") 借助亞馬遜云科技大語言模型等多種服務打造下一代企業(yè)知識庫
借助亞馬遜云科技大語言模型等多種服務打造下一代企業(yè)知識庫

背景
知識庫需求在各行各業(yè)中普遍存在,例如制造業(yè)中歷史故障知識庫、游戲社區(qū)平臺的內(nèi)容知識庫、電商的商品推薦知識庫和醫(yī)療健康領域的掛號推薦知識庫系統(tǒng)等。為保證推薦系統(tǒng)的實效性和準確性,需要大量的數(shù)據(jù)/算法/軟件工程師的人力投入和包括硬件在內(nèi)的物力投入。其次,為了進一步提高搜索準確率,如何引導用戶搜索描述更加準確和充分利用用戶行為優(yōu)化搜索引擎也是常見的用戶痛點。此外,如何根據(jù)企業(yè)知識庫直接給出用戶提問的答案也是眾多企業(yè)中會遇見的技術瓶頸。
本文旨在介紹一些企業(yè)知識庫的典型實用場景,以及如何使用智能搜索,結(jié)合大語言模型,針對企業(yè)知識庫提供基于搜索的精準問答。
各行各業(yè)中有很多場景需要基于企業(yè)知識庫進行搜索和問答
1.構(gòu)建裝備維護知識庫和問答系統(tǒng):使用歷史維保記錄和維修手冊構(gòu)建企業(yè)知識庫,維修人員可依靠該知識庫,快速地進行問題定位和維修。
2.構(gòu)建IT/HR系統(tǒng)智能問答系統(tǒng):使用企業(yè)內(nèi)部IT/HR使用手冊構(gòu)建企業(yè)知識庫,企業(yè)內(nèi)部員工可通過該知識庫快速解決在IT/HR上遇到的問題。
3.構(gòu)建電商平臺的搜索和問答系統(tǒng):使用商品信息構(gòu)建商品數(shù)據(jù)庫,消費者可通過檢索+問答的方式快速了解商品的詳細信息。
4.構(gòu)建游戲社區(qū)自動問答系統(tǒng):使用游戲的信息(例如游戲介紹,游戲攻略等)構(gòu)建社區(qū)知識庫,可根據(jù)該知識庫自動回復社區(qū)成員提供的問題。
5.構(gòu)建智能客戶聊天機器人系統(tǒng):通過與呼叫中心/聊天機器人服務結(jié)合,可自動基于企業(yè)知識庫就客戶提出的問題進行聊天回復。
6.構(gòu)建智能教育輔導系統(tǒng):使用教材和題庫構(gòu)建不同教育階段的知識庫,模擬和輔助老師/家長對孩子進行教學。
為解決上述場景需求,可通過結(jié)合搜索和大語言模型的方式來實現(xiàn)。首先,可以利用企業(yè)自身積累的數(shù)據(jù)資產(chǎn)建立一個知識庫。其次,對于特定的問答任務,可以使用搜索功能對知識庫進行有效的召回,然后將召回的知識進行利用,增強大語言模型。通過這一方法,可以實現(xiàn)對問答任務的解決。
