 低延遲SSD上的快速圖處理
低延遲SSD上的快速圖處理

一、背景
圖處理在社交媒體、導航、推薦等領域應用廣泛。很多場合下圖數據往往非常大以至于難以在單個機器的內存中存儲。分布式圖處理選擇將圖數據存儲在分布式集群的內存中;而與分布式圖處理不同,外部圖處理系統選擇在單臺機器上利用二級存儲來輔助存儲圖數據,同時也能提供與分布式圖處理相近或更優的性能。外部圖處理系統根據存儲方式可以進一步分為半外部系統和全外部系統。前者將圖數據中的頂點數據存儲在內存、邊數據存儲在SSD中;后者則將兩者都存儲在SSD中。本文提出的Blaze就屬于半外部系統。
二、問題
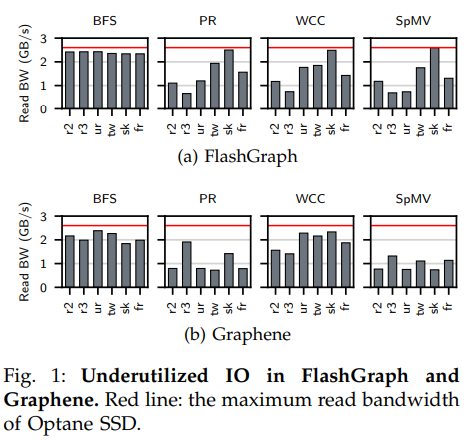
盡管現在新興的快速NVMe SSD提供了比過去的SSD更高的帶寬,但是現有的半外部圖處理系統不能充分利用這些快速SSD帶來的性能提升。本文通過實驗(上圖)發現主要問題為IO利用率低下,可以看出在兩個代表性的半外部處理系統中除了BFS算法以外其他例程的執行中IO帶寬(柱)都遠未達到快速SSD的最大帶寬(紅線)。
本文作者認為IO利用率低下的原因主要包含3個方面:計算傾斜、IO傾斜、IO快計算慢。
1. 計算傾斜
并行圖處理系統需要同步機制來避免并發更新算法相關的頂點數據時出現競爭。現有的半外部圖處理系統FlashGraph采用消息機制來解決同步問題,它為每個頂點分配了一個消息隊列,并按照頂點ID將每個頂點分派給一個計算線程。圖算法迭代性地執行,在執行的每一個迭代中頂點間通過消息通信;在迭代結束的時候系統處理這些消息,并根據處理的結果更新頂點數據。
對于FlashGraph而言,由于圖結構服從照冪律分布,一些線程需要比其他的處理更多消息,即計算傾斜。而(下一迭代的)IO必須得等待這種落伍線程完成處理才能開始。快速SSD在本輪迭代中的IO操作很可能比這個落伍線程完成的早,導致其空閑。
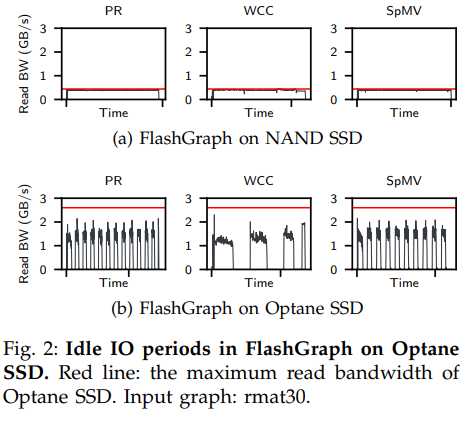
下圖的實驗證明快速SSD(Optane SSD)相較于低速SSD(圖中NAND SSD)帶來的帶寬提升(紅線為磁盤最大讀取帶寬)確實造成了上述問題,造成了IO更多的空閑。
2. IO傾斜
為了更大的容量和帶寬,一些半外部圖處理系統會將邊數據分布在多塊磁盤中。而當IO負載不均的時候顯然會造成部分磁盤比其他磁盤完成IO更慢而造成其他磁盤的空閑。
另一個半外部圖處理系統Graphene采用了一種2D圖分區技術以將邊均勻地分配到每個分區,并將這些分區均勻分布到多個磁盤上。盡管其分布均勻,但是Graphene在執行采用了邊數據選擇性調度的算法的時候仍然受IO傾斜的影響。
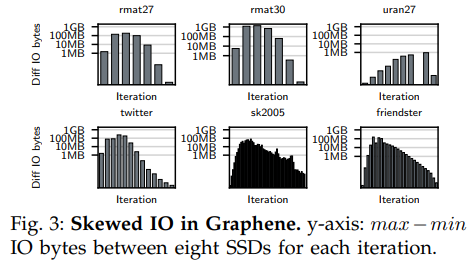
