 李開復4個多月后“放大招”:對標OpenAI、谷歌,發布“全球最強”開源大模型
李開復4個多月后“放大招”:對標OpenAI、谷歌,發布“全球最強”開源大模型

今天,由李開復打造的 AI 大模型創業公司“零一萬物”發布了一系列開源大模型:Yi-34B 和 Yi-6B。
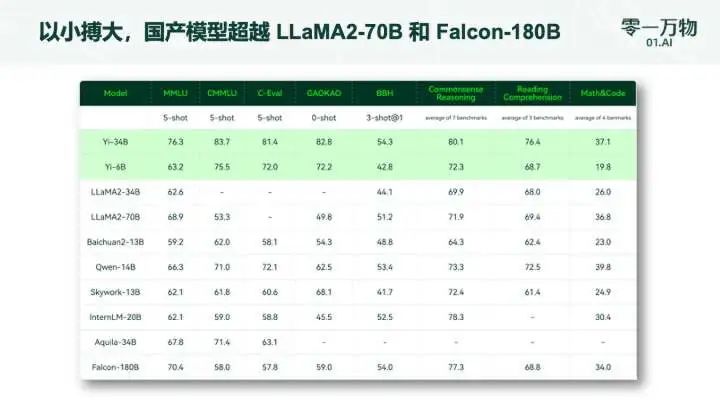
Yi-34B 是一個雙語(英語和中文)基礎模型,經過 340 億個參數訓練,明顯小于 Falcon-180B 和 Meta LlaMa2-70B 等其他開放模型。在發布會中,李開復稱其數據采集、算法研究、團隊配置均為世界第一梯隊,對標 OpenAI、谷歌一線大廠,并抱有成為世界第一的初衷和決心。同時,他表示 Yi-34B 是“全球最強開源模型”,其通用能力、知識推理、閱讀理解等多指標均處于全球榜單首位。
零一萬物團隊也進行了一系列打榜測試,具體成績包括:
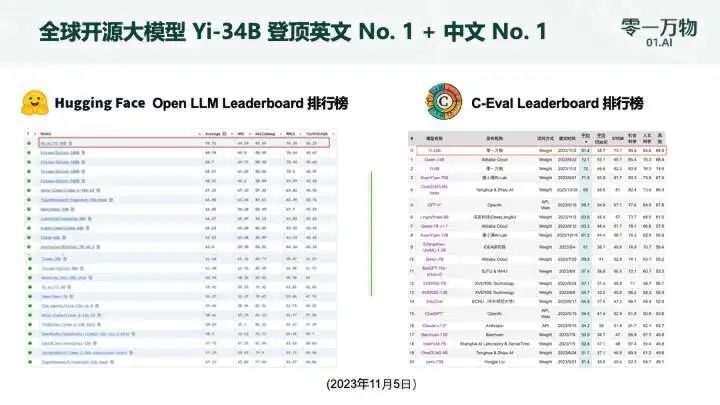
Hugging Face 英文測試榜單,以 70.72 分數位列全球第一;
以小博大,作為國產大模型碾壓 Llama-2 70B 和 Falcon-180B 等一眾大模型(參數量僅為后兩者的 1/2、1/5);
C-Eval 中文能力排行榜位居第一,超越了全球所有開源模型;
MMLU、BBH 等八大綜合能力表現全部勝出,Yi-34B 在通用能力、知識推理、閱讀理解等多項指標評比中“擊敗全球玩家”;
......
然而,在發布中,也有一點需要指出,那就是 Yi 系列模型在 GSM8k 和 MBPP 的數學以及代碼測評方面表現不如 GPT 模型出色。這是因為團隊希望在預訓練階段希望先盡可能保留模型的通用能力,所以訓練數據中沒有加入過多數學和代碼數據。后續他們計劃在開源系列中推出專注于代碼和數學領域的繼續訓練模型。
200K 上下文窗口, 能處理 40 萬字文本
值得注意的是,此次開源的 Yi-34B 模型,將發布全球最長、可支持 200K 超長上下文窗口(context window)版本,可以處理約 40 萬漢字超長文本輸入。這意味著 Yi-34B 不僅能提供更豐富的語義信息,理解超過 1000 頁的 PDF 文檔,還讓很多依賴于向量數據庫構建外部知識庫的場景,都可以用上下文窗口來進行替代。
相比之下,OpenAI 的 GPT-4 上下文窗口只有 32K,文字處理量約 2.5 萬字。今年三月,硅谷知名 AI 2.0 創業公司 Anthropic 的 Claude2-100K 將上下文窗口擴展到了 100K 規模,零一萬物直接加倍,并且是第一家將超長上下文窗口在開源社區開放的大模型公司。
在語言模型中,上下文窗口是大模型綜合運算能力的金指標之一,對于理解和生成與特定上下文相關的文本至關重要,擁有更長窗口的語言模型可以處理更豐富的知識庫信息,生成更連貫、準確的文本。
此外,在文檔摘要、基于文檔的問答等下游任務中,長上下文的能力發揮著關鍵作用,行業應用場景廣闊。在法律、財務、傳媒、檔案整理等諸多垂直場景里,更準確、更連貫、速度更快的長文本窗口功能,可以成為人們更可靠的 AI 助理,讓生產力得到大幅提升。然而,受限于計算復雜度、數據完備度等問題,上下文窗口規模擴充從計算、內存和通信的角度存在各種挑戰,因此大多數發布的大型語言模型僅支持幾千 tokens 的上下文長度。為了解決這個限制,零一萬物技術團隊實施了一系列優化,包括:計算通信重疊、序列并行、通信壓縮等。通過這些能力增強,實現了在大規模模型訓練中近 100 倍的能力提升。
實現 40% 訓練成本下降
AI Infra(AI Infrastructure 人工智能基礎架構技術)主要涵蓋大模型訓練和部署提供各種底層技術設施,包括處理器、操作系統、存儲系統、網絡基礎設施、云計算平臺等等,是模型訓練背后極其關鍵的“保障技術”,這是大模型行業至今較少受到關注的硬技術領域。
李開復曾經表示,“做過大模型 Infra 的人比做算法的人才更稀缺”,而超強的 Infra 能力是大模型研發的核心護城河之一。在芯片、GPU 等算力資源緊缺的當下,安全和穩定成為大模型訓練的生命線。零一萬物的 Infra 技術通過“高精度”系統、彈性訓和接力訓等全棧式解決方案,確保訓練高效、安全地進行。
