 理解指向,說出坐標,Shikra開啟多模態大模型參考對話新維度
理解指向,說出坐標,Shikra開啟多模態大模型參考對話新維度

在人類的日常交流中,經常會關注場景中不同的區域或物體,人們可以通過說話并指向這些區域來進行高效的信息交換。這種交互模式被稱為參考對話(Referential Dialogue)。
如果 MLLM 擅長這項技能,它將帶來許多令人興奮的應用。例如,將其應用到 Apple Vision Pro 等混合現實 (XR) 眼鏡中,用戶可以使用視線注視指示任何內容與 AI 對話。同時 AI 也可以通過高亮等形式來指向某些區域,實現與用戶的高效交流。
本文提出的Shikra 模型,就賦予了 MLLM 這樣的參考對話能力,既可以理解位置輸入,也可以產生位置輸出。

-
論文地址:http://arxiv.org/abs/2306.15195
-
代碼地址:https://github.com/shikras/shikra
核心亮點
Shikra 能夠理解用戶輸入的 point/bounding box,并支持 point/bounding box 的輸出,可以和人類無縫地進行參考對話。
Shikra 設計簡單直接,采用非拼接式設計,不需要額外的位置編碼器、前 / 后目標檢測器或外部插件模塊,甚至不需要額外的詞匯表。