在企業(yè)知識庫建立和搜索服務方面,亞馬遜云科技擁有云端托管式搜索服務Amazon OpenSearch和基于AI/ML的智能企業(yè)搜索服務Amazon Kendra。雖然上述服務能夠提供基本的搜索引擎和框架,解決了用戶在硬件投入大和管理難的痛點,然而上述服務并且不能夠滿足基于文檔的進行問答需求。為了解決用戶需求和亞馬遜云科技服務之間的差距,借助亞馬遜云科技的服務,構(gòu)建了基于智能搜索的大語言模型增強方案。該方案以Amazon OpenSearch/Amazon Kendra為基礎構(gòu)建搜索引擎,結(jié)合托管到Amazon SageMaker上的大語言模型,提供一站式的智能知識庫搜索問答平臺。
基于智能搜索的大語言模型增強方案介紹
架構(gòu)圖
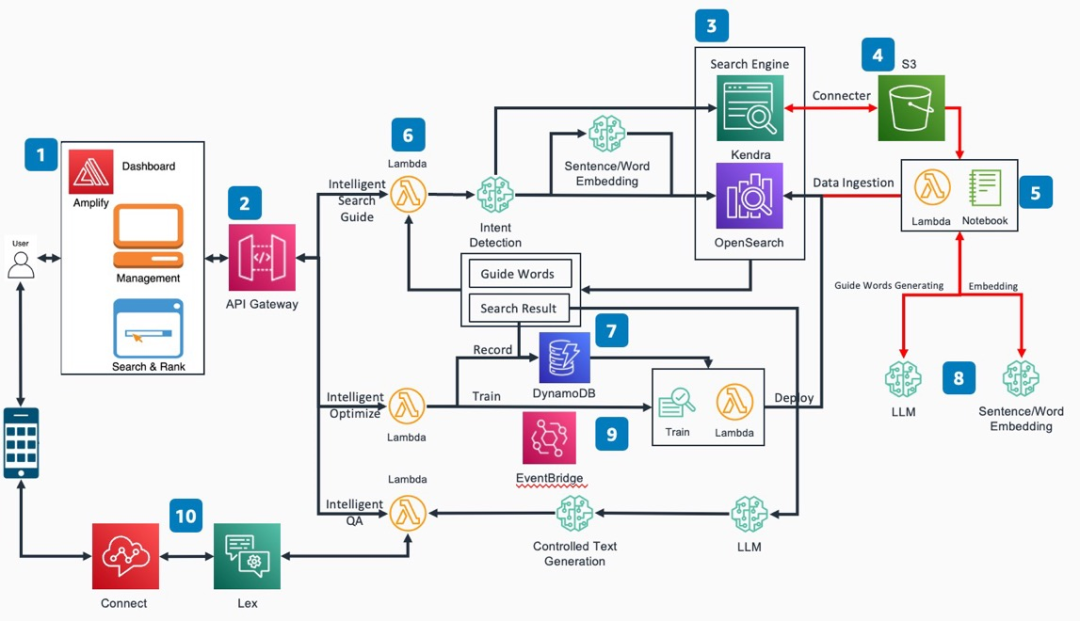
該平臺將包括五大核心內(nèi)容
1. 智能搜索
傳統(tǒng)僅依靠關鍵詞匹配的分詞搜索的方式在很多場景下可以提供快速有效的查詢,但是也存在一些固有的局限性。例如匹配一些包括停用詞在內(nèi)的無關詞匯,無法識別同義詞和缺乏抽象能力。為了解決這些問題,本方案中一方面使用意圖識別模型,對關鍵信息進行提取,從而可以有效的避免停用詞等無法詞匯對搜索造成的干擾。另一方面,引入AI/ML的方法來輔助實現(xiàn)語意搜索。具體來講,使用同一個向量編碼的模型對搜索語句和文檔數(shù)據(jù)庫進行語意編碼,在檢索的過程中,使用knn方法進行向量匹配。以下是一個傳統(tǒng)分詞搜索與語意向量搜索的對比展示。可以看到,使用向量搜索功能后,可以召回更多自然語意上相近而關鍵詞無關的內(nèi)容,增加召回范圍和提升搜索準確性。
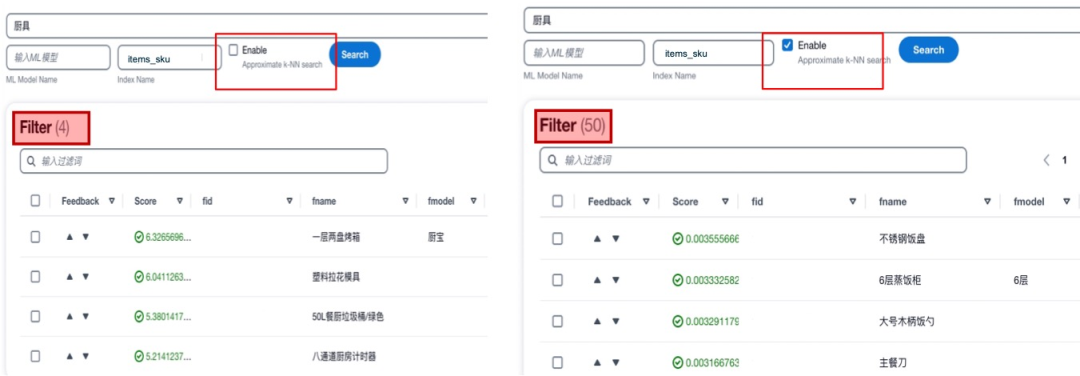
在本方案中,以Amazon OpenSearch和Amazon Kendra為基礎構(gòu)建搜索引擎。提供分詞搜索,模糊查詢和AI/ML輔助搜索功能。不在局限于某一種搜索方式,而是將所有搜索方法取長補短,進行有機的整合。
智能引導
造成搜索不準確的原因,一方面是由于搜索引擎本身的能力不足,另外一方面的原因是因為搜索的語句不夠準確和具體。因此,本方案中提出了一種引導式的搜索機制來幫助檢索人員逐步豐富輸入的搜索語句,最終達到提升搜索準確性的目的。
以下面制造業(yè)大型設備維保知識庫的搜索流程為例。該知識庫存儲歷史維修記錄,包括故障現(xiàn)象,故障原因,維修方案等字段。
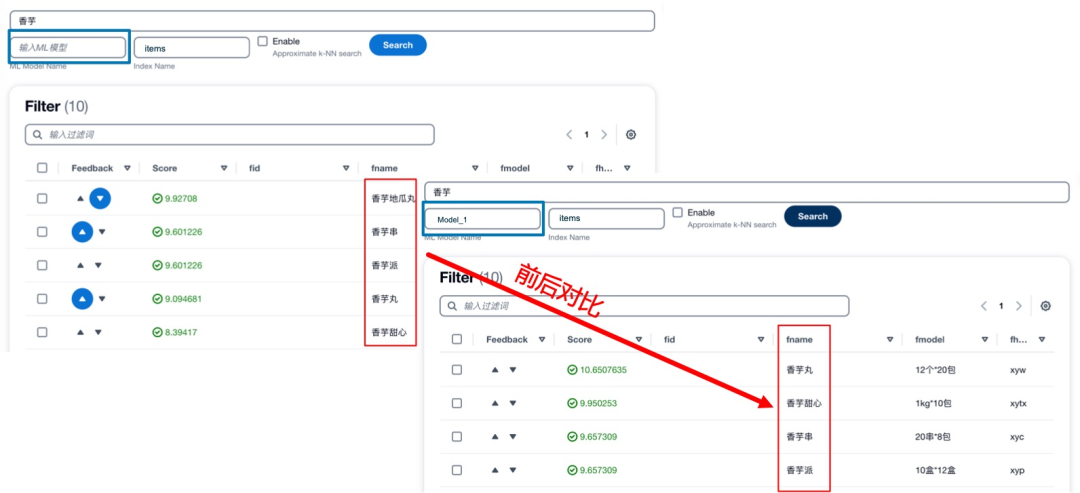
當用戶輸入檢索詞“電路”后,除了從知識庫中返回與電路相關的條目之外,還會給予一些提示詞,例如“門系統(tǒng)”、“控制系統(tǒng)”等,這些詞代表與“電路”相關的故障往往伴隨可能出現(xiàn)問題的系統(tǒng),提示用戶進一步豐富當前的搜索描述。
當用戶進一步輸入“主板”后,會將“電路”和“主板”進行聯(lián)合查詢,返回相關的條目,并進一步給出新的提示詞。
用戶可以重復以上過程,直到搜索出來更為精準的結(jié)果。

