") 復(fù)旦開源LVOS:面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集
復(fù)旦開源LVOS:面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集

本文介紹復(fù)旦大學(xué)提出的面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集LVOS,論文被ICCV2023收錄

現(xiàn)有的視頻目標(biāo)分割(VOS)數(shù)據(jù)集主要關(guān)注于短時(shí)視頻,平均時(shí)長(zhǎng)在3-5秒左右,并且視頻中的物體大部分時(shí)間都是可見的。然而在實(shí)際應(yīng)用過(guò)程中,用戶所需要分割的視頻往往時(shí)長(zhǎng)更長(zhǎng),并且目標(biāo)物體常常會(huì)消失。現(xiàn)有的VOS數(shù)據(jù)集和真實(shí)場(chǎng)景存在一定的差異,真實(shí)場(chǎng)景中的視頻更加困難。
雖然現(xiàn)在的SOTA的視頻目標(biāo)分割方法在短時(shí)的VOS數(shù)據(jù)集上已經(jīng)取得了90%的分割準(zhǔn)確率,但是這些算法在真實(shí)場(chǎng)景中的表現(xiàn)如何卻由于缺少相關(guān)的數(shù)據(jù)集不得而知。

因此,為了探究VOS模型在真實(shí)場(chǎng)景下的表現(xiàn),彌補(bǔ)現(xiàn)有數(shù)據(jù)集的缺失,我們提出了第一個(gè)面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集Long-term Video Object Segmentation (LVOS)。
背景介紹:
視頻目標(biāo)分割(VOS)旨在根據(jù)視頻中第一幀的物體的掩膜,在視頻之后每一幀中準(zhǔn)確地跟蹤并分割目標(biāo)物體。視頻目標(biāo)分割有著十分廣泛的應(yīng)用,比如:視頻編輯、現(xiàn)實(shí)增強(qiáng)等。在實(shí)際應(yīng)用場(chǎng)景中,待分割的視頻長(zhǎng)度常常大于一分鐘,且視頻中的目標(biāo)物體會(huì)頻繁地消失和重新出現(xiàn)。對(duì)于VOS模型來(lái)說(shuō),在任意長(zhǎng)的視頻中準(zhǔn)確地重檢測(cè)和分割目標(biāo)物體是一個(gè)十分重要的能力。
但是,現(xiàn)有的VOS模型主要是針對(duì)于短時(shí)視頻設(shè)計(jì)的,并不能很好的處理長(zhǎng)時(shí)的物體消失和錯(cuò)誤累計(jì)。并且部分VOS算法依賴于不斷增長(zhǎng)的記憶模塊,當(dāng)視頻長(zhǎng)度較長(zhǎng)時(shí),存在著低效率甚至顯存不夠的問(wèn)題。
目前的視頻目標(biāo)分割數(shù)據(jù)集主要關(guān)注于短時(shí)視頻,平均視頻長(zhǎng)度為六秒左右,和真實(shí)場(chǎng)景存在著較大差異。與現(xiàn)有的數(shù)據(jù)集相比,LVOS的視頻長(zhǎng)度更長(zhǎng),對(duì)于VOS算法的要求更高,能夠更高地評(píng)估VOS模型在真實(shí)場(chǎng)景下的性能。
LVOS數(shù)據(jù)集介紹:
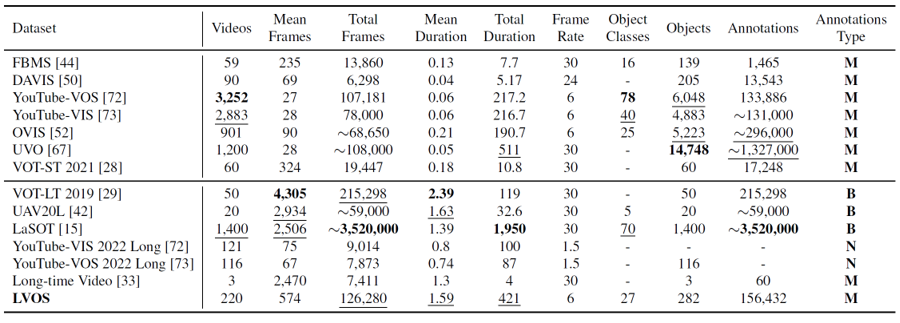
