") 韓國政企組團研發(fā)NPU,大模型算力需求推動中國AI神經(jīng)網(wǎng)絡(luò)處理芯片發(fā)展
韓國政企組團研發(fā)NPU,大模型算力需求推動中國AI神經(jīng)網(wǎng)絡(luò)處理芯片發(fā)展

電子發(fā)燒友網(wǎng)報道(文/李寧遠)近日,韓國政府擬與AI芯片、云計算企業(yè)聯(lián)合,組建團隊研發(fā)高算力、低能耗的神經(jīng)網(wǎng)絡(luò)處理器NPU推理芯片。這一舉措的目的是與英偉達競爭并避開英偉達主導的圖形處理單元GPU市場。
自O(shè)penAI旗下的智能聊天機器人程序ChatGPT去年年末發(fā)布后,全球掀起了一波人工智能熱潮,熱度持續(xù)至今。ChatGPT超出人們預期的智能化表現(xiàn)掀起了人工智能領(lǐng)域的技術(shù)革命。這一場生成式人工智能熱潮催生了海量的數(shù)據(jù),處理海量的數(shù)據(jù)離不開背后龐大的基礎(chǔ)算力作為支撐。
CPU、GPU和DPU作為人們熟知的人工智能場景中重要的算力芯片,能夠為高帶寬、低延遲、數(shù)據(jù)密集的計算場景提供計算引擎,是未來處理超算流量和安全網(wǎng)絡(luò)存儲的核心硬件。而神經(jīng)網(wǎng)絡(luò)處理器NPU作為一種專門用于進行深度學習計算的芯片,在大算力應(yīng)用場景的應(yīng)用優(yōu)勢也正被業(yè)界廣泛看好。
NPU,為深度學習計算而生
早在2011年,Google就已經(jīng)提出了利用大規(guī)模神經(jīng)網(wǎng)絡(luò)進行圖像識別的技術(shù),由于深度學習計算需要大量的計算資源和算力支持,此時傳統(tǒng)的CPU和GPU并不能完全滿足這種需求,因此NPU應(yīng)運而生。
設(shè)計NPU的目的就是為了進行深度學習計算,其特點是具有極高的計算效率和能耗效率,能夠運行多個并行線程在短時間內(nèi)完成大規(guī)模的神經(jīng)網(wǎng)絡(luò)計算任務(wù)。NPU的計算單元通常采用矩陣計算、向量計算等方式以保證快速完成計算任務(wù)。
同時為了計算單元快速處理數(shù)據(jù),其存儲通常采用高速緩存和顯存的結(jié)合方式,方便更快地存取和讀取數(shù)據(jù)。這種設(shè)計在降低計算延遲和提高復雜計算任務(wù)穩(wěn)定性有著很明顯的幫助。
NPU和TPU、BPU這些AI芯片一樣,同屬于ASIC專用集成電路,是為特定應(yīng)用場景(如NPU的神經(jīng)網(wǎng)絡(luò)和深度學習場景)而設(shè)計的定制芯片,其開發(fā)成本高且周期長,但在性能和功耗上優(yōu)于同時期的GPU和FPGA。
傳統(tǒng)的ASIC在開發(fā)完成后是不能更改的,這一點上NPU還是略有差異,NPU一般會具有一定的可編程性,可以通過更改配置適配不同的計算任務(wù),所以其日后的應(yīng)用空間也遠不止局限于深度學習模型。
NPU這種專用芯片在特定的人工智能需求下提供了一種提升算力和能效比的新思路。雖然GPU已經(jīng)針對AI算法加強了并行計算單元,但NPU更容易從高規(guī)律性的深度神經(jīng)網(wǎng)絡(luò)中獲益,短時間內(nèi)完成大規(guī)模的神經(jīng)網(wǎng)絡(luò)計算任務(wù)。
