") 一個(gè)任務(wù)通用的的指令微調(diào)Embedder!
一個(gè)任務(wù)通用的的指令微調(diào)Embedder!

隨著指令微調(diào)模型的發(fā)展,開(kāi)始有人思考既然指令微調(diào)可以用來(lái)提升語(yǔ)言模型的性能,那么是否也可以用類似的方法來(lái)提升文本嵌入模型的性能呢?于是本文作者提出了INSTRUCTOR,這個(gè)模型設(shè)計(jì)了一種通用的Embedder,使得文本嵌入表示能更好地遷移到新的任務(wù)和領(lǐng)域,而不需要額外的訓(xùn)練。這個(gè)想法也是很有意思的,具體的請(qǐng)看下文吧~
背景介紹
現(xiàn)有的文本嵌入表示方法在應(yīng)用到新的任務(wù)或領(lǐng)域時(shí),通常性能都會(huì)受損,甚至應(yīng)用到相同任務(wù)的不同領(lǐng)域也會(huì)遇到同樣的問(wèn)題。常見(jiàn)的解決辦法是通過(guò)針對(duì)下游任務(wù)和領(lǐng)域的數(shù)據(jù)集進(jìn)一步微調(diào)文本嵌入,而這個(gè)工作通常需要大量的注釋數(shù)據(jù)。
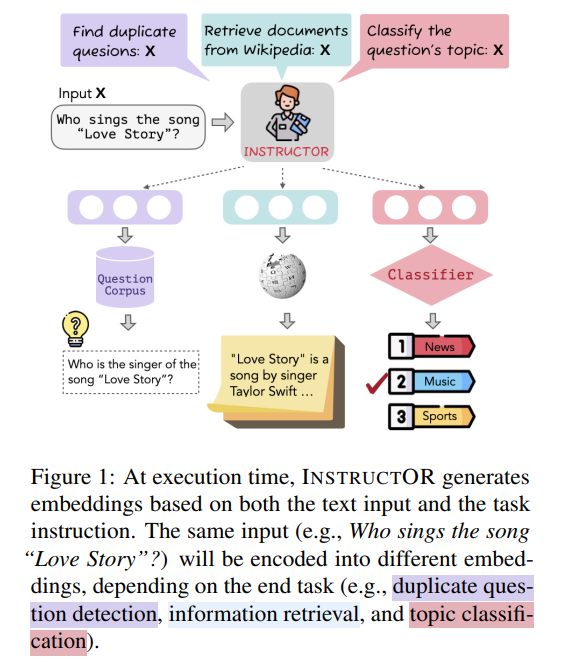
本文提出的INSTRUCOR(Instruction-basedOmnifariousRepresentations)不需要針對(duì)特定任務(wù)或領(lǐng)域進(jìn)行微調(diào)就可以生成輸入文本的嵌入。該模型在70個(gè)嵌入評(píng)價(jià)數(shù)據(jù)集上表現(xiàn)比SOTA嵌入模型平均要高3.4%。INSTRUCTOR和以往的模型不同,它向量表示不僅包含輸入文本還有端任務(wù)和領(lǐng)域的指令。并且針對(duì)不同的目標(biāo),對(duì)于同一個(gè)輸入文本,INSTRUCTOR會(huì)將輸入表示為不同的嵌入。例如圖1中Who sings the song “Love Story”?會(huì)根據(jù)不同的任務(wù)被表示為不同的嵌入。
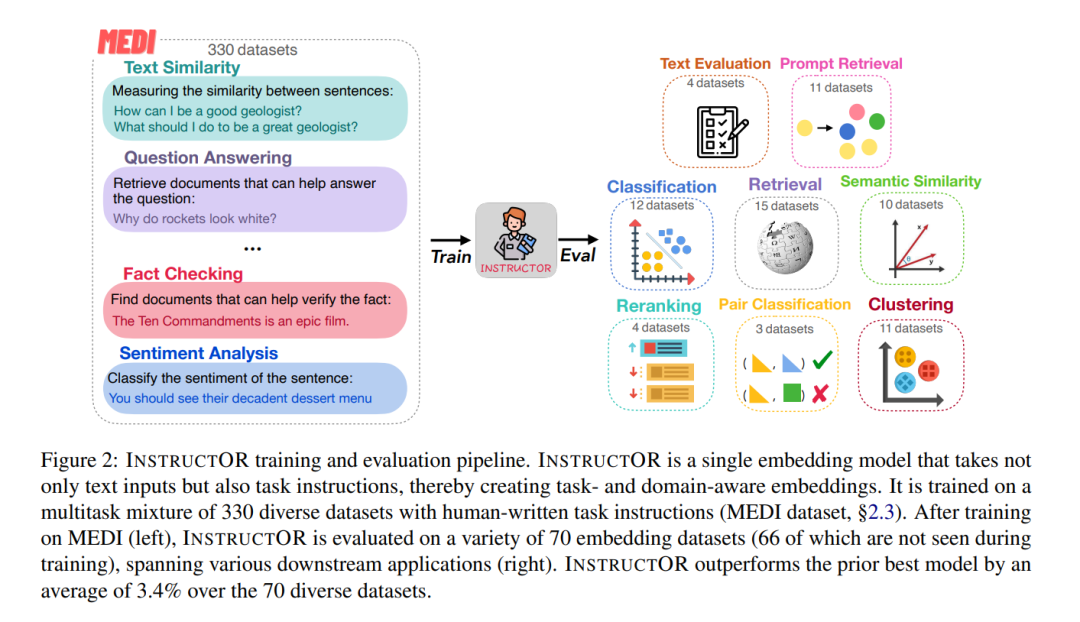
如圖2所示,INSTRUCTOR是在MEDI上進(jìn)行訓(xùn)練的,MEDI是我們的330個(gè)文本嵌入數(shù)據(jù)集的新集合,新標(biāo)注了人工編寫的任務(wù)指令。我們?cè)谒袛?shù)據(jù)集上使用對(duì)比損失來(lái)訓(xùn)練INSTRUCTOR,從而最大化語(yǔ)義相關(guān)文本對(duì)之間的相似性,同時(shí)最小化不相關(guān)文本對(duì)的相似性。