LVOS包含220個(gè)視頻,總時(shí)長(zhǎng)達(dá)421分鐘,平均每個(gè)視頻時(shí)長(zhǎng)為1.59分鐘,遠(yuǎn)遠(yuǎn)大于現(xiàn)有的VOS數(shù)據(jù)集。LVOS中的視頻更加復(fù)雜,且有著在短時(shí)視頻中不存在的挑戰(zhàn),比如長(zhǎng)時(shí)消失重現(xiàn)和跨時(shí)序混淆。這些挑戰(zhàn)更難,且對(duì)VOS模型的性能影響更大。LVOS中涉及27個(gè)類別的物體,其中包含了7種只有測(cè)試集中存在的未見類別,能夠很好地衡量VOS模型的泛化性。
LVOS分為120個(gè)訓(xùn)練視頻,50個(gè)驗(yàn)證視頻和50個(gè)測(cè)試視頻,其中測(cè)試視頻和驗(yàn)證視頻已經(jīng)全部開源,而測(cè)試視頻目前只開源了視頻圖像和第一幀中目標(biāo)物體的掩膜,需要將預(yù)測(cè)結(jié)果上傳到測(cè)試服務(wù)器中進(jìn)行在線評(píng)測(cè)。
方法介紹:
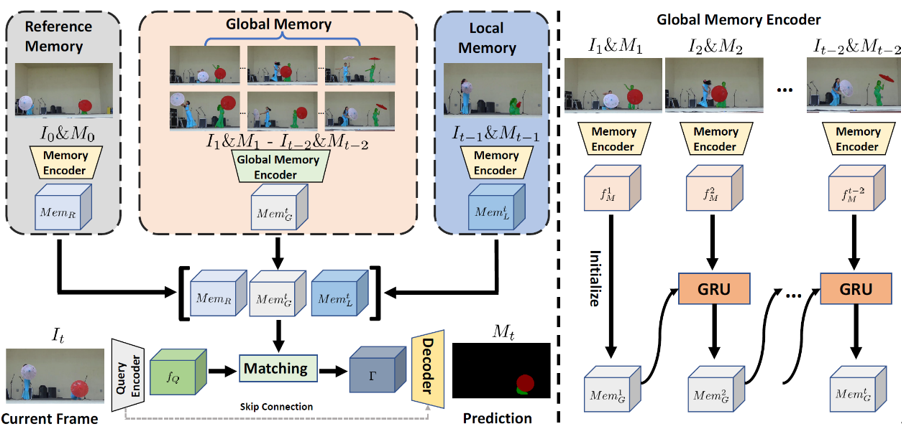
針對(duì)于長(zhǎng)時(shí)視頻,我們提出了一個(gè)新穎的VOS算法,Diverse Dynamic Memory (DDMemory)。DDMemory包含三個(gè)固定大小的記憶模塊,分別是參考記憶,全局記憶和局部記憶。通過(guò)記憶模塊,DDMemory將全局的時(shí)序信息壓縮到三個(gè)固定大小的記憶特征中,在保持高準(zhǔn)確率的同時(shí)實(shí)現(xiàn)了低GPU顯存占用和高效率。在分割當(dāng)前幀時(shí),當(dāng)前幀圖像特征會(huì)與三個(gè)記憶模塊特征進(jìn)行匹配,并根據(jù)匹配結(jié)果輸出掩膜預(yù)測(cè)。參考記憶存儲(chǔ)第一幀的圖像和掩膜信息,參考記憶負(fù)責(zé)物體消失或者遮擋之后的找回。局部記憶會(huì)隨著視頻不斷更新,存儲(chǔ)前一幀的圖像和掩膜,為當(dāng)前幀的分割提供位置和形狀的先驗(yàn)。而全局記憶利用了全局記憶編碼器,通過(guò)循環(huán)網(wǎng)絡(luò)的形式,有效地將全局歷史信息存儲(chǔ)在一個(gè)固定大小的特征中,實(shí)現(xiàn)對(duì)于時(shí)序信息的高效壓縮和對(duì)冗余噪聲干擾的排除。
實(shí)驗(yàn):
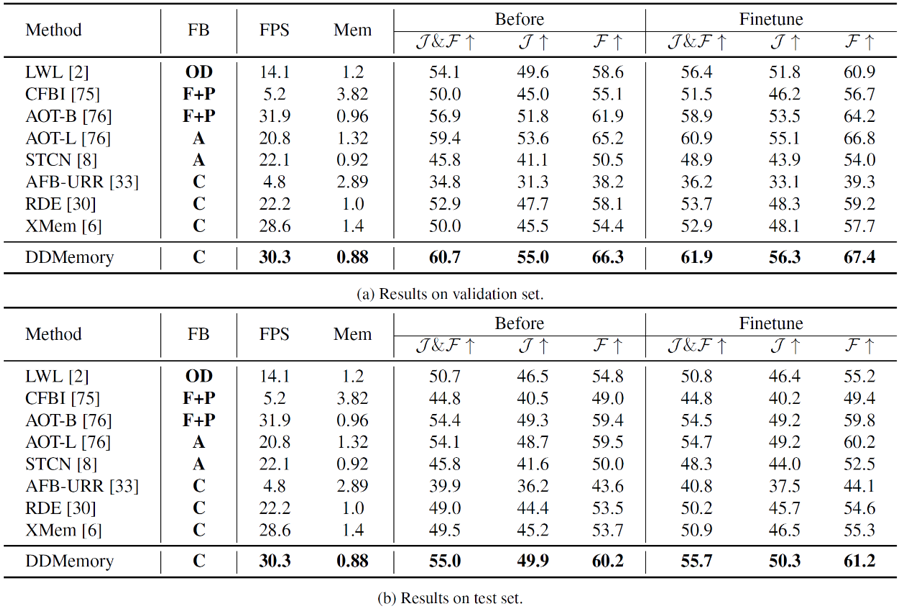
在驗(yàn)證集和測(cè)試集上,我們對(duì)現(xiàn)有的VOS模型和DDMemory進(jìn)行了分別評(píng)測(cè)。從表中可以看到,現(xiàn)有僅在短時(shí)視頻上訓(xùn)練的VOS模型在長(zhǎng)時(shí)視頻上表現(xiàn)不如人意,而在長(zhǎng)時(shí)視頻上進(jìn)行了微調(diào)之后,性能均有一定的提升。我們提出的DDMemory能夠使用最小的GPU顯存,在實(shí)現(xiàn)最好性能的同時(shí),實(shí)現(xiàn)實(shí)時(shí)的速度(30.3FPS)。實(shí)驗(yàn)結(jié)果表明,現(xiàn)有的VOS模型對(duì)于真實(shí)場(chǎng)景表現(xiàn)較差,且由于缺少面向真實(shí)場(chǎng)景的數(shù)據(jù)集,在一定程度上限制了現(xiàn)有VOS模型的發(fā)展,也證明了LVOS數(shù)據(jù)集的價(jià)值。