提示詞的獲取:根據(jù)實際情況,可以采用人工打標、無監(jiān)督聚類、有監(jiān)督分類、大語言模型(LLM)等方法進行提取,并提前注入到數(shù)據(jù)庫中。
智能優(yōu)化
通常情況下,由于知識庫的迭代更新,檢索的準確率可能會隨時時間的推薦逐步降低,一方面是因為我們往往不能保證,數(shù)據(jù)庫和搜索引擎一次性構(gòu)建完成后就達到很好的效果。另外一方面是因為對于過時的知識沒有進行有效的處理。因此,本方案提出以用戶行為對搜索引擎進行持續(xù)優(yōu)化。
具體來講包括兩個步驟:
用戶行為收集:將歷史用戶的行為進行收集,例如用戶對某個搜索詞條的打分。
模型訓練和部署:通過用戶行為,整理得到搜索詞條和知識庫之間的相關度。使用該相關度訓練和部署一個重排模型,該重排模型可以根據(jù)歷史的用戶行為,給予用戶更加偏好的內(nèi)容更高的權(quán)重得分。
值得注意的是,該模型是基于傳統(tǒng)機器學習模型xgboost的,所以所需要的訓練數(shù)據(jù)量和推理所需要的資源都是很小的(例如只需要幾十條數(shù)據(jù)和t3.small機型),因此可以基于不同的用戶/用戶群訓練不同的重排模型,達到千人千面,個性化搜索的目的。
4.智能問答
基于私有知識庫進行問答是另外一個廣泛應用的場景,例如智能客戶聊天機器人系統(tǒng),IT/HR系統(tǒng)智能問答系統(tǒng)等。
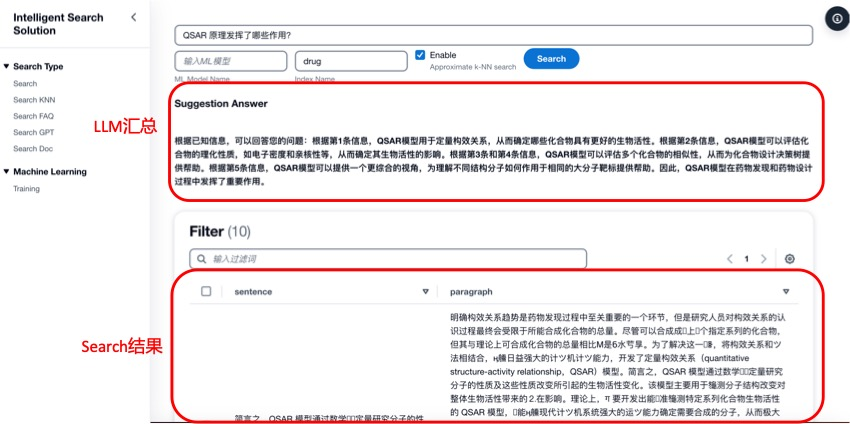
如果僅使用搜索引擎,只能基于問題從數(shù)據(jù)庫中提取與該問題相關的內(nèi)容,而不能直接給出答案。
如果僅使用大語言模型(Large Language Model,LLM),不能基于私有知識庫進行問答。一種可行的方式是將私有知識庫和問題直接以prompt的形式直接一次性給到LLM,然后讓LLM給出回答。但是受限于LLM Token的限制,無法一次性輸入過多的知識庫。
因此,在本方案中,將兩者結(jié)合。如下圖所示,當用戶提出一個問題后,首先使用搜索提取與問題相關的知識,然后再將問題和提取的知識給到LLM進行總結(jié),最后直接給出問題答案。
5. 非結(jié)構(gòu)化數(shù)據(jù)注入
可供搜索引擎進行檢索的企業(yè)知識庫是一種結(jié)構(gòu)化的數(shù)據(jù),但往往企業(yè)的原始知識都是以非結(jié)構(gòu)化的數(shù)據(jù)進行存儲的,來自多個渠道,也包含了多種格式,例如Words,PDF,Excel等。
為了能夠幫助企業(yè)快速將這些結(jié)構(gòu)化數(shù)據(jù)利用起來,本方案提供了非結(jié)構(gòu)化數(shù)據(jù)注入功能,該功能將企業(yè)的知識文檔進行自動段落拆分和向量編碼,建立結(jié)構(gòu)化企業(yè)知識庫。
模型技術細節(jié)
LLM