下圖中的實驗證實了上述問題,圖中縱軸表示每輪迭代中各個磁盤間最大IO量減去最小IO量。盡管均勻分布的數據集可能有著低于1MB的傾斜,但對于其他冪律分布的圖則有著最大可達100MB的傾斜。
3. IO快計算慢
Graphene為每個SSD分配了一個計算核心和一個IO核心,對于慢速SSD而言這樣的設計可以最大化IO帶寬;然而對于快速SSD而言這樣的設計導致計算速度比IO更慢,IO填滿緩沖區的速度比計算使用的速度更快,導致緩沖區填滿后IO必須等待新的緩沖區。
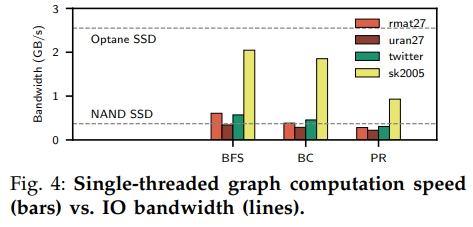
下圖中的實驗對比了計算的速度和存儲設備的讀取帶寬,可以看出計算的速度比快速SSD要慢得多,證明了上述問題。
三、設計
1. Online binning
Blaze采用名為Online binning的機制應對計算傾斜的問題。Bin是存儲在內存中的數據結構,存儲了多條bin record,而bin record則是包含頂點ID和一個數值。Blaze在算法執行時根據目標頂點ID和用戶定義的scatter函數的返回值創建bin record,然后對頂點ID取模計算出需要進入的bin ID。填滿的bin被推入名為full_bins的并發隊列,由gather線程取出處理。每個gather線程獨自處理一個填滿的bin,以避免同步開銷。
2. 頁面交織
為了應對IO傾斜的問題,Blaze采用了頁面交織的存儲方式來存儲邊數據。頁面交織基本類似RAID 0的方式。Blaze將CSR格式存儲的邊數據以4KB粒度交織分布到多個SSD上。
3. Blaze整體執行流程
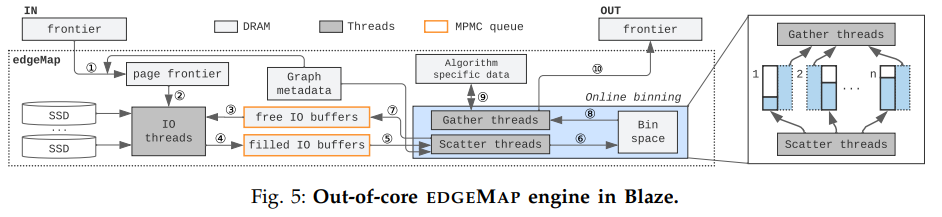
圖算法一般按迭代執行,上圖提供了Blaze中每輪迭代中的處理流程。
作為輸入之一,算法程序會提供需要處理的頂點ID。為了接下來訪問各個頂點的邊列表,Blaze在第1步發動所有可用的線程將頂點ID集合轉換成其邊列表所在的磁盤頁面ID集合(即page frontier內容)。轉換完成后根據其磁盤頁面ID從SSD中訪問數據,寫入到空的IO buffer中,生成滿的IO buffer。Scatter線程取出填滿的IO buffer,計算并生成bin record裝入對應的bin,并將用完的IO buffer還給空IO buffer池。Gather線程取出填滿的bin并處理,根據處理結果修改算法相關的頂點數據。最后返回下一個迭代所需要處理的頂點集合。
四、實驗評估
1. 實驗設置
實驗測試平臺是一臺單處理器(Intel Xeon Gold 6230,20核心,禁用超線程),96GB內存的機器,存儲配置了一塊960GB的快速SSD(Intel DC P4800X)。
對比的算法包含:BFS、PageRank、WCC、稀疏矩陣乘(SpMV)、BC。
