 多個CPU各自的cache同步問題
多個CPU各自的cache同步問題

CACHE的一致性
Cache的一致性有這么幾個層面
2.多個CPU各自的cache同步問題
3.CPU與設備(其實也可能是個異構處理器,不過在Linux運行的CPU眼里,都是設備,都是DMA)的cache同步問題
先看一下ICACHE和DCACHE同步問題。由于程序的運行而言,指令流的都流過icache,而指令中涉及到的數據流經過dcache。所以對于自修改的代碼(Self-Modifying Code)而言,比如我們修改了內存p這個位置的代碼(典型多見于JIT compiler),這個時候我們是通過store的方式去寫的p,所以新的指令會進入dcache。但是我們接下來去執行p位置的指令的時候,icache里面可能命中的是修改之前的指令。
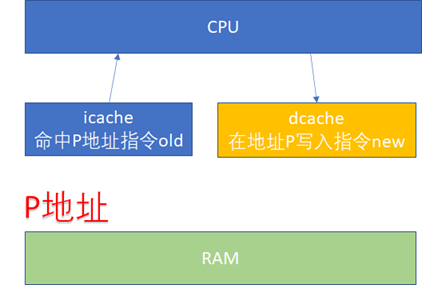
所以這個時候軟件需要把dcache的東西clean出去,然后讓icache invalidate,這個開銷顯然還是比較大的。
但是,比如ARM64的N1處理器,它支持硬件的icache同步,詳見文檔:The Arm Neoverse N1 Platform: Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC

特別注意畫紅色的幾行。軟件維護的成本實際很高,還涉及到icache的invalidation向所有核廣播的動作。
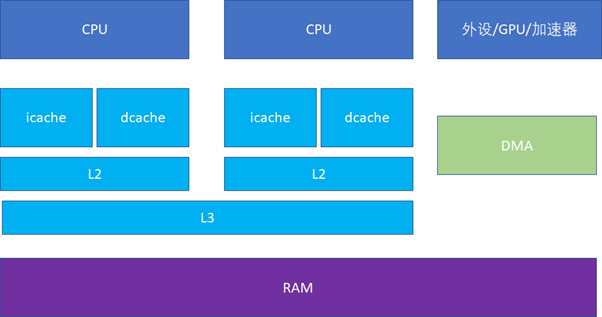
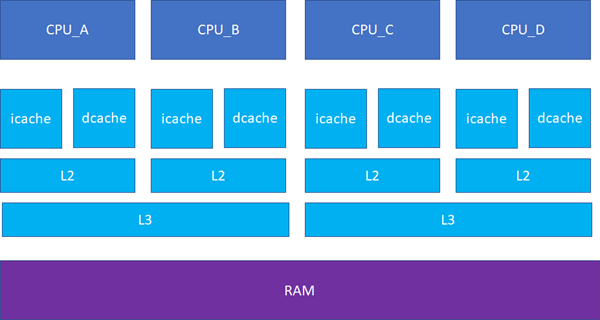
接下來的一個問題就是多個核之間的cache同步。下面是一個簡化版的處理器,CPU_A和B共享了一個L3,CPU_C和CPU_D共享了一個L3。實際的硬件架構由于涉及到NUMA,會比這個更加復雜,但是這個圖反映層級關系是足夠了。
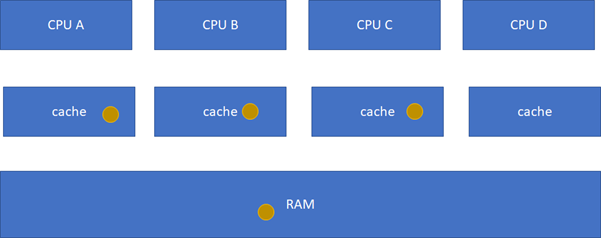
比如CPU_A讀了一個地址p的變量?CPU_B、C、D又讀,難道B,C,D又必須從RAM里面經過L3,L2,L1再讀一遍嗎?這個顯然是沒有必要的,在硬件上,cache的snooping控制單元,可以協助直接把CPU_A的p地址cache拷貝到CPU_B、C和D的cache。
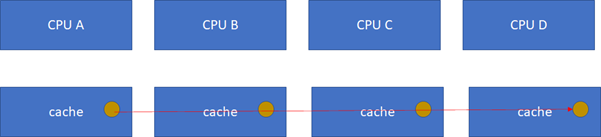
這樣A-B-C-D都得到了相同的p地址的棕色小球。
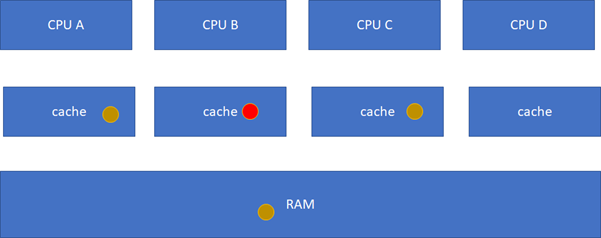
假設CPU B這個時候,把棕色小球寫成紅色,而其他CPU里面還是棕色,這樣就會不一致了:
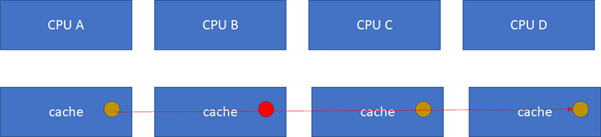
這個時候怎么辦?這里面顯然需要一個協議,典型的多核cache同步協議有MESI和MOESI。MOESI相對MESI有些細微的差異,不影響對全局的理解。下面我們重點看MESI協議。
MESI協議定義了4種狀態:
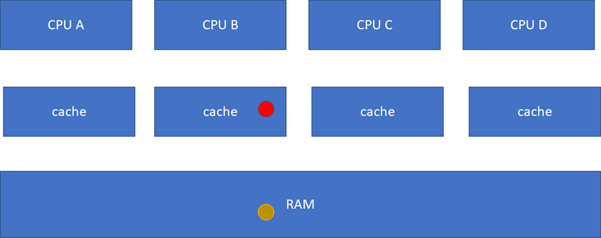
M(Modified):當前cache的內容有效,數據已被修改而且與內存中的數據不一致,數據只在當前cache里存在;類似RAM里面是棕色球,B里面是紅色球(CACHE與RAM不一致),A、C、D都沒有球。
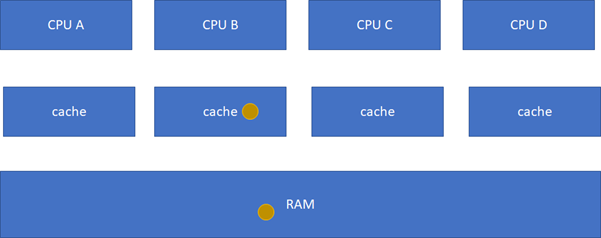
E(Exclusive):當前cache的內容有效,數據與內存中的數據一致,數據只在當前cache里存在;類似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都沒有球。
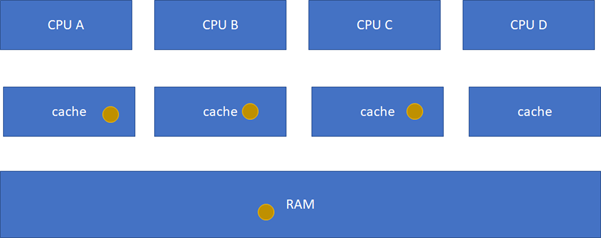
S(Shared):當前cache的內容有效,數據與內存中的數據一致,數據在多個cache里存在。類似如下圖,在CPU A-B-C里面cache的棕色球都與RAM一致。
I(Invalid):當前cache無效。前面三幅圖里面cache沒有球的那些都是屬于這個情況。
然后它有個狀態機
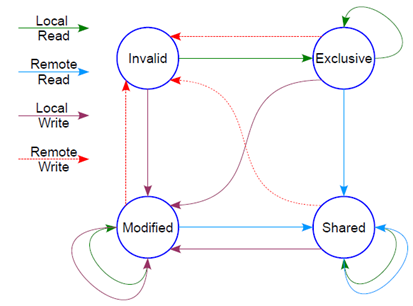
這個狀態機比較難記,死記硬背是記不住的,也沒必要記,它講的cache原先的狀態,經過一個硬件在本cache或者其他cache的讀寫操作后,各個cache的狀態會如何變遷。所以,硬件上不僅僅是監控本CPU的cache讀寫行為,還會監控其他CPU的。只需要記住一點:這個狀態機是為了保證多核之間cache的一致性,比如一個干凈的數據,可以在多個CPU的cache share,這個沒有一致性問題;但是,假設其中一個CPU寫過了,比如A-B-C本來是這樣:
然后B被寫過了:
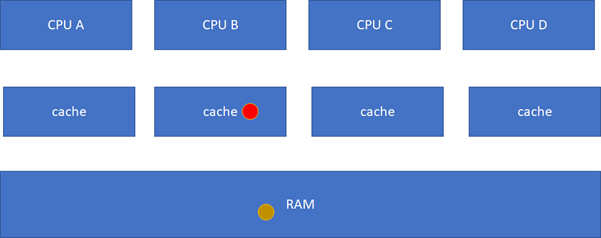
這樣A、C的cache實際是過時的數據,這是不允許的。這個時候,硬件會自動把A、C的cache invalidate掉,不需要軟件的干預,A、C其實變地相當于不命中這個球了:
這個時候,你可能會繼續問,如果C要讀這個球呢?它目前的狀態在B里面是modified的,而且與RAM不一致,這個時候,硬件會把紅球clean,然后B、C、RAM變地一致,B、C的狀態都變化為S(Shared):
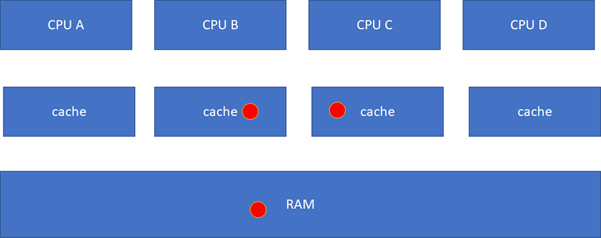
這一系列的動作雖然由硬件完成,但是對軟件而言不是免費的,因為它耗費了時間。如果編程的時候不注意,引起了硬件的大量cache同步行為,則程序的效率可能會急劇下降。
為了讓大家直觀感受到這個cache同步的開銷,下面我們寫一個程序,這個程序有2個線程,一個寫變量,一個讀變量:

這個程序里,x和y都是cacheline對齊的,這個程序的thread1的寫,會不停地與thread2的讀,進行cache同步。
它的執行時間為:
$ time ./a.out real 0m3.614s user 0m7.021s sys0m0.004s
它在2個CPU上的userspace共運行了7.021秒,累計這個程序從開始到結束的對應真實世界的時間是3.614秒(就是從命令開始到命令結束的時間)。
如果我們把程序改一句話,把thread2里面的c = x改為c = y,這樣2個線程在2個CPU運行的時候,讀寫的是不同的cacheline,就沒有這個硬件的cache同步開銷了:
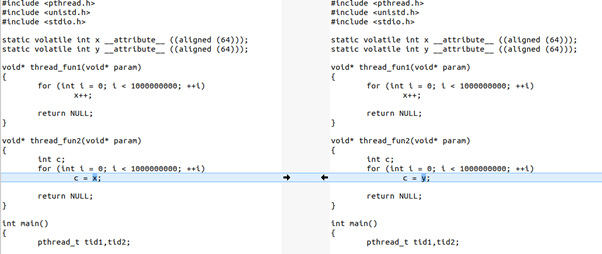
它的運行時間:
$ time ./b.out real 0m1.820s user 0m3.606s sys0m0.008s
現在只需要1.8秒,幾乎減小了一半。
感覺前面那個a.out,雙核的幫助甚至都不大。如果我們改為單核跑呢?
