") 在這個(gè)項(xiàng)目中,將在線和離線TSM網(wǎng)絡(luò)部署到FPGA,通過(guò)2D CNN執(zhí)行視頻理解任務(wù)。
在這個(gè)項(xiàng)目中,將在線和離線TSM網(wǎng)絡(luò)部署到FPGA,通過(guò)2D CNN執(zhí)行視頻理解任務(wù)。

在這個(gè)項(xiàng)目中,將在線和離線 TSM 網(wǎng)絡(luò)部署到 FPGA,通過(guò) 2D CNN 執(zhí)行視頻理解任務(wù)。
介紹
在這個(gè)項(xiàng)目中,展示了 Temporal-Shift-Module ( https://hanlab.mit.edu/projects/tsm/)在 FPGA 上解決視頻理解問(wèn)題的實(shí)用性和性能。
TSM 是一種網(wǎng)絡(luò)結(jié)構(gòu),可以通過(guò) 2D CNN 有效學(xué)習(xí)時(shí)間關(guān)系。在較高級(jí)別上,這是通過(guò)一次對(duì)單個(gè)幀(在線 TSM)或多個(gè)幀(離線 TSM)執(zhí)行推理并在這些張量流經(jīng)網(wǎng)絡(luò)時(shí)在這些張量之間轉(zhuǎn)移激活來(lái)完成的。這是通過(guò)將shift操作插入 2D 主干網(wǎng)的bottleneck層(在本例中為 mobilenetv2 和 resnet50)來(lái)完成的。然后,該shift操作會(huì)打亂時(shí)間相鄰幀之間的部分輸入通道。
詳細(xì)的解析可以看下面的文章:
?
https://zhuanlan.zhihu.com/p/64525610
?
將這樣的模型部署到 FPGA 可以帶來(lái)許多好處。首先,由于 TSM 已經(jīng)在功效方面帶來(lái)了巨大優(yōu)勢(shì),部署到 FPGA 可以進(jìn)一步推動(dòng)這一點(diǎn)。
TSM網(wǎng)絡(luò)結(jié)構(gòu)
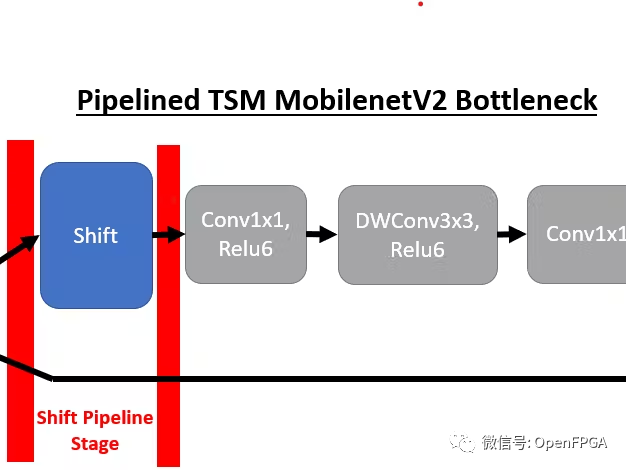
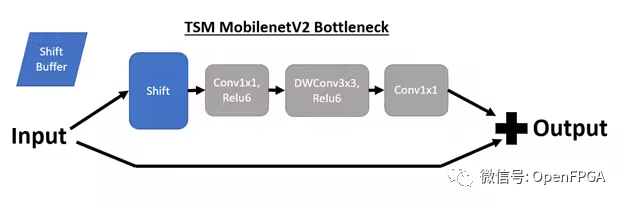
我們將首先回顧這些 TSM 網(wǎng)絡(luò)的底層結(jié)構(gòu)以及到 DPU 兼容實(shí)現(xiàn)的轉(zhuǎn)換。TSM 網(wǎng)絡(luò)的核心結(jié)構(gòu)是插入骨干模型bottleneck層中的時(shí)間shift模塊,以實(shí)現(xiàn)時(shí)間建模。例如,插入shift操作后,TSM MobilenetV2 bottleneck層具有以下結(jié)構(gòu):
Online Shift
在演示的在線 TSM 網(wǎng)絡(luò)中,如果我們處于時(shí)間步驟 T,我們也處于推理輪 T。shift模塊將輸入通道的前 1/8 移位到包含來(lái)自上一推理輪的相同通道的shift緩沖區(qū)( T – 1)。然后,第 (T – 1) 輪的內(nèi)容被移入 T 輪的當(dāng)前張量。
