 Tablib:一個Python的第三方數據導出模塊
Tablib:一個Python的第三方數據導出模塊

Tablib是一個Python的第三方數據導出模塊,它支持以下文件格式的導出:
- Excel
- JSON
- YAML
- Pandas DataFrames
- HTML
- Jira
- TSV
- ODS
- CSV
- DBF
其實這個工具能做到的東西,Pandas都能做到,但是有時候Pandas實在是過重了,如果我們只想實現輕量數據的導出,而非上千萬級別的數據導出,該工具更能體現它的優勢。
1.準備
開始之前,你要確保Python和pip已經成功安裝在電腦上噢,如果沒有,請訪問這篇文章:超詳細Python安裝指南 進行安裝。
Windows環境下打開Cmd(開始—運行—CMD),蘋果系統環境下請打開Terminal(command+空格輸入Terminal),準備開始輸入命令安裝依賴。
當然,我更推薦大家用VSCode編輯器,把本文代碼Copy下來,在編輯器下方的終端裝依賴模塊,多舒服的一件事啊:Python 編程的最好搭檔—VSCode 詳細指南。
在終端輸入以下命令安裝我們所需要的依賴模塊:
pip install tablib
看到 Successfully installed xxx 則說明安裝成功。
2.基本使用
這一塊,官方文檔已經有詳細介紹,這里轉載自xin053的翻譯與介紹,有部分修改:
https://xin053.github.io/2016/07/10/tablib%E5%BA%93%E4%BD%BF%E7%94%A8%E8%AF%A6%E8%A7%A3/
創建Dataset對象

這樣相當于構造了一張表:
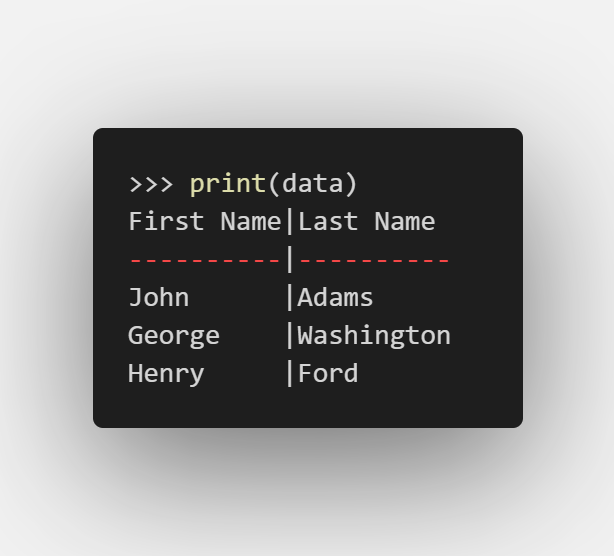
| first_name | last_name |
|---|---|
| John | Adams |
| George | Washington |
其中最重要的就是Dataset對象,當然該對象的創建也可以不輸入參數,直接
data = tablib.Dataset()
創建出一個Dataset對象,然后通過