$ time taskset -c 0 ./a.out real 0m3.299s user 0m3.297s sys0m0.000s
它單核跑,居然只需要3.299秒跑完,而雙核跑,需要3.614s跑完。單核跑完這個程序,甚至比雙核還快,有沒有驚掉下巴?!!!因為單核里面沒有cache同步的開銷。
下一個cache同步的重大問題,就是設備與CPU之間。如果設備感知不到CPU的cache的話(下圖中的紅色數據流向不經過cache),這樣,做DMA前后,CPU就需要進行相關的cacheclean和invalidate的動作,軟件的開銷會比較大。
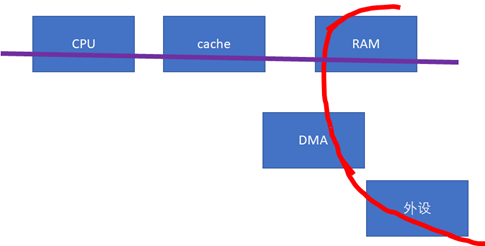
這些軟件的動作,若我們在Linux編程的時候,使用的是streaming DMA APIs的話,都會被類似這樣的API自動搞定:
dma_map_single() dma_unmap_single() dma_sync_single_for_cpu() dma_sync_single_for_device() dma_sync_sg_for_cpu() dma_sync_sg_for_device()
如果是使用的dma_alloc_coherent() API呢,則設備和CPU之間的buffer是cache一致的,不需要每次DMA進行同步。對于不支持硬件cache一致性的設備而言,很可能dma_alloc_coherent()會把CPU對那段DMA buffer的訪問設置為uncachable的。
這些API把底層的硬件差異封裝掉了,如果硬件不支持CPU和設備的cache同步的話,延時還是比較大的。那么,對于底層硬件而言,更好的實現方式,應該仍然是硬件幫我們來搞定。比如我們需要修改總線協議,延伸紅線的觸角:
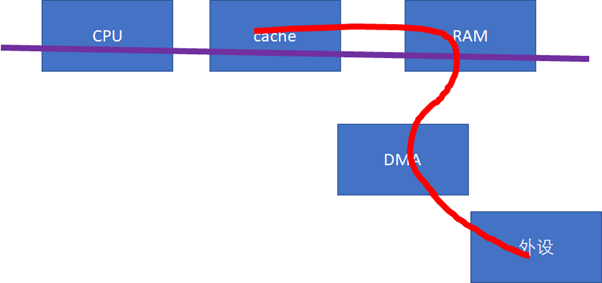
當設備訪問RAM的時候,可以去snoop CPU的cache:
如果做內存到外設的DMA,則直接從CPU的cache取modified的數據;
如果做外設到內存的DMA,則直接把CPU的cache invalidate掉。
這樣,就實現硬件意義上的cache同步。當然,硬件的cache同步,還有一些其他方法,原理上是類似的。注意,這種同步仍然不是免費的,它仍然會消耗bus cycles的。實際上,cache的同步開銷還與距離相關,可以說距離越遠,同步開銷越大,比如下圖中A、B的同步開銷比A、C小。
對于一個NUMA服務器而言,跨NUMA的cache同步開銷顯然是要比NUMA內的同步開銷大。
意識到CACHE的編程
通過上一節的代碼,讀者應該意識到了cache的問題不處理好,程序的運行性能會急劇下降。所以意識到cache的編程,對程序員是至關重要的。