Offline Shift
對(duì)于離線 TSM,如 resnet50 演示(當(dāng)前禁用)中所使用的,shift緩沖區(qū)被繞過(guò)。相反,我們將N 個(gè)相鄰的時(shí)間步驟作為批次中的張量進(jìn)行處理。通道可以在批次內(nèi)直接移動(dòng),而不是將步驟 (T – 1) 中的通道存儲(chǔ)在緩沖區(qū)中。此外,這使得能夠訪問(wèn)批次內(nèi)的未來(lái)回合(即推理步驟 T 可以與步驟 T + 1 存在于同一批次中)。通過(guò)這種訪問(wèn),離線shift也會(huì)將通道從步驟 T + 1 移位到步驟 T 的張量中。
DPU模型優(yōu)化
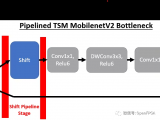
為了將TSM部署到 DPU,需要對(duì)原始 TSM 模型進(jìn)行兩項(xiàng)重大更改。第一個(gè)是將shift模塊與網(wǎng)絡(luò)分離,因?yàn)槲覀儫o(wú)法使用支持的張量流操作來(lái)實(shí)現(xiàn)shift操作。為了實(shí)現(xiàn)這一目標(biāo),我們?cè)诿看纬霈F(xiàn)shift模塊時(shí)對(duì)模型進(jìn)行管道化。
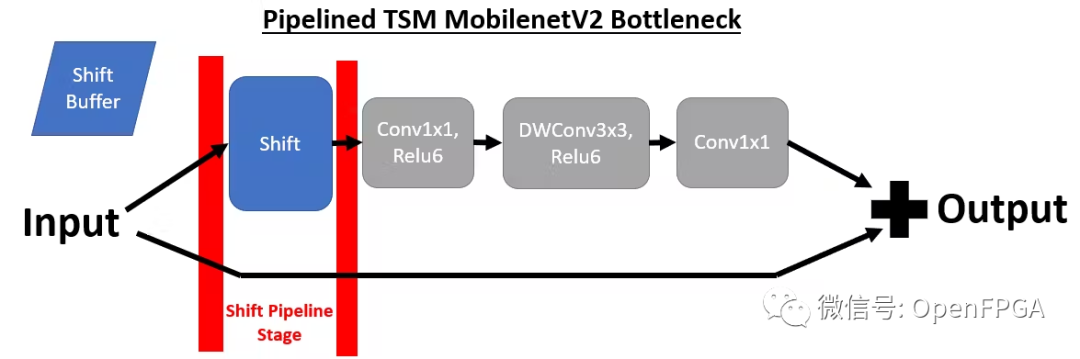
通過(guò)將shift模塊放置在其自己的管道階段,我們可以靈活地從 DPU 內(nèi)核卸載shift操作。下面我們可以看到 MobilenetV2 在線 TSM 的前 4 個(gè)管道階段(從右到左)。如果比較兩個(gè)bottleneck層實(shí)現(xiàn),并刪除shift操作,則這對(duì)應(yīng)于以下轉(zhuǎn)換,其中bottleneck層在移位模塊之前包含 1 個(gè)輸出,在shift模塊之后包含 2 個(gè)輸入。一個(gè)輸入包含來(lái)自頂部分支的移位后張量,另一個(gè)輸入包含底部分支中未移位的殘差張量。
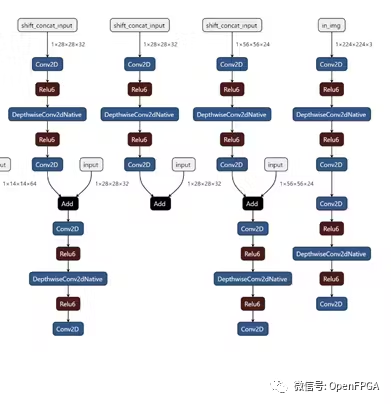
為簡(jiǎn)單起見(jiàn),這里我們使用 mobilenetV2 主干網(wǎng)來(lái)可視化 TSM,但 resnet-50 主干網(wǎng)也使用相同的方法。
為了實(shí)現(xiàn)這種流水線結(jié)構(gòu), Tensorflow 模型中有一個(gè)標(biāo)志,指示我們是否要生成不包括移位操作的拆分模型(用于 DPU 部署)或在 Tensorflow 中實(shí)現(xiàn)移位操作的普通統(tǒng)一模型。如果設(shè)置了分割標(biāo)志,則在每次移位操作之前添加新的輸出,并在移位后添加新的占位符,其中輸入移位后的輸入。
因?yàn)橐莆唬╯hift)模塊僅插入到類似于上面所示的 3 級(jí) MobilenetV2 瓶頸的結(jié)構(gòu)中,所以邏輯的實(shí)現(xiàn)得到了簡(jiǎn)化。然而,對(duì)于 resnet 模型,我們確保在快捷路徑中的歸約邏輯之后插入移位管道階段。由于移位+卷積路徑在瓶頸層完成之前獨(dú)立于快捷路徑,因此快捷路徑上的操作可以放置在3個(gè)階段中的任何一個(gè)中。