data.headers = ['first_name', 'last_name']
設置表頭,當然也可以使用 data.headers = ('first_name', 'last_name'), 因為不管是用列表還是元組,tablib都會自動幫我們處理好,我們可以通過
data.append(['Henry', 'Ford'])
# 或data.append(('Henry', 'Ford'))
來向表中添加一條記錄。
我們可以通過data.dict來查看目前表中的所有數據:

也可以通過print(data)顯示更人性化的輸出:
Dataset屬性
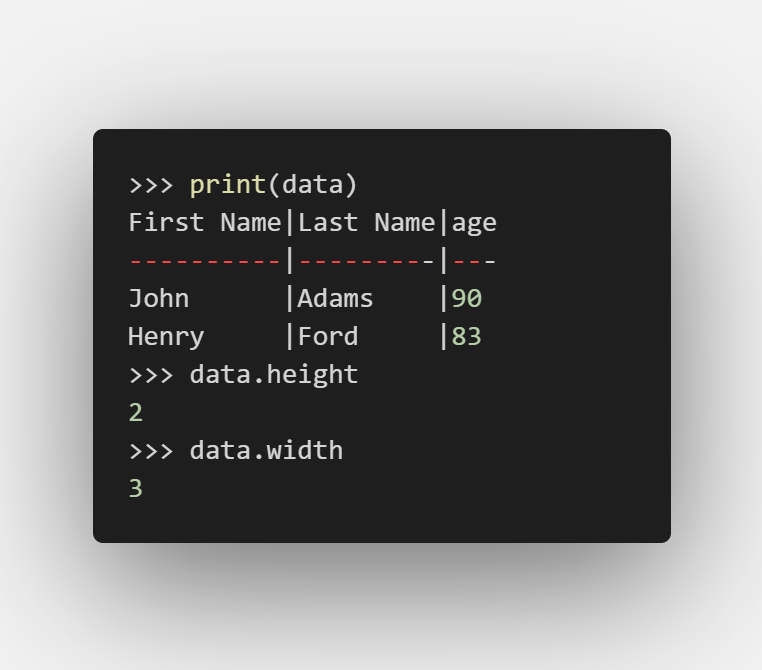
data.height輸出當前記錄(行)總數
data.width輸出當前屬性(列)總數
常用方法
詳情可見官方文檔:
https://tablib.readthedocs.io/en/stable/api/#tablib.Dataset.remove_duplicates