最近半年,大語言模型(LLM)在自然語言處理領域取得了飛速的發(fā)展。大語言模型通常基于Transformer架構(gòu),在大規(guī)模的網(wǎng)絡文本數(shù)據(jù)上進行訓練,其核心是使用一個自我監(jiān)督的目標來預測部分句子中的下一個單詞。亞馬遜云科技已推出大語言模型Titan和大語言模型平臺Amazon Bedrock,另外還有許多研究機構(gòu)推出開源大語言模型,如斯坦福大學的Alpaca和清華大學的ChatGLM等。這些大語言模型都具備強大的文本處理能力,廣泛應用在智能問答、文本總結(jié)、文本生成等場景。
Embedding
各類非結(jié)構(gòu)化數(shù)據(jù)廣泛存在于我們的生活和工作場景,如文本、圖片、視頻等,為了處理這些非結(jié)構(gòu)化數(shù)據(jù),亞馬遜云科技通常使用Embedding模型提取這些數(shù)據(jù)的特征,并把數(shù)據(jù)特征轉(zhuǎn)化成向量,通過特征向量對這些非結(jié)構(gòu)化數(shù)據(jù)進行分析和檢索。通用的預訓練語言模型都有把文本進行向量化的功能,可以根據(jù)不同的場景和語種,選用合適的預訓練模型作為Embedding模型。
Intent Detection
搜索意圖識別主要功能是分析用戶的核心搜索需求,例如在電商場景,用戶找的電子產(chǎn)品,是電腦類的,還是手機類的,是家庭場景用的,還是戶外場景用的等等,如果意圖識別不準,會有很多不相關的商品展現(xiàn)給用戶,導致產(chǎn)生非常差的用戶體驗,因此精準的意圖識別非常重要。意圖識別主要包括類目預測和實體識別模型,類目預測模型主要采用文本多分類模型,根據(jù)平臺的用戶行為數(shù)據(jù),將查詢文本預測屬于各個類目的概率。實體識別模型將查詢文本中的實體詞識別出來,實體詞是描述商品的維度信息,如品牌、顏色、材質(zhì)等,通過實體識別模型識別出查詢文本的實體詞后,再到搜索引擎進行精準查詢。
可控文本生成是在傳統(tǒng)文本生成的基礎上,增加對生成文本的控制,如指定生成文本的關鍵詞、格式、風格等,從而使生成的文本符合我們的預期,比如生成與某人相同風格的文本,生成有固定內(nèi)容格式的報告,根據(jù)簡單的故事線生成完整的小說等等。可控文本生成有對預訓練模型finetune、重新訓練文本生成模型和重構(gòu)預訓練模型輸出結(jié)果等方式。在大語言模型推出后,目前可以方便的通過Prompt提示詞,指導大語言模型進行可控文本生成,針對不同的場景和文本生成目標,設計不同格式和內(nèi)容的提示詞,生成滿足需求的文本。
審核編輯 黃宇
-
機器人
+關注
關注
213文章
31073瀏覽量
222162 -
AI
+關注
關注
91文章
39755瀏覽量
301354 -
數(shù)據(jù)庫
+關注
關注
7文章
4019瀏覽量
68335 -
語言模型
+關注
關注
0文章
571瀏覽量
11310 -
亞馬遜
+關注
關注
8文章
2731瀏覽量
85733
發(fā)布評論請先 登錄
設備維修總踩坑?故障知識庫 + AI 診斷,新手也能修復雜機