在ChatGPT拉高算力需求的背景推動下,NPU開始進入發(fā)展快車道。
大模型需求推動NPU產(chǎn)業(yè)發(fā)展
目前,國內(nèi)人工智能芯片行業(yè)里GPU仍然是首選,根據(jù)IDC的數(shù)據(jù),GPU占有90%以上的市場份額,而NPU、FPGA和其他ASIC等非GPU芯片占有的市場份額相對較少,整體市場份額接近10%,其中NPU的占比為6.3%。
在這條新賽道上,還沒有哪一家廠商成為巨頭主導市場,韓國政府與AI芯片、云計算企業(yè)聯(lián)合發(fā)展高算力、低能耗的NPU也正是為了避開了英偉達主導的GPU市場,開辟一條新的增強AI芯片實力的道路。
今年4月已有韓媒BusinessKorea報道,三星半導體已成功量產(chǎn)采用三星14nm制程工藝第一代WarBoy NPU芯片,速度可以達到普通GPU的十倍,預計不久后投入市場,同時第二代WarBoy NPU芯片預計采用5nm工藝,明年或可推出。
國內(nèi)NPU行業(yè)也是潛力十足,不同于CPU、GPU國內(nèi)起步較慢,國內(nèi)芯片設(shè)計公司在NPU這條賽道的起步時間不晚,已經(jīng)有不少相關(guān)產(chǎn)品量產(chǎn)并推出應(yīng)用。
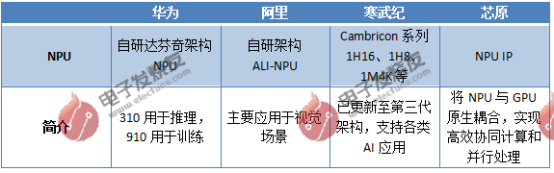
華為海思自研的Da Vinci架構(gòu)昇騰NPU已經(jīng)在移動端AI計算領(lǐng)域中嶄露頭角,張量化的立體運算單元提供了業(yè)界領(lǐng)先的量化精度,在移動端AI計算中用于圖像識別、語音識別、AR SLAM等應(yīng)用大幅提升了運算速度。
紫光展銳的NPU也在旗下多顆SoC中搭載,采用新一代高能效NPU+VDSP架構(gòu),垂直優(yōu)化計算能力,其中NPU算力達到8TOPS,相比上一代提升67%,支持圖像超分、視頻增強、語義分割、目標檢測、文本識別等AI應(yīng)用。
阿里的含光NPU也是用了自研的硬件架構(gòu),集成了達摩院先進算法,針對CNN及視覺類算法深度優(yōu)化計算、存儲密度。國科微的NPU芯片同樣自主自研,目前相關(guān)產(chǎn)品正在落地,今年會擇機發(fā)布嵌入自研NPU、帶算力的相關(guān)產(chǎn)品。
寒武紀的NPU也是國內(nèi)很早進入NPU賽道的玩家,目前NPU產(chǎn)品主要包括寒武紀1A、寒武紀1H、寒武紀1M等,其IP指令集已擴大范圍授權(quán)集成到手機、安防、可穿戴設(shè)備等各類終端芯片中,整體性能上與國外廠商比肩。
芯原股份的Vivante NPU IP也已經(jīng)應(yīng)用于百款人工智能芯片中,不僅可滿足多種芯片尺寸和功耗預算還可以結(jié)合芯原自有的其他處理器IP。同時芯原還將自有的GPU和NPU原生耦合,利用芯原獨有的FLEXA低功耗低延遲同步接口通信技術(shù),實現(xiàn)二者的高效協(xié)同計算和并行處理。
還有不少國內(nèi)廠商在NPU已有建樹,如中星微的VC0616 NPU、OPPO的自研NPU MariSilicon X、瑞芯微的自研NPU、愛芯元智的Neutron NPU等等。
 ?
?
未來NPU如何發(fā)展?