如上圖所示,Shikra 能夠精確理解用戶輸入的定位區域,并能在輸出中引用與輸入時不同的區域進行交流,像人類一樣通過對話和定位進行高效交流。

如上圖所示,Shikra 不僅具備 LLM 所有的基本常識,還能夠基于位置信息做出推理。

如上圖所示,Shikra 可以對圖片中正在發生的事情產生詳細的描述,并為參考的物體生成準確的定位。

盡管Shikra沒有在 OCR 數據集上專門訓練,但也具有基本的 OCR 能力。
更多例子

其他傳統任務

方法
模型架構采用 CLIP ViT-L/14 作為視覺主干,Vicuna-7/13B 作為基語言模型,使用一層線性映射連接 CLIP 和 Vicuna 的特征空間。
Shikra 直接使用自然語言中的數字來表示物體位置,使用 [xmin, ymin, xmax, ymax] 表示邊界框,使用 [xcenter, ycenter] 表示區域中心點,區域的 xy 坐標根據圖像大小進行歸一化。每個數字默認保留 3 位小數。這些坐標可以出現在模型的輸入和輸出序列中的任何位置。記錄坐標的方括號也自然地出現在句子中。
實驗結果
Shikra 在傳統 REC、VQA、Caption 任務上都能取得優良表現。同時在 PointQA-Twice、Point-V7W 等需要理解位置輸入的 VQA 任務上取得了 SOTA 結果。
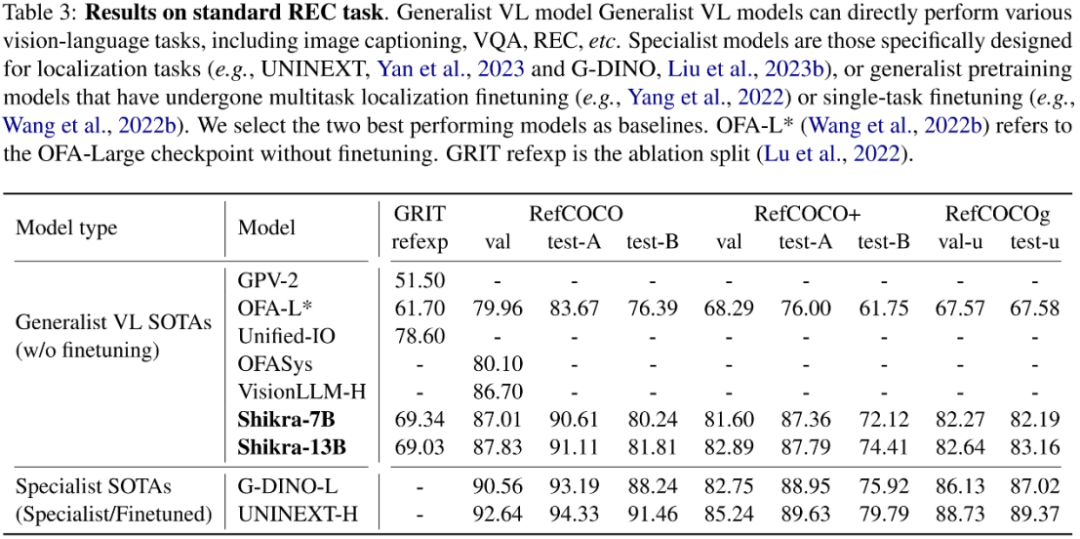
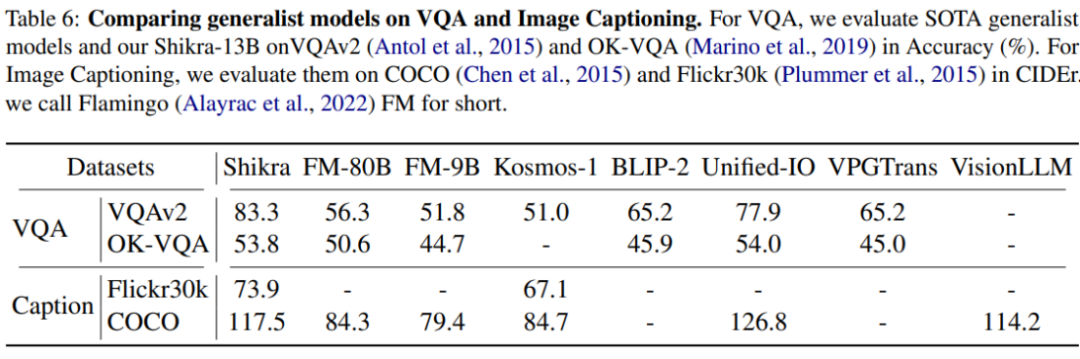
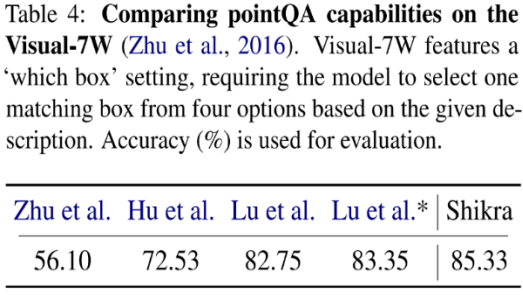
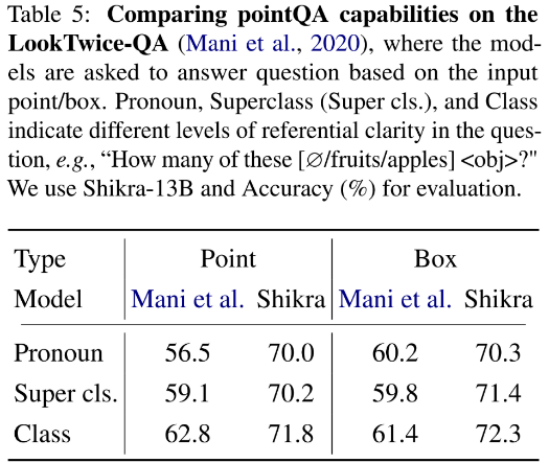
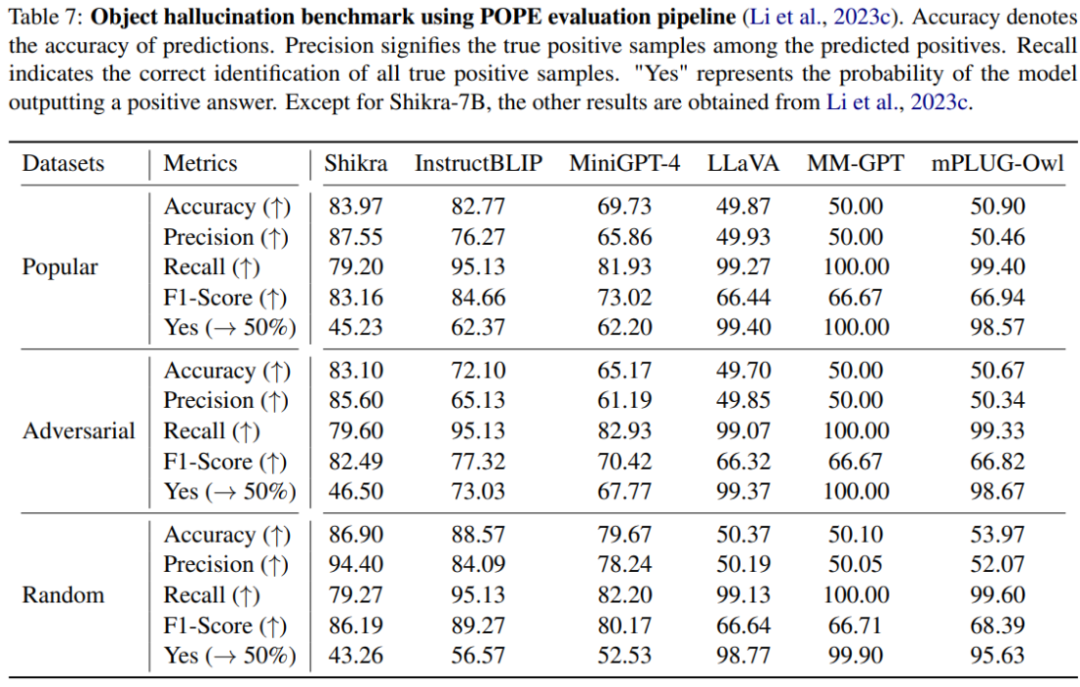
本文使用 POPE benchmark 評估了 Shikra 產生幻覺的程度。Shikra 得到了和 InstrcutBLIP 相當的結果,并遠超近期其他 MLLM。
思想鏈(CoT),旨在通過在最終答案前添加推理過程以幫助 LLM 回答復雜的 QA 問題。這一技術已被廣泛應用到自然語言處理的各種任務中。然而如何在多模態場景下應用 CoT 則尚待研究。尤其因為目前的 MLLM 還存在嚴重的幻視問題,CoT 經常會產生幻覺,影響最終答案的正確性。通過在合成數據集 CLEVR 上的實驗,研究發現,使用帶有位置信息的 CoT 時,可以有效減少模型幻覺提高模型性能。

