 數據清洗、缺失值填充和異常值處理
數據清洗、缺失值填充和異常值處理

數據清洗、缺失值填充和異常值處理是數據分析中非常重要的步驟,而 MATLAB 提供了許多工具來實現這些步驟。
首先,數據清洗是指對數據進行必要的預處理,例如去除重復值、處理缺失值和異常值等。在 MATLAB 中,可以使用基本的函數和工具箱來實現這些任務。
以下是一個示例,假設我們有一個包含重復值、缺失值和異常值的數據集:
data=[1,2,NaN,3,4,5,5,6,7,8,9,99];
要清除重復值,可以使用 unique 函數:
unique_data=unique(data);
要填補缺失值,可以使用 fillmissing 函數。例如,我們可以將缺失值填充為均值。
mean_data=fillmissing(data,'mean');
要處理異常值,可以使用 isoutlier 函數。例如,我們可以將所有大于中位數一倍標準差的值視為異常值。
median_data=median(data)
std_data=std(data)
outlier_data=data(~isoutlier(data,'median'))
這將返回一個新的數據集,其中不包括異常值。
綜上所述,數據清洗、缺失值填充和異常值處理對數據分析非常重要,并且 MATLAB 提供了許多工具來實現這些步驟。可以根據具體情況選擇合適的函數和方法來處理數據。
以下是一個完整的示例,展示如何使用 MATLAB 來清理數據:
%創建一個包含重復值、缺失值和異常值的數據集
data=[1,2,NaN,3,4,5,5,6,7,8,9,99];
%清除重復值
unique_data=unique(data)
%填補缺失值
mean_data=fillmissing(data,'mean')
%處理異常值
median_data=median(data);
std_data=std(data);
outlier_data=data(~isoutlier(data,'median'))
%顯示結果
disp('Originaldata:')
disp(data)
disp('Uniquedata:')
disp(unique_data)
disp('Mean-filleddata:')
disp(mean_data)
disp('Outlier-handleddata:')
disp(outlier_data)
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
matlab
+關注
關注
189文章
3025瀏覽量
238696 -
數據
+關注
關注
8文章
7335瀏覽量
94757 -
數據集
+關注
關注
4文章
1236瀏覽量
26190
原文標題:數據清洗、缺失值填充和異常值處理
文章出處:【微信號:嵌入式職場,微信公眾號:嵌入式職場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
風電機組異常數據識別與清洗
風電機組異常數據識別與清洗-baseline比賽類型:數據挖掘比賽數據:表格題(csv)學習方式:無監督主辦方:國家電力投資集團有限公司科技與創新部比賽鏈接比賽任務:依據提供的8臺風力
發表于 07-12 07:15
基于關聯規則分析和神經網絡的數據清洗策略
的時間序列。然后利用基于密度的聚類算法檢測出序列中的缺失值以及異常點,提出了考慮序列關聯性的清洗流程和規則,有效區分可清洗的傳感器
發表于 12-14 10:44
?0次下載
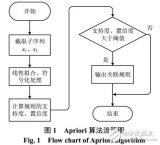
無線傳感網絡缺失值估計方法
針對無線傳感器網絡(WSN)中感知數據易缺失問題,提出了一種基于感知數據屬性相關性的缺失值估計方法。該方法采用多元線性回歸模型,對屬性相關的
發表于 12-27 16:56
?0次下載
在Tableau中盒須圖幫你6步篩除異常值
如果您熟悉盒須圖,那么您也知道這是一個非常好的圖表來檢查數據的分布并突出顯示異常值。但有時僅僅顯示異常值是不夠的,我們可能也想篩選掉異常值,因為這些
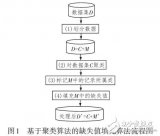
基于聚類的大數據應用數據缺失值充填方法
在大數據應用中,多數建模方法是在完備數據集基礎上進行的,但在數據采集過程或存儲過程中容易出現數據缺失的現象,導致無法建模。為此,提岀一種基于
發表于 06-11 10:44
?6次下載

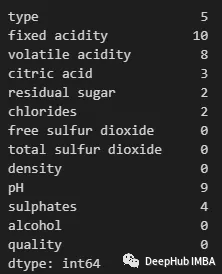
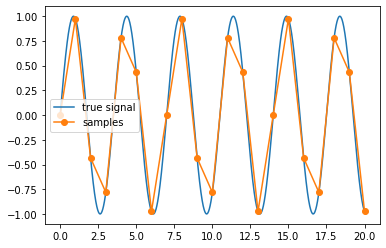

eda分析中的數據清洗步驟
在數據分析的早期階段,探索性數據分析(EDA)是一種重要的方法,它幫助我們理解數據集的特征和結構。然而,原始數據往往包含錯誤、缺失



 工商網監
工商網監
評論