NPU作為一種專門針對深度神經(jīng)網(wǎng)絡(luò)計算的硬件器件,隨著深度學習技術(shù)的不斷發(fā)展,越來越多的算法模型加入,NPU 的多樣化肯定會越來越重要。目前NPU在圖像識別、自然語言處理以及傳感器數(shù)據(jù)處理上所展現(xiàn)出的強大計算性能,已經(jīng)從IoT、消費電子領(lǐng)域開始向汽車自動駕駛領(lǐng)域等更廣泛多樣的場景延伸應(yīng)用。
另一個發(fā)展趨勢則是獨立化,目前大多數(shù)NPU都需要與其他CPU/GPU等配合使用才能完成整個計算任務(wù),對其他芯片的依賴度較高。未來NPU集成度進一步提高,能獨立完成計算任務(wù)后其應(yīng)用空間將更為廣闊。
寫在最后
NPU的誕生就是為了應(yīng)對深度神經(jīng)計算,在ChatGPT將算力需求再推上一個新臺階后,NPU芯片顯著的能耗節(jié)約優(yōu)勢和高效的計算效率在算力需求愈發(fā)凸顯的當下已經(jīng)顯露了不少發(fā)展機遇,在市場需求的推動下相關(guān)產(chǎn)業(yè)發(fā)展也開始加速。
和其他AI芯片相比,NPU依賴定制化,國內(nèi)廠商在這一方面很有優(yōu)勢。在這個賽道上,可以預見競爭會越來越激烈,不過市場還沒有被巨頭壟斷,國內(nèi)廠商空間更大,可以爭奪的生態(tài)位更多,國內(nèi)廠商在這一細分AI芯片領(lǐng)域前景可期。
自O(shè)penAI旗下的智能聊天機器人程序ChatGPT去年年末發(fā)布后,全球掀起了一波人工智能熱潮,熱度持續(xù)至今。ChatGPT超出人們預期的智能化表現(xiàn)掀起了人工智能領(lǐng)域的技術(shù)革命。這一場生成式人工智能熱潮催生了海量的數(shù)據(jù),處理海量的數(shù)據(jù)離不開背后龐大的基礎(chǔ)算力作為支撐。
CPU、GPU和DPU作為人們熟知的人工智能場景中重要的算力芯片,能夠為高帶寬、低延遲、數(shù)據(jù)密集的計算場景提供計算引擎,是未來處理超算流量和安全網(wǎng)絡(luò)存儲的核心硬件。而神經(jīng)網(wǎng)絡(luò)處理器NPU作為一種專門用于進行深度學習計算的芯片,在大算力應(yīng)用場景的應(yīng)用優(yōu)勢也正被業(yè)界廣泛看好。
NPU,為深度學習計算而生
早在2011年,Google就已經(jīng)提出了利用大規(guī)模神經(jīng)網(wǎng)絡(luò)進行圖像識別的技術(shù),由于深度學習計算需要大量的計算資源和算力支持,此時傳統(tǒng)的CPU和GPU并不能完全滿足這種需求,因此NPU應(yīng)運而生。
設(shè)計NPU的目的就是為了進行深度學習計算,其特點是具有極高的計算效率和能耗效率,能夠運行多個并行線程在短時間內(nèi)完成大規(guī)模的神經(jīng)網(wǎng)絡(luò)計算任務(wù)。NPU的計算單元通常采用矩陣計算、向量計算等方式以保證快速完成計算任務(wù)。
同時為了計算單元快速處理數(shù)據(jù),其存儲通常采用高速緩存和顯存的結(jié)合方式,方便更快地存取和讀取數(shù)據(jù)。這種設(shè)計在降低計算延遲和提高復雜計算任務(wù)穩(wěn)定性有著很明顯的幫助。
NPU和TPU、BPU這些AI芯片一樣,同屬于ASIC專用集成電路,是為特定應(yīng)用場景(如NPU的神經(jīng)網(wǎng)絡(luò)和深度學習場景)而設(shè)計的定制芯片,其開發(fā)成本高且周期長,但在性能和功耗上優(yōu)于同時期的GPU和FPGA。
