") 什么是索引合優(yōu)化?探究一下索引合并的幾種情況
什么是索引合優(yōu)化?探究一下索引合并的幾種情況

什么是索引合優(yōu)化
在使用 explain 命令分析 SQL 執(zhí)行情況的時候,type列會描述了表如何被連接,這個列的內(nèi)容直接反映了 SQL 執(zhí)行的效率。當(dāng)里面的內(nèi)容展示為 index_merge時表示使用了索引合并優(yōu)化,在這種情況下輸出行中的key列包含具體使用的索引。
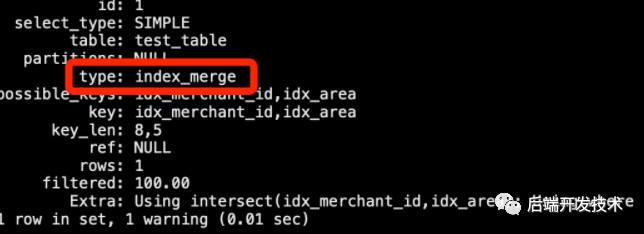
MySQL 的索引合并優(yōu)化是一種查詢優(yōu)化技術(shù),它利用多個索引來加速查詢的執(zhí)行。當(dāng)一個查詢中包含多個條件,并且這些條件分別適用于不同的索引時,MySQL 可以將這些索引合并起來使用,減少了回表的次數(shù),以加速查詢的執(zhí)行。
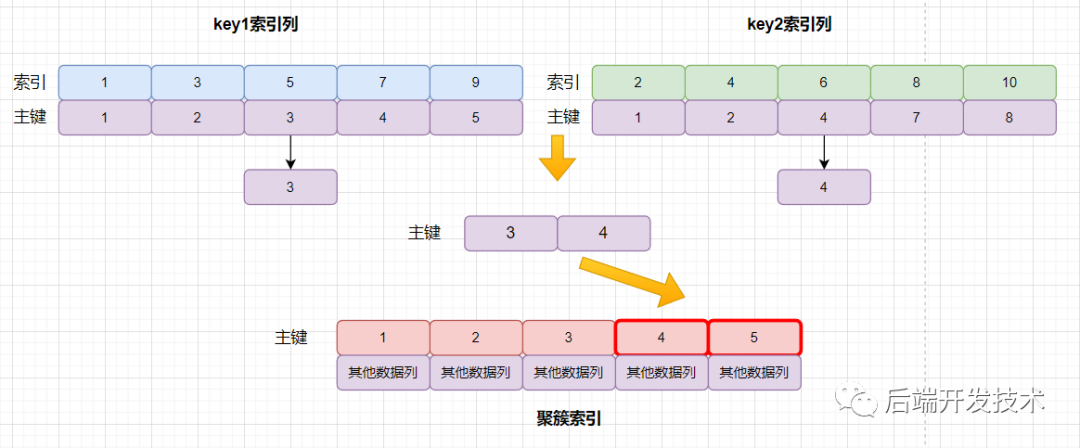
簡單來說過程是這樣:
查詢條件同時包含 index1 和 index2。
在根據(jù) index1 和 index2 查詢到主鍵后并沒有直接分別去聚簇索引中查詢,而是先對他們查到的主鍵做處理,合并到一起。
根據(jù)處理后的主鍵去聚簇索引執(zhí)行查詢,只需一次回表就可以拿到結(jié)果。
下面我們探究一下索引合并的幾種情況。
準備
我們使用如下數(shù)據(jù)做測試,并且建立了三個索引。
CREATETABLE`test_table`( `id`bigint(20)NOTNULLAUTO_INCREMENT, `user_id`bigint(20)NOTNULL, `name`varchar(255)DEFAULT'', `merchant_id`bigint(20)NOTNULL, `area`int(11)DEFAULTNULL, PRIMARYKEY(`id`), UNIQUEKEY`uq_user_id`(`user_id`)USINGBTREE, KEY`idx_merchant_id`(`merchant_id`)USINGBTREE, KEY`idx_area`(`area`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=410DEFAULTCHARSET=utf8mb4
在表中,我初始化了 100 多條數(shù)據(jù)用于測試。
基本用法
Index Merge 通過多次 range掃描檢索行并將它們的結(jié)果合并為一個。僅限合并來自單個表的索引掃描,而不是跨多個表的掃描。合并可以產(chǎn)生其底層掃描的并集、交集或交集并集,所以產(chǎn)生了三種算法。
可以使用索引合并的示例查詢:
SELECT*FROMtest_tableWHEREmerchant_id=3ORarea=3; SELECT*FROMtest_tableWHERE(merchant_id=3ORarea=3)ANDname='daniel'; SELECT*FROMt1,t2 WHERE(t1.key1IN(1,2)ORt1.key2LIKE'value%') ANDt2.key1=t1.some_col; SELECT*FROMt1,t2 WHEREt1.key1=1 AND(t2.key1=t1.some_colORt2.key2=t1.some_col2);
索引合并優(yōu)化算法注意事項如下 :
1、如果您的查詢有一個復(fù)雜的WHERE 子句,帶有深度 AND/OR 嵌套,而 MySQL 沒有選擇最佳執(zhí)行計劃,請嘗試使用以下恒等變換。
(xANDy)ORz=>(xORz)AND(yORz) (xORy)ANDz=>(xANDz)OR(yANDz)
2、Index Merge 不適用于全文索引。
三種算法
Index Merge 訪問方法有幾種算法,顯示在輸出Extra字段 中EXPLAIN:
交集算法Using intersect(...)
并集算法 Using union(...)
排序并集算法Using sort_union(...)
下面我們詳細介紹這些算法,優(yōu)化器根據(jù)各種可用選項的成本估算,在不同的索引合并算法之間進行選擇。
Index Merge 的使用受制于 系統(tǒng)變量的index_merge、 index_merge_intersection、 index_merge_union和 index_merge_sort_unionflags 的值optimizer_switch 。默認情況下,所有這些標志都是on. 要僅啟用某些算法,請設(shè)置index_merge 為off,并僅啟用應(yīng)允許的其他算法。
1.交集算法
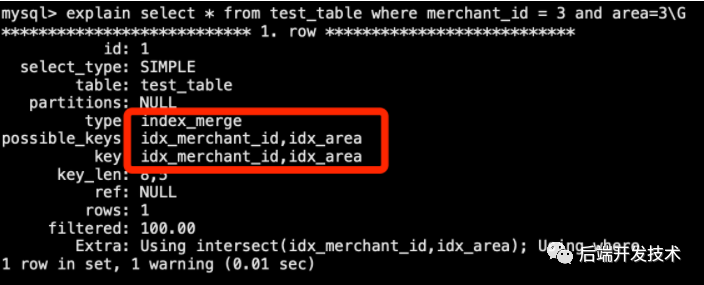
當(dāng)查詢條件是多個查詢的時候,并且條件用 and 關(guān)聯(lián),這種情況會使用交集(intersect)算法,滿足以下條件之一都可以。
這種形式的 -part 表達式*N*,其中索引具有精確的 *N*部分(即,所有索引部分都被覆蓋):
key_part1=const1ANDkey_part2=const2...ANDkey_partN=constN
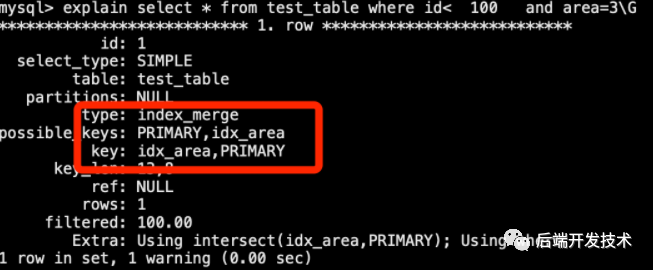
InnoDB 引擎下使用主鍵范圍條件查詢。如果其中一個 merge 條件是對表主鍵的范圍查詢,則它不用于行檢索,而是用于過濾掉使用其他條件檢索的行。
explainselect*fromtest_tablewhereid