我們也進(jìn)行了oracle實(shí)驗(yàn),給定真實(shí)的位置和掩膜,模型的性能都會(huì)有所提升。在分割當(dāng)前幀時(shí),給定目標(biāo)物體的真實(shí)位置,性能能夠提升8.3%。而在記憶模塊更新時(shí),使用真實(shí)掩膜來(lái)代替預(yù)測(cè)掩膜進(jìn)行更新,預(yù)測(cè)性能能夠提升20.8%。但是即使給定目標(biāo)物體的真實(shí)位置和掩膜,模型預(yù)測(cè)結(jié)果仍然和真實(shí)結(jié)果存在較大差距。實(shí)驗(yàn)表明,錯(cuò)誤累計(jì)以及真實(shí)場(chǎng)景視頻中復(fù)雜的物體運(yùn)動(dòng)對(duì)VOS模型仍然是尚未解決的挑戰(zhàn),且這些挑戰(zhàn)在現(xiàn)有短時(shí)視頻數(shù)據(jù)集中并不明顯,卻在真實(shí)場(chǎng)景下對(duì)VOS算法性能有著巨大的影響。
總結(jié)
針對(duì)于真實(shí)場(chǎng)景,我們構(gòu)建了一個(gè)新的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集LVOS,LVOS中的視頻物體運(yùn)動(dòng)更加復(fù)雜,對(duì)于VOS模型的能力有著更高的要求,且比現(xiàn)有的短時(shí)數(shù)據(jù)集更加貼近實(shí)際應(yīng)用。我們對(duì)現(xiàn)有的VOS算法進(jìn)行了測(cè)試和比較,發(fā)現(xiàn)現(xiàn)有的VOS模型并不能很好地解決長(zhǎng)時(shí)視頻中的挑戰(zhàn)。基于LVOS,我們也分析了現(xiàn)有方法的缺陷以及一些可能的改進(jìn)方向。希望LVOS能夠?yàn)槊嫦蛘鎸?shí)場(chǎng)景的視頻理解研究提供一個(gè)平臺(tái)。
-
算法
+關(guān)注
關(guān)注
23文章
4784瀏覽量
98038 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1236瀏覽量
26188 -
VOS
+關(guān)注
關(guān)注
0文章
22瀏覽量
8512
原文標(biāo)題:?ICCV 2023 | 復(fù)旦開源LVOS:面向真實(shí)場(chǎng)景的長(zhǎng)時(shí)視頻目標(biāo)分割數(shù)據(jù)集
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
鴻蒙開源全場(chǎng)景應(yīng)用開發(fā)資料匯總
復(fù)旦微電子學(xué)院楊帆:介紹openDACS物理設(shè)計(jì)&建模驗(yàn)證SIG,發(fā)布開源Verilog Parser
廣泛應(yīng)用的城市語(yǔ)義分割的數(shù)據(jù)集整理
如何在信息熵約束下進(jìn)行視頻的目標(biāo)分割資料詳細(xì)概述
深度學(xué)習(xí)在視頻對(duì)象分割中的應(yīng)用及相關(guān)研究

動(dòng)態(tài)外觀模型和高階能量的雙邊視頻目標(biāo)分割方法

基于深度學(xué)習(xí)的場(chǎng)景分割算法研究
語(yǔ)義分割數(shù)據(jù)集:從理論到實(shí)踐
PyTorch教程14.9之語(yǔ)義分割和數(shù)據(jù)集

PyTorch教程-14.9. 語(yǔ)義分割和數(shù)據(jù)集

最全自動(dòng)駕駛數(shù)據(jù)集分享系列一:目標(biāo)檢測(cè)數(shù)據(jù)集
SAM-PT:點(diǎn)幾下鼠標(biāo),視頻目標(biāo)就分割出來(lái)了!

圖像分割與目標(biāo)檢測(cè)的區(qū)別是什么
傳音TEX AI團(tuán)隊(duì)斬獲ICCV 2025大型視頻目標(biāo)分割挑戰(zhàn)賽雙料亞軍



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論