傳統(tǒng)的ASIC在開發(fā)完成后是不能更改的,這一點上NPU還是略有差異,NPU一般會具有一定的可編程性,可以通過更改配置適配不同的計算任務(wù),所以其日后的應(yīng)用空間也遠不止局限于深度學習模型。
NPU這種專用芯片在特定的人工智能需求下提供了一種提升算力和能效比的新思路。雖然GPU已經(jīng)針對AI算法加強了并行計算單元,但NPU更容易從高規(guī)律性的深度神經(jīng)網(wǎng)絡(luò)中獲益,短時間內(nèi)完成大規(guī)模的神經(jīng)網(wǎng)絡(luò)計算任務(wù)。
在ChatGPT拉高算力需求的背景推動下,NPU開始進入發(fā)展快車道。
大模型需求推動NPU產(chǎn)業(yè)發(fā)展
目前,國內(nèi)人工智能芯片行業(yè)里GPU仍然是首選,根據(jù)IDC的數(shù)據(jù),GPU占有90%以上的市場份額,而NPU、FPGA和其他ASIC等非GPU芯片占有的市場份額相對較少,整體市場份額接近10%,其中NPU的占比為6.3%。
在這條新賽道上,還沒有哪一家廠商成為巨頭主導市場,韓國政府與AI芯片、云計算企業(yè)聯(lián)合發(fā)展高算力、低能耗的NPU也正是為了避開了英偉達主導的GPU市場,開辟一條新的增強AI芯片實力的道路。
今年4月已有韓媒BusinessKorea報道,三星半導體已成功量產(chǎn)采用三星14nm制程工藝第一代WarBoy NPU芯片,速度可以達到普通GPU的十倍,預計不久后投入市場,同時第二代WarBoy NPU芯片預計采用5nm工藝,明年或可推出。
國內(nèi)NPU行業(yè)也是潛力十足,不同于CPU、GPU國內(nèi)起步較慢,國內(nèi)芯片設(shè)計公司在NPU這條賽道的起步時間不晚,已經(jīng)有不少相關(guān)產(chǎn)品量產(chǎn)并推出應(yīng)用。
華為海思自研的Da Vinci架構(gòu)昇騰NPU已經(jīng)在移動端AI計算領(lǐng)域中嶄露頭角,張量化的立體運算單元提供了業(yè)界領(lǐng)先的量化精度,在移動端AI計算中用于圖像識別、語音識別、AR SLAM等應(yīng)用大幅提升了運算速度。
紫光展銳的NPU也在旗下多顆SoC中搭載,采用新一代高能效NPU+VDSP架構(gòu),垂直優(yōu)化計算能力,其中NPU算力達到8TOPS,相比上一代提升67%,支持圖像超分、視頻增強、語義分割、目標檢測、文本識別等AI應(yīng)用。
阿里的含光NPU也是用了自研的硬件架構(gòu),集成了達摩院先進算法,針對CNN及視覺類算法深度優(yōu)化計算、存儲密度。國科微的NPU芯片同樣自主自研,目前相關(guān)產(chǎn)品正在落地,今年會擇機發(fā)布嵌入自研NPU、帶算力的相關(guān)產(chǎn)品。
寒武紀的NPU也是國內(nèi)很早進入NPU賽道的玩家,目前NPU產(chǎn)品主要包括寒武紀1A、寒武紀1H、寒武紀1M等,其IP指令集已擴大范圍授權(quán)集成到手機、安防、可穿戴設(shè)備等各類終端芯片中,整體性能上與國外廠商比肩。
芯原股份的Vivante NPU IP也已經(jīng)應(yīng)用于百款人工智能芯片中,不僅可滿足多種芯片尺寸和功耗預算還可以結(jié)合芯原自有的其他處理器IP。同時芯原還將自有的GPU和NPU原生耦合,利用芯原獨有的FLEXA低功耗低延遲同步接口通信技術(shù),實現(xiàn)二者的高效協(xié)同計算和并行處理。
還有不少國內(nèi)廠商在NPU已有建樹,如中星微的VC0616 NPU、OPPO的自研NPU MariSilicon X、瑞芯微的自研NPU、愛芯元智的Neutron NPU等等。
?未來NPU如何發(fā)展?