從CPU流水線的角度講,任何的內存訪問延遲都可以簡化為如下公式:
Average Access Latency = Hit Time + Miss Rate × Miss Penalty
cache miss會導致CPU的stall狀態,從而影響性能。現代CPU的微架構分了frontend和backend。frontend負責fetch指令給backend執行,backend執行依賴運算能力和Memory子系統(包括cache)延遲。
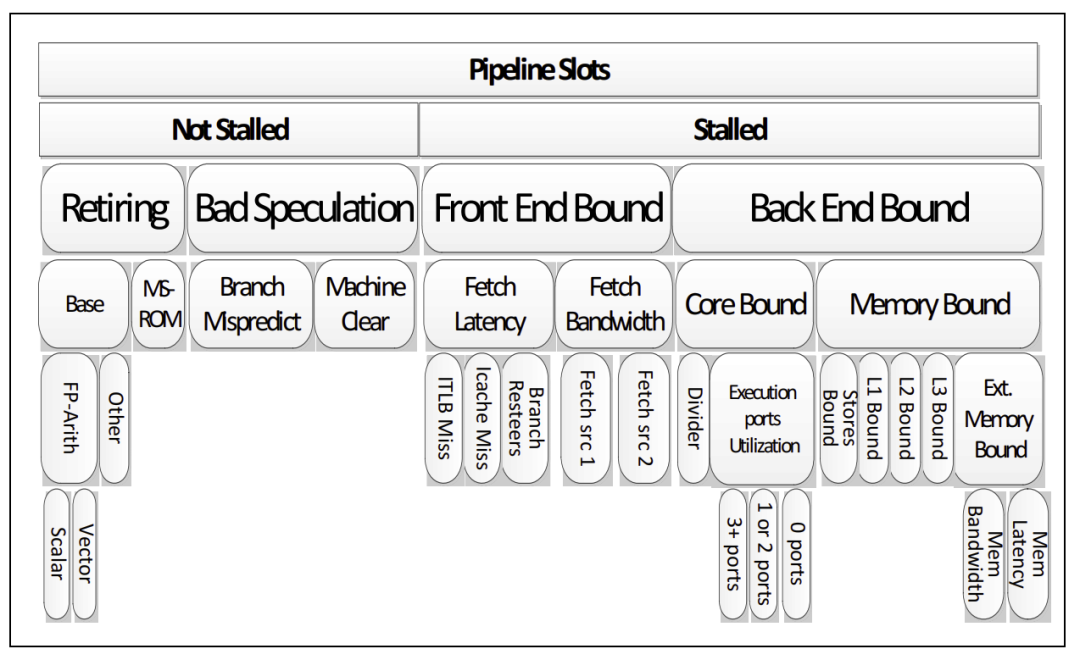
backend執行中訪問數據導致的cache miss會導致backend stall,從而降低IPC(instructions per cycle)。減小cache的miss,實際上是一個軟硬件協同設計的任務。比如硬件方面,它支持預取prefetch,通過分析cache miss的pattern,硬件可以提前預取數據,在流水線需要某個數據前,提前先取到cache,從而CPU流水線跑到需要它的時候,不再miss。當然,硬件不一定有那么聰明,也許它可以學會一些簡單的pattern。但是,對于復雜的無規律的數據,則可能需要軟件通過預取指令,來暗示CPU進行預取。
cache預取
比如在ARM處理器上就有一條指令叫pld,prefetch可以用pld指令:
static inline void prefetch(const void *ptr)
{
__asm__ __volatile__(
"pld %a0"
:: "p" (ptr));
}
眼見為實,我們隨便從Linux內核里面找一個commit:
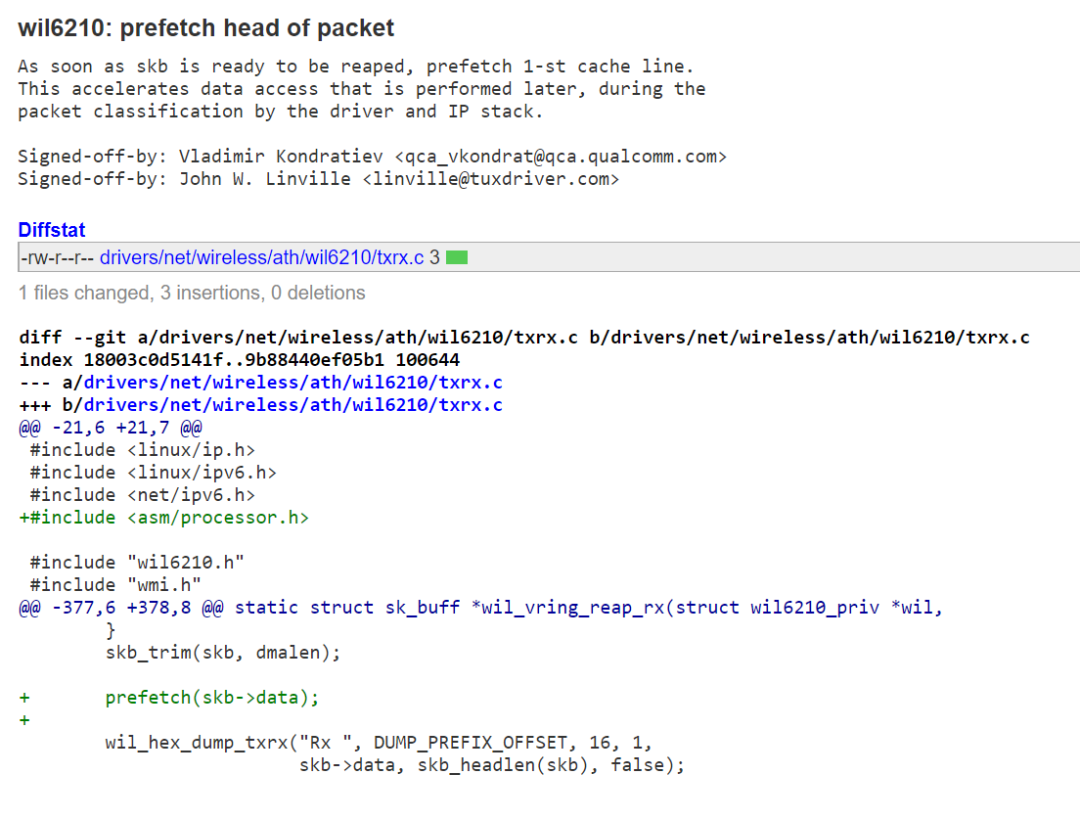
因為我們從WiFi收到了一個skb,我們很快就要訪問這個skb里面的數據來進行packet的分類以及交給IP stack處理了,不如我們先prefetch一下,這樣后面等需要訪問這個skb->data的時候,流水線可以直接命中cache,從而不打斷。
預取的原理有點類似今天星期五,咱們在上海office,下周一需要北京分公司的人來上海office開會。于是,我們通知北京office的人周末坐飛機過來,這樣周一開會的時候就不必等他們了。不預取的情況下,會議開始后,再等北京的人飛過來,會導致stall狀態。
任何東西最終還是要落實到代碼,talk is cheap,show me the code。下面這個是經典的二分查找法代碼,這個代碼是網上抄的。
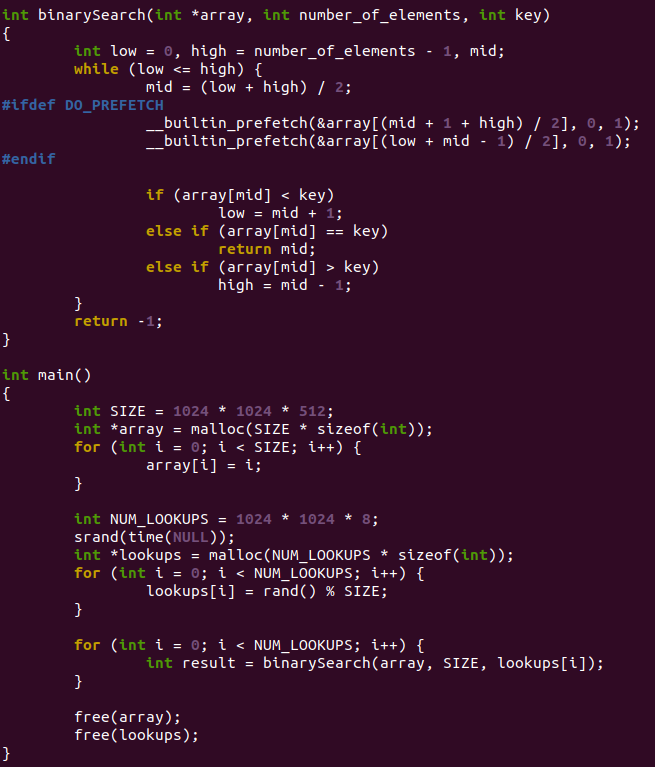