結論
本文介紹了一種名為 Shikra 的簡單且統一的模型,以自然語言的方式理解并輸出空間坐標,為 MLLM 增加了類似于人類的參考對話能力,且無需引入額外的詞匯表、位置編碼器或外部插件。
THE END
原文標題:理解指向,說出坐標,Shikra開啟多模態大模型參考對話新維度
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯網
+關注
關注
2945文章
47820瀏覽量
415101
原文標題:理解指向,說出坐標,Shikra開啟多模態大模型參考對話新維度
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
商湯科技日日新V6.5榮獲2025年多模態大模型全國第一

多模態感知大模型驅動的密閉空間自主勘探系統的應用與未來發展
商湯科技正式發布并開源全新多模態模型架構NEO

格靈深瞳多模態大模型Glint-ME讓圖文互搜更精準

亞馬遜云科技上線Amazon Nova多模態嵌入模型

商湯日日新V6.5多模態大模型登頂全球權威榜單
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
淺析多模態標注對大模型應用落地的重要性與標注實例
基于米爾瑞芯微RK3576開發板的Qwen2-VL-3B模型NPU多模態部署評測

研華科技攜手創新奇智推出多模態大模型AI一體機

商湯日日新SenseNova融合模態大模型 國內首家獲得最高評級的大模型
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

基于MindSpeed MM玩轉Qwen2.5VL多模態理解模型




 工商網監
工商網監
評論