NPU作為一種專門針對深度神經(jīng)網(wǎng)絡(luò)計算的硬件器件,隨著深度學習技術(shù)的不斷發(fā)展,越來越多的算法模型加入,NPU 的多樣化肯定會越來越重要。目前NPU在圖像識別、自然語言處理以及傳感器數(shù)據(jù)處理上所展現(xiàn)出的強大計算性能,已經(jīng)從IoT、消費電子領(lǐng)域開始向汽車自動駕駛領(lǐng)域等更廣泛多樣的場景延伸應(yīng)用。
另一個發(fā)展趨勢則是獨立化,目前大多數(shù)NPU都需要與其他CPU/GPU等配合使用才能完成整個計算任務(wù),對其他芯片的依賴度較高。未來NPU集成度進一步提高,能獨立完成計算任務(wù)后其應(yīng)用空間將更為廣闊。
寫在最后
NPU的誕生就是為了應(yīng)對深度神經(jīng)計算,在ChatGPT將算力需求再推上一個新臺階后,NPU芯片顯著的能耗節(jié)約優(yōu)勢和高效的計算效率在算力需求愈發(fā)凸顯的當下已經(jīng)顯露了不少發(fā)展機遇,在市場需求的推動下相關(guān)產(chǎn)業(yè)發(fā)展也開始加速。
和其他AI芯片相比,NPU依賴定制化,國內(nèi)廠商在這一方面很有優(yōu)勢。在這個賽道上,可以預見競爭會越來越激烈,不過市場還沒有被巨頭壟斷,國內(nèi)廠商空間更大,可以爭奪的生態(tài)位更多,國內(nèi)廠商在這一細分AI芯片領(lǐng)域前景可期。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
AI
+關(guān)注
關(guān)注
91文章
39794瀏覽量
301456 -
NPU
+關(guān)注
關(guān)注
2文章
373瀏覽量
21102
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
應(yīng)對端側(cè)AI算力、內(nèi)存、功耗“三堵墻”困境,安謀科技Arm China “周易”X3給出技術(shù)錦囊
AI大模型正加速從云端向邊緣與端側(cè)滲透,然而,算力、內(nèi)存、功耗等卻成了制約其規(guī)模化落地的“高墻”。專為AI計算而生的

算力積木+3D堆疊!GPNPU架構(gòu)創(chuàng)新,應(yīng)對AI推理需求
落地的關(guān)鍵瓶頸。在此背景下,云天勵飛推出其第五代芯片架構(gòu)——GPNPU(General-Purpose Neural Processing Unit,通用神經(jīng)網(wǎng)絡(luò)處理單元),以一場底層架構(gòu)的革命,試圖重塑
NMSIS神經(jīng)網(wǎng)絡(luò)庫使用介紹
NMSIS NN 軟件庫是一組高效的神經(jīng)網(wǎng)絡(luò)內(nèi)核,旨在最大限度地提高 Nuclei N 處理器內(nèi)核上的神經(jīng)網(wǎng)絡(luò)的性能并最??大限度地減少其內(nèi)存占用。
該庫分為多個功能,每個功能涵蓋特定類別
發(fā)表于 10-29 06:08
國產(chǎn)AI芯片真能扛住“算力內(nèi)卷”?海思昇騰的這波操作藏了多少細節(jié)?
最近行業(yè)都在說“算力是AI的命門”,但國產(chǎn)芯片真的能接住這波需求嗎?