INSTRUCTOR
結(jié)構(gòu)
INSTRUCTOR基于單個(gè)Encoder來(lái)設(shè)計(jì),使用GTR系列模型作為框架(GTR-Base for INSTRUCTOR-Base,GTR-Large for INSTRUCTOR,GTR-XL for INSTRUCTOR-XL)。GTR模型使用T5進(jìn)行初始化。不同大小的GTR使得我們指令微調(diào)嵌入模型的表現(xiàn)也不同。給定一個(gè)輸入文本以及任務(wù)指令,INSTRUCTOR將他們組合成,然后通過(guò)對(duì)的最后一個(gè)隱藏表征進(jìn)行均值池化來(lái)生成固定大小、特定任務(wù)的嵌入。
訓(xùn)練目標(biāo)
通過(guò)將各種任務(wù)轉(zhuǎn)為文本到文本的方式來(lái)訓(xùn)練INSTRUCTOR,給定輸入,需要去區(qū)分好/壞候選輸出,其中訓(xùn)練樣本對(duì)應(yīng)于元組,其中和分別是與和相關(guān)的指令。例如,在檢索任務(wù)中,是查詢,好/壞是來(lái)自某個(gè)文檔的相關(guān)/不相關(guān)文檔。
輸入的候選的好由相似度給出,即它們的INSTRUCTOR嵌入之間的余弦:
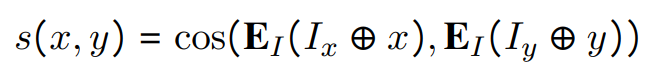
最大化正樣本對(duì)之間的相似度,并最小化負(fù)樣本對(duì)之間的相似度,其中表示每個(gè)正樣本對(duì)的負(fù)樣本對(duì)的數(shù)量,訓(xùn)練目標(biāo):
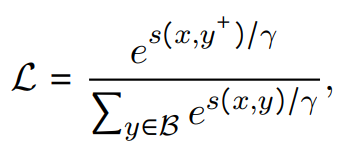
其中是softmax的溫度,是和的并集。此外還加入了雙向批內(nèi)采樣損失。
MEDI: Multitask Embedding Data with Instructions
MEDI(MultitaskEmbeddingsData withInstructions)是我們由330個(gè)數(shù)據(jù)集構(gòu)造而成,該數(shù)據(jù)集包含不同任務(wù)和領(lǐng)域的指令。