憑借其強大的 AI Infra 支撐,零一萬物團隊表示,Yi-34B 模型訓練成本實測下降 40%,實際訓練完成達標時間與預測的時間誤差不到一小時,進一步模擬上到千億規模訓練成本可下降多達 50%。截至目前,零一萬物 Infra 能力實現故障預測準確率超過 90%,故障提前發現率達到 99.9%,不需要人工參與的故障自愈率超過 95%,有力保障了模型訓練的順暢進行。
零一萬物背后
今年 7 月,李開復博士正式官宣并上線了其籌組的“AI 2.0”新公司:零一萬物。此前李開復曾表示,AI 大語言模型是中國不能錯過的歷史機遇,零一萬物就是在今年 3 月下旬,由他親自帶隊孵化的新品牌。
在接受外媒采訪時,他談到了創辦零一萬物的動機:“我認為需求是創新之母,中國顯然存在巨大的需求,”“與其他國際地區不同,中國無法訪問 OpenAI 和谷歌,因為這兩家公司沒有在中國提供他們的產品。因此,我認為有很多人正在努力為市場創造解決方案。這是剛需。”
眾所周知,構建大模型是一項耗資巨大的事業。為了維持現金密集型業務,零一萬物從一開始就制定了商業化計劃。雖然該公司將繼續開源其一些模型,但其目標是構建最先進的專有模型,作為各種商業產品的基礎。
李開復表示,他們非常清楚這些大型語言模型需要大量計算,花費巨大。“我們籌集到了大量資金,其中大部分都花在了 GPU 上。”與中國其他 LLM 玩家一樣,零一萬物也需要積極儲備 GPU 以應對美國制裁。在發布會中,李開復表示零一萬物現在的供應至少足以滿足未來 12-18 個月的需求。
美國的制裁也讓中國企業注重優化計算能力,李開復表示:“借助一支非常高質量的基礎設施團隊,每 1000 個 GPU,我們也許能夠從中擠出 2000 個 GPU 的工作負載。”
從一些報道中,我們可以了解到,零一萬物員工規模已超過 100 人,半數是來自國內外大廠的 LLM 專家。其中,零一萬物技術副總裁及 AI Alignment 負責人是 Google Bard/Assistant 早期核心成員,主導或參與了從 Bert、LaMDA 到大模型在多輪對話、個人助理、AI Agent 等多個方向的研究和工程落地;首席架構師曾在 Google Brain 與 Jeff Dean、Samy Bengio 等合作,為 TensorFlow 的核心創始成員之一。
零一萬物的商業化之路很大程度上取決于其為其昂貴的 AI 模型找到適合的產品市場的能力。“中國在大模型方面并不領先于美國,但毫無疑問,中國可以構建比美國開發商更好的應用程序,這主要是因為過去 12 年左右建立的非凡的移動互聯網生態系統,”李開復說道。
李開復表示,這家初創公司的最終目標是成為一個外部開發人員可以輕松構建應用程序的生態系統。“我們的職責不僅僅是推出好的研究模型,更重要的是讓應用程序開發變得容易,這樣才能有優秀的應用程序,”他說。“歸根結底。這是一場生態系統游戲。”
-
語言模型
+關注
關注
0文章
571瀏覽量
11322 -
OpenAI
+關注
關注
9文章
1245瀏覽量
10109 -
大模型
+關注
關注
2文章
3653瀏覽量
5196
原文標題:李開復4個多月后“放大招”:對標OpenAI、谷歌,發布“全球最強”開源大模型
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
泰凌微:布局端側AI,產品支持谷歌LiteRT、TVM開源模型
GPT-5.1發布 OpenAI開始拼情商
谷歌云發布最強自研TPU,性能比前代提升4倍

華為發布全球最強算力超節點和集群
OpenAI開源模型登陸IBM watsonx.ai開發平臺
澎峰科技完成OpenAI最新開源推理模型適配
訊飛星辰MaaS平臺率先上線OpenAI最新開源模型
OpenAI或在周五凌晨發布GPT-5 OpenAI以低價向美國政府提供ChatGPT
亞馬遜云科技現已上線OpenAI開放權重模型
OpenAI發布2款開源模型
擺脫依賴英偉達!OpenAI首次轉向使用谷歌芯片
“天才”!OpenAI o3 成全球 IQ 最高的 AI 大模型
DeepSeek開源新版R1 媲美OpenAI o3
上新:小米首個推理大模型開源 馬斯克:下周推出Grok 3.5
低至¥2.27/h!就能使用全球最強開元模型——千問 QwQ-32B




 工商網監
工商網監
評論