特別留意ifdef DO_PREFETCH包著的代碼,它提前預取了下次的中間值。我們來對比下,不預取和預取情況下,這個同樣的代碼執行時間的差異。先把cpufreq的影響盡可能關閉掉,設置為performance:
barry@barry-HP-ProBook-450-G7:~$ sudo cpupower frequency-set --governor performance Setting cpu: 0 Setting cpu: 1 Setting cpu: 2 Setting cpu: 3 Setting cpu: 4 Setting cpu: 5 Setting cpu: 6 Setting cpu: 7
然后我們來對比差異:
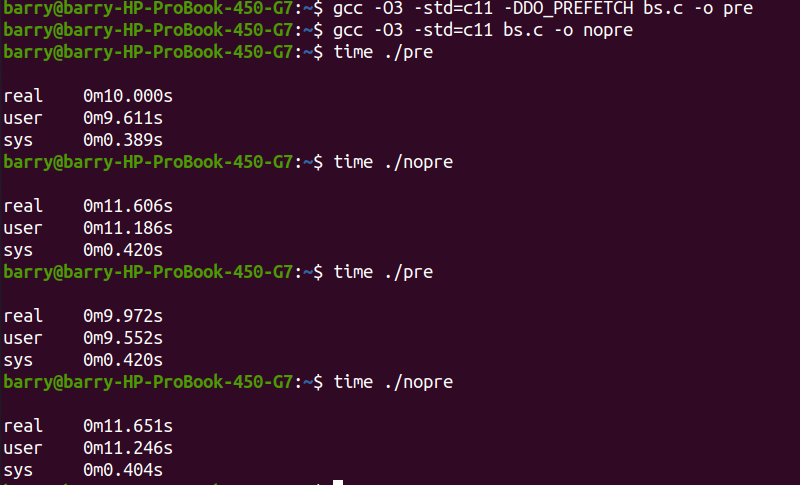
開啟prefetch執行時間大約10s, 不prefetch的情況下,11.6s執行完成,性能提升大約14%,所以周末坐飛機太重要了!
現在我們來通過基于perf的pmu-tools(下載地址:https://github.com/andikleen/pmu-tools),對上面的程序進行topdown分析,分析的時候,為了盡可能減小其他因子的影響,我們把程序通過taskset運行到CPU0。
先看不prefetch的情況,很明顯,程序是backend_bound的,其中DRAM_Bound占比大,達到75.8%。
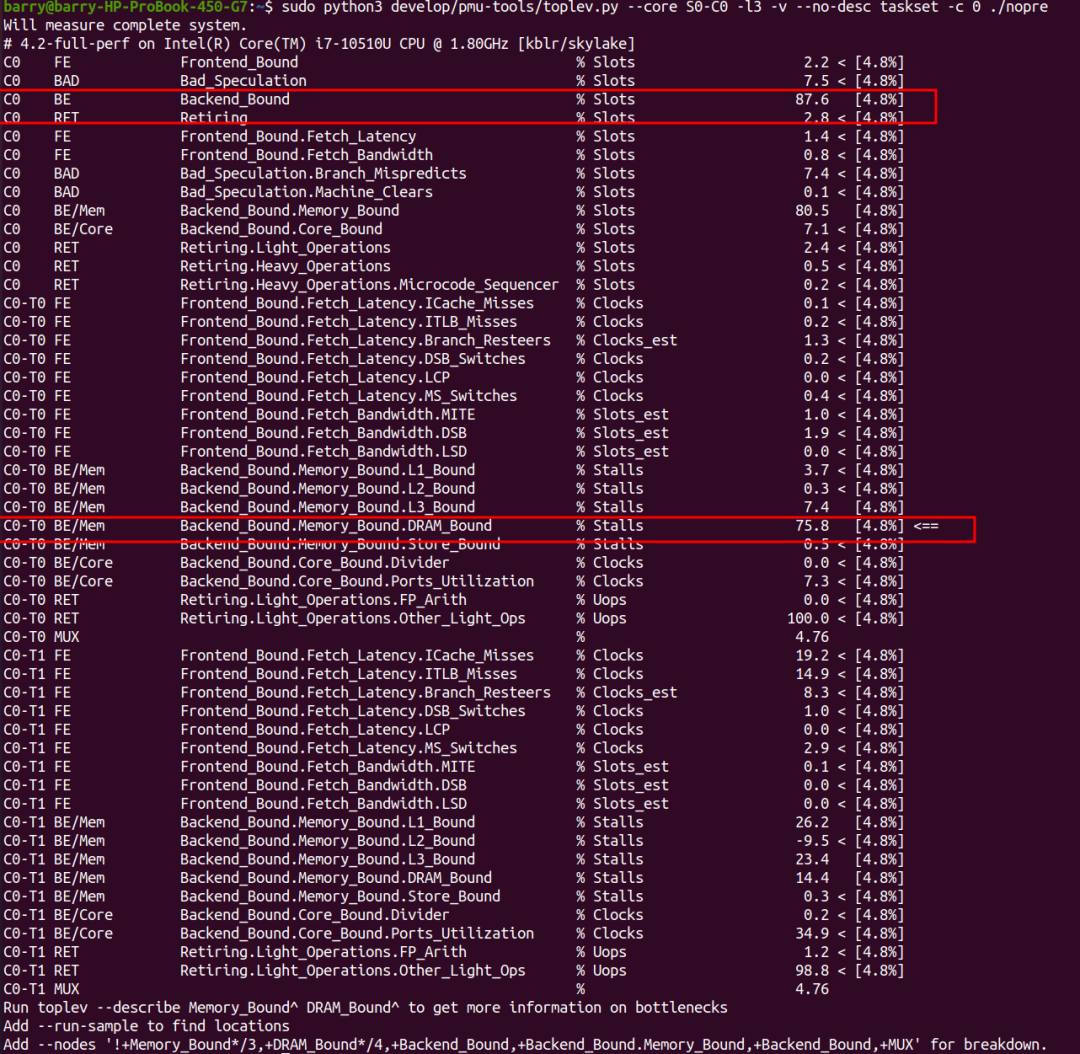
開啟prefetch的情況呢?程序依然是backend_bound的,其中,backend bound的主體依然是DRAM_Bound,但是比例縮小到了60.7%。
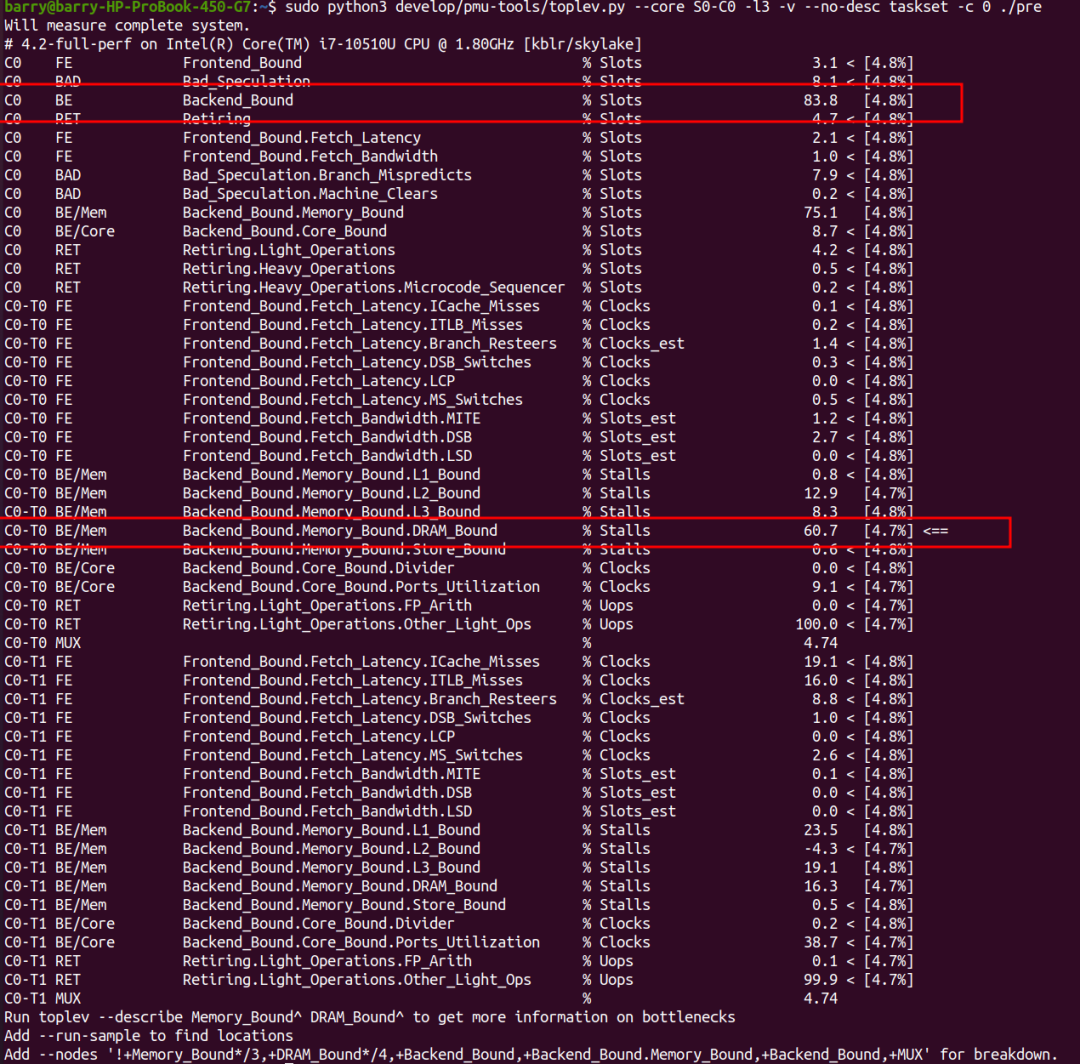
DRAM_Bound主要對應cycle_activity.stalls_l3_miss事件,我們通過perf stat來分別進行搜集:
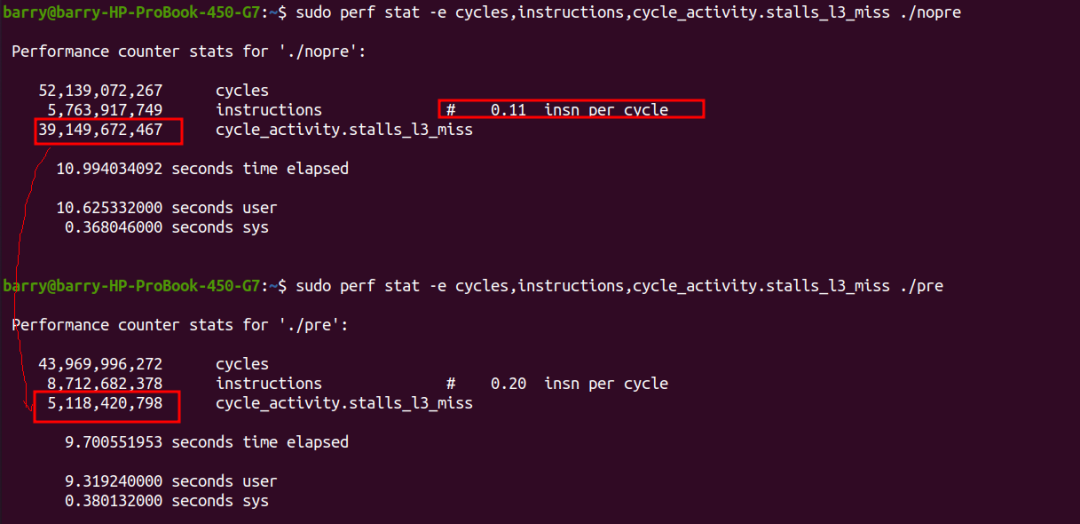
我們看到,執行prefetch情況下,指令的條數明顯多了,但是它的insn per cycle變大了,所以總的時間cycles反而減小。其中最主要的原因是cycle_activity.stalls_l3_miss變小了很多次。
這個時候,我們可以進一步通過錄制mem_load_retired.l3_miss來分析究竟代碼哪里出了問題,先看noprefetch情況:

焦點在main函數:

繼續annotate一下:
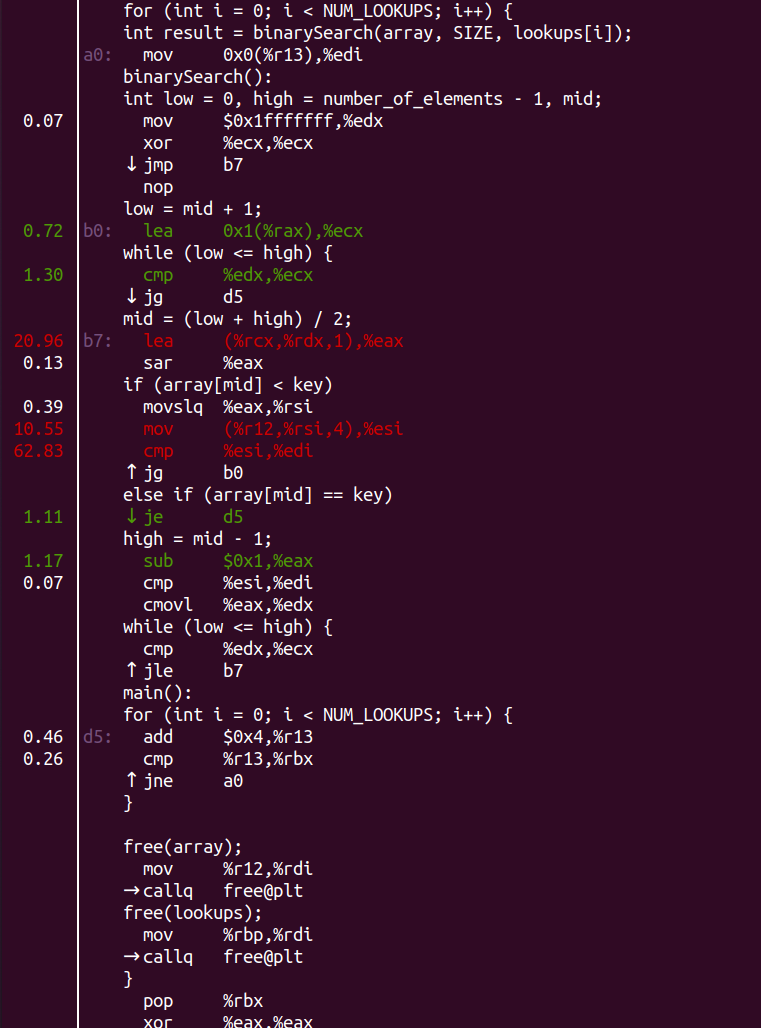
明顯問題出在array[mid] < key這句話這里。做prefetch的情況下呢?