亞馬遜發(fā)布新一代AI芯片Trainium3,性能提升4倍

AI眼鏡或成為下一代手機?谷歌、蘋果等巨頭扎堆布局
亞馬遜云科技上線Amazon Nova多模態(tài)嵌入模型

亞馬遜云科技推出Amazon Quick Suite,引領Agentic AI驅(qū)動的工作新范式
【內(nèi)測活動同步開啟】這么小?這么強?新一代大模型MCP開發(fā)板來啦!
適用于下一代 GGE 和 HSPA 手機的多模/多頻段 PAM skyworksinc

零基礎在智能硬件上克隆原神可莉?qū)崿F(xiàn)桌面陪伴(提供人設提示詞、知識庫、固件下載)
亞馬遜云科技現(xiàn)已上線OpenAI開放權(quán)重模型
積算科技上線赤兔推理引擎服務,創(chuàng)新解鎖FP8大模型算力
華為開發(fā)者大會2025(HDC 2025)亮點:華為云發(fā)布盤古大模型5.5 宣布新一代昇騰AI云服務上線

歐洲借助NVIDIA Nemotron優(yōu)化主權(quán)大語言模型
如何借助大語言模型打造人工智能生態(tài)系統(tǒng)

AI知識庫的搭建與應用:企業(yè)數(shù)字化轉(zhuǎn)型的關鍵步驟
《AI Agent 應用與項目實戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識庫
- 設計技術
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術
- 測量儀表
- 嵌入式技術
- 制造/封裝
- 模擬技術
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設計
- 存儲技術
- 光電顯示
- EMC/EMI設計
- 連接器
- 行業(yè)應用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設備
- 機器人
- 安全設備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 電子發(fā)燒友
- 關于我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡
- 微博
- 移動端
- 發(fā)燒友APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 張迎輝:mikezhang@elecfans.com
-
關注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察

版權(quán)所有 ? 長沙勒克斯教育咨詢有限公司
湖南省長沙市開福區(qū)月湖街道匍園路20號聚恒科技園1棟2301-1房
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1
工商網(wǎng)監(jiān)
湘ICP備2023036445號-105-1
評論