數(shù)據(jù)構(gòu)造:使用來(lái)自super-NI的300個(gè)數(shù)據(jù)集,另外30個(gè)來(lái)自現(xiàn)有的為嵌入訓(xùn)練設(shè)計(jì)的數(shù)據(jù)集。super-NI數(shù)據(jù)集附帶自然語(yǔ)言指令,但不提供正負(fù)樣本對(duì)。我們使用Sentence-T5嵌入來(lái)構(gòu)建樣本對(duì),用表示。對(duì)于分類數(shù)據(jù)集,我們基于輸入文本嵌入計(jì)算樣本之間的余弦相似度。如果兩樣本具有相同的類標(biāo)簽,則使用與高度相似的示例創(chuàng)建一個(gè)正樣本對(duì),如果標(biāo)簽不同,則創(chuàng)建一個(gè)負(fù)樣本對(duì)。對(duì)于輸出標(biāo)簽為文本序列的其余任務(wù),首先計(jì)算以下分?jǐn)?shù):
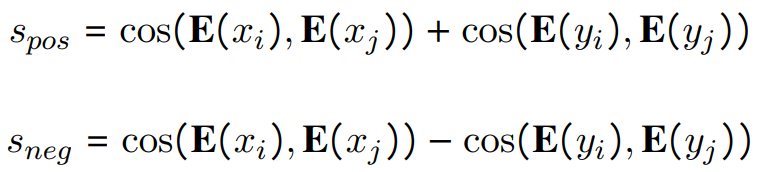
選擇最高的樣本作為正樣本對(duì),并選擇具有最高的作為負(fù)樣本對(duì)。其他30個(gè)嵌入訓(xùn)練數(shù)據(jù)集來(lái)自Sentence Transformers embedding data、KILT、MedMCQA。這30個(gè)數(shù)據(jù)集已經(jīng)包含正樣本對(duì);其中MSMARCO和Natural Questions也包含負(fù)樣本對(duì)。我們?cè)谀P臀⒄{(diào)過(guò)程中使用了4個(gè)負(fù)樣本對(duì)。
指令注釋:每一個(gè)MEDI的實(shí)例都是一個(gè)元組。為了引入指令,我們?cè)O(shè)計(jì)了一個(gè)統(tǒng)一的指令模板:
- 文本類型:指定輸入文本的類型。例如,對(duì)于開(kāi)放域QA任務(wù),查詢的輸入類型是問(wèn)題,而目標(biāo)的輸入類型是文檔。
- 任務(wù)目標(biāo)(可選項(xiàng)):描述輸入文本在該任務(wù)中如何使用。
- 領(lǐng)域(可選項(xiàng)):描述任務(wù)領(lǐng)域
最終的指令格式:“REPRESENT THE(DOMAIN)TEXT TYPEFORTASK OBJECTIVE:."
實(shí)驗(yàn)