前陣子接觸到海思昇騰910B,實測下來有點超出預期——7nm工藝下
發(fā)表于 10-27 13:12
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片到AGI芯片
、分布式群體智能
1)物聯(lián)網(wǎng)AGI系統(tǒng)
優(yōu)勢:
組成部分:
2)分布式AI訓練
7、發(fā)展重點:基于強化學習的后訓練與推理
8、超越大模型:神經(jīng)符號計算
三、AGI
發(fā)表于 09-18 15:31
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+神經(jīng)形態(tài)計算、類腦芯片
是 AI芯片發(fā)展的重要方向。如果利用超導約瑟夫森結(jié)(JJ)來模擬與實時突觸電路相連的神經(jīng)元,神經(jīng)網(wǎng)絡(luò)運行的速度要比目前的數(shù)字或模擬技術(shù)提升幾
發(fā)表于 09-17 16:43
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI的未來:提升算力還是智力
體現(xiàn)在:
1、收益遞減
大模型的基礎(chǔ)的需要極大的算力,這首先源于昂貴的高性能AI芯片,然后是寶貴的電力、水等與環(huán)境相關(guān)的資源。
收益遞減體現(xiàn)
發(fā)表于 09-14 14:04
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+第二章 實現(xiàn)深度學習AI芯片的創(chuàng)新方法與架構(gòu)
連接定義了神經(jīng)網(wǎng)絡(luò)的拓撲結(jié)構(gòu)。
不同神經(jīng)網(wǎng)絡(luò)的DNN:
一、基于大模型的AI芯片
1、Transformer
發(fā)表于 09-12 17:30
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片的需求和挑戰(zhàn)
②Transformer引擎③NVLink Switch系統(tǒng)④機密計算⑤HBM
FPGA:
架構(gòu)的主要特點:可重構(gòu)邏輯和路由,可以快速實現(xiàn)各種不同形式的神經(jīng)網(wǎng)絡(luò)加速。
ASIC:
介紹了幾種ASIC AI芯片
發(fā)表于 09-12 16:07
MediaTek從芯片到應(yīng)用全方位支持端側(cè)AI
NPU 是專為神經(jīng)網(wǎng)絡(luò)設(shè)計的 AI 處理單元,可為各種 AI 任務(wù)提供更強大的算
芯原超低能耗NPU可為移動端大語言模型推理提供超40 TOPS算力
芯原股份今日宣布其超低能耗且高性能的神經(jīng)網(wǎng)絡(luò)處理器(NPU)IP現(xiàn)已支持在移動端進行大語言模型(LLM)推理,AI
算力網(wǎng)絡(luò)的“神經(jīng)突觸”:AI互聯(lián)技術(shù)如何重構(gòu)分布式訓練范式
? 電子發(fā)燒友網(wǎng)綜合報道 隨著AI技術(shù)迅猛發(fā)展,尤其是大型語言模型的興起,對于算力的需求呈現(xiàn)出爆

6TOPS算力NPU加持!RK3588如何重塑8K顯示的邊緣計算新邊界
與復雜運算。明遠智睿推出的RK3588芯片,以6TOPS算力的NPU為核心,為這一難題提供了突破性的解決方案。 從硬件架構(gòu)來看,RK3588的NPU
發(fā)表于 04-18 15:32
【「芯片通識課:一本書讀懂芯片技術(shù)」閱讀體驗】從deepseek看今天芯片發(fā)展
的:
神經(jīng)網(wǎng)絡(luò)處理器(NPU)是一種模仿人腦神經(jīng)網(wǎng)絡(luò)的電路系統(tǒng),是實現(xiàn)人工智能中神經(jīng)網(wǎng)絡(luò)計算的專用處理
發(fā)表于 04-02 17:25
DeepSeek推動AI算力需求:800G光模塊的關(guān)鍵作用
隨著人工智能技術(shù)的飛速發(fā)展,AI算力需求正以前所未有的速度增長。DeepSeek等大模型的訓練與
發(fā)表于 03-25 12:00



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論