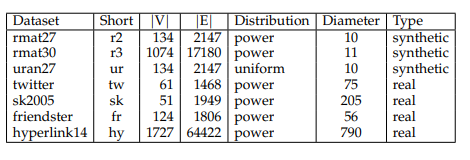
數據集如下表所示:
2. 系統對比
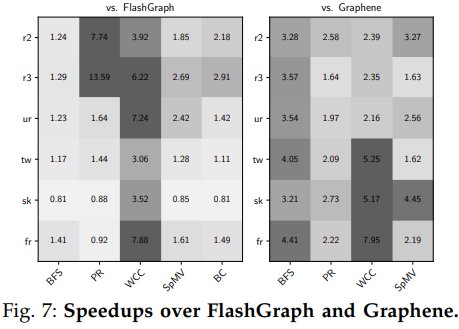
本文將Blaze與FlashGraph和Graphene分別作了對比計算了加速比,加速比如下圖所示(Graphene沒有實現BC算法所以沒做對比)。除了sk2005數據集中FlashGraph表現更優以外總體都有一定提升。sk2005數據集上的處理有著更高的局部性,FlashGraph的LRU頁面緩存借此減少了存儲訪問,而Blaze并沒有針對頁面緩存做專門的優化。
3. IO利用率
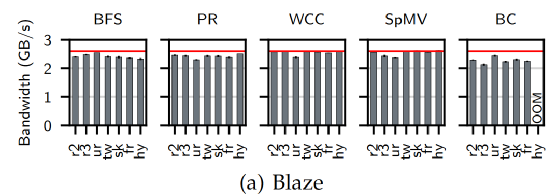
IO利用率的評估如下圖所示,可以看出Blaze的平均IO帶寬基本達到快速SSD的帶寬。
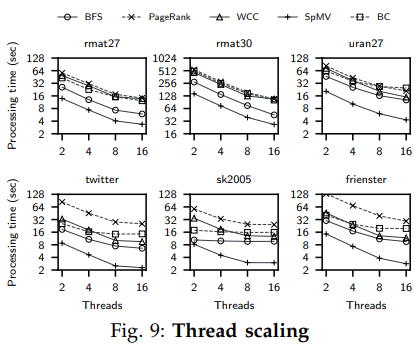
4. 可擴展性
實驗表明Blaze的性能大致隨著核心數的增加而線性增長,除了少部分負載下(如sk2005上的BFS)較快地飽和了IO帶寬而不能擴張其性能。
五、總結
本文提出了一個新的半外部圖處理系統Blaze。Blaze采用了全新的scatter-gather技術,online binning,解決了現有半外部圖處理系統應用快速SSD后不能充分利用其高帶寬的問題。
審核編輯:劉清
-
處理器
+關注
關注
68文章
20300瀏覽量
253668 -
CSR
+關注
關注
3文章
120瀏覽量
70848 -
SSD
+關注
關注
21文章
3135瀏覽量
122365 -
BFS
+關注
關注
0文章
9瀏覽量
2315
原文標題:Blaze:低延遲SSD上的快速圖處理
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
DP83826:確定性、低延遲、低功耗工業以太網PHY的卓越之選
DP83826Ax工業以太網PHY:確定性、低延遲與低功耗的完美融合
DP83826Ax:確定性、低延遲工業以太網PHY的深度解析
兼容性高,延遲低,慧視定制CVBS接口AI圖像處理板

巡檢機器人落地攻略:RK3576驅動12路低延遲視覺
車載360環視平臺:米爾RK3576開發板支持12路低延遲推流
新唐科技推出低延遲音頻編解碼器NAU88L21C

12 路低延遲推流!米爾 RK3576 賦能智能安防 360° 環視

延遲低至30ms+ LLSM流媒體傳輸模塊低延遲方案推薦
明遠智睿SSD2351開發板:語音機器人領域的變革力量
LLSM——基于RK3588的低延遲低帶寬流媒體傳輸模塊
XMOS直播聲卡——可支持實時音頻DSP處理的低延遲音頻方案



 工商網監
工商網監
評論