用MEDI數(shù)據(jù)集對(duì)INSTRUCTOR進(jìn)行訓(xùn)練,并在70個(gè)下游任務(wù)對(duì)其進(jìn)行評(píng)估。使用了MTEB基準(zhǔn),該基準(zhǔn)由7個(gè)不同任務(wù)類別(如分類、重新排序和信息檢索)的56個(gè)數(shù)據(jù)集組成。然后,我們進(jìn)一步將INSTRUCTOR應(yīng)用于上下文學(xué)習(xí)和文本生成評(píng)估的提示檢索。在三種設(shè)置中,INSRTUCTOR都達(dá)到了最先進(jìn)的性能。
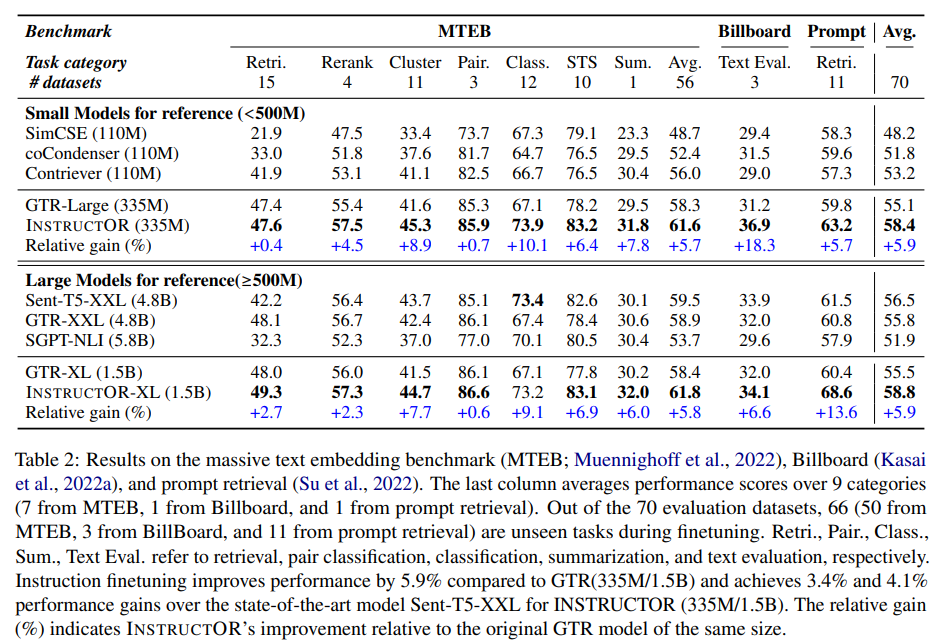
正如預(yù)期的那樣,基于檢索的模型(如GTR-XXL)在檢索和重排序方面表現(xiàn)出較強(qiáng)的性能,但在STS和分類方面明顯落后。相反,基于相似性的模型(例如,Sent-T5-XXL)在STS、分類和文本評(píng)估方面表現(xiàn)良好,但在檢索方面表現(xiàn)不佳。這表明,這些基線傾向于生成只擅長(zhǎng)某些任務(wù)的專門嵌入,而INSTRUCTOR提供了在不同任務(wù)類別上表現(xiàn)良好的通用嵌入。
分析以及消融實(shí)驗(yàn)
指令的重要性
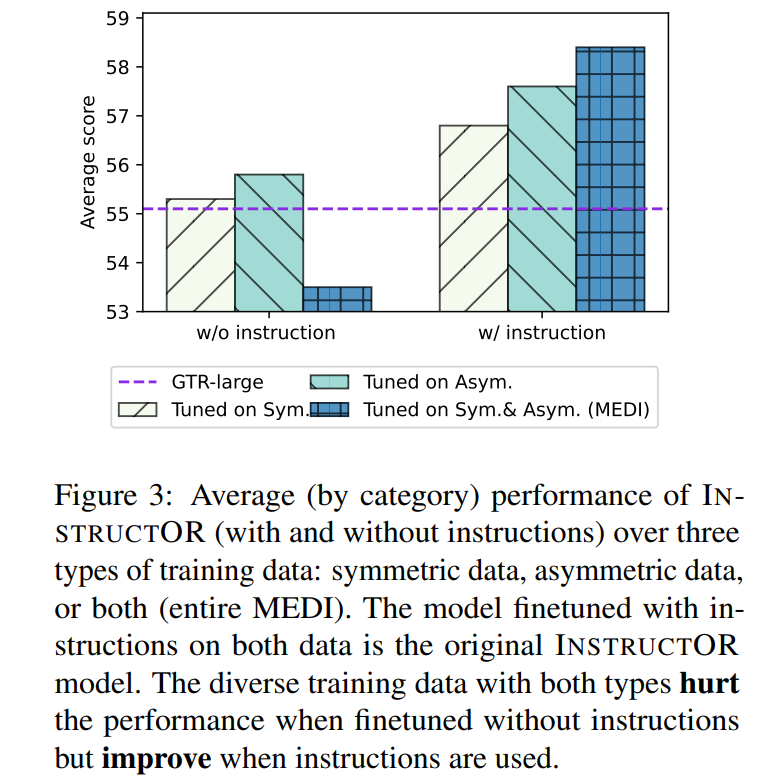
我們將MEDI劃分為對(duì)稱和非對(duì)稱組,然后對(duì)每個(gè)組進(jìn)行有指令和沒(méi)有指令的訓(xùn)練。實(shí)驗(yàn)結(jié)果如圖3所示,結(jié)果表明如果數(shù)據(jù)是對(duì)稱的或非對(duì)稱的,在沒(méi)有指令的情況下進(jìn)行微調(diào)的INSTRUCTOR的性能與原始GTR相近或更好。但是,使用指令微調(diào)使模型能夠從對(duì)稱和非對(duì)稱數(shù)據(jù)的組合中獲益。這體現(xiàn)了指令微調(diào)的重要性。
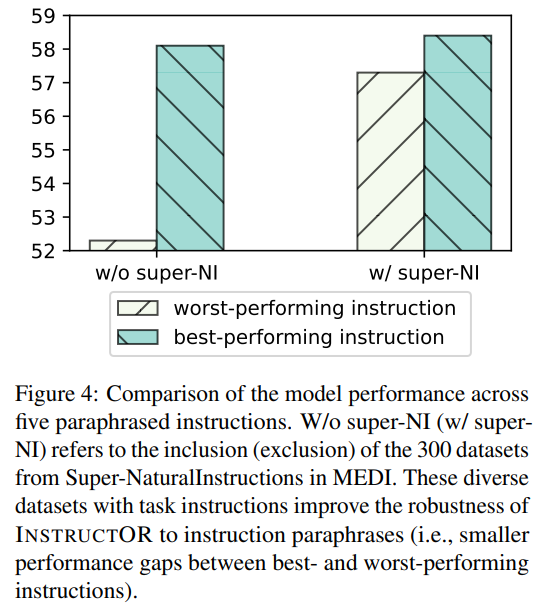
指令的魯棒性
我們?yōu)樗性u(píng)估數(shù)據(jù)集編寫了五個(gè)意譯指令,并測(cè)量了表現(xiàn)最佳和表現(xiàn)最差的指令之間的INSTRUCTOR的性能差距。圖4表明,包含300個(gè)super-NI數(shù)據(jù)集對(duì)INSTRUCTOR的魯棒性至關(guān)重要。從訓(xùn)練中刪除這些數(shù)據(jù)集(沒(méi)有super-NI)大大增加了表現(xiàn)最好和最差的指令之間的性能差距,這表明super-NI的多樣化指令有助于模型處理不同的格式和風(fēng)格。