lpop(), lpush(row, tags=[]), lpush_col(col, header=None)是對列的相關操作
pop(), rpop(), rpush(row, tags=[]), rpush_col(col, header=None)是對行的相關操作
remove_duplicates()去除重復的記錄
sort(col, reverse=False)根據列進行排序
subset(rows=None, cols=None)返回子Dataset
wipe()清空Dataset,包括表頭和內容
新增列
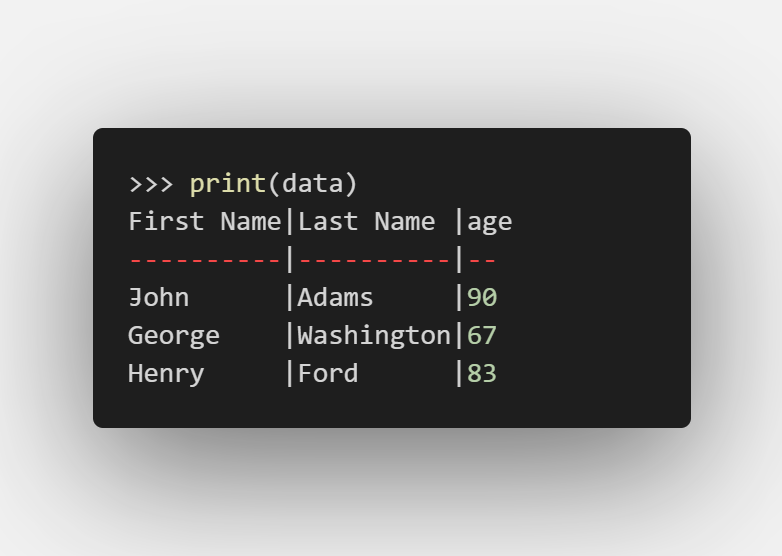
data.append_col((90, 67, 83), header='age')
這樣表就變成了:
| first_name | last_name | age |
|---|---|---|
| John | Adams | 90 |
| George | Washington | 67 |
