 Linux中提高指令緩存命中率
Linux中提高指令緩存命中率

提高指令緩存命中率
前面說的是數據緩存,現在看看指令緩存命中率該如何提高。
有一個數組array,數組元素內容為0-255之間的隨機數:
int array[N];
for (i = 0; i < TESTN; i++)
array[i] = rand() % 256;
現在,要把數組中數字小于128的元素置為0,并且對數組排序。
大家應該都能想到,有兩種方法:
- 先遍歷數組,把小于128的元素置為0,然 后排序 。
- 先對數組排序 , 再遍歷數組 ,把小于128的元素置為0。
for(i = 0; i < N; i++) {
if (array [i] < 128)
array[i] = 0;
}
sort(array, array +N);
先排序后遍歷的速度會比較快,為什么?
因為在for循環中會執行很多次if分支判斷語句,而CPU擁有分支預測器。
如果分支預測器可以預測接下來要執行的分支(執行if還是執行else),那么就可以提前把這些指令放到緩存中,CPU執行的時候就會很快了。
如果一個數組的內容完全隨機的話,那么分支預測器就很難進行正確的預測。但如果數組內容是有序的,它就會根據歷史命中數據的情況對未來進行預測,那命中率就會很高,所以先排序后遍歷的速度會比較快。
怎么驗證指令緩存命中率的情況呢?
在Linux下,可以使用Perf性能分析工具進行驗證。通過-e選項,指定branch-loads和branch-loads-misses事件,可以分別統計出分支預測成功的次數和 分支預測失敗的次數 ,通過L1-icache-load-misses事件也能統計一級緩存中指令未命中的次數。但是,這些性能事件都屬于硬件事件,perf工具能否統計這些事件取決于CPU是否支持以及芯片原廠是否去實現了該接口,我看很多都是不支持或者沒實現的。
另外,在Linux內核中,可以看到大量的likely和unlikely宏,并且它們都出現if語句中,這 兩個宏的作用就是為了提高性能 。
這是顯示預測概率的宏,如果你覺得CPU的分支預測不準,但if中條件為"真"的概率很高,那么你就可以使用likely()括起來,以此提升性能。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
if (likely(a == 1)) …
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
Linux
+關注
關注
88文章
11758瀏覽量
219005 -
指令
+關注
關注
1文章
623瀏覽量
37529 -
緩存
+關注
關注
1文章
248瀏覽量
27760 -
數組
+關注
關注
1文章
420瀏覽量
27351
發布評論請先 登錄
相關推薦
熱點推薦
CPU一級緩存與二級緩存深度分析
CPU緩存:通過優化的的讀取機制,可以使CPU讀取緩存的命中率非常高,也就是說CPU下一次要讀取的數據90%都在緩存中,只有大約10%需要從內存讀取。
AM335x SDK關于cache的命中率,請問有能改善cache命中率的有效方法嗎?請問怎么才能控制RAM映射到cache?
()④CP15DCacheEnable()⑤CP15DCacheCleanFlush()①~④確定能使cache無效/有效嗎?⑤是否有清除cache的功能?■二:關于cache的命中率 請問有能改善cache命中率的有效方法
發表于 06-21 04:06
緩存命中率低的原因是什么?
匯編中加載數據用的是LDW,5個cycle之后就會到達寄存器,并沒有體現出緩存命中率的問題。LDW是固定5個cycle,請問緩存命中率低,帶來的延遲體現在什么地方?難道是LDW之前,有
發表于 05-25 08:46
基于節點中心性度量的緩存機制
為了降低內容中心網絡的緩存內容冗余度和提高緩存內容命中率,提出一種基于節點中心性度量的緩存機制(CMC)。CMC利用控制器獲取整個網絡的拓撲
發表于 01-17 11:00
?0次下載
基于概率存儲的啟發式住處中心網絡內容緩存方法
概率時綜合考慮內容熱度和緩存放置收益,即內容熱度越高,放置收益越大的內容被緩存的概率越高。實驗結果表明,PCP在緩存服務率、緩存
發表于 02-11 11:16
?0次下載
Web代理服務器緩存優化
Web代理服務器緩存能在一定程度上減少網絡擁塞現象和用戶的訪問延遲,減輕服務器負載。然而Web代理緩存的緩存命中率和字節命中率較低,并不能很
發表于 03-06 10:00
?0次下載
基于節點熱度與緩存替換率的ICN協作緩存
內容,考慮網絡流量在不同區域和不同時間段內的差異性,周期性地計算節點熱度和緩存替換率,并將其作為內容是否被緩存在節點上的度量指標。實驗結果表明,相對于LCE和CLFM策略,該策略能有效降低平均請求跳數和源端
發表于 03-29 15:17
?1次下載
一種基于內容優先級的緩存替換策略PFC
,將其作為緩存替換的參考因子進行緩存替換決策,以提高重要內容的命中率和可用性。在 ndnsim仿真平臺上的測試結果表明,相比LRU和FIFO策略,PF℃策略在不影響全局
發表于 03-24 14:48
?9次下載

把進程綁定到某個 CPU 上運行是怎么實現?
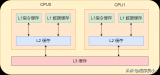
、L2緩存,而L3緩存是共用的。如果一個進程在核心間來回切換,各個核心的緩存命中率就會受到影響。相反如果進程不管如何調度,都始終可以在一個核心上執行,那么其數據的L1、L2



 工商網監
工商網監
評論