指令的復(fù)雜程度
我們考慮了四個(gè)層次的指令復(fù)雜性:N/A(無(wú)指令)、數(shù)據(jù)集標(biāo)簽、簡(jiǎn)單指令和詳細(xì)指令。在數(shù)據(jù)集標(biāo)簽實(shí)驗(yàn)中,每個(gè)示例都附有其數(shù)據(jù)集名稱。例如,在Natural Questions數(shù)據(jù)集上,查詢格式為"Natural Questions; Input: who sings the song Love Story").。在簡(jiǎn)單的指令實(shí)驗(yàn)中,我們使用一兩個(gè)單詞來(lái)描述域(例如,對(duì)于Natural Questions數(shù)據(jù)集,輸入查詢是Wikipedia Questions;輸入是who sings the song Love Story)。圖5表明使用瑣碎的數(shù)據(jù)集標(biāo)簽,INSTRUCTOR也優(yōu)于原始的GTR模型,說(shuō)明了指令在不同訓(xùn)練中的有效性。隨著提供的信息越來(lái)越多,我們觀察到持續(xù)的改進(jìn)。
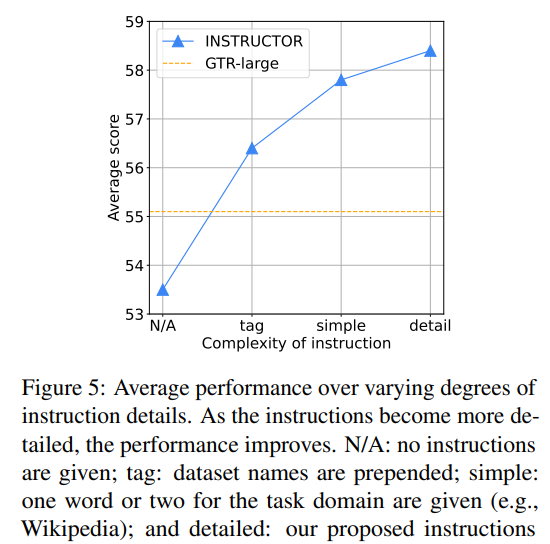
模型大小和指令微調(diào)
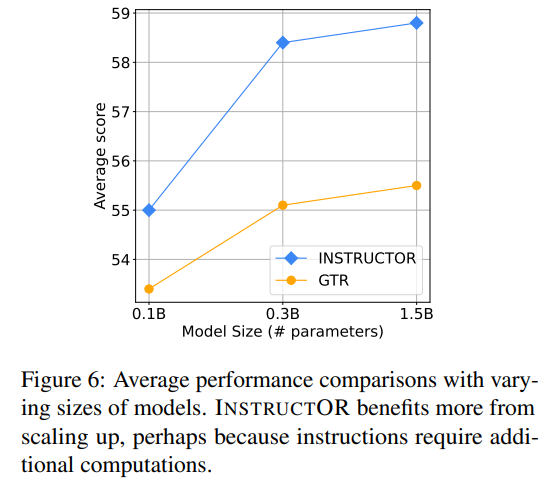
圖6展示了比較不同大小的模型的平均性能。隨著編碼器transformer模型的擴(kuò)大,GTR和INSTRUCTOR的性能都在不斷提高。盡管如此,INSTRUCTOR的改進(jìn)更加明顯,這可能是因?yàn)閹в兄噶畹那度胧芤嬗诟蟮娜萘俊_@意味著大模型在計(jì)算各種領(lǐng)域和任務(wù)類型中的文本時(shí)更加一般化。
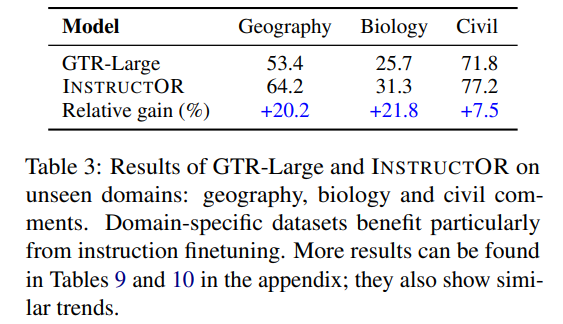
指令的域轉(zhuǎn)移
基于指令微調(diào)的一個(gè)優(yōu)點(diǎn)是,它提高了模型泛化到不可見(jiàn)領(lǐng)域和任務(wù)的能力。為了證明這種有效性,我們研究了三個(gè)unseen的INSTRUCTOR沒(méi)有受過(guò)訓(xùn)練的領(lǐng)域:地理、生物和民間評(píng)論。如表3所示,INSTRUCTOR在所有三個(gè)領(lǐng)域上極大地提高了GTR-Large的性能(高于平均水平),這表明當(dāng)將模型應(yīng)用于不可見(jiàn)或不常見(jiàn)的領(lǐng)域時(shí),指令可以提供更多幫助。