| Henry | Ford | 83 |
對記錄操作
> >> print(data[:2])
[('John', 'Adams', 90), ('George', 'Washington', 67)]
> >> print(data[2:])
[('Henry', 'Ford', 83)]
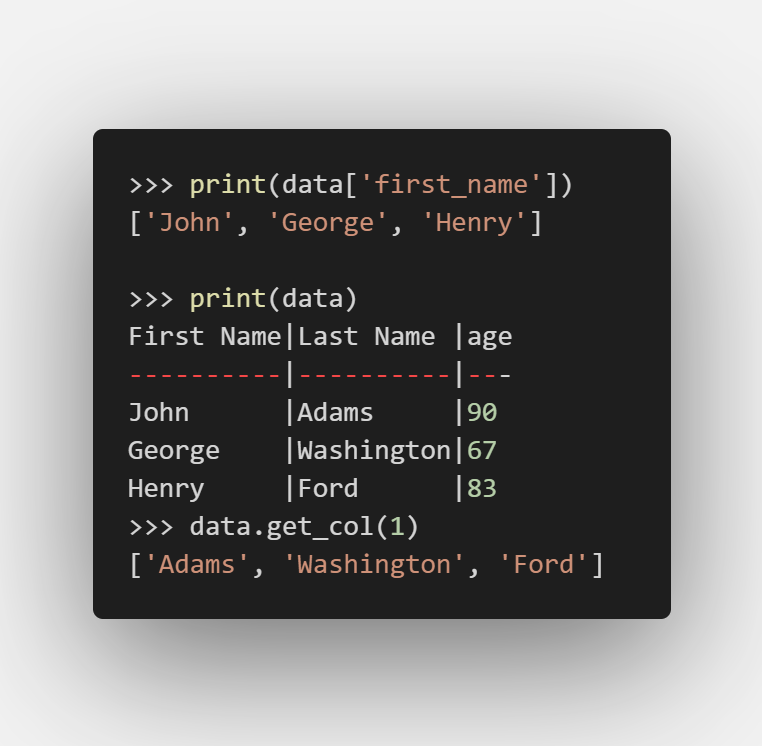
對屬性操作
刪除記錄
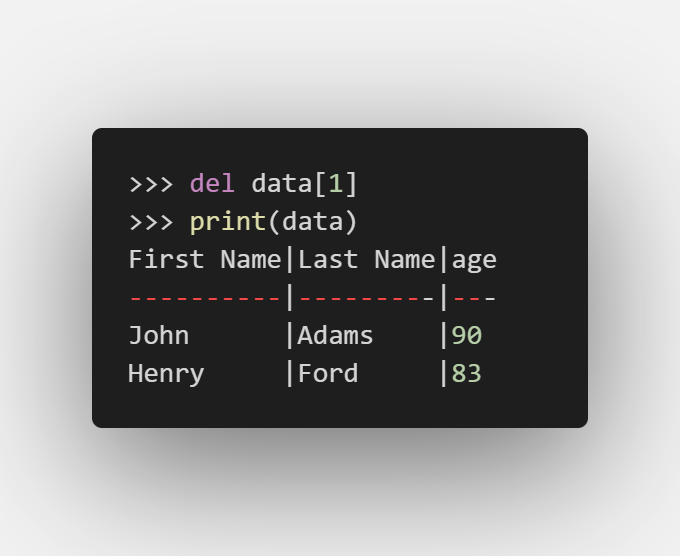
可見記錄也是從0開始索引的
刪除記錄操作也支持切片, 即 del data[1:999] 也是可行的
刪除屬性
del data['Col Name']
導入數據
imported_data = tablib.Dataset().load(open('data.csv').read())
導出數據
csv:
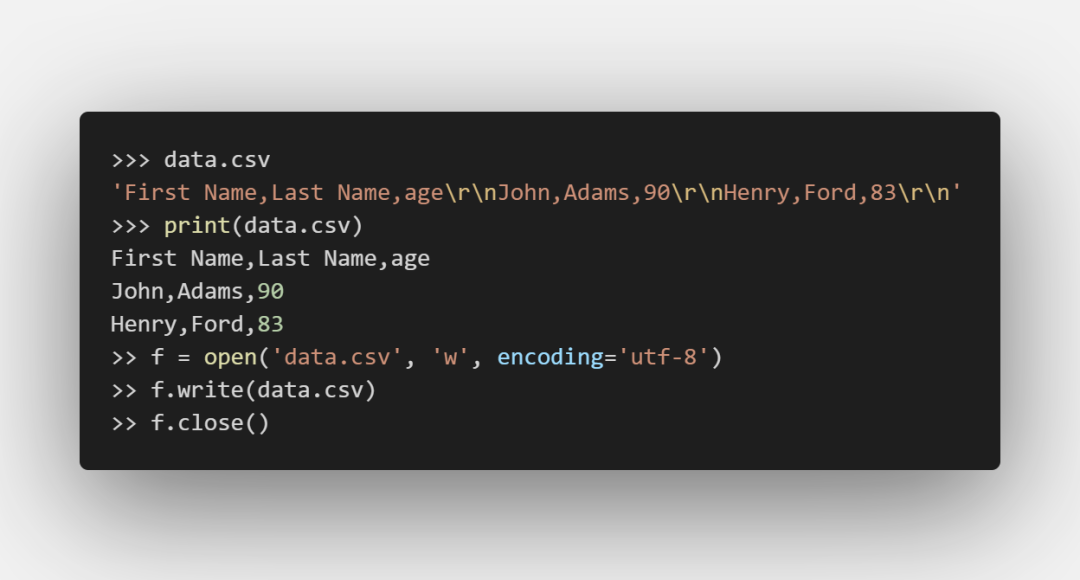
這樣便可成功將數據導出為csv文件。
json:
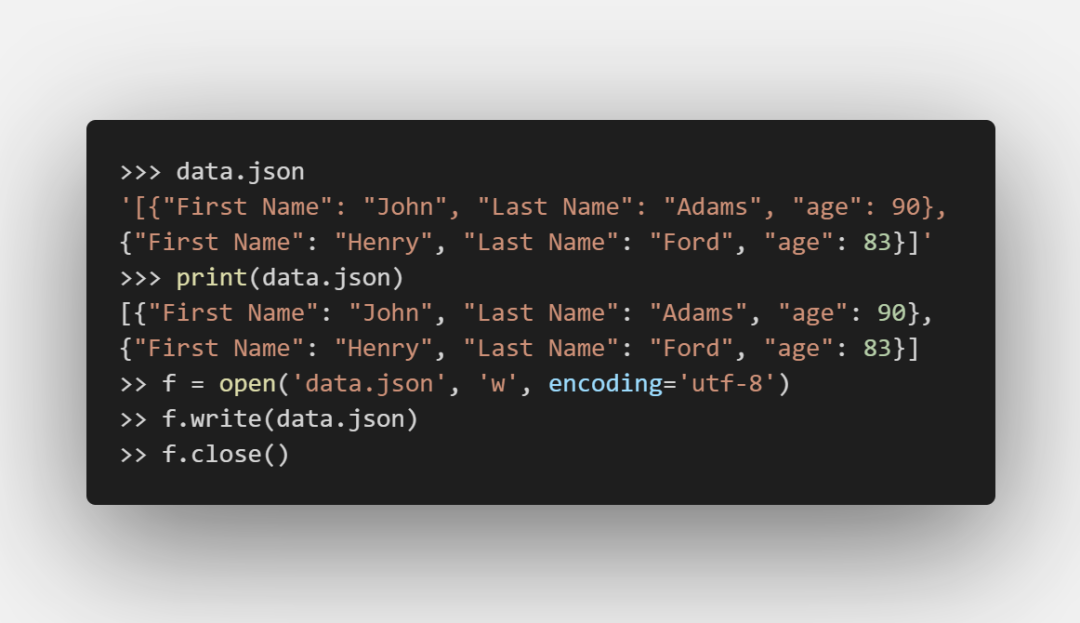
yaml:
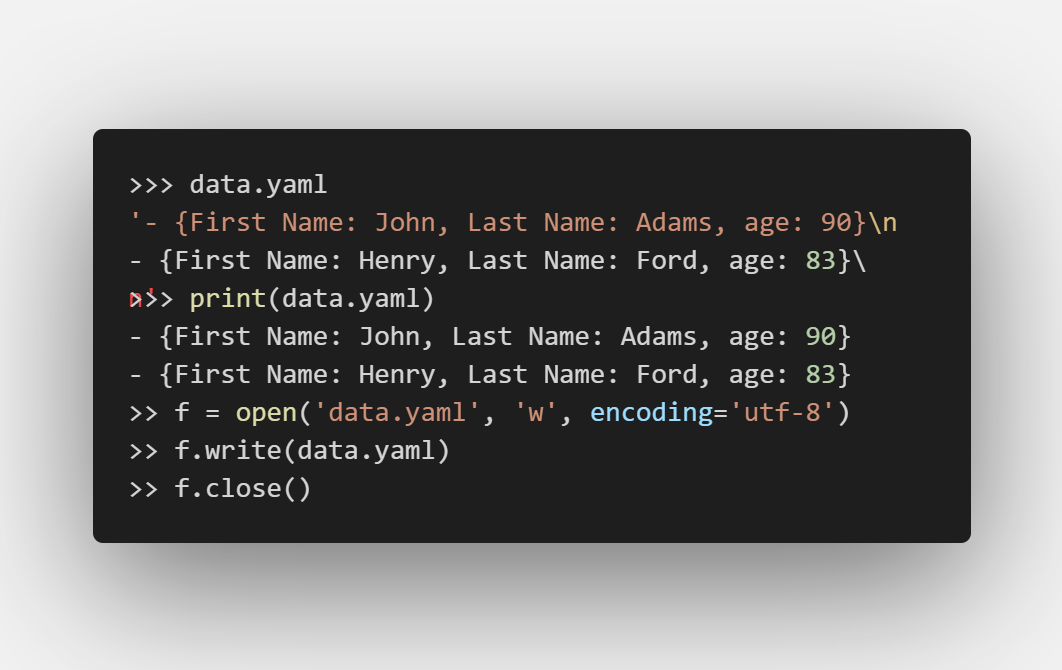
excel:
>> > with open('people.xls', 'wb') as f:
... f.write(data.xls)
注意要以二進制形式打開文件
dbf:
>> > with open('people.dbf', 'wb') as f:
... f.write(data.dbf)
高級使用
動態列
可以將一個函數指定給Dataset對象
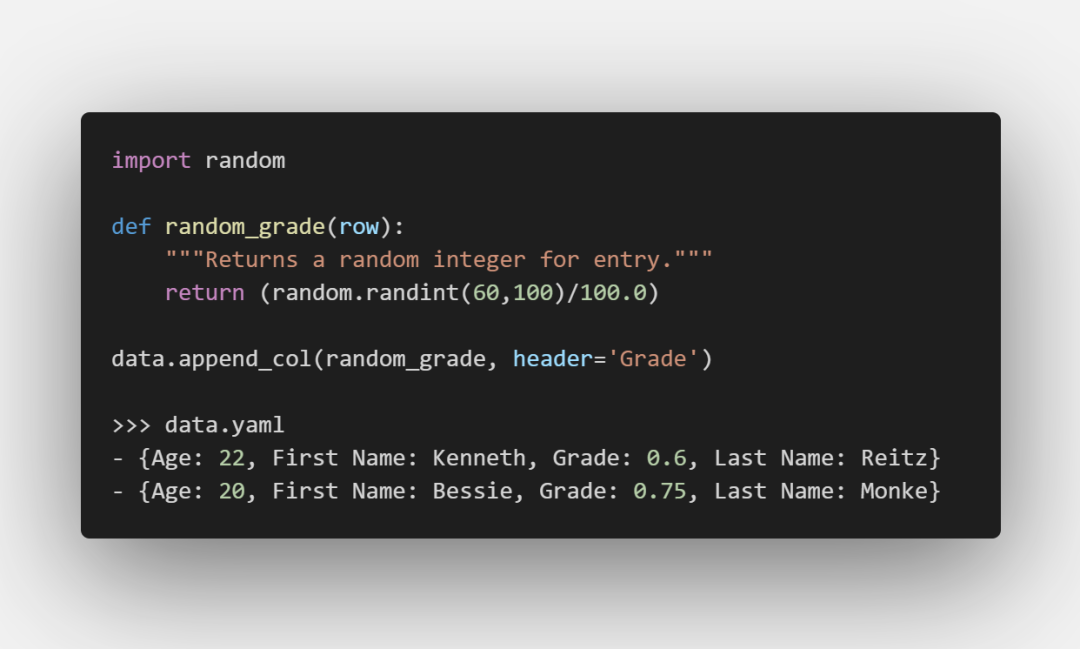
函數的參數row傳入的是每一行記錄,所以可以根據傳入的記錄進行更一步的計算:
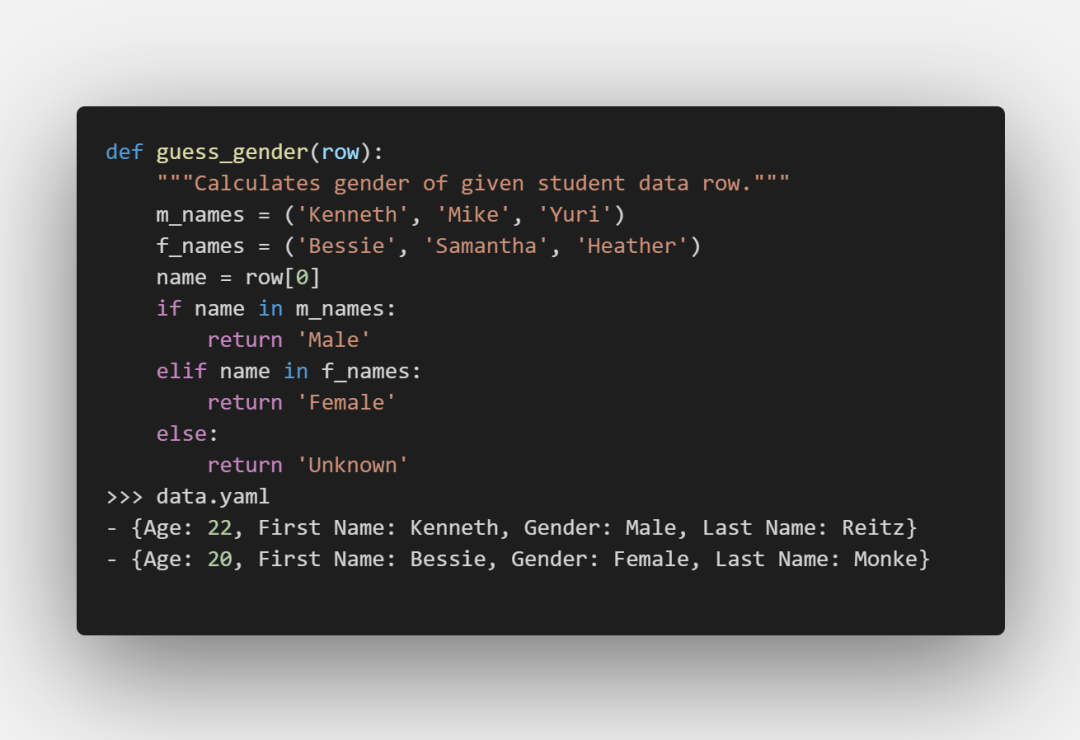
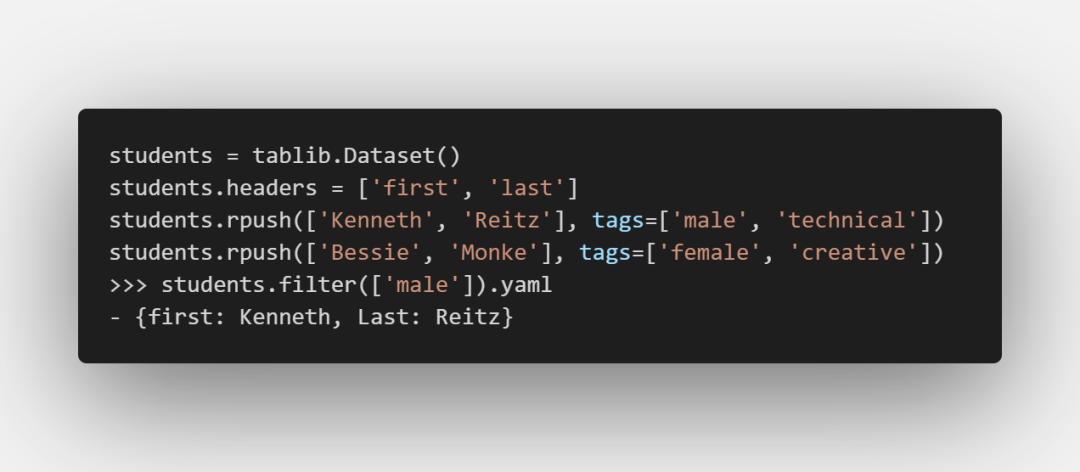
tag
可以給記錄添加tag,之后通過tag來過濾記錄:
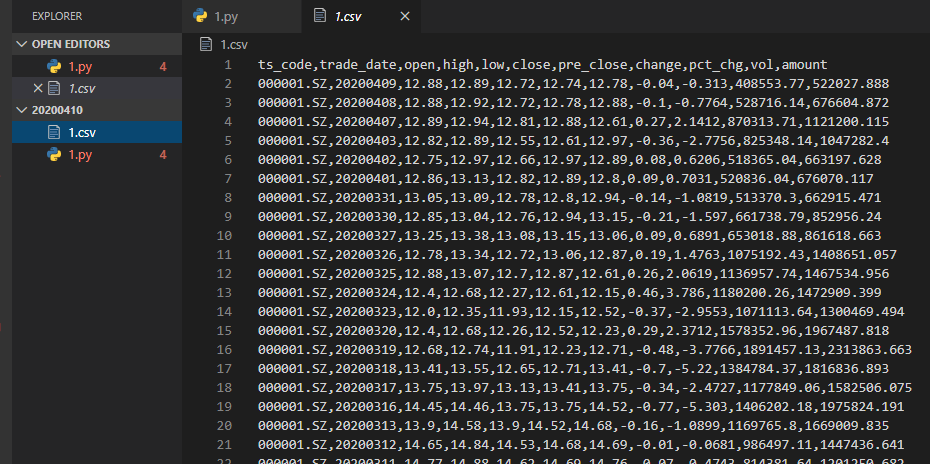
3.舉個小例子
現在有一個場景,我們需要將一份股票數據csv文件轉化為json數據:
你只需要這樣操作:
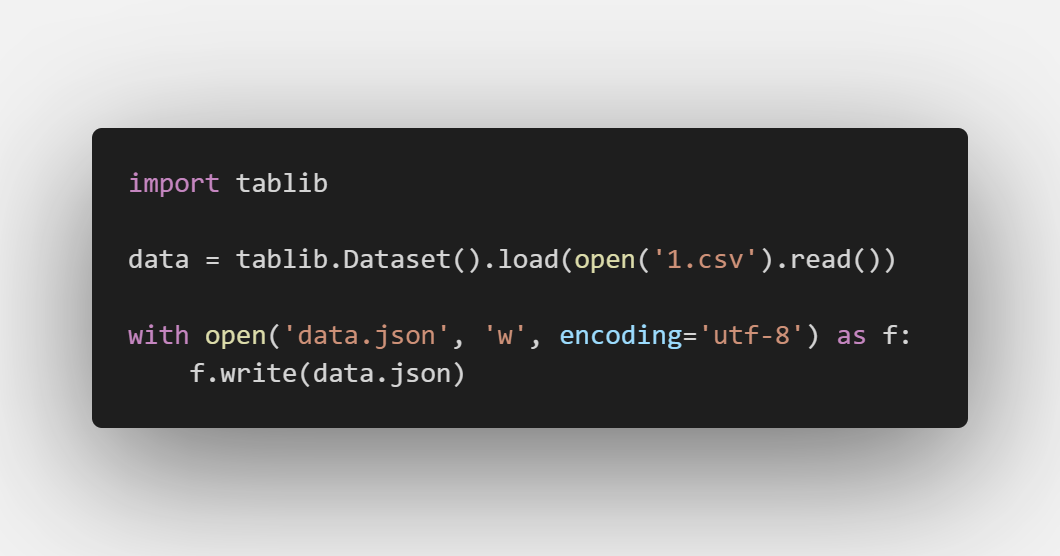
即可將其轉化為json格式,顯然,它的特點在于輕量、簡單。如果用Pandas來做這樣的轉化,則有些大材小用。
-
模塊
+關注
關注
7文章
2837瀏覽量
53283 -
數據
+關注
關注
8文章
7335瀏覽量
94757 -
python
+關注
關注
57文章
4876瀏覽量
90025
發布評論請先 登錄
Labview如何內嵌操作第三方EXE程序!
LabVIEW與第三方軟件交互問題
國內知名第三方檢測認證機構排名
關于LabVIEW調用第三方exe,如何去控制第三方exe按鈕的問題
頭文件中包含第三方文件
第三方腳本成為網絡攻擊“重災區”,多管齊下防范第三方腳本安全隱患
GeoPandas:針對地理數據做了特別支持的第三方模塊



 工商網監
工商網監
評論