概念其實一直沒有改變。但驅(qū)動它們的機器學(xué)習(xí)引擎卻有了顯著的發(fā)展,從而提高了實用性和受歡迎程度。
20 世紀(jì) 90 年代中期,Ask Jeeves 服務(wù)(即現(xiàn)在的 Ask.com)以一個穿著考究的男仆作為吉祥物,普及了問答系統(tǒng)。2011 年,IBM 的 Watson 在《危險邊緣》(Jeopardy!)節(jié)目中輕松擊敗兩位人類冠軍,成為電視名人。
如今,LLM 正在將問答系統(tǒng)提升至全新的水平。
在一家倫敦實驗室中迸發(fā)的靈感
在 2020 年發(fā)表這篇開創(chuàng)性的論文時,Lewis 正在倫敦大學(xué)學(xué)院攻讀自然語言處理(NLP)博士學(xué)位,并在倫敦一家新成立的 AI 實驗室中為 Meta 工作。當(dāng)時,該團隊正在尋找將更多知識加入到 LLM 參數(shù)中的方法,并使用模型自己開發(fā)的基準(zhǔn)來衡量進(jìn)展。
Lewis 回憶道,團隊在早期方法的基礎(chǔ)上,受谷歌研究人員一篇論文的啟發(fā),“產(chǎn)生了這一絕妙的想法——在一個經(jīng)過訓(xùn)練的系統(tǒng)中嵌入檢索索引,這樣它就能學(xué)習(xí)并生成你想要的任何文本輸出。”