main的占比明顯變小了(99.93% -> 80.00%):

繼續annotate一下:
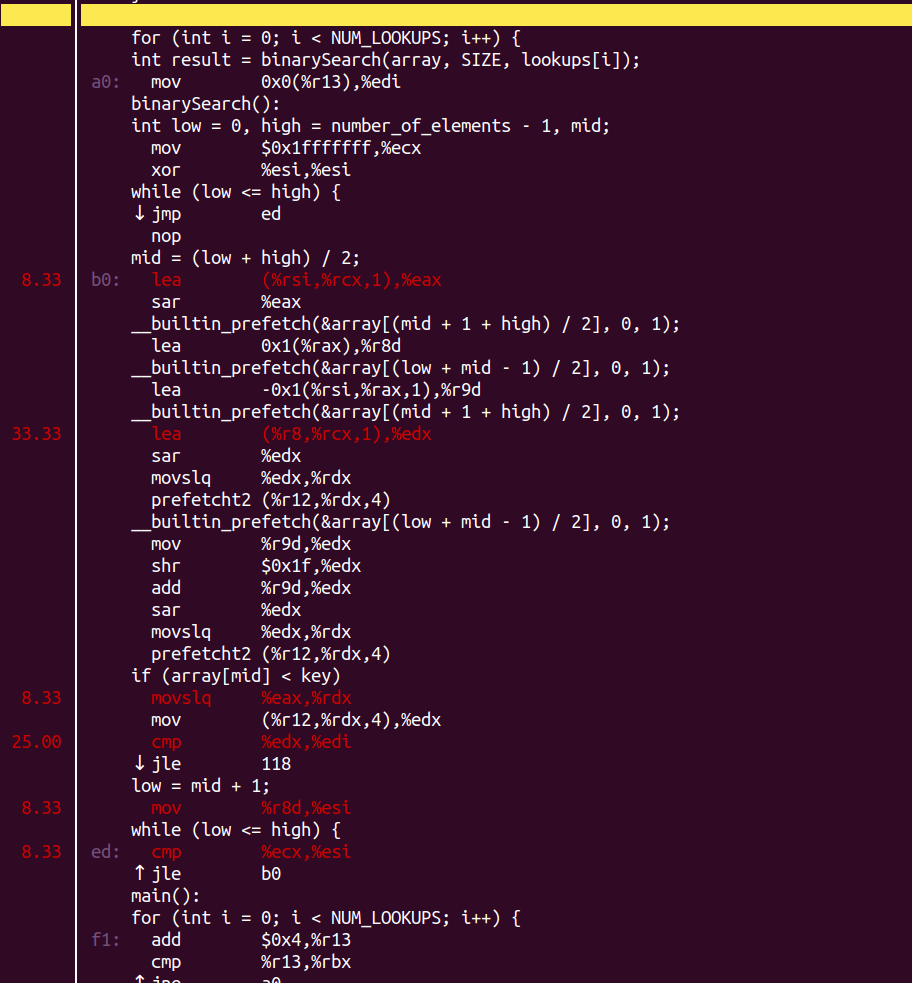
熱點被分散了,預取緩解了Memory_Bound的情況。
避免false sharing
前面我們提到過,數據如果在一個cacheline,被多核訪問的時候,多核間運行的cache一致性協議,會導致cacheline在多核間的同步。這個同步會有很大的延遲,是工程里著名的false sharing問題。
比如下面一個結構體
structs
{
inta;
intb;
}
如果1個線程讀寫a,另外一個線程讀寫b,那么兩個線程就有機會在不同的核,于是產生cacheline同步行為的來回顛簸。但是,如果我們把a和b之間padding一些區域,就可以把這兩個纏繞在一起的人拉開:
struct s
{
int a;
charpadding[cacheline_size-sizeof(int)];
int b;
}
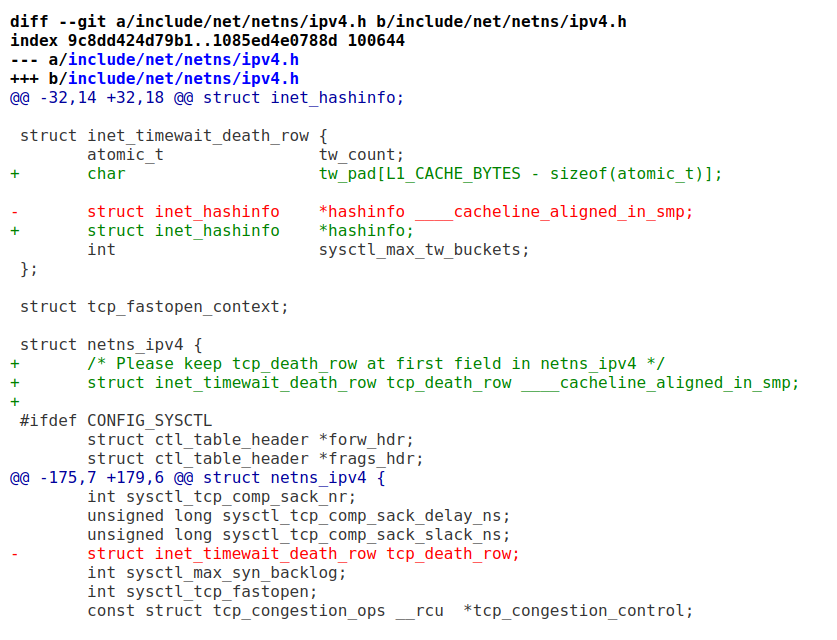
因此,在實際的工程中,我們經常看到有人對數據的位置進行移位,或者在2個可能引起false sharing的數據間填充數據進行padding。這樣的代碼在內核不甚枚舉,我們隨便找一個:

它特別提到在tw_count后面60個字節(L1_CACHE_BYTES - sizeof(atomic_t))的padding,從而避免false sharing:
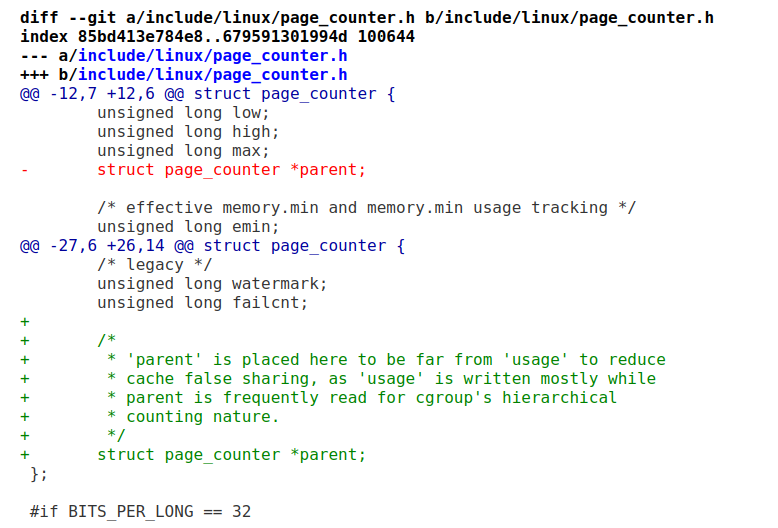
下面這個則是通過移動結構體內部成員的位置,相關數據的cacheline分開的:

這個改動有明顯的性能提升,最高可達9.9%。代碼里面也有明顯地注釋,usage和parent原先靠地太近,一個頻繁寫,一個頻繁讀。移開了2邊互相不打架了:
把理論和代碼能對上的感覺真TNND爽。無論是996,還是007,都必須留些時間來思考,來讓理論和實踐結合,否則,就變成漫無目的的內卷,這樣一定會卷輸的。內卷并不可悲,可悲的是卷不贏別人。
1. 什么是CPU Cache?
如圖所示:
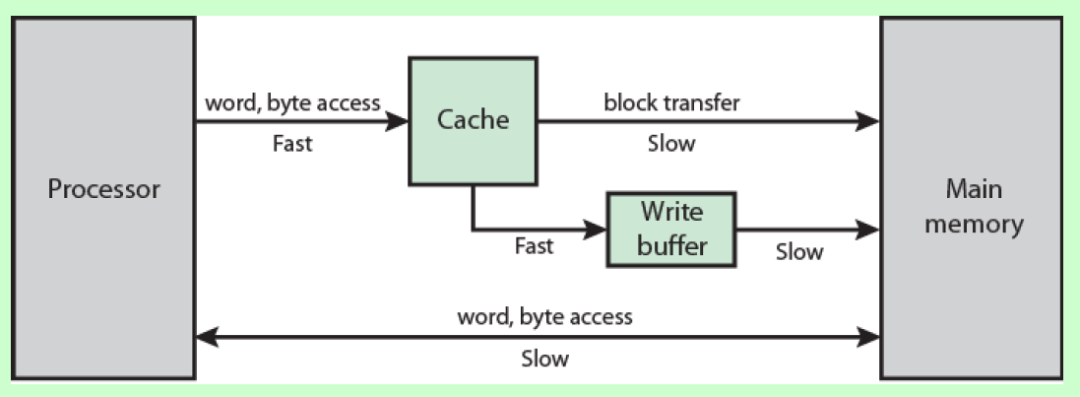
CPU Cache可以理解為CPU內部的高速緩存,當CPU從內存中讀取數據時,并不是只讀自己想要的那一部分,而是讀取更多的字節到CPU高速緩存中。當CPU繼續訪問相鄰的數據時,就不必每次都從內存中讀取,可以直接從高速緩存行讀取數據,而訪問高速緩存比訪問內存速度要快的多,所以速度會得到極大提升。
2. 為什么要有Cache?為什么要有多級Cache?