消融實(shí)驗(yàn)
我們使用T-SNE來(lái)可視化兩個(gè)有和沒(méi)有指令的分類示例。如圖7所示,情感相同的點(diǎn)對(duì)距離更近,而情感不同的點(diǎn)對(duì)距離更遠(yuǎn)。

總結(jié)
本文的貢獻(xiàn)有兩點(diǎn):
- 提出了INSTRUCTOR,一個(gè)使用自然語(yǔ)言指令創(chuàng)建廣泛適用的文本嵌入的單模型。大量實(shí)驗(yàn)表明INSTRUCTOR在文本嵌入測(cè)試中達(dá)到了最先進(jìn)的性能。
- 構(gòu)建了MEDI數(shù)據(jù)集。
-
模型
+關(guān)注
關(guān)注
1文章
3752瀏覽量
52111 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1236瀏覽量
26196 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13989
原文標(biāo)題:ACL2023 | 一個(gè)任務(wù)通用的的指令微調(diào)Embedder!
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【「基于大模型的RAG應(yīng)用開(kāi)發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
一個(gè)任務(wù)如何擁有自己的CPU

文本分類任務(wù)的Bert微調(diào)trick大全
MELSEC iQ L編程手冊(cè)(CPU模塊用指令/通用FUN/通用FB篇)

谷歌提出Flan-T5,一個(gè)模型解決所有NLP任務(wù)
GLoRA:一種廣義參數(shù)高效的微調(diào)方法
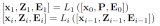
基于一個(gè)完整的 LLM 訓(xùn)練流程

FreeRTOS任務(wù)通知通用發(fā)送函數(shù)
怎樣使用QLoRA對(duì)Llama 2進(jìn)行微調(diào)呢?
多任務(wù)微調(diào)框架MFTCoder詳細(xì)技術(shù)解讀

四種微調(diào)大模型的方法介紹



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論