索引合并交集算法對所有使用的索引執(zhí)行同時掃描,并生成它從合并索引掃描中接收到的主鍵的交集。如果查詢中使用的所有列都被使用的索引覆蓋,則不會檢索完整的表行(具體使用的算法輸出在 Extra 字段中)。
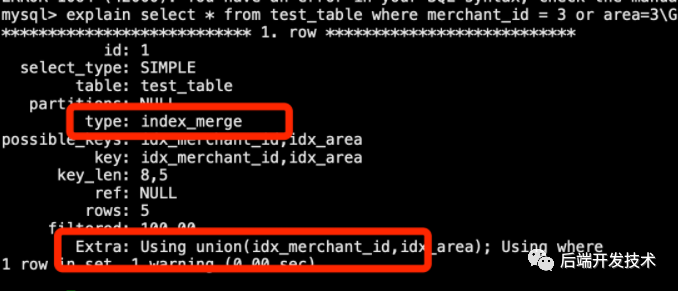
2.并集算法
并集(union)算法適用于將表的WHERE 子句轉(zhuǎn)換為不同索引列組合的多個范圍條件,并且使用OR關(guān)聯(lián),且每個條件為以下之一:
不同普通索引列使用 or 關(guān)聯(lián)
key_part1=const1ORkey_part2=const2...ORkey_partN=constN
InnoDB引擎下主鍵使用范圍查詢
例子:
explainselect*fromtest_tablewheremerchant_id=3orarea=3;
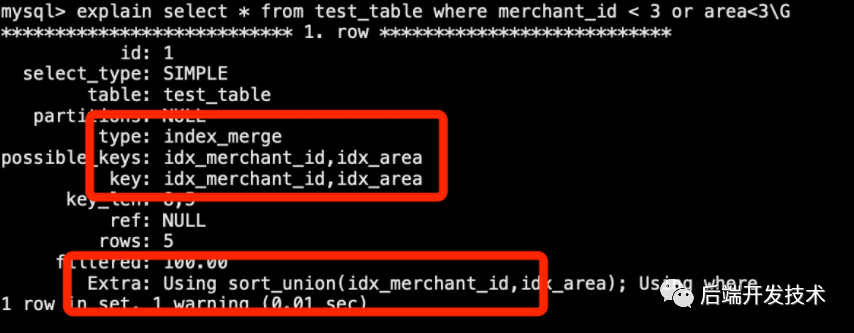
3.排序并集算法
排序并集(sort_union)算法適用于由 or 關(guān)鍵詞組合的多個范圍查詢。
例子:
explainselect*fromtest_tablewheremerchant_id
sort-union 算法和 union 算法之間的區(qū)別在于,sort-union 算法必須首先獲取所有行的行 ID ,然后在回表之前它們進行排序。
審核編輯:劉清
-
SQL
+關(guān)注
關(guān)注
1文章
803瀏覽量
46825 -
MYSQL數(shù)據(jù)庫
+關(guān)注
關(guān)注
0文章
97瀏覽量
10290
原文標題:面試官:會SQL調(diào)優(yōu),那你知道索引合并嗎?
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
如何利用Flood多維索引技術(shù)實現(xiàn)優(yōu)化數(shù)據(jù)存儲布局

基于索引的SQL語句優(yōu)化之降龍十八掌
LV Nugget之?dāng)?shù)組索引的妙用
LabVIEW Nugget之?dāng)?shù)組索引的妙用
求各位大神指點一下,關(guān)于自動索引
Mysql優(yōu)化選擇最佳索引規(guī)則
MySQL索引的使用問題
一百道關(guān)于MySQL索引解答
數(shù)據(jù)庫索引使用策略及優(yōu)化

MySQL高級進階:索引優(yōu)化
Mysql索引是什么東西?索引有哪些特性?索引是如何工作的?
導(dǎo)致MySQL索引失效的情況以及相應(yīng)的解決方法
MATLAB中的矩陣索引



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論