圖 3:IBM Watson 問答系統(tǒng)在電視節(jié)目《危險邊緣》(Jeopardy!)中大獲全勝,一舉成名
Lewis 將這項正在開發(fā)的工作與另一個 Meta 團隊的優(yōu)秀檢索系統(tǒng)連接,所產(chǎn)生的第一批結(jié)果令人大吃一驚。
“我把結(jié)果拿給主管看,他驚嘆道:‘哇,你們做到了。這可不是常有的事情’。因為這些工作流很難在第一次就被設(shè)置正確。”
Lewis 還贊揚了團隊成員 Ethan Perez 和 Douwe Kiela 的重要貢獻(xiàn),兩人分別來自紐約大學(xué)和當(dāng)時的 Facebook AI 研究院。
這項在 NVIDIA GPU 集群上運行并已完成的工作,展示了如何讓生成式 AI 模型更具權(quán)威性和可信度。此后,數(shù)百篇論文引用了這一研究成果,并在這一活躍的研究領(lǐng)域?qū)ο嚓P(guān)概念進(jìn)行了擴展和延伸。
檢索增強生成如何工作
NVIDIA 技術(shù)簡介(https://docs.nvidia.com/ai-enterprise/workflows-generative-ai/0.1.0/technical-brief.html)高度概括了 RAG 流程:
當(dāng)用戶向 LLM 提問時,AI 模型會將查詢發(fā)送給另一個模型,后者會將查詢轉(zhuǎn)換成數(shù)字格式以便機器讀取。數(shù)字版本的查詢有時被稱為嵌入或向量。
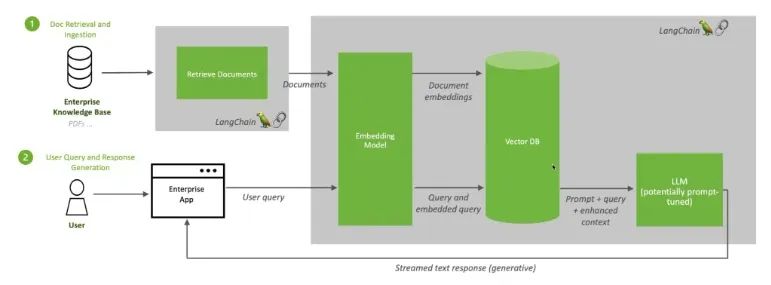
圖 4:檢索增強生成將 LLM 與嵌入模型和向量數(shù)據(jù)庫相結(jié)合。
隨后,嵌入模型會將這些數(shù)值與可用知識庫的機器可讀索引中的向量進(jìn)行比較。當(dāng)發(fā)現(xiàn)存在一個或多個匹配項時,它會檢索相關(guān)數(shù)據(jù),將其轉(zhuǎn)換為人類可讀的單詞并發(fā)送回 LLM。
最后,LLM 會將檢索到的單詞和它自己對查詢的響應(yīng)相結(jié)合,形成最終的答案并提交給用戶,其中可能會引用嵌入模型找到的來源。
始終使用最新的資源
在后臺,嵌入模型會不斷創(chuàng)建并更新機器可讀索引(有時被稱為向量數(shù)據(jù)庫),以獲得經(jīng)過更新的最新知識庫。
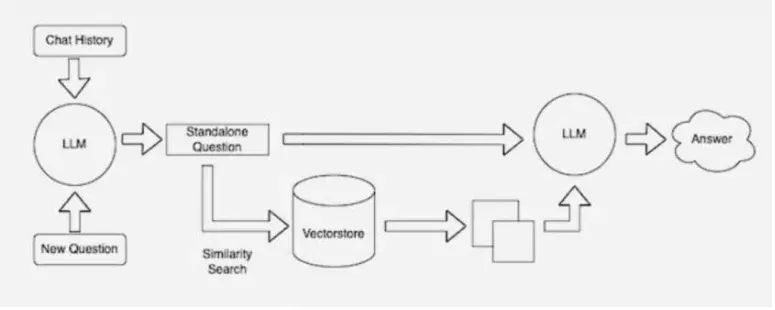
圖 5:LangChain 的示意圖從另一個角度描述了使用檢索流程的 LLM。
許多開發(fā)者也發(fā)現(xiàn),LangChain 這個開源程序庫特別適合將 LLM、嵌入模型和知識庫串聯(lián)到一起。NVIDIA 在其檢索增強生成參考架構(gòu)中就是使用了 LangChain。
而在 LangChain 社群里,他們也提供了自己的 RAG 流程描述。(https://blog.langchain.dev/tutorial-chatgpt-over-your-data/)
展望未來,生成式 AI 的未來在于其創(chuàng)造性地串聯(lián)起各種 LLM 和知識庫,創(chuàng)造出各種新型助手,并將可以驗證的權(quán)威結(jié)果提供給用戶。
也歡迎您訪問NVIDIA LaunchPad(https://www.nvidia.com/en-us/launchpad/ai/generative-ai-knowledge-base-chatbot/)中的實驗室,您可以通過 AI 聊天機器人親身體驗檢索增強生成。
GTC 2024 將于 2024 年 3 月 18 至 21 日在美國加州圣何塞會議中心舉行,線上大會也將同期開放。點擊“閱讀原文”或掃描下方海報二維碼,立即注冊 GTC 大會。
原文標(biāo)題:什么是檢索增強生成?
文章出處:【微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
23文章
4086瀏覽量
99173
原文標(biāo)題:什么是檢索增強生成?
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
RAG(檢索增強生成)原理與實踐
openDACS 2025 開源EDA與芯片賽項 賽題七:基于大模型的生成式原理圖設(shè)計
強生醫(yī)療科技攜手NVIDIA推進(jìn)手術(shù)機器人開發(fā)
RAG實踐:一文掌握大模型RAG過程
基于FPGA的CLAHE圖像增強算法設(shè)計

孔夫子舊書網(wǎng)開放平臺接口實戰(zhàn):古籍圖書檢索與商鋪數(shù)據(jù)集成
生成式 AI 重塑自動駕駛仿真:4D 場景生成技術(shù)的突破與實踐

軟通動力發(fā)布智慧園區(qū)RAG解決方案
石墨烯增強生物基凝膠導(dǎo)熱和導(dǎo)電性能研究

【「零基礎(chǔ)開發(fā)AI Agent」閱讀體驗】+Agent的案例解讀
如何在基于Arm Neoverse平臺的Google Axion處理器上構(gòu)建RAG應(yīng)用




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論