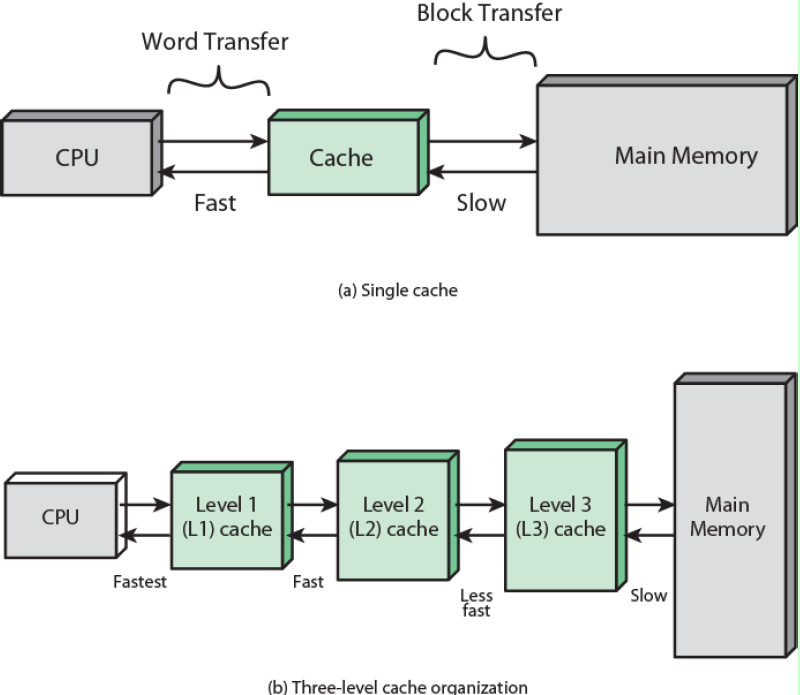
為什么要有Cache這個問題想必大家心里都已經有了答案了吧,CPU直接訪問距離較遠,容量較大,性能較差的主存速度很慢,所以在CPU和內存之間插入了Cache,CPU訪問Cache的速度遠高于訪問主存的速度。
CPU Cache是位于CPU和內存之間的臨時存儲器,它的容量比內存小很多但速度極快,可以將內存中的一小部分加載到Cache中,當CPU需要訪問這一小部分數據時可以直接從Cache中讀取,加快了訪問速度。
想必大家都聽說過程序局部性原理,這也是CPU引入Cache的理論基礎,程序局部性分為時間局部性和空間局部性。時間局部性是指被CPU訪問的數據,短期內還要被繼續訪問,比如循環、遞歸、方法的反復調用等。空間局部性是指被CPU訪問的數據相鄰的數據,CPU短期內還要被繼續訪問,比如順序執行的代碼、連續創建的兩個對象、數組等。因為如果將剛剛訪問的數據和相鄰的數據都緩存到Cache時,那下次CPU訪問時,可以直接從Cache中讀取,提高CPU訪問數據的速度。
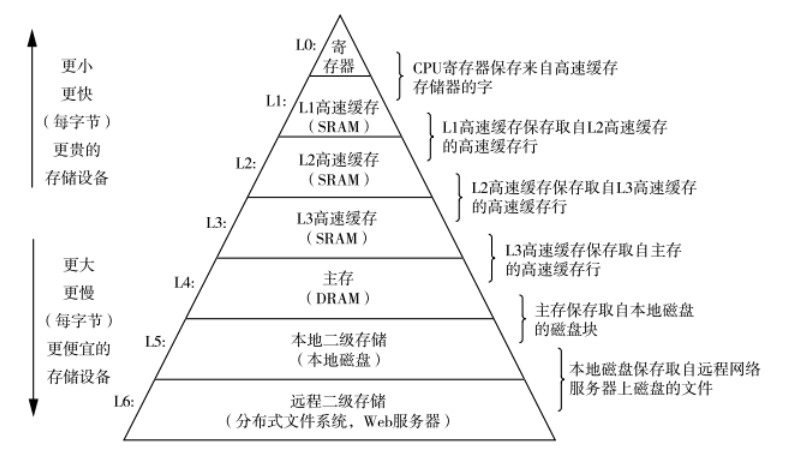
一個存儲器層次大體結構如圖所示,速度越快的存儲設備自然價格也就越高,隨著數據訪問量的增大,單純的增加一級緩存的成本太高,性價比太低,所以才有了二級緩存和三級緩存,他們的容量越來越大,速度越來越慢(但還是比內存的速度快),成本越來越低。
3. Cache的大小和速度如何?
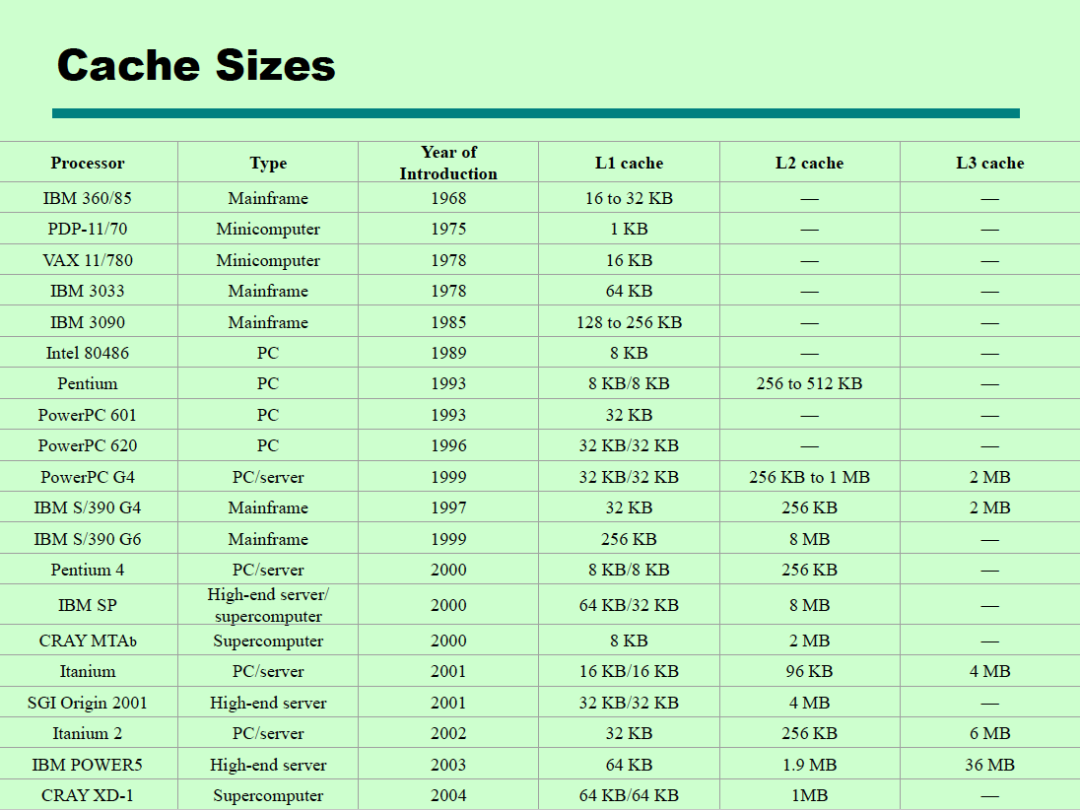
通常越接近CPU的緩存級別越低,容量越小,速度越快。不同的處理器Cache大小不同,通常現在的處理器的L1 Cache大小都是64KB。
那CPU訪問各個Cache的速度如何呢?