DPU量化策略
雖然如上所述對(duì)模型進(jìn)行流水線化簡(jiǎn)化了轉(zhuǎn)換實(shí)現(xiàn),但由于我們的網(wǎng)絡(luò)不再是單個(gè)內(nèi)核,因此使 DPU 部署變得復(fù)雜。相反,我們?yōu)槊總€(gè)管道階段都有一個(gè)內(nèi)核,無(wú)需進(jìn)行移位操作(MobilenetV2 為 11,resnet50 為 17)。
為了量化這樣的網(wǎng)絡(luò),我們必須為每個(gè)內(nèi)核提供未量化的輸入。為了生成這些信息,我們的模型可以在沒(méi)有管道階段的情況下生成。然后,我們直接在 Tensorflow 中對(duì)來(lái)自真實(shí)校準(zhǔn)數(shù)據(jù)集的幀進(jìn)行推理,但是我們?cè)诿總€(gè)管道邊界轉(zhuǎn)儲(chǔ)中間網(wǎng)絡(luò)狀態(tài)。轉(zhuǎn)儲(chǔ)的狀態(tài)包括需要饋送到 vai_q_tensorflow 的節(jié)點(diǎn)名稱等元數(shù)據(jù)以及相應(yīng)的張量數(shù)據(jù)。當(dāng)在校準(zhǔn)集中重復(fù)推理時(shí),所有這些信息都會(huì)被“波及”。
轉(zhuǎn)儲(chǔ)此中間推理信息后,我們獲得了輸入 vai_q_tensorflow 的每個(gè)內(nèi)核的輸入張量。該邏輯全部由我們的tensorflow模型腳本和quantize_split.sh腳本中的DUMP_QUANTIZE標(biāo)志處理(項(xiàng)目結(jié)構(gòu)在“Deployment”部分中描述)。一旦對(duì)所有內(nèi)核運(yùn)行量化,我們就可以為每個(gè)內(nèi)核生成一個(gè) ELF 文件,就可以集成到我們的主代碼中。
演示
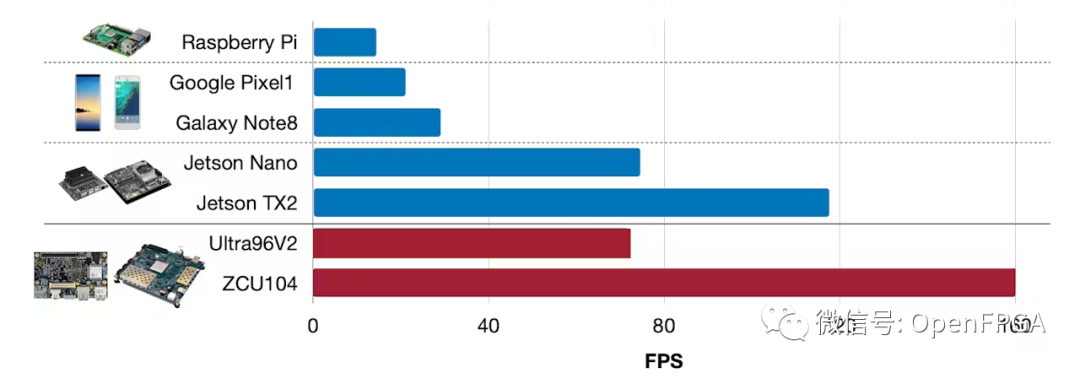
下面我們介紹 2 個(gè)平臺(tái)(ZCU104 和 Ultra96V2)和 2 個(gè)模型(MobilenetV2 Online TSM 和 Resnet50 Offline TSM)的性能細(xì)分。我們將 FPS 計(jì)算為 1/(預(yù)處理 + 推理延遲)。
MobilenetV2 在線 TSM 延遲:
ZCU104 (60.1 FPS) - B4096,300MHz,RAM 高,啟用所有功能

Ultra96V2 (38.4 FPS) - B2304,300MHz,RAM 低,啟用所有功能

現(xiàn)在,我們可以將推理延遲與之前在移動(dòng)設(shè)備和 NVIDIA Jetson 平臺(tái)上收集的 TSM 數(shù)據(jù)進(jìn)行比較。
部署
上面演示的所有代碼都位于 TSM github 存儲(chǔ)庫(kù)的 fpga 分支中:
?