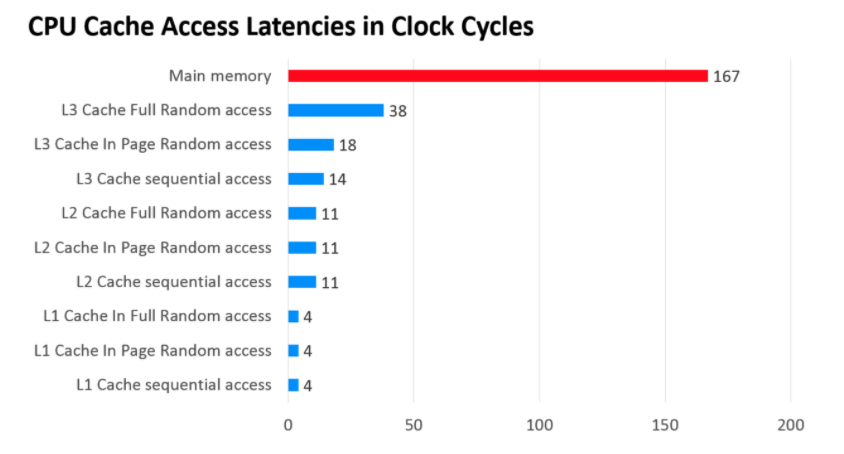
如圖所示,級別越低的高速緩存,CPU訪問的速度越快。
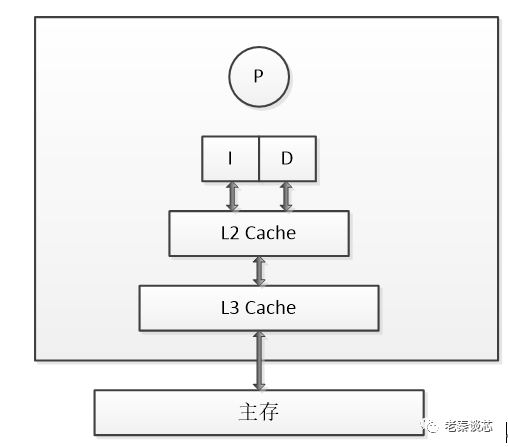
CPU多級緩存架構大體如下:
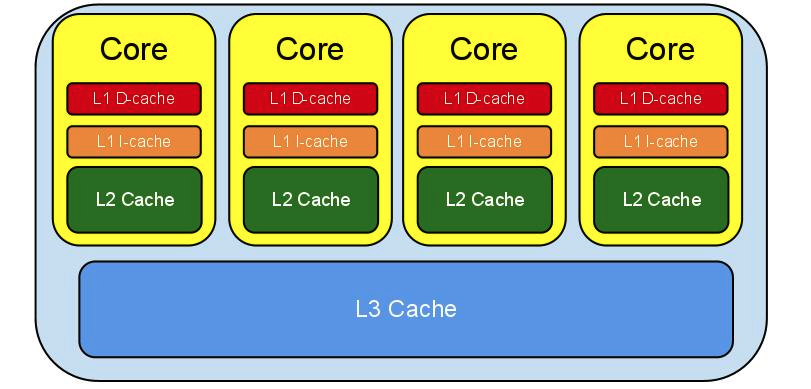
L1 Cache是最離CPU最近的,它容量最小,速度最快,每個CPU都有L1 Cache,見上圖,其實每個CPU都有兩個L1 Cache,一個是L1D Cache,用于存取數據,另一個是L1I Cache,用于存取指令。
L2 Cache容量較L1大,速度較L1較慢,每個CPU也都有一個L2 Cache。L2 Cache制造成本比L1 Cache更低,它的作用就是存儲那些CPU需要用到的且L1 Cache miss的數據。
L3 Cache容量較L2大,速度較L2慢,L3 Cache不同于L1 Cache和L2 Cache,它是所有CPU共享的,可以把它理解為速度更快,容量更小的內存。
當CPU需要數據時,整體流程如下:
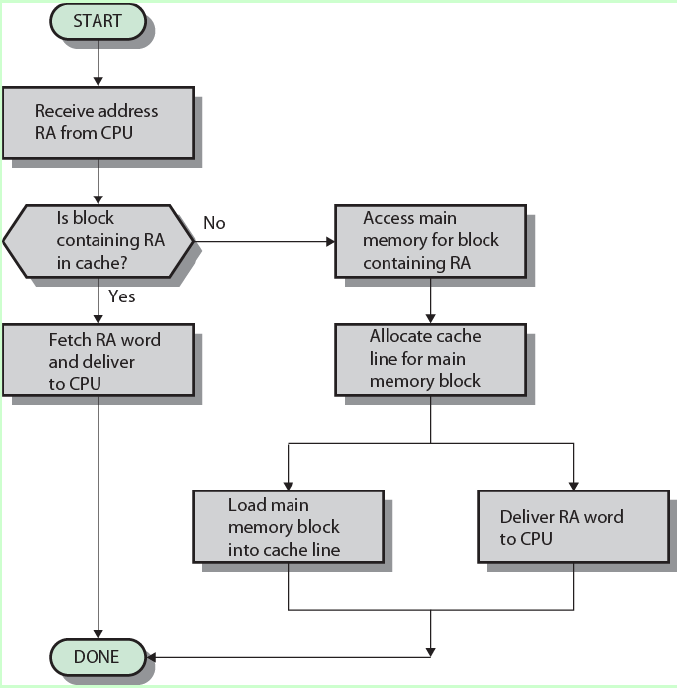
會最先去CPU的L1 Cache中尋找相關的數據,找到了就返回,找不到就去L2 Cache,再找不到就去L3 Cache,再找不到就從內存中讀取數據,尋找的距離越長,自然速度也就越慢。
4. Cache Line?
Cache Line可以理解為CPU Cache中的最小緩存單位。Main Memory-Cache或Cache-Cache之間的數據傳輸不是以字節為最小單位,而是以Cache Line為最小單位,稱為緩存行。 目前主流的Cache Line大小都是64字節,假設有一個64K字節的Cache,那這個Cache所能存放的Cache Line的個數就是1K個。
5. 寫入策略
Cache的寫入策略有兩種,分別是WriteThrough(直寫模式)和WriteBack(回寫模式)。 直寫模式:在數據更新時,將數據同時寫入內存和Cache,該策略操作簡單,但是因為每次都要寫入內存,速度較慢。 回寫模式:在數據更新時,只將數據寫入到Cache中,只有在數據被替換出Cache時,被修改的數據才會被寫入到內存中,該策略因為不需要寫入到內存中,所以速度較快。但數據僅寫在了Cache中,Cache數據和內存數據不一致,此時如果有其它CPU訪問數據,就會讀到臟數據,出現bug,所以這里需要用到Cache的一致性協議來保證CPU讀到的是最新的數據。
6. 什么是Cache一致性呢?
多個CPU對某塊內存同時讀寫,就會引起沖突的問題,被稱為Cache一致性問題。
有這樣一種情況:
a.CPU1讀取了一個字節offset,該字節和相鄰的數據就都會被寫入到CPU1的Cache. b.此時CPU2也讀取相同的字節offset,這樣CPU1和CPU2的Cache就都擁有同樣的數據。 c.CPU1修改了offset這個字節,被修改后,這個字節被寫入到CPU1的Cache中,但是沒有被同步到內存中。 d.CPU2 需要訪問offset這個字節數據,但是由于最新的數據并沒有被同步到內存中,所以CPU2 訪問的數據不是最新的數據。
這種問題就被稱為Cache一致性問題,為了解決這個問題大佬們設計了MESI協議,當一個CPU1修改了Cache中的某字節數據時,那么其它的所有CPU都會收到通知,它們的相應Cache就會被置為無效狀態,當其他的CPU需要訪問此字節的數據時,發現自己的Cache相關數據已失效,這時CPU1會立刻把數據寫到內存中,其它的CPU就會立刻從內存中讀取該數據。
MESI協議是通過四種狀態的控制來解決Cache一致性的問題:
■M:代表已修改(Modified) 緩存行是臟的(dirty),與主存的值不同。如果別的CPU內核要讀主存這塊數據,該緩存行必須回寫到主存,狀態變為共享(S).
■E:代表獨占(Exclusive) 緩存行只在當前緩存中,但是干凈的(clean)--緩存數據同于主存數據。當別的緩存讀取它時,狀態變為共享(S);當前寫數據時,變為已修改(M)狀態。
■S:代表共享(Shared) 緩存行也存在于其它緩存中且是干凈(clean)的。緩存行可以在任意時刻拋棄。
■I:代表已失效(Invalidated) 緩存行是臟的(dirty),無效的。
四種狀態的相容關系如下:
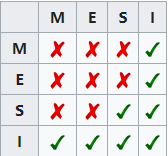
這里我們只需要知道它是通過這四種狀態的切換解決的Cache一致性問題就好,具體狀態機的控制實現太繁瑣,就不多介紹了,這是狀態機轉換圖,是不是有點懵。
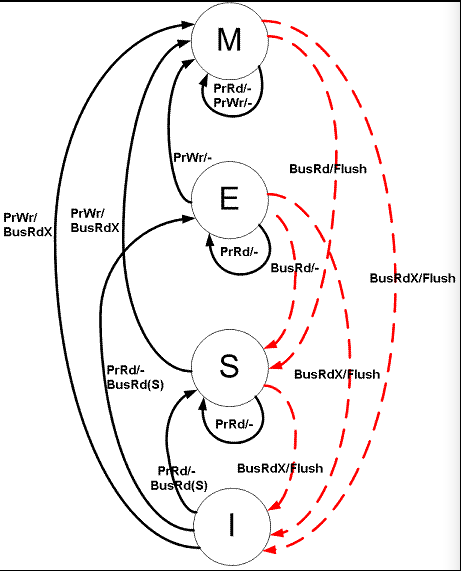
7. Cache與主存的映射關系?
直接映射

直接映射如圖所示,每個主存塊只能映射Cache的一個特定塊。直接映射是最簡單的地址映射方式,它的硬件簡單,成本低,地址轉換速度快,但是這種方式不太靈活,Cache的存儲空間得不到充分利用,每個主存塊在Cache中只有一個固定位置可存放,容易產生沖突,使Cache效率下降,因此只適合大容量Cache采用。
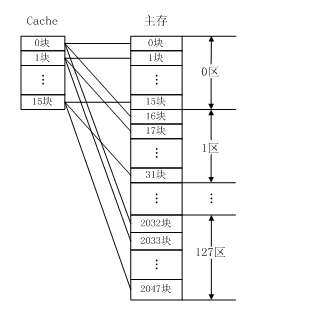
例如,如果一個程序需要重復引用主存中第0塊與第16塊,最好將主存第0塊與第16塊同時復制到Cache中,但由于它們都只能復制到Cache的第0塊中去,即使Cache中別的存儲空間空著也不能占用,因此這兩個塊會不斷地交替裝入Cache中,導致命中率降低。
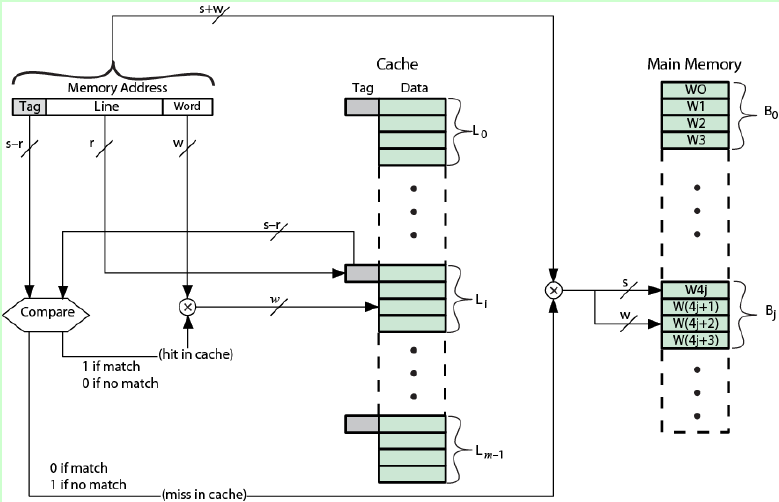
直接映射方式下主存地址格式如圖,主存地址為s+w位,Cache空間有2的r次方行,每行大小有2的w次方字節,則Cache地址有w+r位。通過Line確定該內存塊應該在Cache中的位置,確定位置后比較標記是否相同,如果相同則表示Cache命中,從Cache中讀取。
全相連映射
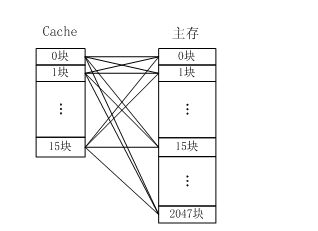
全相連映射如圖所示,主存中任何一塊都可以映射到Cache中的任何一塊位置上。
全相聯映射方式比較靈活,主存的各塊可以映射到Cache的任一塊中,Cache的利用率高,塊沖突概率低,只要淘汰Cache中的某一塊,即可調入主存的任一塊。但是,由于Cache比較電路的設計和實現比較困難,這種方式只適合于小容量Cache采用。
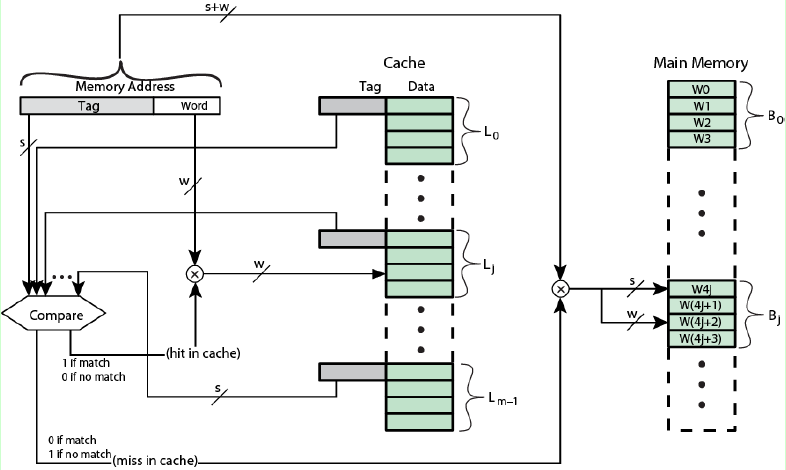
全相連映射的主存結構就很簡單啦,將CPU發出的內存地址的塊號部分與Cache所有行的標記進行比較,如果有相同的,則Cache命中,從Cache中讀取,如果找不到,則沒有命中,從主存中讀取。
組相連映射
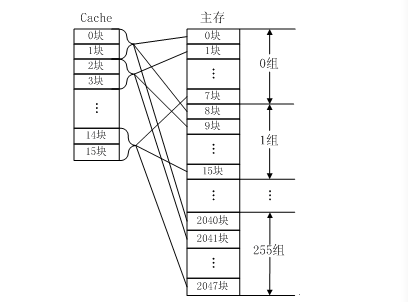
組相聯映射實際上是直接映射和全相聯映射的折中方案,其組織結構如圖3-16所示。主存和Cache都分組,主存中一個組內的塊數與Cache中的分組數相同,組間采用直接映射,組內采用全相聯映射。也就是說,將Cache分成u組,每組v塊,主存塊存放到哪個組是固定的,至于存到該組哪一塊則是靈活的。例如,主存分為256組,每組8塊,Cache分為8組,每組2塊。
主存中的各塊與Cache的組號之間有固定的映射關系,但可自由映射到對應Cache組中的任何一塊。例如,主存中的第0塊、第8塊……均映射于Cache的第0組,但可映射到Cache第0組中的第0塊或第1塊;主存的第1塊、第9塊……均映射于Cache的第1組,但可映射到Cache第1組中的第2塊或第3塊。
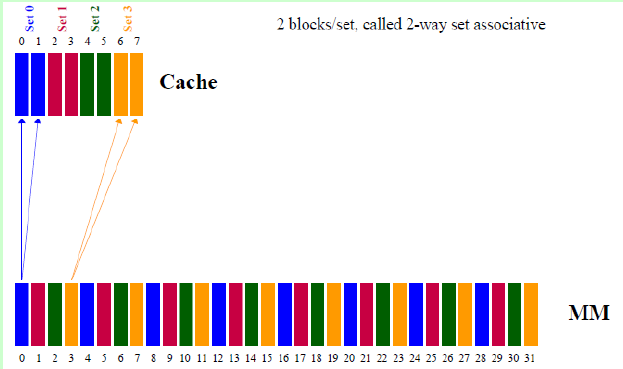
常采用的組相聯結構Cache,每組內有2、4、8、16塊,稱為2路、4路、8路、16路組相聯Cache。組相聯結構Cache是前兩種方法的折中方案,適度兼顧二者的優點,盡量避免二者的缺點,因而得到普遍采用。
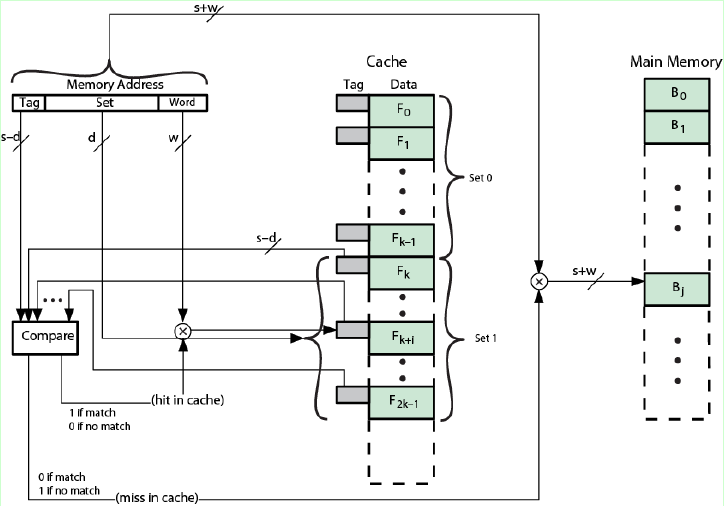
組相連映射方式下的主存地址格式如圖,先確定主存應該在Cache中的哪一個組,之后組內是全相聯映射,依次比較組內的標記,如果有標記相同的Cache,則命中,否則不命中。
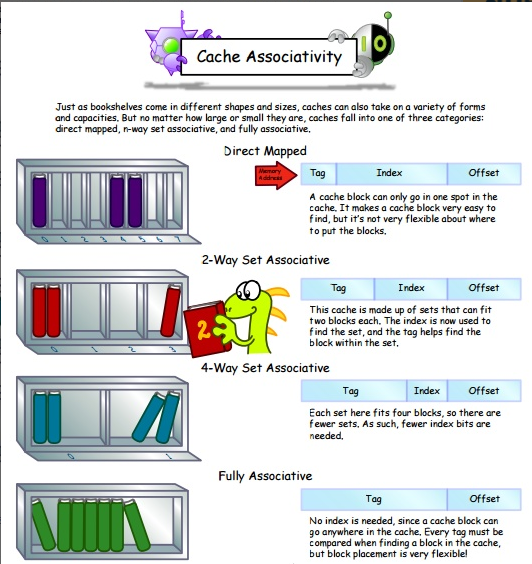
在網上找到了三種映射方式下的主存格式對比圖,大家也可以看下:
8. Cache的替換策略?
Cache的替換策略想必大家都知道,就是LRU策略,即最近最少使用算法,選擇未使用時間最長的Cache替換。
9. 如何巧妙利用CPU Cache編程?
constintrow=1024; constintcol=1024; intmatrix[row][col]; //按行遍歷 intsum_row=0; for(intr=0;r
上面是兩段二維數組的遍歷方式,一種按行遍歷,另一種是按列遍歷,乍一看您可能認為計算量沒有任何區別,但其實按行遍歷比按列遍歷速度快的多,這就是CPU Cache起到了作用,根據程序局部性原理,訪問主存時會把相鄰的部分數據也加載到Cache中,下次訪問相鄰數據時Cache的命中率極高,速度自然也會提升不少。
平時編程過程中也可以多利用好程序的時間局部性和空間局部性原理,就可以提高CPU Cache的命中率,提高程序運行的效率。
責任編輯:彭菁
-
處理器
+關注
關注
68文章
20250瀏覽量
252213 -
cpu
+關注
關注
68文章
11277瀏覽量
224952 -
Cache
+關注
關注
0文章
130瀏覽量
29707
原文標題:深入理解cache對寫好代碼至關重要
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
cpu與cache內存交互的過程
CPU Cache是如何保證緩存一致性的?
cache的應用——什么時候需要刷cache1
嵌入式CPU指令Cache的設計與實現
什么是緩存Cache
什么是Cache/SIMD?
什么是Instructions Cache/IMM/ID
高速緩存(Cache),高速緩存(Cache)原理是什么?
Buffer和Cache之間區別是什么?
cache的排布與CPU的典型分布
什么是 Cache? Cache讀寫原理
CPU Cache偽共享問題
CPU設計之Cache存儲器



 工商網監
工商網監
評論