https://github.com/mit-han-lab/temporal-shift-module
?
環(huán)境設(shè)置
要為上面這些設(shè)置開(kāi)發(fā)環(huán)境,按照此處所述進(jìn)行初始 Vitis-AI 環(huán)境設(shè)置:
?
https: //github.com/Xilinx/Vitis-AI
?
使用的 ZCU104 DPU 映像如下所述:
?
https: //github.com/Xilinx/Vitis-AI/tree/master/mpsoc
?
ZCU104 VCU 映像是按照此處所述的 ivas 示例應(yīng)用程序構(gòu)建的:
?
https://github. com/Xilinx/Vitis-In-Depth-Tutorial/tree/master/Runtime_and_System_Optimization/Design_Tutorials/02-ivas-ml
?
Ultra96V2 映像是根據(jù) 2020.1 Avnet BSP 構(gòu)建的,并在 petalinux 構(gòu)建時(shí)啟用 Vitis-AI
?
https://github.com/Avnet/vitis/tree/2020.1
?
參考文獻(xiàn)
?
https://www.hackster.io/joshua-noel/tsm-networks-for-efficient-video-understanding-on-fpga-f881ba
?
?
https://hanlab.mit.edu/projects/tsm/
?
?
https: //github.com/Xilinx/Vitis-AI/tree/master/mpsoc
?
?
https://github.com/Avnet/vitis/tree/2020.1
?
代碼
?
https://github.com/mit-han-lab/temporal-shift-module/tree/master/tsm_fpga
?
-
FPGA
+關(guān)注
關(guān)注
1660文章
22412瀏覽量
636317 -
模塊
+關(guān)注
關(guān)注
7文章
2837瀏覽量
53291 -
TSM
+關(guān)注
關(guān)注
0文章
7瀏覽量
6907
發(fā)布評(píng)論請(qǐng)先 登錄
怎么在xC8中傳遞和返回2D數(shù)組
怎么在xC8中傳遞和返回2D數(shù)組?
理解任務(wù)切換和任務(wù)狀態(tài)改變的關(guān)鍵是什么?
如何移植一個(gè)CNN神經(jīng)網(wǎng)絡(luò)到FPGA中?
可分離卷積神經(jīng)網(wǎng)絡(luò)在 Cortex-M 處理器上實(shí)現(xiàn)關(guān)鍵詞識(shí)別
2D到3D視頻自動(dòng)轉(zhuǎn)換系統(tǒng)
一款只通過(guò)單個(gè)普通的2D攝像頭就能實(shí)時(shí)捕捉視頻中的3D動(dòng)作的系統(tǒng)
通過(guò)2D NoC可實(shí)現(xiàn)FPGA內(nèi)部超高帶寬邏輯互連
基于差分進(jìn)化算法的CNN推斷任務(wù)卸載策略
從C 到 matlab 到 FPGA,如何實(shí)現(xiàn)CNN的項(xiàng)目
Achronix Speedster7t FPGA芯片中2D NoC的設(shè)計(jì)細(xì)節(jié)
2D執(zhí)行器在X/Y 2D空間中移動(dòng)微型機(jī)器人

西門子CPU-1200在線和診斷工具-比較離線CPU與在線CPU
使用CNN進(jìn)行2D路徑規(guī)劃
Temporal-Shift-Module在 FPGA上解決視頻理解問(wèn)題的實(shí)用性和性能



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論